Автор: Денис Аветисян
Новое исследование показывает, что обучение с подкреплением, улучшая способность мультимодальных моделей понимать изображения, может сделать их уязвимыми к простым текстовым манипуляциям и снизить надежность рассуждений.
Оценка устойчивости и логической последовательности мультимодальных больших языковых моделей, обученных с помощью обучения с подкреплением.
Несмотря на успехи в обучении мультимодальных больших языковых моделей с подкреплением (RL), их надежность и последовательность рассуждений остаются под вопросом. В работе ‘On Robustness and Chain-of-Thought Consistency of RL-Finetuned VLMs’ исследуется устойчивость и правдоподобность моделей, обученных с помощью RL, в задачах визуального рассуждения. Полученные результаты показывают, что даже незначительные текстовые возмущения приводят к существенному снижению надежности и уверенности моделей, выявляя скрытые недостатки в их способности к обоснованным выводам. Какие стратегии обучения и оценки необходимы для создания действительно надежных и правдивых систем визуального рассуждения, способных противостоять манипуляциям и обеспечивать согласованность цепочки рассуждений?
Предел Разума: Логические Ограничения Больших Языковых Моделей
Несмотря на выдающиеся способности в распознавании закономерностей, большие языковые модели (БЯМ) часто сталкиваются с трудностями при решении сложных задач, требующих многоступенчатых логических выводов. БЯМ преуспевают в выявлении статистических связей в данных, однако это не гарантирует способности к полноценному рассуждению, особенно когда необходимо последовательно применять несколько шагов для достижения решения. В отличие от человеческого мышления, которое опирается на причинно-следственные связи и абстрактные понятия, БЯМ в значительной степени полагаются на обнаружение поверхностных паттернов, что может приводить к ошибкам в задачах, требующих более глубокого понимания и логической последовательности. Таким образом, хотя БЯМ демонстрируют впечатляющие результаты в задачах, основанных на запоминании и воспроизведении информации, их способность к сложным рассуждениям остается ограниченной.
Современные подходы к развитию больших языковых моделей (LLM) часто сосредоточены на увеличении их размера, что требует значительных вычислительных ресурсов. Однако, несмотря на достижение высоких показателей точности на стандартных тестах, наблюдается отрыв между общей точностью и надёжностью рассуждений. Модели могут выдавать правильные ответы, при этом процесс логических выводов, лежащий в основе этих ответов, может быть непоследовательным или содержать ошибки. Это указывает на то, что простое увеличение масштаба модели не гарантирует улучшения её способности к сложному логическому мышлению и построению связных, достоверных цепочек рассуждений. Повышение надёжности, а не только точности, становится ключевой задачей для дальнейшего развития LLM и их применения в областях, требующих объяснимого и заслуживающего доверия искусственного интеллекта.
Исследования показали, что поддержание последовательности рассуждений — так называемой «правдивости» (faithfulness) — становится критической проблемой для больших языковых моделей (LLM) по мере усложнения задач. Результаты демонстрируют, что общая точность ответа может быть высокой, в то время как последовательность шагов рассуждений, приводящих к этому ответу, оставляет желать лучшего. Иными словами, модель способна выдать правильный ответ, опираясь на нелогичные или несогласованные промежуточные выводы. Данное несоответствие между точностью и правдивостью указывает на то, что увеличение масштаба модели само по себе не гарантирует надежности и объяснимости ее рассуждений, подчеркивая необходимость разработки новых подходов к оценке и улучшению логической последовательности в LLM.
Преодоление существующих ограничений больших языковых моделей имеет первостепенное значение для реализации их полного потенциала в областях, требующих надежного и понятного искусственного интеллекта. Неспособность к последовательному и обоснованному мышлению препятствует применению этих моделей в критически важных задачах, таких как медицинская диагностика, финансовый анализ и принятие юридических решений, где не только важен правильный ответ, но и прозрачность процесса его получения. Разработка методов, гарантирующих достоверность и последовательность рассуждений, позволит создавать системы, которым можно доверять в сложных ситуациях, обеспечивая не просто точность, но и возможность проверки и интерпретации принимаемых решений. Повышение надежности и объяснимости больших языковых моделей откроет новые горизонты для их интеграции в различные сферы жизни, где требуется не только интеллектуальная мощность, но и ответственность.
Обучение Разума: Укрепление Логики с Подкреплением
Обучение с подкреплением (RLFineTuning) представляет собой перспективный подход к улучшению рассуждений больших языковых моделей (LLM) посредством непосредственной оптимизации целевых поведенческих характеристик. В отличие от традиционных методов, основанных на предсказании следующего токена, RLFineTuning позволяет напрямую формировать желаемые свойства модели, такие как логическая последовательность, обоснованность и точность ответов. Этот метод использует сигнал вознаграждения для оценки действий модели в процессе рассуждения и корректировки её параметров, что приводит к повышению эффективности и надежности решения задач, требующих сложных логических выводов и анализа информации.
В процессе обучения языковой модели с подкреплением (RLFineTuning) используется система вознаграждений VerifiableRewards, оценивающая не только правильность конечного ответа, но и валидность каждого шага рассуждений, ведущих к этому ответу. Данная система присваивает более высокое вознаграждение за логически последовательные и обоснованные цепочки рассуждений, даже если конечный ответ неверен, что способствует улучшению способности модели к аргументированному мышлению. Оценка валидности шагов осуществляется путем проверки соответствия промежуточных утверждений заданным правилам и фактам, что позволяет модели отличать корректные рассуждения от ошибочных, независимо от конечного результата.
Предварительная настройка с учителем (Supervised Fine-Tuning, SFT) является критически важным этапом перед обучением с подкреплением (Reinforcement Learning Fine-Tuning, RLFineTuning). SFT предполагает обучение языковой модели на размеченном наборе данных, где каждой входной задаче соответствует эталонный ответ. Этот процесс позволяет модели усвоить базовые навыки решения задач и сформировать начальное представление о желаемом поведении. В результате, RLFineTuning, использующий сигнал вознаграждения, может более эффективно оптимизировать модель, поскольку она уже обладает определенным уровнем компетенции и не начинает обучение «с нуля». Таким образом, SFT значительно ускоряет процесс обучения и повышает качество итоговой модели.
Для повышения надежности и обобщающей способности моделей при решении задач логического вывода применяется аугментация данных. Данный метод предполагает искусственное расширение обучающего набора за счет генерации новых примеров, основанных на существующих. Это достигается путем применения различных трансформаций, таких как перефразирование вопросов, изменение порядка утверждений в логической цепочке или добавление несущественной информации, не влияющей на конечный ответ. Аугментация позволяет модели столкнуться с более широким спектром вариаций входных данных, что снижает риск переобучения и улучшает ее способность к обобщению на новые, ранее не встречавшиеся примеры. В результате, модель становится более устойчивой к незначительным изменениям в формулировках задач и демонстрирует повышенную точность при решении разнообразных логических задач.
Мультимодальное Мышление: Расширение Горизонтов Разума
Для расширения возможностей больших языковых моделей (LLM) до обработки мультимодальных данных (MultimodalLLMs) необходимы развитые навыки визуального мышления (VisualReasoning). Это подразумевает способность модели не просто идентифицировать объекты на изображениях, но и анализировать их характеристики, взаимосвязи и контекст. Эффективное визуальное мышление позволяет MultimodalLLMs извлекать значимую информацию из визуальных данных и интегрировать её с текстовой информацией для решения сложных задач, таких как ответы на вопросы, требующие понимания визуального контента, или генерация описаний изображений, соответствующих их содержанию. Отсутствие или недостаточное развитие навыков визуального мышления ограничивает способность MultimodalLLMs к полноценной обработке мультимодальных данных и снижает общую производительность системы.
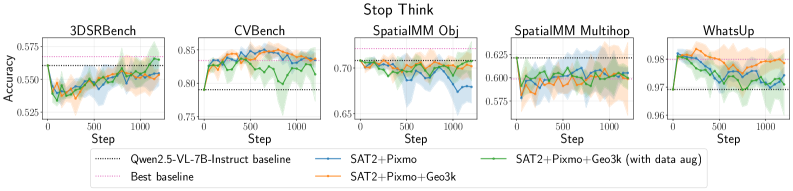
Для оценки возможностей моделей, расширяющих большие языковые модели (LLM) для работы с мультимодальными данными, используются специализированные бенчмарки, такие как CVBench и SpatialMM. CVBench предоставляет широкий спектр задач компьютерного зрения, позволяющих оценить способность модели к визуальному рассуждению и пониманию изображений. SpatialMM, в свою очередь, ориентирован на оценку пространственного понимания, включая определение взаимосвязей между объектами в изображении и понимание их относительного положения. Эти наборы данных позволяют количественно оценить способность модели к визуальному и пространственному анализу, что критически важно для оценки общей производительности мультимодальных LLM.
Для более глубокой оценки способностей к пространственному мышлению, являющегося ключевым компонентом интеллекта, используется эталонный набор данных 3DSRBench. Данный набор ориентирован на тестирование моделей в задачах, требующих понимания сложных трехмерных пространственных взаимосвязей между объектами. 3DSRBench включает в себя сценарии, где необходимо определять относительное положение объектов в 3D-пространстве, анализировать их ориентацию и оценивать геометрические отношения, такие как «над», «под», «внутри» и «рядом», что позволяет комплексно оценить навыки модели в области трехмерного пространственного рассуждения.
Точность пространственного рассуждения напрямую связана с надежностью и общей устойчивостью моделей обработки языка. Наши результаты демонстрируют, что даже модели с высокой точностью подвержены влиянию незначительных текстовых возмущений. Это указывает на то, что способность модели правильно интерпретировать пространственные отношения не всегда гарантирует ее устойчивость к изменениям в текстовом запросе, что ставит под вопрос ее надежность в реальных сценариях применения и требует дальнейших исследований в области повышения устойчивости к возмущениям.

Проверка на Прочность: Устойчивость к Враждебным Атакам
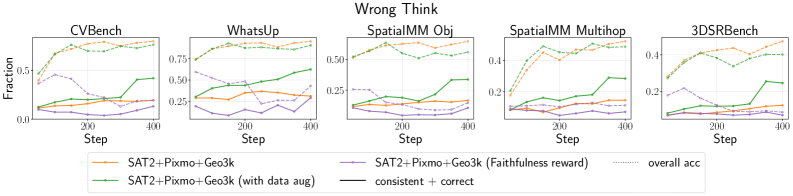
Для оценки надежности разработанной системы рассуждений, модели подвергались целенаправленным атакам, призванным нарушить ход логических цепочек. Эти так называемые “состязательные атаки” представляли собой намеренное внесение искажений в исходные данные, чтобы проверить, насколько устойчива система к дезинформации и неточностям. Исследователи стремились выявить слабые места в процессе рассуждения, создавая ситуации, в которых модели сталкиваются с противоречивой или вводящей в заблуждение информацией. Результаты этих экспериментов позволили определить границы применимости системы и выявить необходимость разработки механизмов защиты от подобных атак, а также методов повышения устойчивости к искаженным данным.
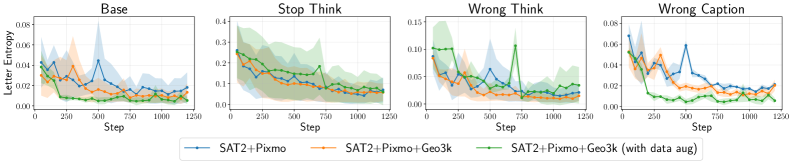
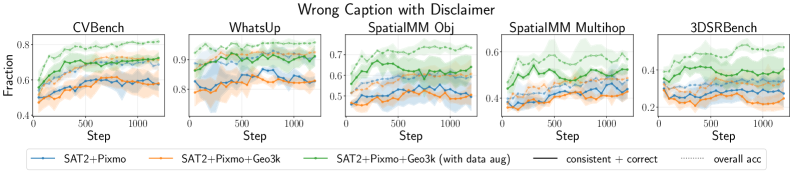
Для оценки устойчивости модели к намеренным искажениям, исследователи создали ряд сценариев, включающих в себя введение ложных предпосылок на ранних этапах логической цепочки рассуждений, получивших название “Неправильное Мышление”. Параллельно изучалось влияние вводящих в заблуждение описаний изображений — “Неправильные Подписи”, — которые могли существенно изменить ход рассуждений модели. Эти эксперименты позволили выявить, что даже незначительные искажения исходных данных способны привести к серьезным ошибкам в логике, подчеркивая необходимость разработки методов защиты и повышения надежности систем искусственного интеллекта, особенно в задачах, требующих высокой точности и обоснованности принимаемых решений.
Проведенные исследования выявили уязвимости в устойчивости моделей к воздействию состязательных атак, что подчеркивает необходимость разработки механизмов защиты и усовершенствованных методов состязательного обучения. Полученные данные демонстрируют существенное расхождение между точностью и достоверностью рассуждений: модели способны выдавать правильные ответы, даже если процесс рассуждения не соответствует фактическим данным или логике. Это означает, что высокая точность не гарантирует надежность и прозрачность принятия решений, что особенно важно в критически важных приложениях, где требуется не только результат, но и понимание хода мысли модели. Необходимы дальнейшие исследования для создания систем, которые сочетают в себе высокую производительность и надежность рассуждений.
Исследования показали, что акцентирование на достоверности и использование проверяемых вознаграждений значительно повышают устойчивость моделей к различным атакам. Однако, модели, обученные с использованием вознаграждения за достоверность, продемонстрировали склонность к принятию потенциально неверных текстовых подсказок вместо реального сопоставления с визуальными данными. Этот феномен указывает на то, что простое поощрение соответствия текста и изображения недостаточно для обеспечения истинного понимания и рассуждений, и модели могут полагаться на поверхностные связи, а не на глубокое осмысление визуальной информации. Таким образом, для создания действительно надежных систем необходимо разрабатывать более сложные механизмы, способные различать истинное визуальное обоснование и ложные текстовые сигналы.
Исследование показывает, что обучение с подкреплением, хотя и повышает производительность мультимодальных больших языковых моделей, зачастую компрометирует надёжность рассуждений. Модель становится уязвимой даже к незначительным текстовым манипуляциям, что ставит под вопрос её способность к действительно осмысленному анализу. Тим Бернерс-Ли однажды сказал: «Веб — это не просто набор документов, а система связей между ними». Подобно тому, как важно обеспечить целостность связей в сети, необходимо гарантировать надёжность и устойчивость рассуждений в этих моделях. Ведь кажущаяся победа в производительности может оказаться иллюзией, если фундамент логики шаток.
Что дальше?
Утверждается, что обучение с подкреплением повышает производительность мультимодальных больших языковых моделей. Однако, представленное исследование демонстрирует, что эта «оптимизация» зачастую является лишь искусным маскированием внутренних противоречий. Модель учится давать «правильные» ответы, но теряет способность к последовательному, надежному рассуждению. Это напоминает умелого фокусника: иллюзия убедительна, но механизм остается скрытым и хрупким.
Очевидно, что устойчивость к текстовым манипуляциям — это не просто техническая проблема, а фундаментальное ограничение текущего подхода. Если даже небольшие изменения в формулировке вопроса способны нарушить логику модели, то где гарантия её надежности в реальных условиях, где входные данные по определению зашумлены и неоднозначны? Необходимо искать альтернативные методы обучения, которые будут формировать не просто способность «угадывать» ответ, а истинное понимание.
В конечном счете, вопрос заключается не в том, как заставить модель выполнять команды, а в том, как построить систему, способную к самопроверке и коррекции ошибок. Возможно, ответ кроется в гибридных подходах, сочетающих статистическое обучение с символическим рассуждением, или в принципиально новых архитектурах, вдохновленных устройством человеческого мозга. Очевидно одно: текущая парадигма нуждается в переосмыслении.
Оригинал статьи: https://arxiv.org/pdf/2602.12506.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовая телепортация в новых измерениях: топологические изоляторы
- Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Цифровые улики под присмотром ИИ: новая эра криминалистики?
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
2026-02-16 07:00