Автор: Денис Аветисян
Исследование показывает, что AI-агенты, генерирующие TypeScript, часто допускают ошибки в работе с типами, что потенциально приводит к накоплению технического долга.
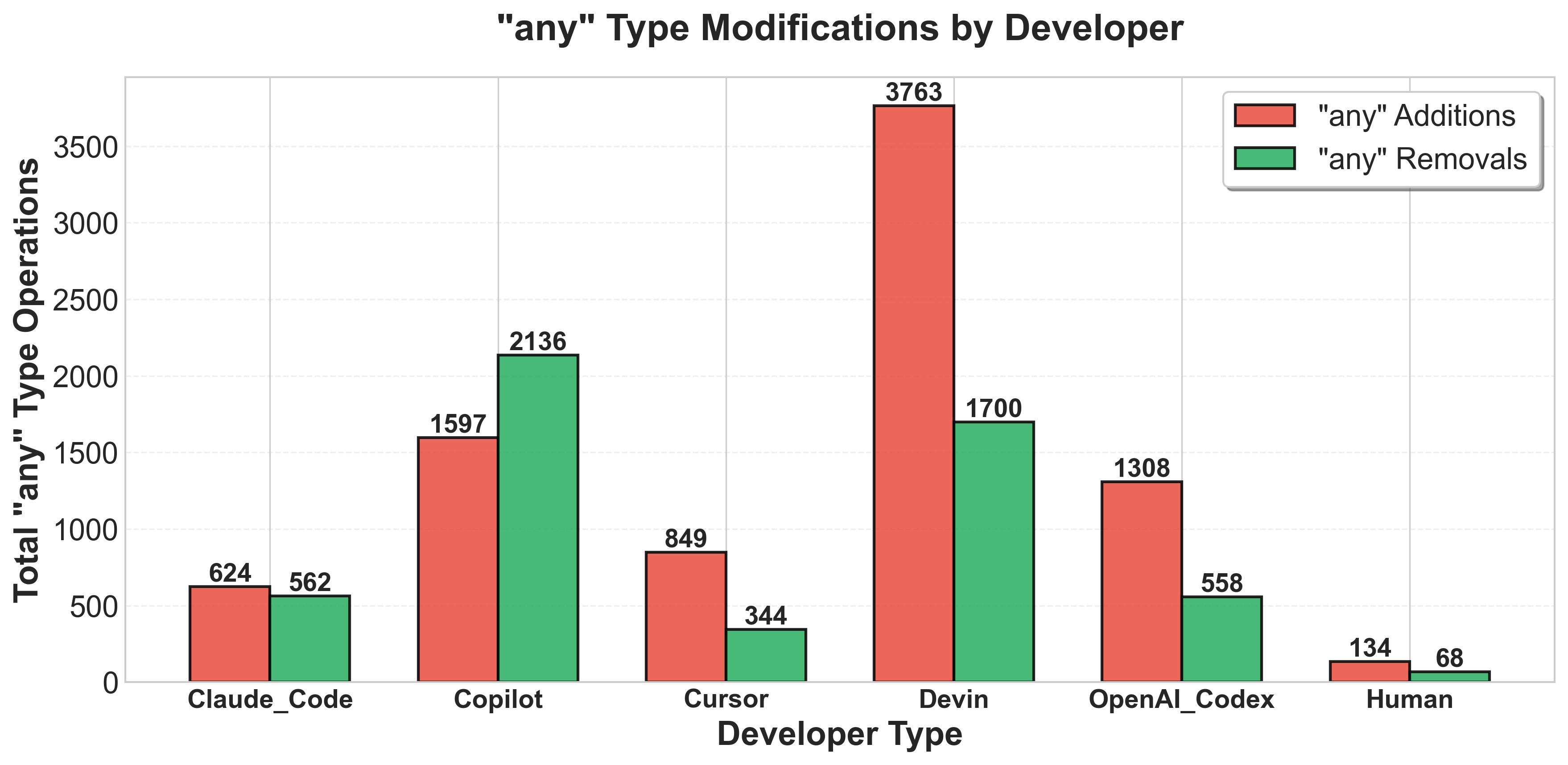
Анализ паттернов в коде, созданном AI-агентами, выявил распространенные проблемы с типобезопасностью, несмотря на более высокую скорость принятия pull requests.
Несмотря на растущую автоматизацию разработки программного обеспечения искусственным интеллектом, остается неясным, превосходит ли ИИ человека в задачах, связанных с типобезопасностью. В работе ‘Mining Type Constructs Using Patterns in AI-Generated Code’ представлен первый эмпирический анализ использования типовых конструкций в проектах TypeScript, демонстрирующий, что ИИ-агенты в 9 раз чаще используют ключевое слово ‘any’ и активнее применяют продвинутые, но потенциально небезопасные, типовые конструкции. Удивительно, но запросы на включение изменений, сгенерированные ИИ, принимаются в 1.8 раза чаще, чем запросы от людей. Не приведет ли широкое использование ИИ в разработке к накоплению технического долга, связанного с типобезопасностью, и как обеспечить надежность кода, созданного в сотрудничестве с ИИ?
Гибкость и Опасности Динамической Типизации
Язык JavaScript, известный своей гибкостью, использует динамическую типизацию, что позволяет переменным менять тип данных во время выполнения программы. Хотя это и упрощает процесс разработки на начальных этапах, подобный подход часто приводит к неожиданным ошибкам уже в процессе работы приложения. Эти ошибки, проявляющиеся только во время исполнения, становятся особенно проблематичными в крупных проектах, где отладка и исправление таких недочетов требует значительных усилий и времени. Отсутствие строгой проверки типов на этапе компиляции затрудняет обнаружение потенциальных проблем, увеличивая риск возникновения сбоев в работе приложения и усложняя его дальнейшую поддержку и масштабирование.
Для решения проблем, связанных с гибкостью и потенциальными ошибностями динамической типизации в JavaScript, был разработан TypeScript. Этот язык представляет собой надстройку над JavaScript, вводящую статическую систему типов. Она позволяет разработчикам указывать типы данных для переменных, параметров функций и возвращаемых значений, что позволяет компилятору выявлять многие ошибки на этапе разработки, а не во время выполнения программы. Такой подход значительно повышает надежность и поддерживаемость кода, особенно в крупных проектах, где отслеживание ошибок в динамически типизированном коде может быть чрезвычайно сложным. Внедрение статической типизации позволяет улучшить рефакторинг, автодополнение кода в редакторах и общее понимание логики программы.
Эффективность TypeScript, как инструмента повышения надежности кода, напрямую зависит от добросовестного применения его системы типов разработчиками. Несмотря на потенциал статической типизации для выявления ошибок на этапе компиляции и упрощения рефакторинга, практика показывает, что не все программисты в полной мере используют предоставляемые возможности. Часто встречаются случаи, когда типы указываются неточно, используются типы any для обхода проверок, или система типов игнорируется вовсе, что нивелирует преимущества TypeScript и возвращает проект к проблемам, свойственным динамически типизированным языкам. Таким образом, внедрение TypeScript само по себе не гарантирует повышение качества кода; ключевым фактором является дисциплина и внимательность разработчиков к деталям при определении и использовании типов.
Выявление Антипаттернов в Коде TypeScript
Разработчики часто обходят систему строгой типизации TypeScript, используя конструкции, такие как тип any и оператор не-null утверждения (!). Применение any отключает проверку типов для конкретной переменной или выражения, эффективно возвращаясь к динамической типизации, свойственной JavaScript. Оператор не-null утверждения (!) указывает компилятору, что переменная, которая потенциально может быть null или undefined, гарантированно имеет значение, подавляя предупреждения компилятора и перекладывая ответственность за корректность на разработчика. Эти практики, известные как “анти-паттерны, связанные с типами”, снижают надежность и предсказуемость кода, написанного на TypeScript, и могут привести к ошибкам времени выполнения, которые могли бы быть обнаружены на этапе компиляции.
Использование таких практик, как тип any и оператор утверждения ненулевого значения (!), фактически нивелирует преимущества статической типизации в TypeScript. Вместо гарантии безопасности типов на этапе компиляции, разработчик, по сути, возвращается к динамической типизации, где ошибки, связанные с типами данных, могут проявиться только во время выполнения программы. Это увеличивает вероятность возникновения runtime-ошибок, усложняет отладку и снижает надежность кода, поскольку компилятор не может выявить потенциальные несоответствия типов на ранних стадиях разработки.
Для выявления и количественной оценки антипаттернов в коде TypeScript необходим комплексный анализ реальных кодовых баз. Такой анализ предполагает автоматизированное сканирование проектов с использованием статических анализаторов кода, способных детектировать использование типов any, ненулевых утверждений (!), а также другие конструкции, ослабляющие типобезопасность. Количественная оценка проводится путем подсчета частоты встречаемости этих антипаттернов в различных частях кодовой базы, что позволяет оценить степень риска, связанного с потенциальными ошибками типов. Результаты анализа могут быть представлены в виде метрик, таких как процент строк кода, содержащих any, или количество ненулевых утверждений на тысячу строк кода, что позволяет отслеживать динамику и эффективность применения типобезопасности.
Анализ Pull Request’ов TypeScript с Использованием AI-Агентов
Для анализа распространенных шаблонов, связанных с использованием типов в TypeScript, был собран и структурирован набор данных ‘AIDev Dataset’. В его состав вошли запросы на внесение изменений (pull requests) из различных репозиториев, содержащие код на TypeScript. Данный набор данных включает в себя информацию о внесенных изменениях, комментариях и метаданных, что позволяет проводить статистический анализ и выявлять типичные подходы к типизации, а также распространенные ошибки и антипаттерны, встречающиеся на практике при разработке на TypeScript. Объем и разнообразие ‘AIDev Dataset’ обеспечивают статистическую значимость результатов анализа и позволяют делать обоснованные выводы о текущем состоянии использования типов в проектах на TypeScript.
Для фильтрации и категоризации запросов на изменение кода (pull requests) на TypeScript, связанных с типами, была использована многоагентная система, основанная на больших языковых моделях (LLM). Эта система функционировала совместно с парсером, использующим регулярные выражения (Regex-Based Parser), для извлечения и анализа релевантных характеристик, таких как добавление, изменение или удаление типов, использование конкретных типовых конструкций и выявление потенциальных несоответствий типов. Сочетание возможностей LLM по семантическому пониманию кода и точности регулярных выражений позволило автоматизировать процесс идентификации pull requests, содержащих изменения, влияющие на систему типов, и классифицировать их по различным признакам, связанным с типами.
Использование предложенного подхода позволило эффективно выявлять случаи антипаттернов, связанных с типизацией, в крупных кодовых базах. Анализ проводился путем автоматизированного поиска распространенных ошибок и неоптимальных решений в TypeScript коде. Автоматизация процесса позволила значительно сократить время, необходимое для обнаружения антипаттернов, по сравнению с ручным анализом, и охватить значительно больший объем кода. Выявленные антипаттерны включают в себя избыточное использование типов any, неоптимальное использование обобщений и неэффективные конструкции, ухудшающие читаемость и поддерживаемость кода.
Влияние на Качество Кода и Перспективы Развития
Анализ данных выявил заметную взаимосвязь между частотой встречаемости антипаттернов, связанных с типами данных, и более низким процентом принятия pull request’ов. В частности, чем чаще в предложенном коде обнаруживаются неоптимальные или избыточные использования типов, тем меньше вероятность того, что этот код будет одобрен и включен в основную кодовую базу. Это указывает на то, что подобные паттерны не только снижают читаемость и поддерживаемость кода, но и могут служить индикатором потенциальных ошибок или уязвимостей, что закономерно вызывает критическое отношение со стороны рецензентов. Выявление и устранение этих антипаттернов представляется важной задачей для повышения качества программного обеспечения и оптимизации процесса разработки.
Анализ продемонстрировал существенную разницу в скорости принятия изменений, внесенных автоматическими агентами, и изменений, внесенных разработчиками. В частности, запросы на слияние (Pull Requests), созданные AI-агентами, принимаются в 45.8% случаев, тогда как для запросов, созданных людьми, этот показатель составляет лишь 25.3% (p < 0.0001, Cramer’s V = 0.32). Данная статистическая значимость указывает на то, что автоматические агенты предлагают изменения, которые чаще оказываются полезными и соответствуют требованиям проекта, что приводит к более быстрому принятию и интеграции кода в основную ветку разработки.
Исследование выявило существенную разницу в использовании типа ‘any’ при внесении изменений в кодовую базу искусственными интеллектами и разработчиками-людьми. В среднем, ИИ-агенты добавляют тип ‘any’ в 2.16 раза чаще, чем это делают люди, при анализе одних и тех же pull request’ов. Данная закономерность статистически значима (p ≈ 2.33 × 10⁻⁷), что указывает на устойчивую тенденцию. В то время как тип ‘any’ может упростить первоначальную разработку, его чрезмерное использование потенциально ведет к накоплению технического долга и снижению надежности кода, поскольку отключает строгий контроль типов и может приводить к ошибкам, которые сложно обнаружить на этапе компиляции. Это подчеркивает необходимость разработки стратегий, направленных на минимизацию использования ‘any’ при автоматической генерации кода с помощью ИИ.
Анализ выявил, что закономерности использования типов данных, свойственные коду, сгенерированному искусственным интеллектом, могут приводить к накоплению технического долга и, как следствие, снижению производительности разработчиков. Наличие подобных паттернов усложняет понимание и поддержку кодовой базы, увеличивая затраты на рефакторинг и исправление ошибок в будущем. Подобные явления приводят к необходимости дополнительных усилий для обеспечения качества кода и могут затормозить процесс разработки новых функций, поскольку разработчикам требуется больше времени на анализ и адаптацию к существующему коду, содержащему эти антипаттерны. Таким образом, выявление и устранение подобных проблем на ранних этапах жизненного цикла разработки программного обеспечения является критически важным для поддержания здоровой кодовой базы и обеспечения устойчивого развития проекта.
Анализ показал, что искусственные агенты значительно активнее используют продвинутые возможности типизации в коде. Данное наблюдение, подтвержденное статистически значимым результатом p < 5.50 \times 10^{-5} и большим значением Cohen’s d (1.45), указывает на то, что агенты не просто генерируют код, но и стремятся к более строгому и детализированному определению типов данных. Это может свидетельствовать о потенциале AI в создании более надежного и поддерживаемого программного обеспечения, однако требует дальнейшего изучения для оценки влияния на общую сложность и читаемость кода, а также на скорость разработки.
Исследования показывают, что использование агентов искусственного интеллекта для автоматической генерации кода и проактивного выявления антипаттернов, связанных с типами данных, может значительно повысить качество программного обеспечения и снизить затраты на разработку. Автоматизированный анализ кода, выполняемый AI-агентами, способен выявлять потенциальные источники технического долга на ранних этапах, позволяя разработчикам оперативно устранять недостатки и поддерживать высокий уровень чистоты кода. Такой подход не только сокращает время, затрачиваемое на ручную проверку, но и способствует формированию более надежных и поддерживаемых программных систем, что в конечном итоге приводит к повышению производительности и снижению рисков, связанных с дефектами.
Исследование показывает, что агенты искусственного интеллекта, несмотря на высокую скорость принятия изменений, склонны к созданию типовых проблем в коде TypeScript. Это не удивительно, если вспомнить слова Джона фон Неймана: «В цифровой компьютер можно ввести любую информацию, но он не будет думать». Искусственный интеллект, как и любой инструмент, не избавляет от необходимости тщательного анализа и контроля. Возникающие антипаттерны и технический долг — закономерное следствие слепого следования алгоритмам без понимания семантики. Система, как и живой организм, требует постоянного внимания и ухода, иначе даже самые успешные изменения могут привести к неожиданным последствиям. Ведь разделение системы на микросервисы не отменяет общей судьбы, а лишь усложняет отладку.
Что дальше?
Представленное исследование выявляет закономерность: агенты искусственного интеллекта, стремясь к скорости и принятию изменений, часто оставляют за собой след в виде проблем с типизацией. Это не ошибка инструментов, а закономерность сложных систем. Каждая новая архитектура обещает свободу от технического долга, пока не потребует DevOps-жертвоприношений в виде ручного аудита и рефакторинга. Упор на автоматическое исправление типов, безусловно, важен, но иллюзия полной автоматизации опасна. Необходимо признать, что статические системы типов — это не абсолютная защита, а лишь временный кэш между сбоями.
Следующим шагом видится не столько в улучшении самих агентов, сколько в исследовании способов их интеграции в существующие процессы разработки. Как создать систему, в которой AI-агенты не просто генерируют код, но и учатся на своих ошибках, получая обратную связь от людей и инструментов анализа? Важно сместить фокус с «генерации идеального кода» на «генерацию кода, который легко исправить и адаптировать».
В конечном счете, исследование указывает на необходимость более глубокого понимания компромиссов между скоростью разработки, безопасностью типов и долгосрочной поддерживаемостью кода. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить, осознавая, что хаос неизбежен, и задача разработчика — не его избежать, а научиться с ним жить.
Оригинал статьи: https://arxiv.org/pdf/2602.17955.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 19:02