Автор: Денис Аветисян
В статье представлен обзор методов атрибуции, направленных на снижение количества недостоверной информации, выдаваемой системами генерации, использующими поиск релевантных знаний.
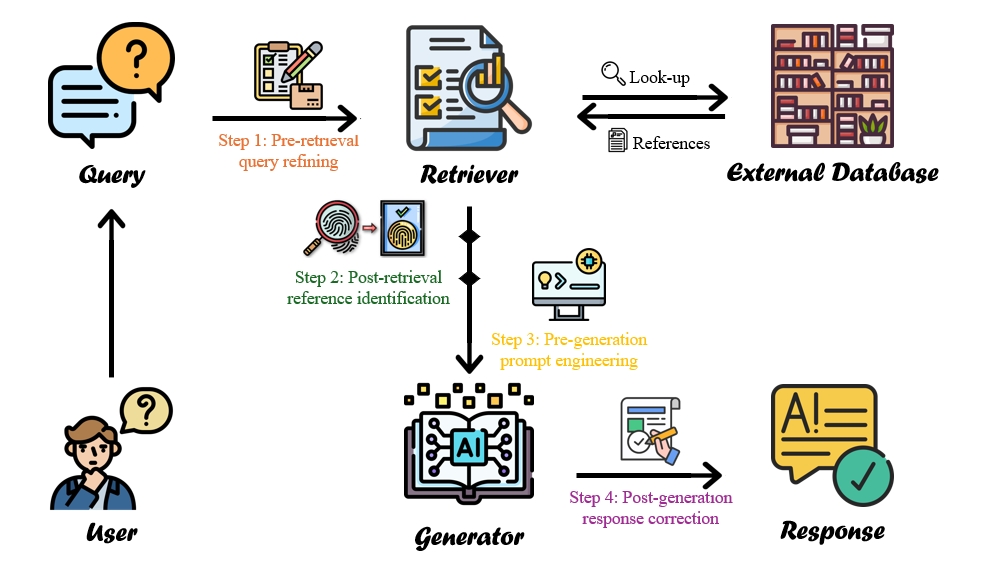
Обзор методов атрибуции для смягчения галлюцинаций в системах генерации с поиском, классификация типов галлюцинаций и предложение унифицированного подхода к улучшению.
Несмотря на впечатляющие успехи систем вопросно-ответного типа на основе больших языковых моделей, проблема галлюцинаций, то есть генерации недостоверной информации, остается актуальной. Данный обзор, озаглавленный ‘Attribution Techniques for Mitigating Hallucinated Information in RAG Systems: A Survey’, посвящен анализу методов атрибуции, направленных на снижение галлюцинаций в системах генерации с расширением извлечением (RAG). В работе предложена систематизация типов галлюцинаций, унифицированный пайплайн для техник атрибуции и сравнительный анализ их эффективности в зависимости от конкретных сценариев применения. Какие перспективы открываются для дальнейшего развития методов атрибуции и повышения надежности систем RAG в различных областях?
Иллюзия Знаний: Проблема Галлюцинаций в Больших Языковых Моделях
Современные большие языковые модели (БЯМ) демонстрируют впечатляющую способность к беглому и связному изложению, однако склонны к генерации фактических ошибок или утверждений, не подкрепленных достоверными источниками — этот феномен получил название “галлюцинации”. Несмотря на кажущуюся правдоподобность, ответы БЯМ могут содержать вымышленные детали, неверные даты или искаженные факты, что ставит под сомнение надежность и применимость этих систем в критически важных областях. Данная особенность связана не с недостатком данных, а с принципиальными ограничениями в способах обработки и интеграции знаний, а также с трудностями в логическом мышлении и проверке информации на соответствие реальности. Таким образом, хотя БЯМ и способны имитировать человеческую речь, важно помнить об их склонности к “галлюцинациям” и тщательно проверять достоверность предоставляемой ими информации.
Ненадежность больших языковых моделей (LLM) обусловлена фундаментальными ограничениями в процессах интеграции знаний и способности к логическому мышлению. Модели, демонстрирующие впечатляющую беглость речи, зачастую не способны достоверно сопоставлять информацию из различных источников или делать обоснованные выводы, что приводит к генерации фактических ошибок и несоответствий. Данный недостаток существенно подрывает доверие к результатам, предоставляемым LLM, и ограничивает их применимость в критически важных областях, где точность и надежность информации являются первостепенными. В конечном итоге, это препятствует широкому внедрению LLM в профессиональную практику и повседневную жизнь, поскольку пользователи опасаются столкнуться с недостоверными или вводящими в заблуждение ответами.
Несмотря на перспективность систем генерации с поиском (RAG), призванных снизить склонность больших языковых моделей к галлюцинациям, они часто сталкиваются с серьезными ограничениями. Одной из ключевых проблем является тенденция к подтверждению информации из единственного источника, что не позволяет модели критически оценивать данные и повышает риск генерации недостоверных утверждений. Более того, RAG-системы испытывают трудности при обработке длинных контекстов, теряя релевантную информацию и ухудшая качество ответов по мере увеличения объема входных данных. Это усугубляет проблему галлюцинаций, поскольку модель может упустить важные детали или неправильно интерпретировать информацию, что в конечном итоге приводит к генерации неточных или вводящих в заблуждение ответов.
Единый Конвейер для Обоснованной Генерации
Предлагаемый ‘Унифицированный конвейер’ представляет собой интегрированный подход к снижению галлюцинаций в задачах генерации текста, объединяя четыре ключевые техники: уточнение запросов (Query Refining), идентификацию релевантных источников (Reference Identification), проектирование промптов (Prompt Engineering) и постобработку ответов (Response Correction). Данный конвейер не только объединяет существующие методы, но и предоставляет всесторонний обзор и таксономию атрибутивных техник, позволяя систематизировать и анализировать подходы, направленные на обеспечение фактической достоверности генерируемого контента. В рамках данного подхода, каждая техника выполняет определенную функцию в процессе генерации, совместно обеспечивая снижение вероятности появления ложной или недостоверной информации.
Процесс уточнения запроса (Query Refining) направлен на повышение точности поиска релевантных источников информации. Этот этап включает в себя переформулировку исходного запроса с целью улучшения соответствия между запросом и содержанием доступных документов. Одновременно, идентификация референсов (Reference Identification) фокусируется на отборе наиболее достоверных и авторитетных источников из числа найденных. При этом используются различные метрики, такие как цитируемость, репутация автора и дата публикации, для оценки надежности каждого источника и последующего выбора наиболее подходящих для генерации ответа.
Метод разработки промптов (Prompt Engineering) направлен на создание входных запросов, стимулирующих генерацию ответов, основанных на предоставленных источниках, что снижает вероятность галлюцинаций. В то время как разработка промптов фокусируется на превентивных мерах, этап коррекции ответов (Response Correction) применяет постобработку с целью выявления и устранения фактических неточностей в уже сгенерированном тексте. Этот подход позволяет повысить надежность и достоверность сгенерированной информации за счет комбинации предварительной настройки входных данных и последующего контроля качества выходных данных.
Разбирая Типы Галлюцинаций и Нацеленная Минимизация
Для более точной диагностики и последующей коррекции галлюцинаций в больших языковых моделях (LLM) выделяют несколько основных типов. Недостаточность рассуждений (Reasoning Deficiency) проявляется в логических ошибках и неспособности делать корректные выводы из представленных данных. Несогласованность контекста (Context Inconsistency) возникает, когда ответ противоречит ранее предоставленной информации или внутреннему состоянию модели. Устарелость (Outdatedness) характеризуется использованием неактуальных или неверных данных, что особенно актуально для моделей, обучавшихся на данных с ограниченным сроком действия. Наконец, непроверяемость (Unverifiability) относится к утверждениям, которые невозможно подтвердить или опровергнуть, используя доступные источники информации. Каждый из этих типов требует специфического подхода к диагностике и минимизации.
Наша система обработки данных напрямую решает проблемы устаревания информации и несогласованности контекста. Для борьбы с устареванием используются уточненные поисковые запросы и надежные источники информации, позволяющие получать актуальные данные. Несогласованность контекста и нефальсифицируемость минимизируются за счет тщательной разработки запросов и последующей коррекции ответов, что обеспечивает логическую связность и проверяемость генерируемого текста.
Для снижения вероятности галлюцинаций, вызванных излишней уверенностью модели, применяется метод калибровки вербальной неопределенности. Данный подход заключается в добавлении в запросы элементов, выражающих неуверенность или предположение (например, “возможно”, “вероятно”, “по оценкам”), что позволяет согласовать уровень уверенности модели в ответе с надежностью используемых справочных материалов. Фактически, это снижение вероятности выдачи категоричных утверждений, не подкрепленных достаточными доказательствами из релевантных источников, и повышение вероятности предоставления более взвешенных и обоснованных ответов.
К Доверию к Искусственному Интеллекту: Последствия и Перспективы
Разработанный унифицированный конвейер значительно повышает надежность больших языковых моделей (LLM) за счет снижения склонности к галлюцинациям — генерации неверной или бессмысленной информации. Этот подход особенно важен для приложений, требующих высокой точности, таких как системы ответов на вопросы и диалоговые агенты, где предоставление ложных сведений может привести к серьезным последствиям. Уменьшение галлюцинаций достигается за счет комплексной обработки входных данных и более тщательной проверки генерируемых ответов, что позволяет LLM выдавать более правдоподобные и обоснованные результаты в различных областях применения, тем самым укрепляя доверие пользователей к этим технологиям.
Предлагаемый подход выходит за рамки простого извлечения фактов, стремясь к более тонкому пониманию знаний и признанию их границ. Вместо слепого воспроизведения информации, система способна оценивать достоверность и применимость данных, что позволяет ей избегать необоснованных утверждений и предоставлять более надежные ответы. Такой подход к обработке информации принципиально важен для формирования доверия пользователей к искусственному интеллекту, поскольку демонстрирует осознание системой собственной неполноты знаний и готовность признавать ограничения. В результате, взаимодействие с системой становится более предсказуемым и прозрачным, а ее ответы — более обоснованными и заслуживающими доверия.
В дальнейшем планируется расширение разработанного подхода на мультимодальные контексты, то есть на ситуации, когда информация поступает из различных источников, таких как текст, изображения и звук. Исследователи стремятся создать систему, способную не только обрабатывать информацию из разных каналов, но и выявлять несоответствия и галлюцинации, возникающие при объединении данных. Особое внимание будет уделено разработке автоматизированных методов обнаружения и исправления этих ошибок, что позволит значительно повысить надежность и достоверность работы искусственного интеллекта в различных областях применения, от обработки естественного языка до анализа визуальной информации.
Исследование методов атрибуции для снижения галлюцинаций в системах RAG демонстрирует стремление к структурной честности в обработке информации. Как отмечает Винтон Серф: «Интернет — это великий уравнитель, но он также и великий исказитель». Предложенный единый конвейер для улучшения RAG систем, направленный на выявление и устранение причин возникновения галлюцинаций в процессе извлечения и генерации знаний, отражает понимание сложности современных систем искусственного интеллекта. Четкость и лаконичность в определении типов галлюцинаций и методов их устранения — признак хорошо продуманного подхода к решению проблемы, где каждое слово имеет значение.
Что дальше?
Представленный обзор, стремясь к компрессии шума в системах генерации, дополненной поиском, неизбежно обнажил более глубокую проблему. Иллюзии — это не ошибка алгоритма, а симптом избыточности. Попытки атрибуции, хоть и полезны, лишь маскируют фундаментальную сложность: необходимость в избыточном объеме знаний для производства даже элементарной правды. Устранение галлюцинаций через более точный поиск и генерацию — это лишь временное облегчение, а не излечение.
Будущие исследования должны сместить фокус с симптомов на причину. Вместо того, чтобы бороться с иллюзиями, необходимо задаться вопросом: возможно ли вообще построить систему, которая не нуждается в «галлюцинациях» как в способе заполнения пробелов в знаниях? Вероятно, истинный прогресс лежит не в улучшении существующих моделей, а в разработке принципиально новых архитектур, где знание не является просто данными, а структурированным, проверяемым и самодостаточным.
Предлагаемая унифицированная схема улучшения — это лишь первый шаг. Реальная задача — не создание более совершенного инструмента, а осознание границ его применимости. Иллюзии, в конечном счете, являются напоминанием о том, что любое упрощение — это всегда потеря информации. И иногда, самое мудрое решение — признать эту потерю и отказаться от иллюзии совершенства.
Оригинал статьи: https://arxiv.org/pdf/2601.19927.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-30 05:52