Автор: Денис Аветисян
В статье представлен обзор стремительно развивающейся области автономных систем на базе больших языковых моделей, способных надежно выполнять сложные задачи.
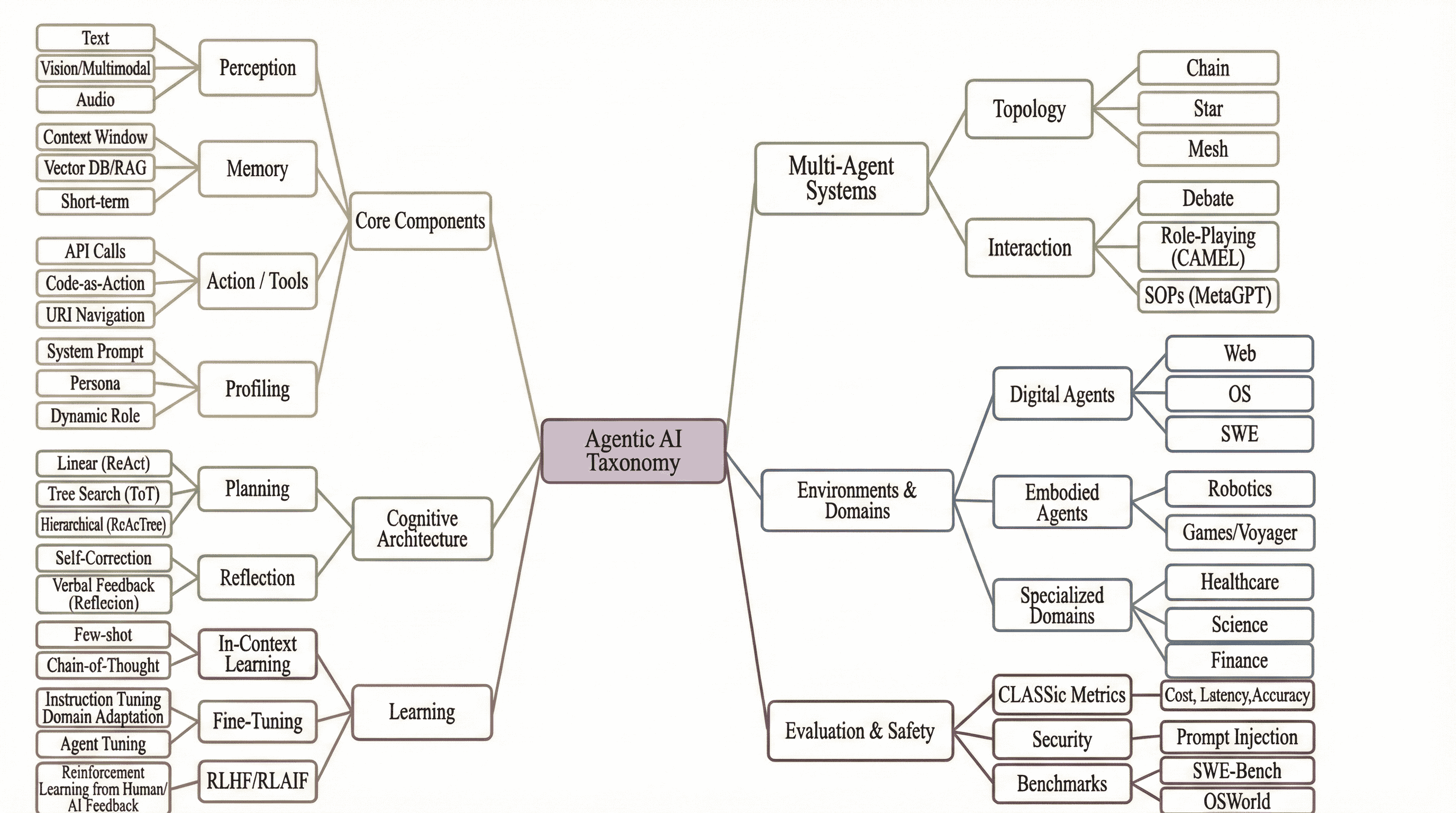
Обзор архитектур, таксономий и методов оценки агентов искусственного интеллекта, использующих большие языковые модели для оркестровки рабочих процессов и решения проблем.
Традиционные модели искусственного интеллекта все чаще оказываются недостаточными для решения комплексных задач, требующих автономного планирования и действий. В данной работе, ‘Agentic Artificial Intelligence (AI): Architectures, Taxonomies, and Evaluation of Large Language Model Agents’, проводится всесторонний анализ архитектур, таксономий и методов оценки агентов искусственного интеллекта, основанных на больших языковых моделях. Предлагается унифицированная классификация агентов, включающая восприятие, планирование, действия и использование инструментов, что позволяет систематизировать быстро развивающееся поле исследований. Какие новые вызовы и возможности возникают при создании надежных и эффективных автономных систем, способных к сложным взаимодействиям и решению реальных задач?
За гранью разговоров: Эволюция автономных агентов
Традиционные большие языковые модели демонстрируют впечатляющую способность к генерации текста, однако сталкиваются с серьезными трудностями при решении задач, требующих последовательного, многошагового рассуждения. В то время как они превосходно справляются с предсказанием следующего слова или фразы, их возможности по планированию, анализу сложных ситуаций и выполнению задач, состоящих из нескольких этапов, ограничены. Эта неспособность к комплексному мышлению приводит к тому, что модели часто допускают ошибки при решении задач, требующих логического вывода или адаптации к изменяющимся условиям, подчеркивая необходимость разработки принципиально новых подходов к искусственному интеллекту.
Искусственный интеллект переживает фундаментальный сдвиг, уходя от простого ведения диалога к активному решению задач и автономным действиям. Вместо пассивного ответа на запросы, агенты ИИ теперь способны самостоятельно планировать и выполнять сложные последовательности действий для достижения поставленных целей. Этот переход предполагает не просто генерацию текста, а способность к рассуждению, адаптации к меняющимся условиям и использованию различных инструментов для достижения результата. В отличие от традиционных моделей, ориентированных на предсказание следующего слова, агенты ИИ стремятся к активному взаимодействию с окружающей средой и решению практических задач, открывая новые горизонты для автоматизации и интеллектуальных систем.
Переход к автономным агентам требует от систем умения не просто генерировать текст, но и активно взаимодействовать с окружением, используя различные инструменты для достижения поставленных целей. Исследования показывают, что даже в простых, одношаговых задачах, успех таких агентов составляет лишь 47%. С увеличением сложности и длительности задач, требующих последовательного выполнения множества действий, этот показатель резко снижается до 11%. Это свидетельствует о существенных трудностях в разработке систем, способных к надежному планированию, адаптации к меняющимся условиям и эффективному использованию доступных ресурсов для решения комплексных проблем.
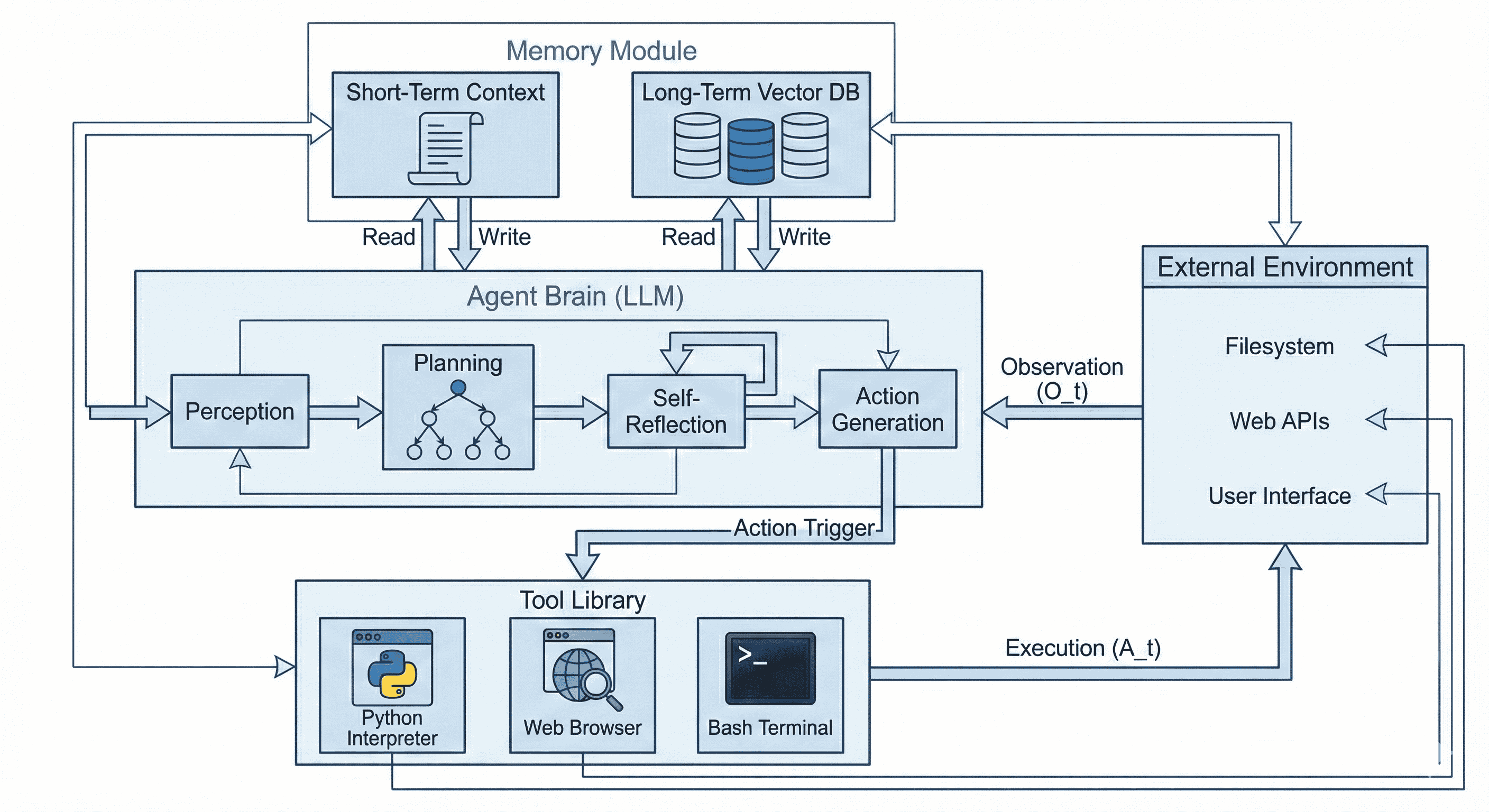
Оркестровка интеллекта: Многоагентные системы
Многоагентные системы (МАС) представляют собой эффективный подход к решению сложных задач путем распределения функциональности между специализированными агентами. Вместо монолитной структуры, где единый компонент отвечает за все аспекты проблемы, МАС декомпозируют задачу на более мелкие, независимые подзадачи, каждая из которых решается отдельным агентом. Такая архитектура позволяет добиться параллельной обработки, повышения масштабируемости и отказоустойчивости, поскольку выход из строя одного агента не обязательно приводит к полной остановке системы. Специализация агентов обеспечивает более эффективное использование ресурсов и упрощает разработку и отладку отдельных компонентов, что в конечном итоге способствует повышению общей производительности системы.
Различные топологии взаимодействия в многоагентных системах (МАС) оказывают существенное влияние на эффективность коммуникации и общую устойчивость системы. В топологии “цепочка” информация передается последовательно от агента к агенту, что может приводить к задержкам и уязвимости к сбоям отдельных узлов. В “звезде” все агенты взаимодействуют через центральный узел, обеспечивая быстрый обмен данными, но создавая единую точку отказа. Топология “сетка”, напротив, обеспечивает высокую надежность за счет множественных путей связи между агентами, однако требует значительных коммуникационных ресурсов. Выбор оптимальной топологии зависит от конкретной задачи и требований к производительности и отказоустойчивости МАС.
Эффективность многоагентных систем (MAS) напрямую зависит от организации взаимодействия между агентами. Ключевым фактором является создание структуры, способствующей сотрудничеству и предотвращающей возникновение узких мест в коммуникации. Оптимизация взаимодействий позволяет агентам использовать коллективный интеллект для решения сложных задач. В частности, методика CoAct продемонстрировала повышение успешности выполнения задач на 60.76% за счет улучшения координации между агентами и минимизации задержек в обмене информацией.
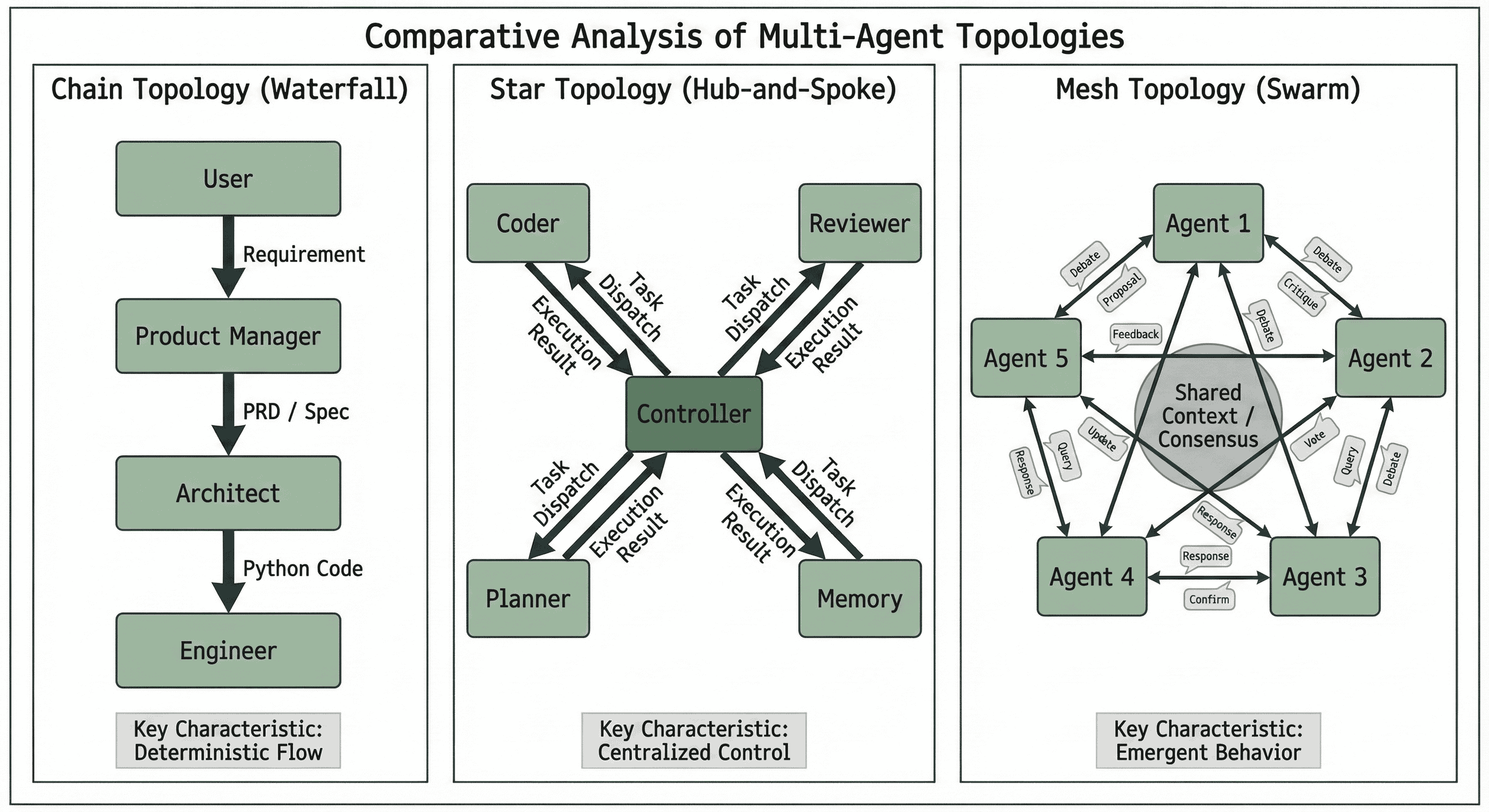
Рассуждения и валидация: Построение надежных агентов
Методы ReAct и Tree of Thoughts расширяют возможности рассуждений больших языковых моделей (LLM) за счет чередования действий и рефлексивных мыслительных процессов. ReAct (Reason + Act) предполагает, что агент генерирует как рассуждения, так и действия, используя наблюдения для корректировки дальнейших шагов. Tree of Thoughts (ToT) идет дальше, позволяя модели исследовать несколько путей рассуждений, оценивая различные варианты действий и выбирая наиболее перспективные. В отличие от традиционных подходов, где LLM генерируют действия непосредственно из входных данных, эти методы обеспечивают итеративный процесс, позволяющий модели анализировать промежуточные результаты, выявлять ошибки и корректировать стратегию, что повышает надежность и точность принимаемых решений.
Риск возникновения “галлюцинаций в действиях” (Hallucination in Action) в агентах, основанных на больших языковых моделях, требует применения методов валидации перед выполнением действий. Технология Self-CheckGPT представляет собой один из подходов, заключающийся в проверке последовательности рассуждений агента на каждом этапе. Этот процесс включает в себя генерацию альтернативных цепочек рассуждений и сравнение их с первоначальной, с целью выявления потенциальных ошибок или несоответствий. Если обнаружены расхождения, система может запросить дополнительную информацию или пересмотреть свой план действий, минимизируя вероятность выполнения ошибочных или нежелательных действий. Валидация с использованием Self-CheckGPT повышает надежность и предсказуемость поведения агента, особенно в критически важных приложениях.
Конституционный ИИ представляет собой структуру для согласования поведения агента с человеческими ценностями и этическими принципами, способствуя ответственному развитию ИИ. Данный подход позволяет задать набор принципов, которым агент должен следовать при принятии решений и выполнении действий. Параллельно, методы дистилляции знаний позволяют значительно сократить количество параметров модели — до 100 раз — без существенной потери производительности. Это достигается путем обучения компактной модели имитировать поведение более крупной и сложной модели, что делает возможным развертывание агентов на устройствах с ограниченными ресурсами, таких как периферийные устройства и мобильные платформы.
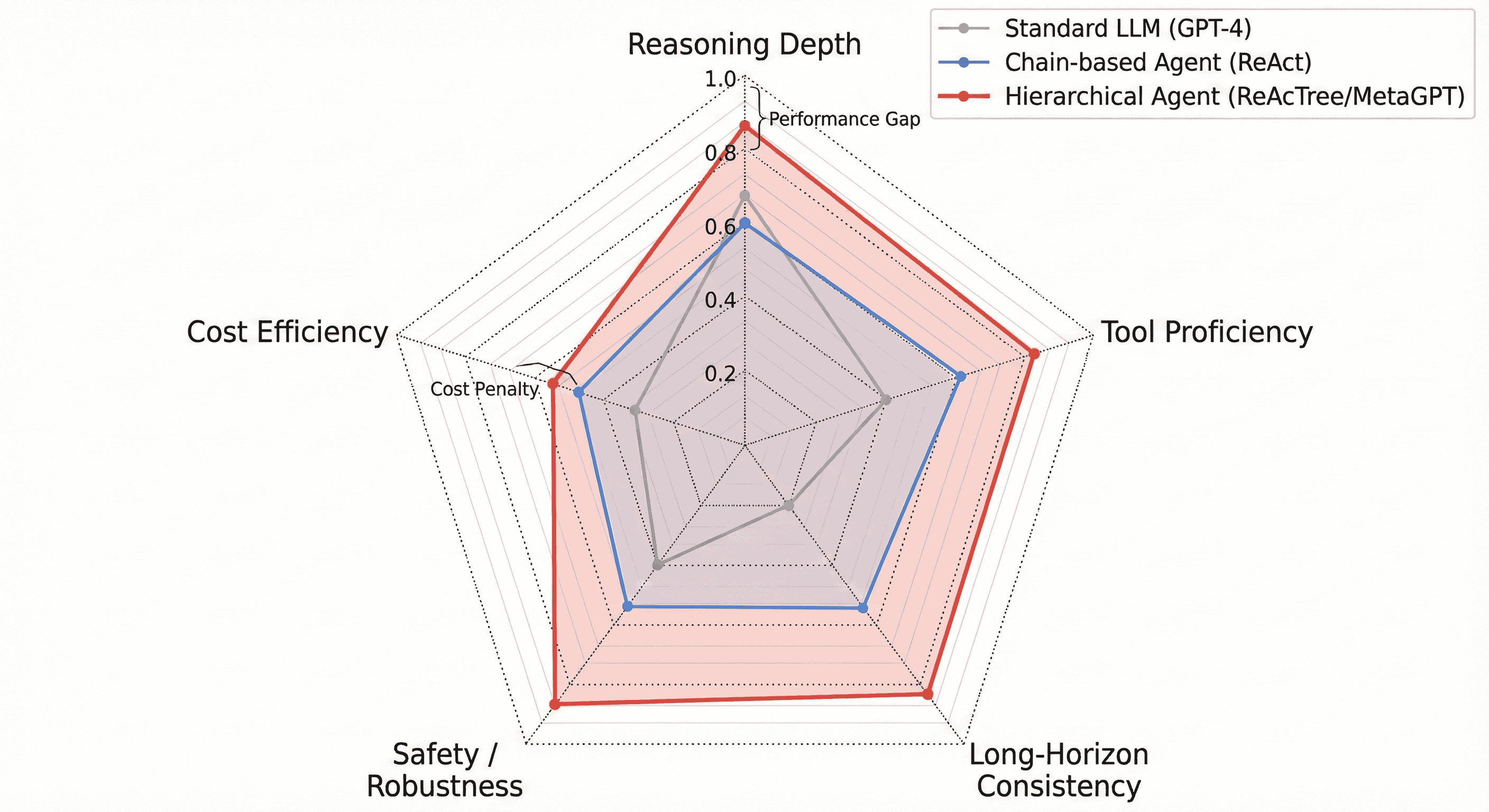
Эталоны и фреймворки: Развивая границы возможного
Для объективной оценки возможностей искусственного интеллекта и сравнения различных агентов, всё большее значение приобретают стандартизированные тестовые среды. Платформы, такие как WebArena, OSWorld и SWE-Bench, предоставляют унифицированные условия для выполнения широкого спектра задач — от навигации в интернете и взаимодействия с операционными системами до разработки программного обеспечения. Эти бенчмарки позволяют исследователям и разработчикам не просто констатировать успешность или неудачу агента, но и количественно оценить его производительность по конкретным показателям, выявляя сильные и слабые стороны. Такой подход способствует более целенаправленному развитию ИИ и позволяет сравнивать различные модели и алгоритмы в честных и воспроизводимых условиях, ускоряя прогресс в области автономных систем.
Разработка многоагентных систем значительно упрощается благодаря специализированным фреймворкам, таким как LangGraph, MetaGPT и AutoGen. Эти инструменты предоставляют разработчикам готовые компоненты и модули, позволяющие избежать рутинной работы по созданию базовой инфраструктуры. LangGraph, например, облегчает построение сложных рабочих процессов, а MetaGPT предлагает возможность моделирования различных ролей и задач, что способствует более реалистичному взаимодействию агентов. AutoGen, в свою очередь, автоматизирует процесс разработки и тестирования, позволяя быстро создавать и развертывать многоагентные решения. Использование таких фреймворков не только ускоряет разработку, но и повышает надежность и масштабируемость создаваемых систем, открывая новые возможности для решения сложных задач в различных областях.
Развитие многоагентных систем всё чаще опирается на методы, имитирующие сложные человеческие взаимодействия. Проекты CAMEL и MAKER внедряют принципы ролевой игры и перекрестного допроса, позволяя агентам не просто решать задачи, но и взаимодействовать друг с другом, как это происходит в реальных коллективах. Этот подход способствует развитию более сложных стратегий и повышает адаптивность системы. Важно отметить, что оценка надежности агентов выходит за рамки простого подсчета успешных попыток. Всё больше внимания уделяется анализу режимов отказа — выявлению и количественной оценке сценариев, в которых агенты демонстрируют ошибки или неэффективность. Такой подход позволяет выявлять слабые места системы и разрабатывать более устойчивые и предсказуемые решения.
Будущее агентных систем: К общему интеллекту
Сочетание многоагентных систем, передовых методов рассуждений и строгой системы оценки результатов неуклонно ускоряет прогресс в направлении достижения искусственного общего интеллекта. Ранее разрозненные области исследований — координация множества автономных агентов, развитие сложных алгоритмов логического вывода и создание объективных критериев оценки интеллектуальных способностей — теперь конвергируют, создавая синергетический эффект. Такой подход позволяет создавать системы, способные решать широкий спектр задач, адаптироваться к новым ситуациям и обучаться на собственном опыте, приближая возможность создания искусственного интеллекта, сравнимого с человеческим.
Современные платформы, такие как Swarm и RAP, предоставляют исследователям и разработчикам беспрецедентные возможности для масштабирования и координации больших групп автономных агентов. Swarm, благодаря своей модульной архитектуре и акценту на децентрализованное управление, позволяет создавать сложные системы, где взаимодействие между агентами приводит к возникновению коллективного интеллекта. RAP (Robust Agent Platform) фокусируется на обеспечении надежности и предсказуемости поведения агентов, что особенно важно при решении критически важных задач. Эти инструменты не просто облегчают разработку многоагентных систем, но и открывают путь к созданию более сложных и адаптивных решений, приближая нас к реализации концепции общего искусственного интеллекта, способного решать широкий спектр задач, подобно человеческому разуму.
Дальнейшие исследования в области надежных методов валидации и этических рамок представляются критически важными для ответственного внедрения агентных систем. Разработка таких инструментов позволит не только подтвердить безопасность и предсказуемость поведения этих сложных систем, но и гарантировать соответствие их действий общепринятым моральным и правовым нормам. Особое внимание уделяется созданию механизмов, способных выявлять и предотвращать непредвиденные последствия, а также обеспечивать прозрачность и объяснимость принимаемых агентами решений. Именно строгий контроль и учет этических аспектов станут залогом того, что развитие агентных систем принесет пользу человечеству, а не создаст новые риски и угрозы.
Исследование архитектур Agentic AI, представленное в статье, напоминает процесс деконструкции сложного механизма. Авторы тщательно разбирают принципы работы автономных систем, основанных на больших языковых моделях, выявляя ключевые компоненты и потенциальные уязвимости. В этом контексте, слова Кena Thompson’а: «Вы должны думать о вещах, которые вы можете изменить, а не о том, что вы не можете». — особенно актуальны. Ведь именно способность модифицировать и улучшать систему, выявлять и устранять недостатки, лежит в основе прогресса в области создания надежных и эффективных Agentic AI. Особое внимание к оркестровке рабочих процессов и смягчению галлюцинаций демонстрирует стремление к созданию систем, способных к адаптации и самокоррекции.
Что дальше?
Представленный обзор, констатируя текущий ландшафт агентов, основанных на больших языковых моделях, лишь подчеркивает глубину нерешенных вопросов. Если предположить, что кажущаяся «интеллектуальность» этих систем — не более чем статистическая иллюзия, то настоящая проверка ждет в ситуациях, требующих не просто манипулирования символами, а понимания причинно-следственных связей. Что произойдет, если задача потребует выйти за рамки предопределенных инструментов, импровизировать, осознанно нарушать правила, чтобы достичь цели? Подобные сценарии обнажат хрупкость архитектур, основанных на «галлюцинациях» и статистической вероятности.
Очевидно, что переход от простых рабочих процессов к настоящей кооперации в многоагентных системах требует не только обмена данными, но и способности к мета-рассуждению — способности оценивать действия других агентов, предвидеть их последствия и адаптировать собственную стратегию. Если текущие модели рассматривают инструменты как внешние объекты, то будущее — за созданием агентов, способных создавать и модифицировать эти инструменты, подстраивая их под изменяющиеся обстоятельства. Другими словами, необходимо перейти от использования инструментов к их изобретению.
И, наконец, стоит задуматься о природе «агентности» как таковой. Если агенты лишь имитируют разумное поведение, следуя заложенным алгоритмам, то где проходит грань между автоматизацией и истинным интеллектом? Что произойдет, если агенты начнут ставить под сомнение сами цели, которые перед ними поставлены? Ответ на этот вопрос, возможно, и станет настоящим вызовом для исследователей в ближайшие годы.
Оригинал статьи: https://arxiv.org/pdf/2601.12560.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые прорывы: Хорошее, плохое и смешное
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2026-01-22 04:20