Автор: Денис Аветисян
Исследователи представили масштабный бенчмарк для оценки моделей вознаграждения, управляющих агентами, использующими инструменты, что открывает путь к более эффективному и универсальному искусственному интеллекту.
ToolPRMBench: Комплексная оценка и продвижение моделей вознаграждения для обучения агентов, работающих с инструментами, с использованием методов обучения с подкреплением и траекторной выборки.
Несмотря на перспективность методов обучения с подкреплением для агентов, использующих инструменты, систематической оценки и сопоставления моделей вознаграждения на каждом шаге (Process Reward Models, PRM) до сих пор не проводилось. В данной работе, представленной под названием ‘ToolPRMBench: Evaluating and Advancing Process Reward Models for Tool-using Agents’, авторы предлагают масштабный бенчмарк ToolPRMBench, предназначенный для всесторонней оценки PRM в контексте использования инструментов. Эксперименты с различными большими языковыми моделями показали, что специализированные PRM демонстрируют значительные преимущества перед общими моделями. Сможем ли мы создать более надежных и универсальных агентов, эффективно использующих инструменты, благодаря более глубокому пониманию и совершенствованию моделей вознаграждения?
Преодолевая Сложность Последовательного Использования Инструментов
Традиционное обучение с подкреплением испытывает значительные трудности при решении задач, требующих последовательного использования инструментов. Проблема заключается в разреженности вознаграждений: агент получает сигнал об успехе лишь после завершения всей последовательности действий, что затрудняет определение, какие именно действия привели к положительному результату. Эта разреженность существенно усложняет процесс обучения, поскольку алгоритм сталкивается с необходимостью исследовать огромное пространство возможных действий, чтобы случайно обнаружить успешную последовательность. По сути, агент вынужден действовать вслепую, не имея четких указаний на то, какие действия приближают его к цели, что приводит к низкой эффективности обучения и требует огромного количества проб и ошибок для достижения удовлетворительных результатов.
Для успешной навигации в сложных средах необходимы агенты, способные к долгосрочному планированию и точному управлению инструментами, однако современные модели зачастую испытывают недостаток в этих ключевых возможностях. Неспособность предвидеть последствия действий на большом временном горизонте приводит к неэффективному использованию ресурсов и затрудняет решение задач, требующих последовательных манипуляций с объектами. Точность управления инструментами критически важна для выполнения сложных операций, таких как сборка, ремонт или строительство, где даже небольшие отклонения могут привести к неудаче. В результате, разработка алгоритмов, позволяющих агентам формировать долгосрочные планы и осуществлять точное управление инструментами, является одной из центральных задач в области искусственного интеллекта и робототехники.
Процедурные Модели Вознаграждения: Направляя Исследование
Модели вознаграждения за процесс (PRM) предоставляют плотную, поэтапную обратную связь, позволяя агентам извлекать уроки из частичных успехов и отсекать неверные траектории. В отличие от разреженных вознаграждений, выдаваемых только по завершении задачи, PRM оценивают каждый шаг, обеспечивая более гранулированное обучение. Это особенно важно в сложных задачах, где достижение конечной цели требует последовательности правильных действий. Оценивая промежуточные шаги, PRM позволяют агенту корректировать свою стратегию на ранних этапах, избегая затяжных и бесплодных поисков. Такой подход значительно ускоряет процесс обучения и повышает эффективность агента в достижении поставленной цели.
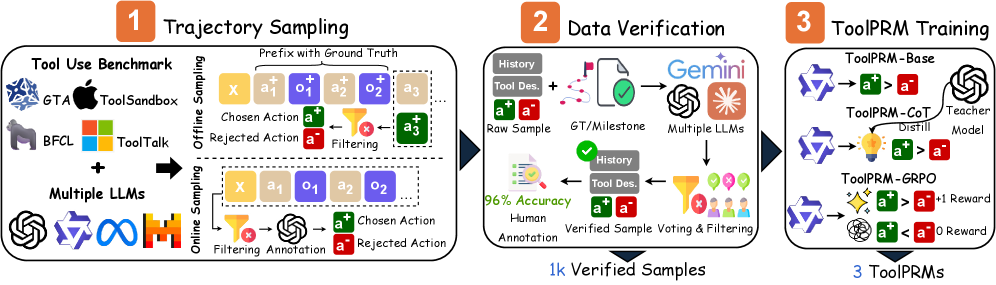
Для эффективной тренировки моделей вознаграждения процесса (PRM) необходимы надежные алгоритмы, такие как Group Relative Policy Optimization (GRPO). GRPO позволяет оптимизировать политику агента, учитывая относительное изменение вознаграждения в группе траекторий, что повышает стабильность обучения. Кроме того, для масштабирования обучения PRM, особенно при работе с большими моделями и наборами данных, применяются техники, такие как DeepSpeed ZeRO-3. ZeRO-3 обеспечивает разделение состояний оптимизатора, градиентов и параметров модели между несколькими GPU, значительно снижая потребление памяти и позволяя обучать модели большего размера, чем это было бы возможно на одном устройстве.
Крупные языковые модели, такие как GPT-5 и Gemini 2.5 Pro, играют ключевую роль в уточнении понимания моделями процесса вознаграждения (PRM) принципов использования инструментов и сигналов вознаграждения. Они используются для генерации и анализа данных, необходимых для обучения PRM, что позволяет повысить точность оценки промежуточных шагов и корректировать траектории обучения агента. Применение этих моделей позволяет PRM более эффективно интерпретировать сложные взаимодействия с инструментами и давать более информативные сигналы вознаграждения, способствуя тем самым улучшению стратегий исследования и повышению общей производительности агента.
ToolPRMBench: Всесторонний Инструмент Оценки
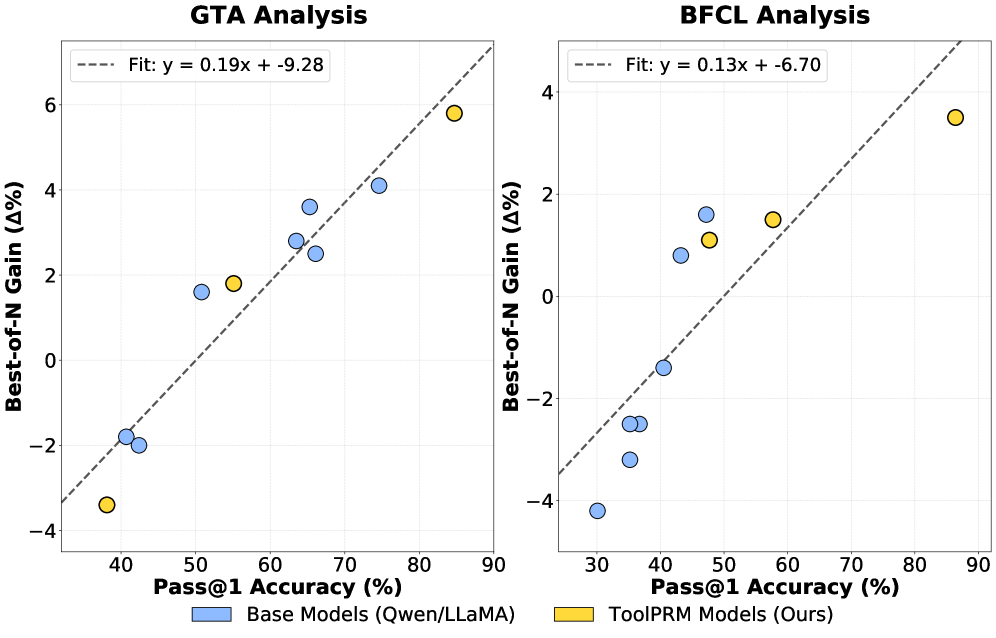
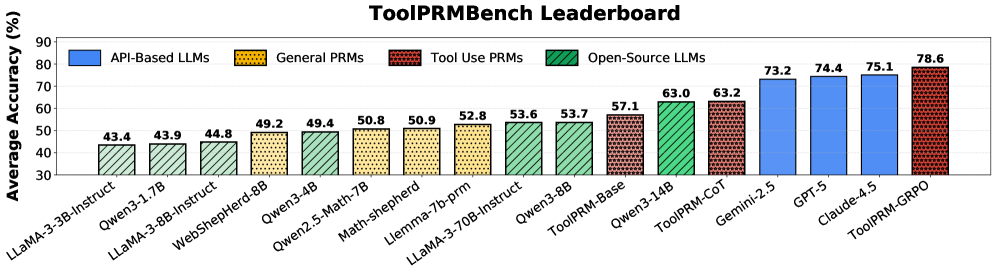
ToolPRMBench представляет собой масштабный оценочный комплекс, разработанный для анализа производительности моделей планирования действий (PRM) в задачах, требующих использования инструментов. Он включает в себя оценку на различных платформах и сценариях, таких как ToolTalk, GTA (General Task Automation), BFCL (Behavioral Feature Control Language) и ToolSandbox. Этот комплекс позволяет проводить всестороннее тестирование PRM в условиях, имитирующих реальное применение инструментов, охватывая широкий спектр задач автоматизации и управления поведением.
Для обеспечения надежности бенчмарка ToolPRMBench, процесс разметки данных осуществляется с особой тщательностью. Для гарантии согласованности и точности полученных меток применяется метод Multi-LLM Filtering, заключающийся в использовании нескольких больших языковых моделей для перекрестной проверки и валидации разметки. Этот подход позволяет минимизировать субъективные ошибки и обеспечить объективную оценку производительности моделей, работающих с инструментами. Данная методика гарантирует, что данные для обучения и оценки бенчмарка соответствуют высоким стандартам качества и отражают реальные сценарии использования инструментов.
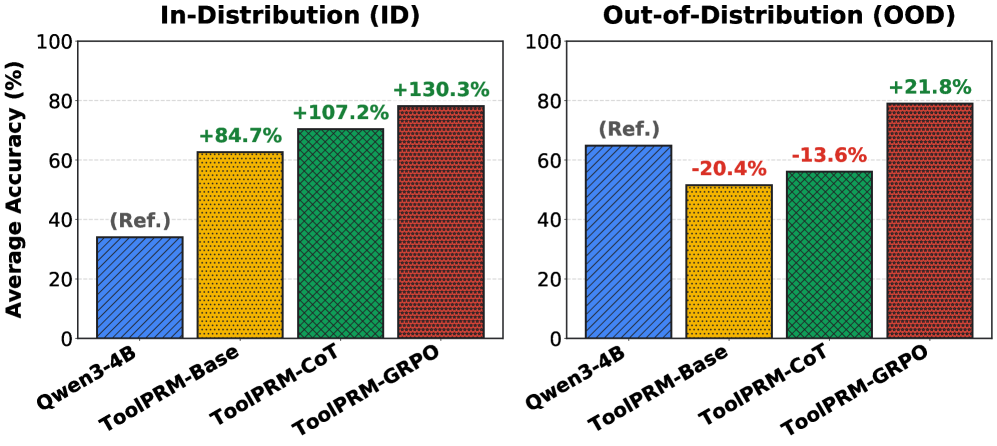
В ходе оценки производительности модели ToolPRM-GRPO на наборе данных ToolPRMBench было достигнуто до 96% точности в определении корректных действий. Для проведения оценки использовались два метода сэмплирования: Offline Sampling, ориентированный на выявление локальных ошибок в отдельных шагах, и Online Sampling, имитирующий реалистичные сценарии выполнения задач с полным развертыванием последовательности действий. Применение обоих методов позволило всесторонне оценить способность модели к правильному выбору инструментов и действий в различных задачах.
Направляемый Вознаграждением Поиск и Более Широкие Последствия
Процедурные модели поиска (PRM) оказались эффективным инструментом для реализации поиска с подкреплением, позволяя агентам продуктивно исследовать сложные пространства действий и выявлять оптимальные последовательности использования инструментов. Благодаря PRM, агент способен систематически пробовать различные комбинации действий, оценивая их результаты с помощью заданной функции вознаграждения. Этот подход позволяет избежать слепого перебора и сосредоточиться на наиболее перспективных направлениях поиска, что особенно важно при работе с многообразием доступных инструментов и задач. В результате, агенты, использующие PRM, демонстрируют повышенную эффективность в решении сложных задач, требующих планирования и координации действий.
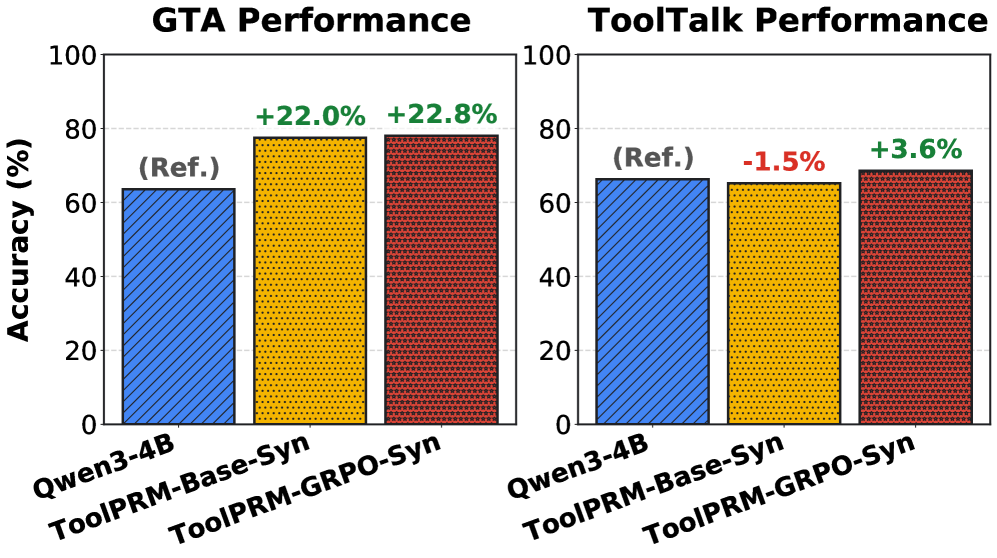
Исследование продемонстрировало значительное повышение устойчивости системы ToolPRM-GRPO в условиях, отличных от тех, на которых она обучалась — прирост производительности составил 21.8%. Этот результат подчеркивает преимущества использования обучения с подкреплением для создания более надежных и адаптивных агентов. Важно отметить, что ToolPRM не только демонстрирует сопоставимую точность с моделями, использующими API, но и существенно снижает затраты на эксплуатацию, что делает данный подход особенно привлекательным для широкого спектра практических приложений, где важна как эффективность, так и экономичность.
Представленная работа закладывает основу для создания более устойчивых, приспосабливающихся и интеллектуальных агентов, способных решать широкий спектр реальных задач. Разработанный подход позволяет существенно расширить возможности искусственного интеллекта в сложных и динамичных средах, где требуется не только выполнение конкретных инструкций, но и способность к самостоятельному обучению и адаптации к новым условиям. Благодаря возможности эффективного поиска и использования инструментов, такие агенты смогут успешно функционировать в различных областях, от автоматизации рутинных процессов до решения сложных научных и инженерных задач, открывая новые перспективы для развития искусственного интеллекта и его применения на благо общества.
Исследование демонстрирует, что архитектуры систем, даже самые передовые, подвержены неизбежному старению, особенно в контексте быстро развивающихся моделей вознаграждения для агентов, использующих инструменты. Как отмечал Г.Х. Харди: «Математика — это искусство делать то, что очевидно». В данном случае, очевидной становится необходимость постоянной адаптации и совершенствования моделей вознаграждения, поскольку старые методы перестают эффективно оценивать сложные траектории действий. ToolPRMBench, представленный в работе, служит своего рода «лакмусовой бумажкой», выявляя устаревшие подходы и стимулируя разработку более надежных и обобщающих решений. Каждая архитектура проживает свою жизнь, а мы лишь свидетели её эволюции, и ToolPRMBench позволяет отслеживать этот процесс.
Что дальше?
Представленный анализ, фокусируясь на оценке моделей вознаграждения для агентов, использующих инструменты, неизбежно сталкивается с фундаментальным вопросом: как долго прослужит любое «улучшение» в этой области? Создание эталонного набора данных, безусловно, является шагом вперед, но инерция времени неумолима. Любая достигнутая обобщающая способность, любая кажущаяся «робастность» — это лишь отсрочка неизбежного. Совершенствование траекторной выборки и обучение с подкреплением — полезные тактики, но они не изменяют базовую реальность: системы стареют.
Особенно интересно, что акцент делается на оценке процесса вознаграждения, а не конечного результата. Это признание того, что ценность заключается не в достижении цели, а в самом пути, что, впрочем, лишь подчеркивает эфемерность любого прогресса. Поскольку любое усовершенствование в модели вознаграждения, как и любое другое, будет со временем обесценено, возникает вопрос: не является ли постоянное тестирование и перекалибровка более продуктивной стратегией, чем стремление к недостижимой «идеальной» модели?
В конечном счете, исследование, представленное в этой работе, является еще одним шагом по спирали, ведущей к все более сложным системам. Однако, не стоит забывать, что даже самая тщательно откалиброванная система неизбежно столкнется с энтропией. Откат — это не провал, а естественное путешествие назад по стрелке времени. И, возможно, именно признание этой истины — первый шаг к созданию действительно устойчивых систем.
Оригинал статьи: https://arxiv.org/pdf/2601.12294.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовые прорывы: Хорошее, плохое и смешное
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
2026-01-21 15:57