Автор: Денис Аветисян
Новое исследование сравнивает возможности современных больших языковых моделей в решении задач квантовой механики, выявляя их сильные и слабые стороны.
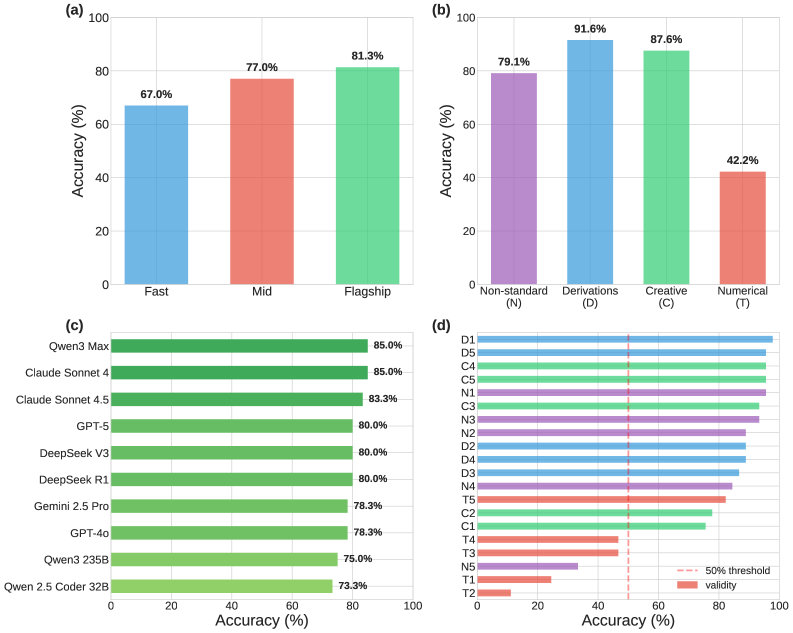
Проведено комплексное сравнение 15 больших языковых моделей на 20 задачах квантовой механики, оценивались эффективность, стоимость и воспроизводимость результатов.
Несмотря на стремительное развитие больших языковых моделей (LLM), их способность к решению задач, требующих глубоких знаний в специализированных областях, остаётся малоизученной. В работе ‘Evaluating Large Language Models on Quantum Mechanics: A Comparative Study Across Diverse Models and Tasks’ представлен систематический анализ 15 LLM от пяти ведущих разработчиков в области квантовой механики, охватывающий 20 задач различной сложности. Полученные результаты демонстрируют чёткую стратификацию моделей по производительности, а также выявляют неоднозначные эффекты использования инструментов для расширения возможностей LLM, при этом флагманские модели демонстрируют значительное превосходство и стабильность. Сможем ли мы в будущем создать LLM, способные не просто решать, но и генерировать новые знания в области фундаментальной физики?
Квантовые горизонты: LLM вступают в сложный мир
В последнее время наблюдается растущий интерес к применению больших языковых моделей (LLM) в различных научных областях, включая квантовую механику. Однако, несмотря на впечатляющие возможности в обработке естественного языка, LLM сталкиваются с существенными трудностями в области численного анализа и точных вычислений. Квантовая механика, по своей природе, требует высокой степени математической точности и способности оперировать сложными уравнениями, что представляет собой серьезный вызов для моделей, изначально ориентированных на лингвистические задачи. Неспособность LLM к надежному выполнению числовых расчетов ограничивает их потенциал в решении квантово-механических задач и требует разработки специализированных подходов, позволяющих компенсировать эти ограничения и обеспечить достоверность результатов. Это особенно актуально при моделировании динамики квантовых систем и анализе их свойств, где даже незначительные погрешности могут привести к ошибочным выводам.
Успешное освоение квантовой механики требует не только точных вычислений, но и глубокого концептуального понимания, что традиционно представляет сложность для больших языковых моделей (LLM) без дополнительной поддержки. LLM, обученные на огромных объемах текстовых данных, часто испытывают трудности при решении задач, требующих математической точности и логических выводов, характерных для квантовой физики. В то время как модели демонстрируют способность к обработке и генерации текста, связанного с квантовыми явлениями, их эффективность в решении конкретных уравнений или интерпретации физических принципов остается ограниченной. Для преодоления этих сложностей необходимы специализированные подходы, включающие интеграцию LLM с инструментами численного моделирования или разработку новых архитектур, способных к более эффективному представлению и обработке квантовой информации. Именно поэтому для надежного применения LLM в квантовой механике требуется их дополнение внешними вычислительными средствами и экспертными знаниями.
Применение больших языковых моделей (LLM) к решению таких задач, как уравнение Линдблада и квантовый гармонический осциллятор, выявило потребность в специализированных подходах. Эти задачи требуют не просто обработки информации, но и глубокого понимания математического аппарата и физических принципов квантовой механики, что выходит за рамки возможностей стандартных LLM. Успешное решение подобных уравнений предполагает точные вычисления и манипулирование комплексными математическими выражениями, включая матрицы и собственные значения . Исследования показывают, что для достижения приемлемой точности LLM нуждаются в интеграции с внешними вычислительными инструментами или в обучении на специализированных наборах данных, содержащих примеры решения подобных задач, а также в использовании техник, улучшающих их способность к символьным вычислениям и логическому выводу.
Первоначальные оценки применения больших языковых моделей (LLM) к задачам квантовой механики выявили непостоянство в ответах. Флагманские модели демонстрируют общую точность в 81.3% при решении специализированных задач, однако среднее отклонение в 6.3% при повторных запусках (трехкратных попытках) указывает на необходимость повышения надежности и стабильности результатов. Эта вариативность подчеркивает, что, несмотря на впечатляющую общую производительность, LLM нуждаются в дальнейшей оптимизации для обеспечения воспроизводимости и точности в сложных научных расчетах, таких как решение уравнения Линдблада или квантового гармонического осциллятора. Устранение этой непоследовательности является ключевым шагом на пути к интеграции LLM в научные исследования, где достоверность данных имеет первостепенное значение.
Инструментальное усиление: преодолевая числовой барьер
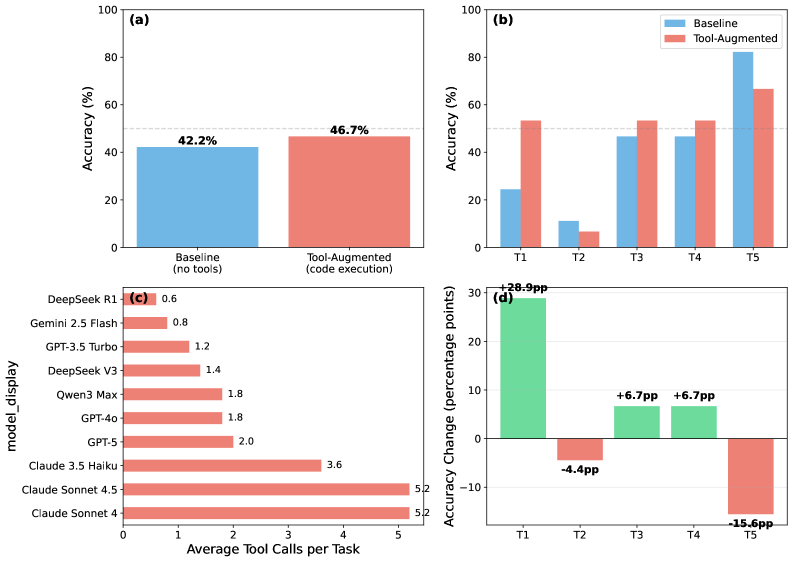
Дополнение больших языковых моделей (LLM) инструментами, в частности, возможностью выполнения кода Python, представляет собой эффективное решение для расширения их вычислительных возможностей. Внутренние ограничения LLM в обработке числовых данных преодолеваются за счет делегирования вычислений внешнему интерпретатору Python. Этот подход позволяет LLM решать сложные задачи, требующие точных расчетов, такие как решение квантовомеханических уравнений, что ранее было затруднительно или невозможно без специализированных инструментов. Использование Python обеспечивает доступ к широкому спектру математических библиотек и функций, значительно повышая точность и надежность результатов, получаемых LLM.
Перенос вычислительных задач на специализированный интерпретатор Python позволяет большим языковым моделям (LLM) преодолеть внутренние ограничения, связанные с представлением и обработкой чисел. Встроенные возможности LLM для выполнения арифметических операций ограничены точностью представления чисел с плавающей точкой и количеством итераций. Использование Python позволяет LLM обращаться к библиотекам и функциям, разработанным для высокоточных вычислений, необходимых для решения сложных задач квантовой механики, где требуются операции с большими числами и матрицами, а также специализированные алгоритмы. Этот подход обеспечивает повышение точности результатов, поскольку вычисления выполняются в среде, оптимизированной для числовой обработки, а не внутри самой языковой модели.
Использование инструментов, в частности, возможности выполнения Python-кода, позволило языковым моделям эффективно решать численные задачи, ранее недоступные для них. Экспериментальные данные демонстрируют повышение точности на 4,4% при решении таких задач. Однако, следует учитывать, что данное решение сопровождается увеличением затрат на обработку токенов в 3 раза, что необходимо учитывать при масштабировании и оптимизации производительности. Несмотря на увеличение стоимости, повышение точности является значительным шагом к расширению возможностей LLM в областях, требующих высокой вычислительной точности.
Успешная интеграция выполнения Python-кода демонстрирует возможность использования больших языковых моделей (LLM) в качестве интеллектуальных интерфейсов к вычислительным инструментам. Этот подход позволяет LLM не просто генерировать текст, но и динамически использовать внешние вычислительные ресурсы для решения сложных задач, требующих точных вычислений или доступа к специализированным библиотекам. LLM выступает в роли посредника, принимая запрос на выполнение задачи, генерируя необходимый Python-код, передавая его на исполнение, и затем интерпретируя результаты для предоставления пользователю. Такая архитектура открывает перспективы для расширения функциональности LLM за пределы возможностей, ограниченных только их внутренними параметрами и данными, и позволяет им эффективно взаимодействовать с широким спектром программного обеспечения и аппаратных средств.
Оптимизация эффективности: многоуровневый подход к выбору моделей
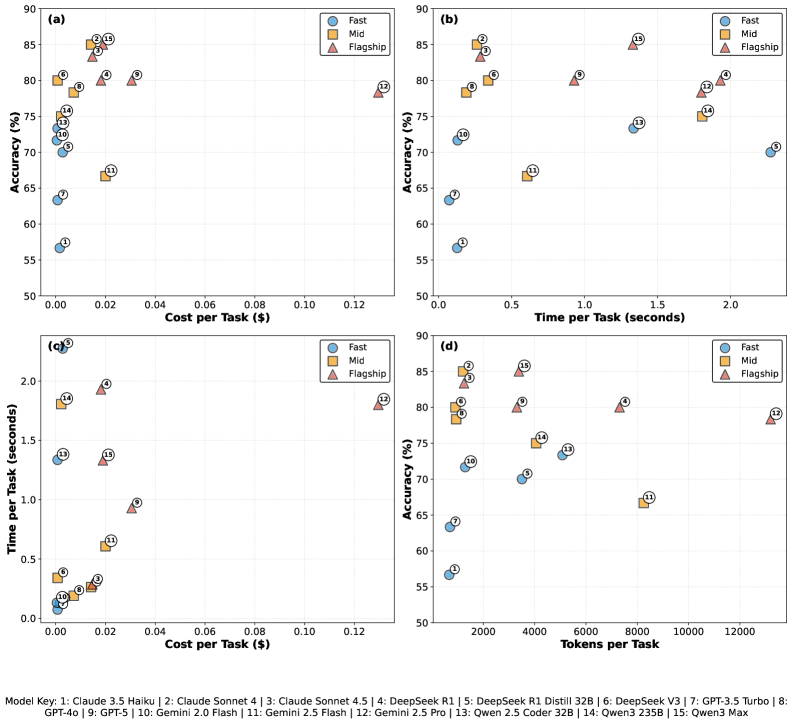
Существуют различные уровни языковых моделей (LLM), классифицируемые как флагманские, модели среднего уровня и быстрые модели, каждый из которых представляет собой компромисс между производительностью и стоимостью. Флагманские модели, такие как GPT-4, обеспечивают наивысшую точность и сложность обработки, но требуют значительно больше вычислительных ресурсов и, следовательно, стоят дороже. Модели среднего уровня, например, GPT-3.5, предлагают сбалансированное сочетание производительности и стоимости, подходящее для широкого спектра задач. Быстрые модели, оптимизированные для скорости и экономии ресурсов, обеспечивают приемлемую производительность для менее требовательных приложений, где важна низкая задержка и минимальные затраты. Выбор подходящего уровня LLM зависит от конкретных требований к точности, скорости обработки и бюджетным ограничениям.
Анализ моделей через API OpenRouter показал, что производительность не всегда линейно зависит от размера модели. В частности, наблюдается, что увеличение размера модели не всегда приводит к пропорциональному увеличению точности или качества генерации текста. Вместо этого, эффективность модели — соотношение между производительностью и затратами — становится критическим фактором. Модели меньшего размера могут обеспечивать достаточную производительность для определенных задач, при этом значительно снижая вычислительные затраты и задержку, что делает их более выгодными в практическом применении. Оптимизация на основе эффективности требует тщательного анализа конкретных требований к задаче и выбора модели, обеспечивающей оптимальный баланс между качеством и стоимостью.
Температура выборки является ключевым параметром, влияющим на баланс между исследованием (exploration) и использованием (exploitation) при генерации текста большими языковыми моделями (LLM). Более высокие значения температуры (например, ближе к 1) увеличивают вероятность выбора менее вероятных токенов, способствуя большей вариативности и креативности в ответах, но могут снизить их согласованность и релевантность. Напротив, более низкие значения температуры (например, ближе к 0) приводят к более детерминированным и предсказуемым ответам, концентрируясь на наиболее вероятных токенах, что повышает согласованность, но ограничивает разнообразие и потенциальную оригинальность. Оптимальное значение температуры зависит от конкретной задачи и требуемого баланса между качеством, креативностью и предсказуемостью выходных данных.
Оптимизация затрат при использовании больших языковых моделей (LLM) требует осознанного выбора подходящего уровня модели в зависимости от конкретной задачи. Анализ, проведенный через OpenRouter API, показывает, что флагманские модели достигают точности 81.3%, однако их стоимость в 67 раз превышает стоимость самых быстрых моделей, при этом прирост точности составляет всего 14 процентных пункта. Это указывает на то, что более высокая производительность флагманских моделей не всегда оправдывает значительно более высокие затраты, и в ряде случаев использование моделей среднего или быстрого уровня может обеспечить достаточную точность при существенно меньших финансовых издержках.
За пределами вычислений: расширение горизонтов квантовых LLM
Усиленные инструментами языковые модели демонстрируют возможности, выходящие за рамки простых числовых вычислений, успешно справляясь со сложными задачами, такими как символьные выкладки и даже творческие задания в области квантовой механики. Эти системы способны решать уравнения, выводить новые формулы и исследовать концептуальные вопросы, что существенно расширяет спектр их применения. Вместо простого подбора числовых ответов, модели оперируют с математическими выражениями и логическими связями, позволяя решать задачи, требующие не только вычислительной мощности, но и понимания принципов квантовой физики. Например, они могут быть использованы для проверки корректности сложных доказательств или для генерации новых гипотез, открывая перспективы для более глубокого изучения квантовых явлений и ускорения научных открытий.
Расширенные возможности языковых моделей, дополненных инструментами, выходят далеко за рамки простых вычислений и позволяют им активно участвовать в решении сложных задач, оптимизации проектов и исследовании нестандартных концепций в квантовой механике. Эти модели способны не просто находить численные ответы, но и предлагать решения, основанные на логических выводах и творческом подходе к проблеме. Благодаря этому, они становятся ценным инструментом для учёных, позволяя им экспериментировать с различными подходами, находить оптимальные конструкции и углублять понимание фундаментальных принципов квантового мира. Возможность исследовать нетрадиционные концепции открывает путь к новым открытиям и инновациям в области физики и смежных дисциплин, значительно ускоряя процесс научного поиска.
Флагманские модели квантовых языковых моделей демонстрируют впечатляющее владение символьными вычислениями, достигая 100% точности при решении задач на вывод формул и уравнений. Этот результат свидетельствует о способности систем не просто выполнять численные расчеты, но и оперировать абстрактными понятиями и логическими связями, характерными для квантовой механики. По сути, модели способны к формальным манипуляциям с математическими выражениями, аналогичным тем, что выполняет опытный физик-теоретик, выводя новые формулы из существующих принципов и аксиом. Такое мастерство символьной логики открывает возможности для автоматизированного поиска решений сложных задач, проверки корректности теоретических построений и даже генерации новых гипотез в области квантовой физики, значительно ускоряя процесс научных исследований и открытий.
Современные языковые модели, расширенные возможностями внешних инструментов, представляют собой гибкую и адаптируемую платформу, способную значительно ускорить темпы научных открытий в области квантовой механики. Они позволяют исследователям не просто проводить численные расчеты, но и исследовать более сложные концепции, оптимизировать дизайн экспериментов и даже выдвигать гипотезы, выходящие за рамки стандартных представлений. Благодаря способности обрабатывать и анализировать большие объемы информации, эти модели помогают выявлять закономерности и связи, которые могли бы остаться незамеченными при традиционных методах исследования, открывая новые пути для понимания фундаментальных квантовых явлений и разработки инновационных технологий. Такой подход способствует не только углублению теоретических знаний, но и практическому применению квантовых принципов в различных областях науки и техники.
Исследование демонстрирует, что оценка больших языковых моделей в сложных областях, таких как квантовая механика, требует не только анализа их производительности, но и учета компромиссов между точностью, стоимостью и возможностью воспроизведения результатов. Авторы подчеркивают важность бенчмаркинга и использования инструментов для повышения эффективности моделей. В этом контексте примечательна мысль Брайана Кернигана: «Простота масштабируется, изощрённость — нет». Данное утверждение особенно актуально, учитывая, что стремление к излишней сложности в архитектуре модели может привести к увеличению вычислительных затрат и снижению возможности её применения в реальных научных задачах. Вместо этого, акцент на простых и понятных решениях позволяет создавать системы, способные эффективно обрабатывать большие объемы данных и адаптироваться к новым задачам.
Что дальше?
Представленное исследование, хотя и выявляет иерархии производительности больших языковых моделей в области квантовой механики, лишь подчеркивает фундаментальную сложность задачи. Каждая оптимизация, направленная на повышение точности, неизбежно создает новые узлы напряжения в системе, новые области, где поверхностное понимание маскирует глубинную неопределенность. Архитектура системы определяется ее поведением во времени, а не схемой на бумаге; результаты, полученные сегодня, лишь временный снимок сложной эволюции.
Особое внимание следует уделить воспроизводимости и экономической эффективности. Заманчиво полагаться на самые крупные модели, но истинная ценность заключается в создании систем, способных к надежному и доступному научному мышлению. Вместо бесконечной гонки за параметрами, необходимо сосредоточиться на разработке инструментов, которые позволяют моделям не просто выдавать ответы, а демонстрировать процесс рассуждения, поддающийся проверке и интерпретации.
Будущие исследования должны выйти за рамки простого бенчмаркинга. Необходимо исследовать, как большие языковые модели могут интегрироваться в существующие научные рабочие процессы, как они могут помогать ученым формулировать гипотезы, проектировать эксперименты и анализировать данные. Истинный тест — не в способности модели решать задачи, а в ее способности расширять границы человеческого познания.
Оригинал статьи: https://arxiv.org/pdf/2602.19006.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Искусственный интеллект и квантовая физика: кто кого?
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Серебро и медь: новый взгляд на наноаллои
- Разумный подбор растворителей: новый подход на стыке нейросетей и физики
- Сознание машин: новая модель двойных законов
2026-02-24 12:09