Автор: Денис Аветисян
Исследователи представили UI-Venus-1.5, систему, способную к самостоятельному взаимодействию с графическим интерфейсом пользователя, значительно превосходящую существующие аналоги.
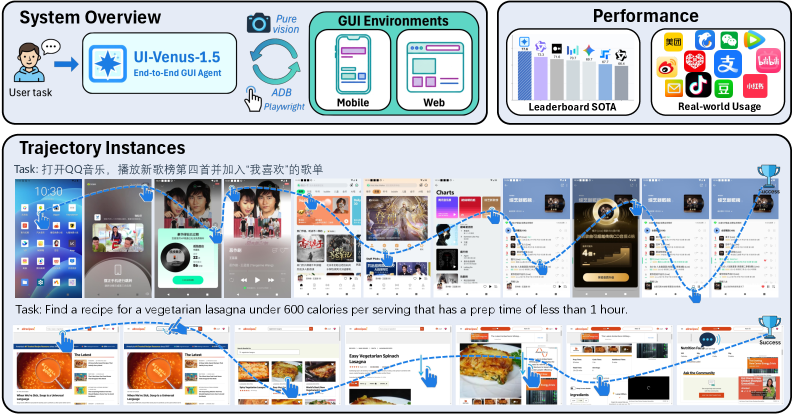
Представлена система UI-Venus-1.5, использующая комбинированный подход обучения с подкреплением, включая обучение в процессе, офлайн и онлайн методы, а также объединение моделей для достижения высокой производительности в управлении GUI.
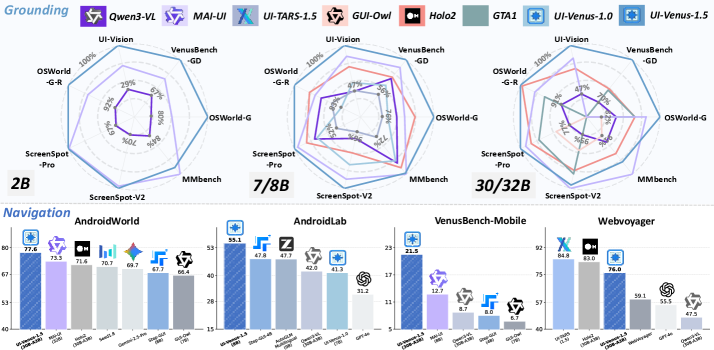
Автоматизация взаимодействия с цифровыми интерфейсами остается сложной задачей, требующей одновременного достижения широкой применимости и высокой производительности. В данной работе, представленной в ‘UI-Venus-1.5 Technical Report’, описывается UI-Venus-1.5 — унифицированный агент для GUI, демонстрирующий передовые результаты благодаря новому конвейеру обучения, включающему промежуточное обучение, обучение с подкреплением в режимах offline и online, а также объединение моделей. Достигнуты рекордные показатели на бенчмарках ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%) и AndroidWorld (77.6%), а также подтверждена надежная навигация в китайских мобильных приложениях. Какие перспективы открываются для создания еще более интеллектуальных и адаптивных цифровых помощников на основе подобных архитектур?
Преодоление Разрыва: Основные Вызовы Автоматизации Графических Интерфейсов
Традиционные методы автоматизации графического интерфейса пользователя (GUI) часто основываются на хрупких эвристиках, что делает их крайне чувствительными к малейшим изменениям в структуре или внешнем виде приложения. Динамические интерфейсы, в которых элементы управления постоянно меняют свое положение или свойства, представляют особую проблему, поскольку заранее заданные правила и шаблоны быстро становятся недействительными. В результате, даже незначительные обновления программного обеспечения могут привести к сбоям в автоматизированных процессах, требуя постоянной поддержки и адаптации. Эта нестабильность подчеркивает необходимость разработки более надежных и адаптивных решений, способных эффективно взаимодействовать с GUI, независимо от их динамичности и сложности, и обеспечивать стабильную работу автоматизированных систем.
Существующие методы автоматизации графических интерфейсов зачастую демонстрируют ограниченные возможности по адаптации к новым приложениям и выполнению сложных задач в их рамках. Это связано с тем, что большинство подходов полагаются на жестко заданные шаблоны и правила, которые оказываются неэффективными при изменении структуры или поведения интерфейса. Вместо того чтобы понимать логику приложения, системы часто ориентируются на визуальные элементы, что делает их уязвимыми к даже незначительным изменениям в дизайне. В результате, автоматизация требует постоянной перенастройки и адаптации при каждом обновлении или изменении приложения, что существенно снижает её эффективность и масштабируемость. Неспособность к обобщению ограничивает возможности использования автоматизации в динамичных и постоянно меняющихся средах, где требуется гибкость и адаптивность.
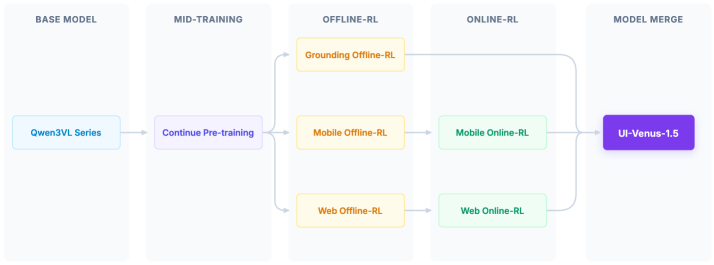
UI-Venus-1.5: Трёхфазный Подход к Надежной Автоматизации
UI-Venus-1.5 использует трехэтапный процесс обучения для достижения повышенной производительности. Первый этап, Mid-Training, предполагает дообучение базовой модели Qwen3-VL на размеченных данных пользовательского интерфейса для освоения базовых навыков взаимодействия. Далее следует этап Offline-RL, на котором агент обучается на заранее собранном наборе данных взаимодействий, используя алгоритмы обучения с подкреплением без прямого взаимодействия с окружением. Завершающий этап, Online-RL, включает в себя обучение агента в реальном времени посредством взаимодействия с графическим интерфейсом, что позволяет ему адаптироваться к новым ситуациям и оптимизировать свою стратегию действий. Последовательное применение этих трех этапов обеспечивает стабильное и эффективное обучение агента для автоматизации задач в пользовательском интерфейсе.
В основе UI-Venus-1.5 лежит мультимодальная модель Qwen3-VL, обеспечивающая понимание как визуальной информации (скриншотов интерфейса), так и текстовых инструкций. Qwen3-VL предварительно обучена на обширном наборе данных, включающем изображения и текст, что позволяет ей эффективно интерпретировать элементы графического пользовательского интерфейса (GUI) и их взаимосвязи. Данная способность к мультимодальному пониманию критически важна для выполнения задач автоматизации, поскольку позволяет агенту распознавать кнопки, поля ввода и другие интерактивные элементы, а также понимать контекст и назначение этих элементов, что необходимо для правильного взаимодействия с GUI.
В UI-Venus-1.5 для интеграции специализированных возможностей в единого агента применяются методы объединения моделей (Model Merging). Этот подход позволяет совместить различные экспертные модули, такие как распознавание элементов интерфейса, планирование действий и управление мышью/клавиатурой, в единую систему. Объединение моделей осуществляется путем взвешенного усреднения параметров предварительно обученных моделей, что позволяет получить агента с расширенной функциональностью и повышенной производительностью. Использование Model Merging позволяет избежать необходимости обучения единой, сложной модели с нуля, сокращая время разработки и требуемые вычислительные ресурсы.
Внедрение Знаний о GUI: Mid-Training и Визуализация
Предварительное обучение модели (Mid-Training) использует обширные наборы данных, содержащие информацию о графических пользовательских интерфейсах (GUI). Этот процесс позволяет модели изучить структуру и взаимосвязи между элементами GUI, такими как кнопки, поля ввода и меню. В ходе Mid-Training модель анализирует визуальные характеристики и семантическое значение этих элементов, что способствует формированию более эффективного представления GUI и повышает ее способность к обобщению при взаимодействии с новыми, ранее не встречавшимися интерфейсами. Данный подход позволяет значительно улучшить производительность модели в задачах автоматизации GUI и взаимодействия с приложениями.
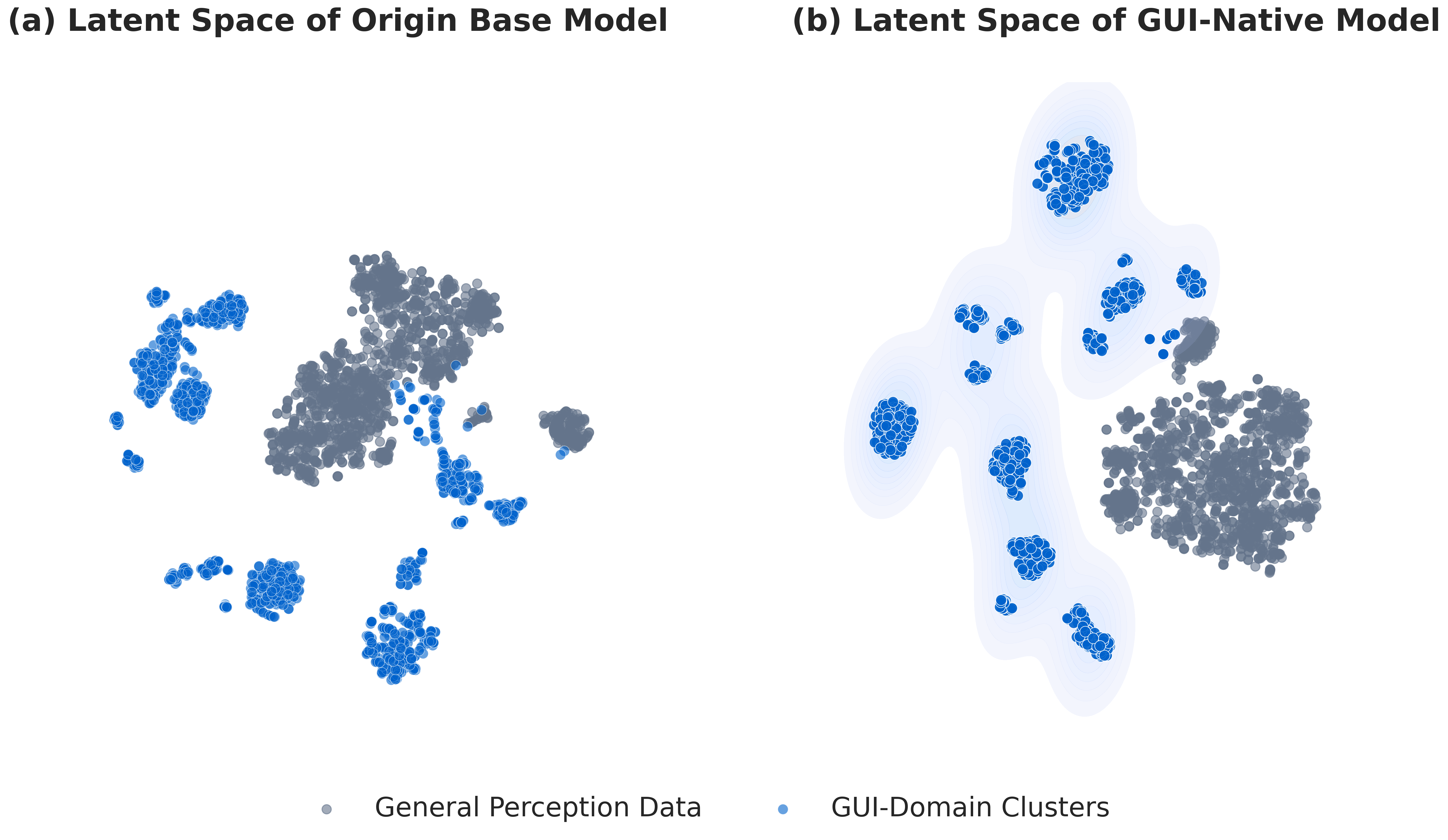
Влияние Mid-Training оценивается посредством визуализации T-SNE (t-distributed Stochastic Neighbor Embedding), позволяющей наглядно продемонстрировать улучшение представления признаков и кластеризацию данных. Метод T-SNE снижает размерность данных, сохраняя при этом локальные отношения между точками, что позволяет визуализировать высокоразмерные данные в двумерном или трехмерном пространстве. Анализ визуализаций T-SNE показывает, что после Mid-Training признаки, соответствующие различным элементам графического интерфейса, формируют более четкие и разделенные кластеры по сравнению с данными до Mid-Training, что свидетельствует об улучшении способности модели различать и понимать различные GUI-компоненты и их взаимосвязи. Данная визуализация подтверждает, что Mid-Training эффективно оптимизирует внутреннее представление признаков, улучшая обобщающую способность модели.
Чётко определенное пространство действий (Action Space) является критически важным для успешной работы агента в среде графического пользовательского интерфейса (GUI). Оно представляет собой полный набор допустимых операций, которые агент может выполнять, включая клики мышью, ввод текста, выбор элементов из меню и прочие взаимодействия. Объем и детализация этого пространства напрямую влияют на способность агента решать задачи в GUI — чем полнее и точнее определены доступные действия, тем более сложные и разнообразные задачи агент может выполнять. Ограниченное или неточно заданное пространство действий может привести к невозможности выполнения определенных задач или к неоптимальному поведению агента, даже если модель обладает достаточными знаниями о GUI.
Оптимизация Производительности: Offline-RL и GRPO
Обучение с подкреплением в автономном режиме (Offline-RL) предполагает использование статических наборов данных для тренировки агента, что позволяет ему совершенствовать навыки выполнения конкретных задач, связанных с графическим пользовательским интерфейсом (GUI). В отличие от традиционных методов обучения с подкреплением, требующих взаимодействия с окружением в реальном времени, Offline-RL позволяет агенту обучаться на заранее собранных данных, что повышает эффективность и позволяет избегать дорогостоящих или опасных экспериментов. Этот подход особенно полезен для автоматизации GUI-взаимодействий, где сбор данных может быть трудоемким, а ошибки — критичными. Обучение происходит путем анализа исторических данных о действиях пользователя и их последствиях, что позволяет агенту выявлять оптимальные стратегии для достижения заданных целей в GUI.
В рамках фазы обучения с использованием Offline-RL применяется алгоритм Group Relative Policy Optimization (GRPO) для ускорения процесса обучения. GRPO отличается от стандартных алгоритмов обучения с подкреплением тем, что он группирует схожие состояния и действия, позволяя агенту обобщать знания и быстрее адаптироваться к новым ситуациям. Это достигается за счет вычисления градиентов политики относительно групп состояний, что повышает эффективность обучения и снижает дисперсию оценок. Использование GRPO позволяет агенту быстрее достигать оптимальной политики на основе статического набора данных, избегая необходимости в интерактивном взаимодействии со средой во время обучения.
Агент продемонстрировал передовые результаты на сложных эталонных задачах, включая AndroidWorld, где достигнут показатель успешности в 77.6%, и ScreenSpot-Pro, где точность составила 69.6%. Эти показатели подтверждают высокую обобщающую способность агента, позволяющую эффективно решать задачи в различных, ранее не встречавшихся сценариях графического интерфейса. Достигнутые результаты превосходят существующие аналоги и свидетельствуют о надежности и универсальности разработанного подхода.
Динамическая Адаптация и За пределами: Влияние на Реальный Мир и Обработка Отказов
Обучение с подкреплением в режиме онлайн значительно расширяет возможности агента по навигации в графических пользовательских интерфейсах. Вместо статических данных, агент взаимодействует непосредственно с реальными GUI-средами, динамически адаптируясь к изменяющимся условиям и визуальным элементам. Такой подход позволяет агенту не просто запоминать последовательности действий, но и развивать навыки решения задач в новых, ранее не встречавшихся ситуациях. В процессе взаимодействия, агент оценивает результаты своих действий и корректирует стратегию, постепенно улучшая способность успешно ориентироваться и выполнять поставленные задачи в сложных графических средах. Это обеспечивает более гибкое и эффективное решение задач по сравнению с традиционными методами обучения, основанными на предопределенных наборах данных.
Система UI-Venus-1.5 демонстрирует выдающиеся способности к обработке задач отказа, корректно идентифицируя и отклоняя невыполнимые инструкции. Это достигается благодаря встроенному механизму оценки реализуемости запроса, позволяющему агенту избегать действий, которые привели бы к ошибкам или нежелательным последствиям в графическом интерфейсе. Способность к разумному отказу от выполнения невозможных задач является ключевым аспектом надежности и безопасности автономных агентов, взаимодействующих с реальными пользовательскими средами, и значительно повышает доверие к системе, поскольку она не пытается выполнить заведомо ошибочные команды.
Агент демонстрирует передовые показатели точности на различных эталонных наборах данных, включая VenusBench-GD (75.0%), OSWorld-G-R (76.4%) и WebVoyager (76.0%). Этот результат свидетельствует о высокой адаптивности и превосходстве системы в решении широкого спектра задач, связанных с взаимодействием с графическими пользовательскими интерфейсами. Способность агента достигать лучших в отрасли результатов на столь разнообразных платформах подтверждает его потенциал для практического применения в автоматизации рутинных операций и создании интеллектуальных помощников, способных эффективно работать в реальных пользовательских средах.
Исследование, представленное в отчете о UI-Venus-1.5, демонстрирует стремление к созданию действительно элегантных и надежных систем взаимодействия с графическим интерфейсом. Авторы подчеркивают важность сочетания различных подходов обучения с подкреплением — от обучения на исторических данных до онлайн-обучения — для достижения превосходных результатов. Этот подход напоминает о словах Фэй-Фэй Ли: «Искусственный интеллект должен быть разработан таким образом, чтобы он был полезен человечеству, а не просто технологически совершенен». В данном случае, стремление к высокой производительности UI-Venus-1.5 неразрывно связано с созданием полезного и интуитивно понятного цифрового помощника, где каждый алгоритм должен быть доказуемо корректен, а не просто «работать» на тестовых примерах. Доказательство корректности и надежности — вот та математическая чистота, к которой стремятся разработчики UI-Venus-1.5.
Куда Далее?
Представленная работа, безусловно, демонстрирует прогресс в создании агентов, взаимодействующих с графическим интерфейсом. Однако, необходимо признать, что достигнутое превосходство — это, скорее, результат кропотливой инженерии, нежели фундаментального прорыва. Сочетание методов обучения с подкреплением, как offline, так и online, а также слияние моделей — это, по сути, компромиссы, призванные обойти ограничения в объеме данных и вычислительных ресурсах. Элегантность решения, заключающаяся в его практической применимости, не отменяет необходимости поиска более принципиальных подходов.
Очевидным направлением дальнейших исследований является переход от эмпирических наблюдений к строгим математическим моделям. Вопрос о том, насколько хорошо современные многомодальные языковые модели действительно понимают интерфейс, а не просто имитируют взаимодействие, остается открытым. Необходимо разрабатывать методы верификации и доказательства корректности поведения агента, а не полагаться исключительно на тестовые сценарии.
В конечном счете, истинный прогресс будет достигнут, когда удастся создать агента, способного к генерализации — то есть, к адаптации к новым, ранее не встречавшимся интерфейсам и задачам, без необходимости переобучения. Пока же, каждое новое приложение потребует нового набора настроек и компромиссов, и это, к сожалению, закономерность, а не исключение.
Оригинал статьи: https://arxiv.org/pdf/2602.09082.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект на службе редких болезней
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Видео-Мыслитель: гармония разума и визуального потока.
- Плоские зоны: от теории к новым материалам
- Наука, управляемая интеллектом: новая эра открытий
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Квантовый Переворот: От Теории к Реальности
- Генерация без рисков: как избежать нарушения авторских прав при работе с языковыми моделями
2026-02-11 12:29