Автор: Денис Аветисян
Исследователи разработали метод создания специализированных языковых моделей, способных генерировать исполняемый код для сложных инженерных задач, даже при ограниченном объеме данных.

Предложена схема выравнивания, основанная на Direct Preference Optimization (DPO), для построения доменно-специфичных языковых моделей, демонстрируемая на примере модели TcadGPT для TCAD-симуляций.
Несмотря на растущий интерес к большим языковым моделям, их применение в специализированных инженерных областях часто затруднено из-за нехватки данных и строгих требований к исполняемости генерируемого кода. В работе, озаглавленной ‘A Generalizable Framework for Building Executable Domain-Specific LLMs under Data Scarcity: Demonstration on Semiconductor TCAD Simulation’, предложен новый подход к созданию компактных, исполняемых доменно-специфичных LLM в условиях ограниченных ресурсов. Ключевым элементом является схема-ориентированное выравнивание с использованием Direct Preference Optimization (DPO), позволившие модели TcadGPT достичь 85.6% семантической точности и 80.0% успеха в синтаксической проверке для задач моделирования полупроводников. Возможно ли масштабирование данного подхода для других профессиональных областей, где критичны как точность, так и исполняемость генерируемого кода?
Предел Теории: TCAD и Проблемы Автоматизации
Технологический компьютерный дизайн (TCAD) играет фундаментальную роль в современной полупроводниковой промышленности, являясь ключевым инструментом для разработки и оптимизации микроэлектронных устройств. Однако, его эффективность напрямую зависит от сложных численных симуляций, требующих глубоких знаний физики процессов и значительного опыта от инженеров-разработчиков. TCAD позволяет моделировать поведение электронов и других частиц в полупроводниках, предсказывать характеристики будущих устройств и выявлять потенциальные проблемы на ранних стадиях проектирования. Этот процесс требует не только мощных вычислительных ресурсов, но и детального понимания влияния различных параметров технологического процесса на конечные характеристики чипа, что делает TCAD сложной и ресурсоемкой задачей, требующей высокой квалификации специалистов.
Современные методы технологического компьютерного проектирования (TCAD) сталкиваются с растущими трудностями, обусловленными экспоненциальным увеличением сложности конструкций полупроводниковых приборов. Проектирование новых поколений транзисторов и микросхем требует моделирования всё более сложных физических процессов и геометрических форм, что приводит к значительному увеличению вычислительных затрат и времени моделирования. К тому же, существенным препятствием является нехватка размеченных данных для обучения алгоритмов машинного обучения, необходимых для автоматизации процесса проектирования. Создание качественных обучающих выборок требует проведения большого количества дорогостоящих и трудоемких симуляций, а доступ к экспертным знаниям в области TCAD ограничен, что существенно замедляет прогресс в автоматизации и оптимизации полупроводниковых устройств.
Автоматизация рабочих процессов в технологическом компьютерном проектировании (TCAD) сталкивается с существенной проблемой: необходимостью преобразования человеческого намерения, выраженного на естественном языке, в конкретные, исполняемые скрипты симуляции. Это требует создания интеллектуальных систем, способных понимать сложные запросы, сформулированные инженером, и транслировать их в последовательность команд, управляющих симуляцией полупроводниковых приборов. Успешное решение этой задачи позволит значительно ускорить процесс разработки новых устройств, снизить зависимость от узкоспециализированных экспертов и открыть путь к более эффективному исследованию пространства параметров проектирования. Преодоление разрыва между лингвистическим описанием и вычислительным исполнением является ключевым шагом к созданию интеллектуальных систем TCAD, способных к автономной оптимизации и инновациям.
TcadGPT: LLM для Автоматизации Полупроводникового Моделирования
TcadGPT представляет собой большую языковую модель (LLM), специально обученную для интерпретации запросов на естественном языке и генерации исполняемых скриптов для технологического моделирования полупроводниковых приборов (TCAD). В процессе обучения модель анализировала обширный корпус данных, включающий как текстовые описания задач моделирования, так и соответствующие скрипты, написанные на языках, используемых в TCAD-симуляторах. Это позволяет TcadGPT преобразовывать пользовательские инструкции, сформулированные обычным языком, в структурированный код, готовый к выполнению в среде моделирования. Особенностью является способность модели понимать контекст и специфические требования к моделируемому устройству или процессу, что обеспечивает создание точных и эффективных скриптов.
Модель TcadGPT использует подход Retrieval-Augmented Generation (RAG) для генерации скриптов. В процессе создания скрипта, RAG позволяет модели обращаться к релевантной базе знаний, извлекать необходимую информацию и интегрировать её в генерируемый код. Это достигается путем поиска наиболее подходящих фрагментов информации, соответствующих запросу пользователя, и использования их в качестве контекста для формирования скрипта. Применение RAG значительно повышает точность и релевантность генерируемых скриптов, особенно в сложных задачах, требующих специфических знаний о технологических процессах и физических моделях.
Интеграция TcadGPT с открытыми конечно-элементными решателями, такими как Elmer, значительно расширяет доступ к передовым инструментам моделирования полупроводников. Традиционно, использование коммерческих TCAD-пакетов требовало значительных финансовых вложений и специализированных навыков. TcadGPT, используя возможности Elmer и других open-source решений, позволяет пользователям создавать и выполнять сложные симуляции, опираясь на естественный язык для описания задачи. Это снижает барьер входа для исследователей, малых предприятий и студентов, не имеющих доступа к дорогостоящему программному обеспечению и экспертам в области моделирования, что способствует более широкому распространению инноваций в микроэлектронике.
Увеличение Охвата Данных: QA-Синтез и Schema-First Подход
Для решения проблемы нехватки данных мы используем метод QA-синтеза, который автоматически генерирует обучающие данные на основе существующей экспертной документации. Этот процесс включает в себя извлечение вопросов и ответов из документации, что позволяет создавать новые примеры для обучения модели без необходимости ручной аннотации. Использование QA-синтеза позволяет существенно увеличить размер обучающей выборки, что потенциально улучшает обобщающую способность модели и её производительность в условиях ограниченных данных. Метод позволяет эффективно использовать имеющиеся знания, представленные в документации, для создания структурированного набора данных, пригодного для обучения моделей обработки естественного языка.
Процесс синтеза данных позволяет значительно расширить обучающую выборку модели без необходимости ручной разметки. Генерируемые синтетические данные, полученные из существующей экспертной документации, служат дополнительным источником информации для обучения, что особенно важно при ограниченном объеме размеченных данных. Это позволяет снизить затраты на создание обучающего набора и ускорить процесс разработки, сохраняя при этом качество и точность модели. Использование автоматизированных методов генерации данных позволяет масштабировать процесс обучения и адаптировать модель к новым задачам и доменам без привлечения дополнительных ресурсов на аннотацию.
В домене Elmer, в ходе тестирования метода синтеза данных для обучения, была достигнута точность ответов на вопросы (QA accuracy) в 52 из 100. Данный показатель демонстрирует эффективность предложенного подхода к автоматической генерации обучающих данных из существующей экспертной документации, позволяя расширить набор данных для обучения модели без ручной аннотации и повысить её производительность в целевой области.
В процессе обучения модели используется фреймворк Schema-First Alignment, который обеспечивает структурную целостность и надежность генерируемых TCAD-скриптов. Данный подход предполагает предварительное определение и валидацию схемы TCAD-скриптов, что позволяет гарантировать соответствие сгенерированного кода установленным стандартам и избежать синтаксических ошибок. Приоритет структурной целостности достигается за счет жесткого контроля синтаксиса и семантики генерируемых скриптов, что повышает их надежность и предсказуемость при выполнении симуляций. Такой подход особенно важен для обеспечения воспроизводимости результатов и минимизации ошибок, связанных с некорректным форматом или структурой TCAD-скриптов.
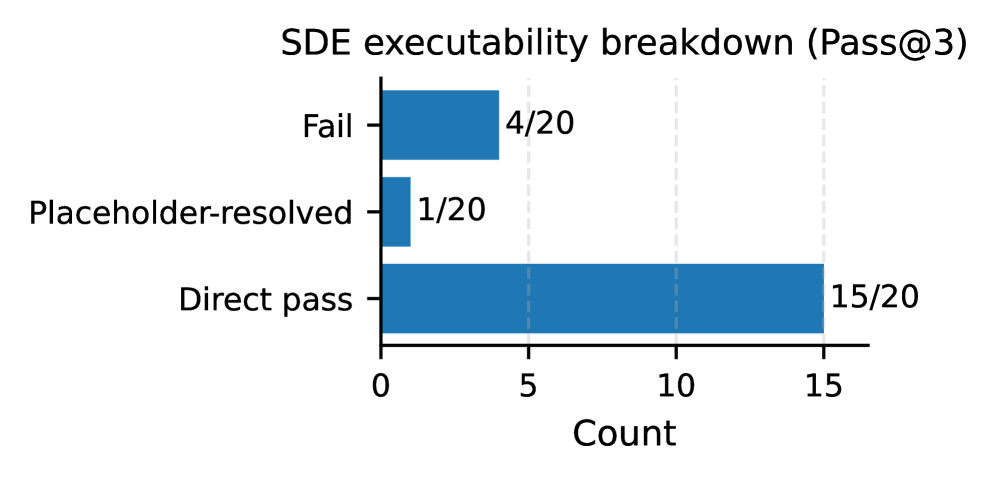
IR→DPO Выравнивание: Уточнение Следования Инструкциям и Валидности Кода
Процесс IR→DPO Alignment преобразует исходные файлы TCAD-деков в промежуточное представление (Intermediate Representation, IR). Это преобразование играет ключевую роль в создании разнообразных сценариев обучения модели. Перевод в IR позволяет абстрагироваться от конкретного синтаксиса и структуры исходных файлов, что открывает возможности для генерации и анализа широкого спектра TCAD-кода. Благодаря этому, модель способна обучаться на различных вариантах инструкций и входных данных, значительно повышая свою обобщающую способность и устойчивость к вариациям в формате TCAD-деков. Такой подход позволяет модели не просто запоминать конкретные примеры, но и понимать логику и принципы построения TCAD-скриптов, что необходимо для успешного выполнения сложных задач.
Прямая оптимизация предпочтений (DPO) была применена для точной настройки модели, направленной на формирование желаемого поведения при генерации кода. Этот метод позволяет модели не просто выдавать синтаксически корректные скрипты, но и обеспечивать логическую последовательность операций, необходимую для успешного моделирования. В процессе обучения DPO модель получает обратную связь, основанную на предпочтениях — она учится различать желательные результаты (правильный синтаксис и логический поток симуляции) от нежелательных. Благодаря этому, модель постепенно адаптирует свои параметры, чтобы с высокой вероятностью генерировать валидный и функциональный код, способный успешно выполняться в среде TCAD, что существенно повышает эффективность автоматизированного проектирования.
Комбинация подходов, включающая промежуточное представление (IR) и оптимизацию предпочтений (DPO), продемонстрировала впечатляющие результаты в генерации корректных TCAD-скриптов. В ходе тестирования достигнута 80.0%-ная успешность синтаксического анализа сгенерированных SDE-скриптов, что указывает на высокую грамматическую корректность кода. Более того, общая точность модели на TCAD-бенчмарке составила 85.6%, что значительно превосходит показатели, достигнутые универсальными языковыми моделями. Такой успех свидетельствует о способности данной методики эффективно переводить инструкции в исполняемые и валидные TCAD-скрипты, открывая перспективы для автоматизации и повышения эффективности моделирования в микроэлектронике.
Значительное повышение способности модели точно преобразовывать инструкции в исполняемые и корректные TCAD-скрипты стало возможным благодаря новой методологии. Оптимизация напрямую предпочтений (DPO) в сочетании с промежуточным представлением (IR) позволяет модели не просто генерировать код, но и адаптироваться к требуемому синтаксису и логическому потоку симуляции. Это приводит к впечатляющим результатам: достигнут 80.0% уровень успешной компиляции сгенерированных SDE-скриптов и общая точность в 85.6% на TCAD-бенчмарке, что превосходит показатели универсальных больших языковых моделей. Подобное улучшение открывает новые возможности для автоматизации проектирования и анализа в микроэлектронике, обеспечивая более эффективное и надежное создание сложных схем.

Исследование демонстрирует, что даже в условиях дефицита данных, при грамотном подходе к структурированию и обучению, можно создавать вполне работоспособные LLM для специфических задач. Авторы предлагают схему, ориентированную на структурирование информации и использование DPO для оптимизации. Это напоминает о том, что элегантная теория без практической реализации мало что стоит. Как однажды заметил Джон Маккарти: «Искусственный интеллект — это искусство заставить машины делать вещи, которые мы считаем умными». В данном случае, «умная» вещь — генерация исполняемого кода для TCAD симуляций, а ключ к успеху — не в количестве данных, а в их структуре и алгоритме обучения. Очевидно, что каждый «революционный» подход рано или поздно превращается в технический долг, но данная работа показывает, что даже с ограниченными ресурсами можно добиться значительных результатов.
Что дальше?
Представленная работа, безусловно, демонстрирует возможность построения специализированных языковых моделей для узких доменов, даже при дефиците данных. Однако, если честно, это лишь переупаковка старых проблем в новую обёртку. Задача генерации исполняемого кода всегда была сложна, а добавление слоя «языковой модели» лишь перемещает узкое место. В конечном итоге, система всё равно рухнет на первом же нетривиальном кейсе — это, как минимум, последовательно. “Schema-first alignment” звучит красиво, но, по сути, это просто более сложный способ ручного написания правил.
Следующим шагом, вероятно, станет попытка автоматизировать создание этих самых «схем». Наверняка появятся инструменты, обещающие «самообучающиеся» схемы, которые будут генерировать код, который, в свою очередь, будет запускать симуляции. Это будет дорого, сложно и, скорее всего, будет работать чуть лучше, чем написанный вручную код — но зато с более впечатляющим ценником. В конечном счете, мы не пишем код — мы просто оставляем комментарии для будущих археологов, которые будут гадать, что же мы пытались сделать.
Более реалистичным направлением, пожалуй, является фокус на верификации сгенерированного кода. Если машина способна генерировать код, то ей же и придётся доказывать, что он работает правильно. Иначе это просто красивая игрушка, которая рано или поздно сломается. “Cloud-native” подходы, конечно, добавят масштабируемости, но, как известно, масштабируемость — это просто способ сделать большую ошибку быстрее.
Оригинал статьи: https://arxiv.org/pdf/2601.10128.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-17 03:02