Автор: Денис Аветисян
В статье представлен практический подход к созданию интеллектуальных агентов, использующих большие языковые модели и систематизированные знания экспертов для автоматизации сложных задач.
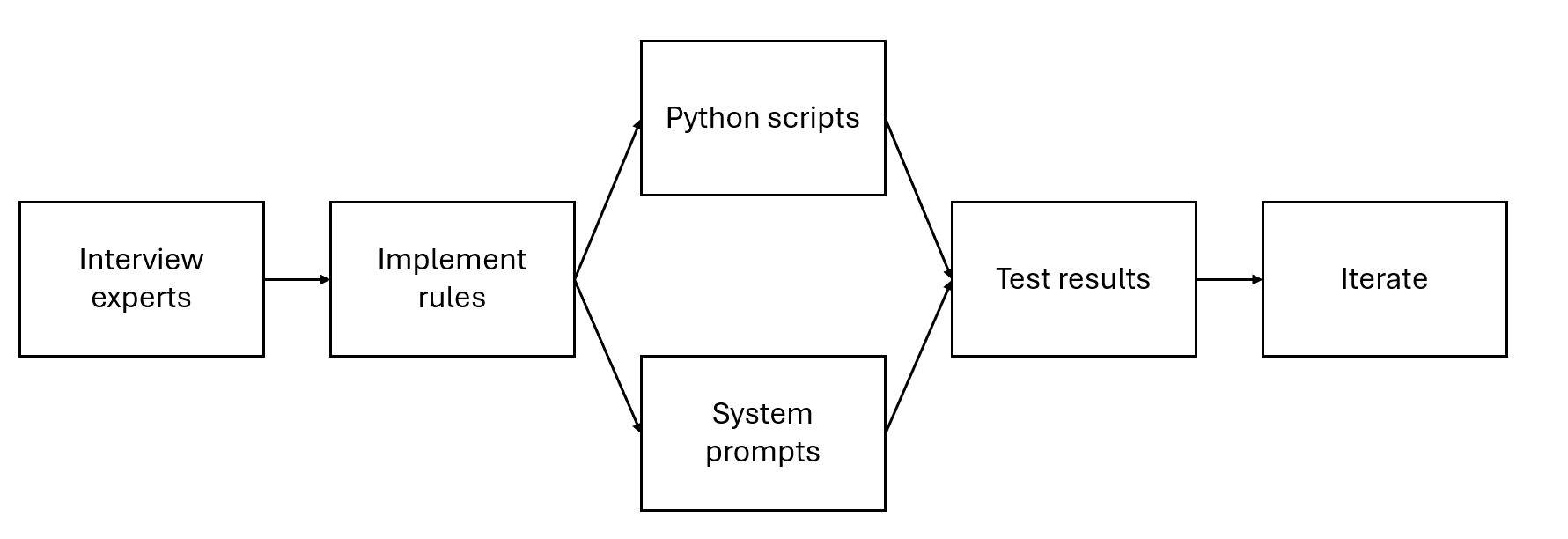
Предлагается программно-инженерный фреймворк для кодификации экспертных знаний и создания AI-агентов, способных генерировать визуализации данных и решать сложные аналитические задачи.
Ограниченный доступ к экспертным знаниям часто становится узким местом в масштабировании и принятии решений в сложных областях. В данной работе, посвященной теме ‘How to Build AI Agents by Augmenting LLMs with Codified Human Expert Domain Knowledge? A Software Engineering Framework’, предложен программный инженерный фреймворк для создания интеллектуальных агентов, способных автоматизировать генерацию визуализаций данных моделирования на уровне экспертного знания. Предложенная система, использующая большие языковые модели (LLM) и методы RAG (Retrieval-Augmented Generation), демонстрирует значительное улучшение качества выходных данных — до 206% — и позволяет неспециалистам получать результаты, сопоставимые с экспертными. Возможно ли, таким образом, систематизировать и передавать неявные знания экспертов, расширяя возможности анализа данных в различных инженерных областях?
Преодоление Узких Мест в Анализе Сложных Симуляций
Анализ данных, получаемых в результате сложных симуляций, будь то в механике, электромагнетизме или электрохимии, исторически требовал глубоких знаний в соответствующей предметной области. Это обусловлено тем, что интерпретация результатов, выявление закономерностей и валидация моделей требуют понимания физических принципов, лежащих в основе симуляции, а также умения отличать значимые данные от шума и артефактов. Специалисты, обладающие таким опытом, становятся критически важными для извлечения полезной информации, однако их ограниченное количество и высокая востребованность создают узкое место, замедляющее процесс анализа и ограничивающее возможности масштабирования исследований. Без экспертной оценки, даже самые совершенные симуляции рискуют остаться неиспользованными, а потенциальные открытия — незамеченными.
Зависимость анализа сложных симуляций от узкоспециализированных экспертов создает критическую проблему, известную как “узкое место эксперта”. Это ограничивает скорость, с которой можно извлекать полезные знания из моделирования механических, электромагнитных и электрохимических систем. Поскольку каждый этап — от интерпретации данных до формулирования выводов — требует глубокого понимания предметной области, процесс становится последовательным и медленным. Необходимость постоянного обращения к экспертам замедляет масштабирование анализа, препятствуя возможности быстрого исследования широкого спектра сценариев и оптимизации сложных процессов. В результате, потенциальная ценность данных симуляций не реализуется в полной мере, а время, необходимое для принятия обоснованных решений, значительно увеличивается.
Визуализация данных играет ключевую роль в интерпретации результатов сложных симуляций, будь то в механике, электромагнетизме или электрохимии. Однако, создание эффективных и информативных визуализаций зачастую представляет собой трудоемкий и отнимающий много времени процесс, требующий ручной настройки параметров и отдельных навыков. Традиционно, для преобразования сырых данных симуляций в понятные графики и диаграммы необходимы значительные усилия и экспертиза, что замедляет анализ и ограничивает возможность быстрого получения ценных выводов. Автоматизация этого процесса и разработка инструментов, упрощающих создание визуализаций, являются критически важными для ускорения исследований и расширения доступа к результатам сложных симуляций.
Автоматическое Создание Визуализаций на Основе Больших Языковых Моделей
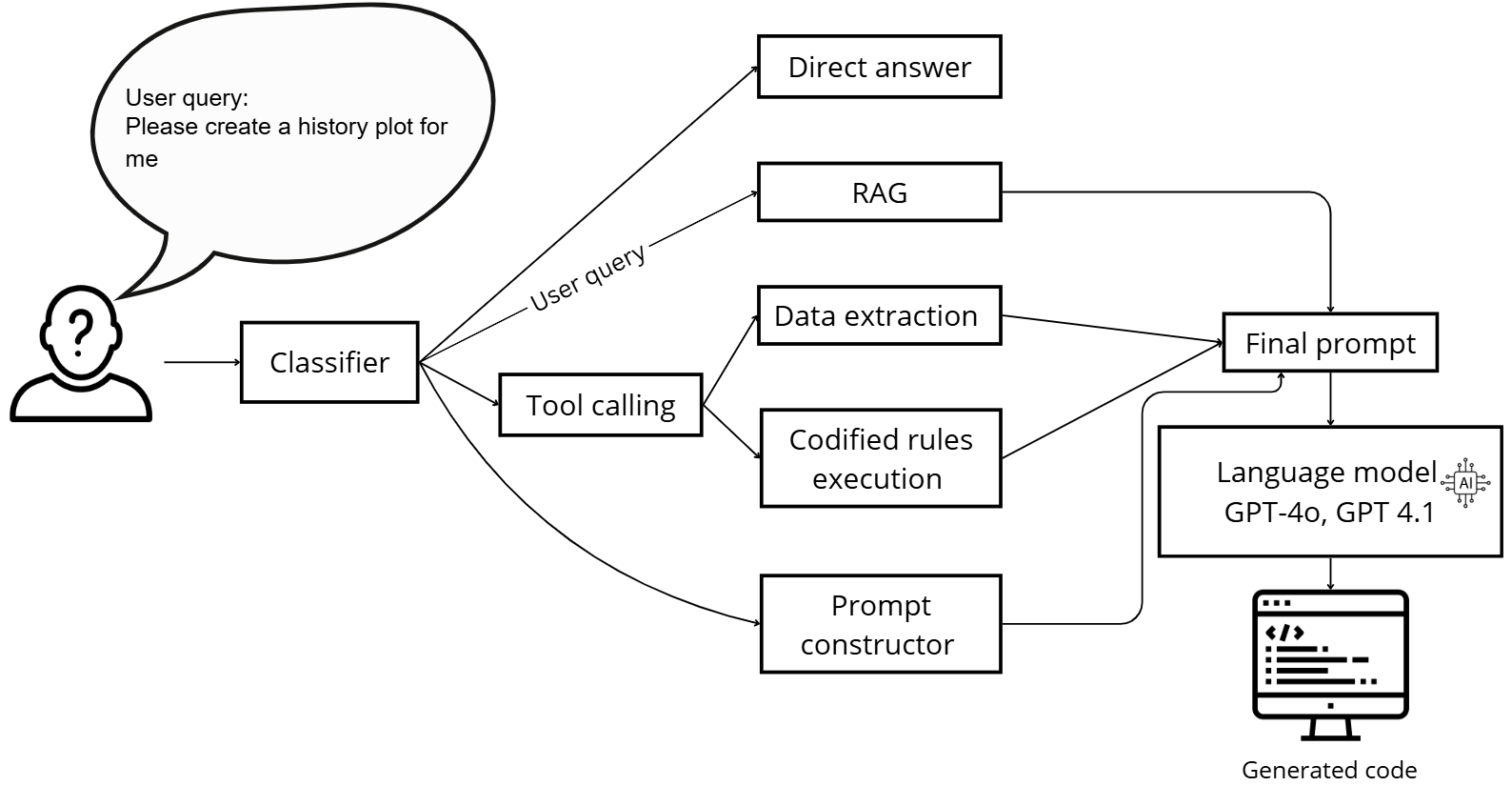
Представляется агент автоматической генерации визуализаций на базе большой языковой модели (LLM), предназначенный для автономного создания визуальных представлений из данных моделирования. Агент способен самостоятельно обрабатывать данные, определять подходящие типы визуализаций (например, графики, диаграммы рассеяния, тепловые карты) и генерировать соответствующие изображения без вмешательства человека. Процесс включает в себя анализ структуры данных, выявление ключевых параметров и зависимостей, и последующее формирование визуализаций, нацеленных на эффективное представление полученных результатов. Автономность агента обеспечивает масштабируемость и ускорение процесса анализа данных, особенно в контексте крупномасштабных симуляций и моделирования.
Агент автоматической генерации визуализаций использует систему Retrieval-Augmented Generation (RAG) для доступа и применения специализированных знаний в предметной области. RAG-система позволяет агенту извлекать релевантную информацию из внешних баз данных и документов, что значительно расширяет его возможности по сравнению со стандартными языковыми моделями. В процессе генерации визуализаций, RAG-система идентифицирует наиболее подходящие фрагменты данных и использует их для контекстуализации и уточнения выходных результатов, обеспечивая соответствие визуализаций специфическим требованиям и стандартам предметной области. Это позволяет агенту создавать более точные, информативные и полезные визуализации, основанные не только на входных данных модели, но и на накопленных знаниях.
Агент автоматической генерации визуализаций включает в себя кодифицированные “Экспертные Правила”, определяющие лучшие практики визуализации и процедуры проверки сходимости. Эти правила, представленные в виде структурированных данных, позволяют агенту автоматически выбирать оптимальные типы графиков, масштабы осей, цветовые схемы и другие параметры отображения данных. Проверка сходимости, основанная на этих правилах, гарантирует, что сгенерированные визуализации корректно отображают результаты моделирования и не содержат артефактов, вызванных ошибками или неполными данными. Это обеспечивает высокое качество выходных визуализаций и снижает потребность в ручной корректировке.
Обеспечение Надежности: Качество Кода и Визуализаций
Ключевым направлением наших исследований является обеспечение корректности генерируемого Python-кода, используемого для создания визуализаций. Данный аспект включает в себя проверку синтаксической правильности, логической непротиворечивости и функциональной работоспособности кода, чтобы гарантировать, что визуализации формируются на основе достоверных вычислений и точной обработки данных. Стандартное отклонение для корректности кода, измеренное в ходе экспериментов, составляет 0.29-0.58, что значительно ниже, чем у базовой модели (0.67-1.24), подтверждая эффективность предложенного подхода к генерации корректного кода.
Качество генерируемых визуализаций является критически важным аспектом работы системы. В ходе исследований продемонстрировано увеличение качества выходных данных на 206%, что выражается в среднем балле 2.60 по сравнению с базовым уровнем 0.85. Данный показатель отражает улучшение в плане ясности, информативности и точности представления исходных данных на визуализациях, генерируемых системой.
Для демонстрации возможностей системы был проведен анализ с использованием программного обеспечения для анализа моделирования. Система успешно обработала сложные наборы данных, полученные из различных типов симуляций. Показатели корректности сгенерированного кода, измеренные стандартным отклонением, составили 0.29-0.58, что значительно ниже, чем у базовой системы, где стандартное отклонение колебалось в диапазоне 0.67-1.24. Данные результаты подтверждают повышенную надежность и стабильность системы при работе с комплексными данными моделирования.
К Физически Агностическому Анализу и Открытию Новых Знаний
Система построена на принципах физической агностичности, что позволяет ей успешно применяться в самых разных областях моделирования — от механики и электромагнетизма до электрохимии и других. В отличие от традиционных подходов, требующих адаптации алгоритмов под конкретную физическую задачу, данная разработка способна анализировать данные из симуляций, независимо от лежащей в их основе физической модели. Это достигается благодаря использованию общих принципов обработки и визуализации данных, позволяющих выявлять закономерности и инсайты, не привязанные к специфике конкретной области науки. Такой подход значительно расширяет возможности анализа, делая его доступным для широкого круга исследователей и инженеров, работающих с различными типами симуляций.
Система искусственного интеллекта, автоматизируя процесс визуализации данных, значительно расширяет возможности специалистов в различных областях науки и техники. Она не заменяет экспертные знания, а эффективно дополняет их, позволяя извлекать ценные сведения из сложных симуляций даже тем, кто не обладает глубокой специализацией в конкретной области. Автоматизированная визуализация помогает выявлять закономерности и аномалии, которые могли бы остаться незамеченными при ручном анализе, тем самым упрощая процесс принятия обоснованных решений и стимулируя новые открытия. Оценка эффективности предложенного подхода показала существенное улучшение качества визуализаций по сравнению с базовыми методами, что подтверждает способность системы предоставлять более наглядные и информативные результаты.
В основе разработанного искусственного интеллекта лежит интеграция принципов визуального дизайна, что обеспечивает не только эффективность представления данных, но и их ясную коммуникацию пользователю. В ходе оценки, эксперты последовательно ставили оценку 3 по модальному значению, что свидетельствует о высоком качестве визуализаций, создаваемых агентом. Для сравнения, базовая модель демонстрировала модальное значение 0 в четырех из пяти сценариев тестирования. Такой значительный разрыв подтверждает, что применение специализированных принципов визуализации существенно повышает способность системы к предоставлению значимых и понятных выводов из сложных данных, делая информацию доступной для более широкой аудитории специалистов.
Представленная работа демонстрирует, что масштабируемость системы напрямую зависит не от вычислительных мощностей, а от четкости и ясности заложенных в неё идей. Авторы подчеркивают важность структурированного подхода к кодированию экспертных знаний, что позволяет создавать агентов, способных автоматизировать сложные задачи анализа данных моделирования. Этот принцип перекликается со словами Эдсгера Дейкстры: «Программирование — это не столько техника, сколько искусство структурирования». В данном исследовании, подобно созданию элегантной системы, ключевым является не просто сбор информации, а её организация в целостную и понятную структуру, позволяющую неспециалистам эффективно использовать сложные инструменты. Очевидно, что подобный подход, основанный на структуре, определяет поведение агента и обеспечивает его масштабируемость.
Что Дальше?
Представленная работа демонстрирует, что даже сложные системы могут быть построены на основе относительно простых принципов — кодификации экспертных знаний и их интеграции с мощностью больших языковых моделей. Однако, иллюзия простоты не должна затмевать остающиеся вопросы. Эффективность предложенного подхода сильно зависит от качества исходной кодификации знаний. Как обеспечить надежность и полноту этой кодификации, особенно в динамично меняющихся областях, остается непростой задачей. Полагаться на автоматическое извлечение знаний из неструктурированных данных — рискованно; информация, как правило, зашумлена и требует тщательной очистки.
Дальнейшее развитие, вероятно, связано с исследованием способов автоматической верификации и обновления этих кодифицированных знаний. Необходимо разработать инструменты, позволяющие выявлять противоречия и неточности в экспертных системах, а также адаптировать их к новым данным без потери целостности. Более того, важно помнить, что даже самая элегантная система — лишь приближение к реальности. Стремление к абсолютной точности может привести к чрезмерной сложности и хрупкости.
В конечном итоге, успех подобных систем будет определяться не столько технологическими инновациями, сколько умением найти баланс между автоматизацией и человеческим опытом. Попытки полностью заменить эксперта машиной, вероятно, обречены на неудачу. Гораздо перспективнее — создать инструменты, которые усилят возможности человека, позволят ему принимать более обоснованные решения и видеть закономерности, скрытые в потоке данных.
Оригинал статьи: https://arxiv.org/pdf/2601.15153.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Робот, который видит, понимает и действует: новая эра общего назначения
- Лунный гелий-3: Охлаждение квантового будущего
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-22 19:33