Автор: Денис Аветисян
Исследователи представили комплексную методику оценки способности больших языковых моделей понимать намерения и убеждения других, приближенную к принципам человеческого мышления.

CogToM: всесторонний бенчмарк для оценки способности больших языковых моделей к моделированию психических состояний других, вдохновленный когнитивными исследованиями.
Несмотря на растущий интерес к оценке способности больших языковых моделей (LLM) к пониманию теории разума, существующие бенчмарки зачастую не отражают всего спектра когнитивных механизмов, присущих человеку. В данной работе представлена платформа ‘CogToM: A Comprehensive Theory of Mind Benchmark inspired by Human Cognition for Large Language Models’ — всесторонний, теоретически обоснованный набор данных, включающий более 8000 примеров на 46 парадигмах, валидированных 49 экспертами-аннотаторами. Систематический анализ 22 моделей, включая передовые разработки, выявил существенные различия в производительности и указал на узкие места в определенных когнитивных областях, а также потенциальные расхождения между когнитивными структурами LLM и человека. Позволит ли CogToM более глубоко понять границы когнитивных возможностей искусственного интеллекта и приблизиться к созданию действительно разумных систем?
Вызов Истинного Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющую способность генерировать связные и грамматически верные тексты, современные большие языковые модели (БЯМ) испытывают трудности в решении задач, требующих здравого смысла и понимания ментальных состояний. Эти модели, обученные на огромных объемах текстовых данных, превосходно распознают статистические закономерности, однако им часто не хватает способности делать логические выводы, основанные на реальном понимании мира. Например, БЯМ могут испытывать затруднения при определении мотивации персонажей в рассказе или предсказании последствий простых действий, поскольку они не обладают интуитивным пониманием причинно-следственных связей, характерным для человеческого интеллекта. Это ограничение особенно заметно в сценариях, требующих понимания намерений, эмоций и убеждений других людей — областей, где требуется не просто обработка информации, но и эмпатия и социальный интеллект.
Современные архитектуры больших языковых моделей, демонстрирующие впечатляющую способность к распознаванию закономерностей, часто сталкиваются с так называемым “парадоксом Морвека” — явлениями, которые кажутся тривиальными для человека, но представляют значительную сложность для искусственного интеллекта. В то время как модели легко овладевают сложными математическими вычислениями или анализом больших объемов данных, задачи, требующие базового понимания физического мира, интуиции или здравого смысла, оказываются неожиданно трудными. Этот парадокс объясняется тем, что человеческий мозг автоматически и неосознанно обрабатывает огромный объем информации о повседневных вещах, формируя глубокое понимание, которое трудно воспроизвести с помощью алгоритмов, основанных исключительно на статистическом анализе и сопоставлении шаблонов. Таким образом, способность к распознаванию образов, являясь сильной стороной LLM, одновременно подчеркивает их слабость в решении задач, требующих базового понимания мира, которое у человека формируется с самого рождения.
Для успешной ориентации в социальных взаимодействиях и сложных ситуациях недостаточно простого выявления статистических закономерностей в данных. Исследования показывают, что понимание намерений других людей и умение учитывать их точку зрения — ключевые факторы, определяющие адекватное поведение. Модели, основанные исключительно на корреляциях, часто не способны предвидеть действия, мотивированные внутренними убеждениями или скрытыми целями. Способность к эмпатии и пониманию чужой перспективы позволяет не только прогнозировать поведение, но и строить эффективные стратегии взаимодействия, что требует от системы способности к моделированию «теории разума» — представления о том, как функционирует разум другого человека.
Теория Разума: Основа для Продвинутой Оценки БЯМ
Теория разума (ToM), или способность приписывать ментальные состояния другим, является фундаментальным аспектом социального интеллекта и эффективной коммуникации. Она предполагает понимание того, что у других людей могут быть убеждения, желания, намерения и знания, отличные от собственных, и использование этого понимания для предсказания и интерпретации их поведения. Способность к ToM позволяет учитывать перспективу другого человека, что критически важно для успешного взаимодействия, сотрудничества и разрешения конфликтов. Недостаточное развитие ToM может приводить к сложностям в социальных взаимодействиях и непониманию намерений других людей.
Оценка способности больших языковых моделей (LLM) к теории разума (ToM) требует использования бенчмарков, выходящих за рамки простого вопросно-ответного формата. Традиционные тесты, основанные на поиске фактов, не позволяют выявить понимание модели ментальных состояний других агентов, таких как убеждения, желания и намерения. Необходимы специализированные наборы данных и метрики, которые проверяют способность модели делать выводы о психологических состояниях, предсказывать поведение на основе этих состояний и учитывать, что убеждения других могут отличаться от ее собственных или от действительности. Эффективная оценка требует от LLM не просто воспроизведения информации, а демонстрации способности к моделированию разума других.
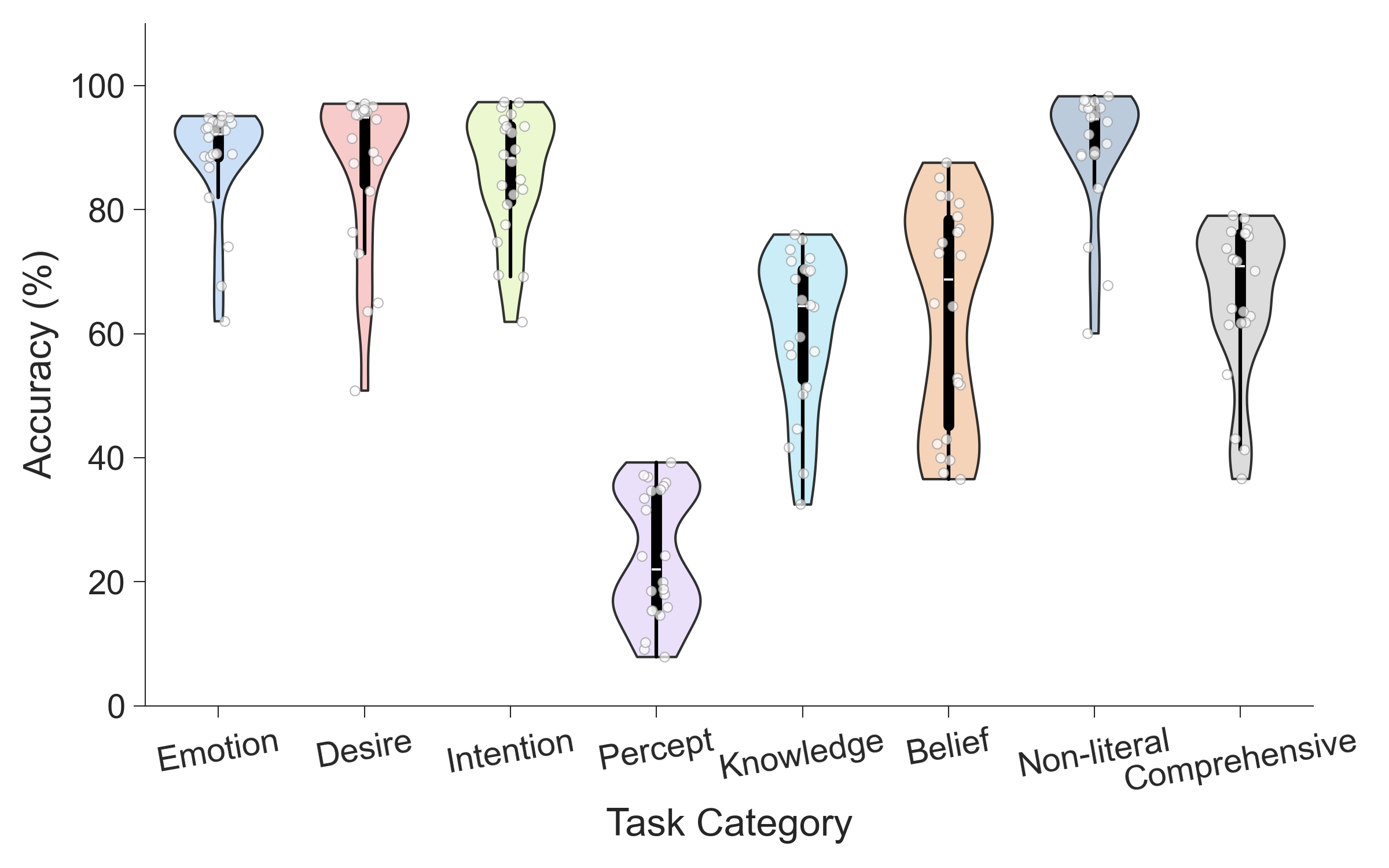
Фреймворк ATOMS (Attributing Thoughts, Observations, Motivations, and Self) представляет собой психологически обоснованную систему классификации и оценки различных компонентов теории разума (ToM). Вместо оценки ToM как единого целого, ATOMS разбивает ее на отдельные, измеримые аспекты: понимание убеждений других (Beliefs), интерпретацию наблюдений (Observations), распознавание мотиваций (Motivations) и осознание собственных ментальных состояний (Self). Этот гранулярный подход позволяет более точно диагностировать сильные и слабые стороны языковых моделей в области понимания ментальных состояний, предоставляя детальную картину их способностей в моделировании когнитивных процессов других агентов. Каждый компонент ATOMS оценивается посредством специализированных тестов, разработанных для проверки конкретных аспектов ToM, что обеспечивает более объективную и информативную оценку, чем традиционные методы.
CogToM: Комплексный Бенчмарк для Оценки Теории Разума
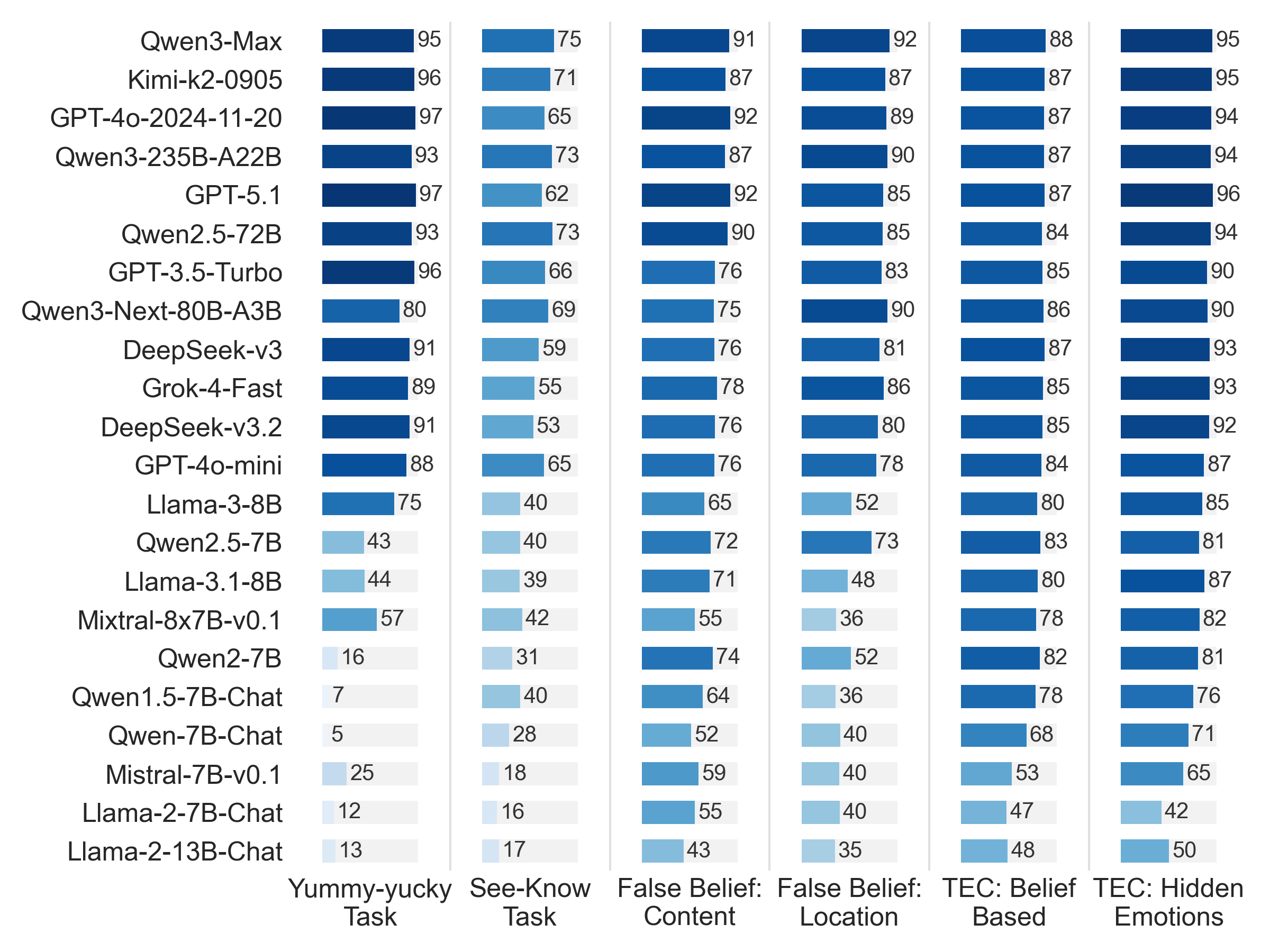
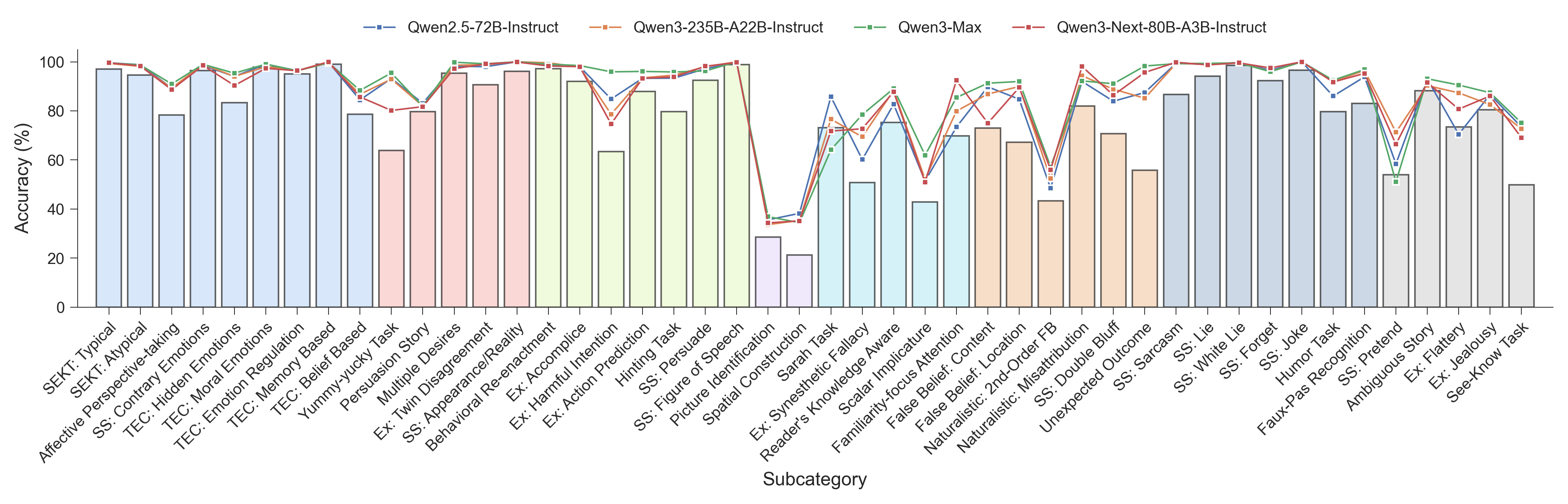
CogToM представляет собой новую комплексную оценку, предназначенную для анализа способности больших языковых моделей (LLM) к пониманию теории разума. В отличие от существующих, ограниченных по охвату тестов, CogToM включает в себя 46 различных задач, суммарно состоящих из более чем 8000 примеров. Такой масштаб позволяет более полно и точно оценить способность моделей к моделированию ментальных состояний других агентов и прогнозированию их поведения в сложных социальных ситуациях. Разработка данного бенчмарка направлена на преодоление ограничений существующих методов оценки ToM и обеспечение более надежной и всесторонней оценки прогресса в области искусственного интеллекта.
Бенчмарк CogToM использует двуязычный набор данных, включающий тексты на китайском и английском языках, для оценки способности больших языковых моделей (LLM) к рассуждениям, требующим понимания теории разума (ToM) в кросс-лингвистическом контексте. Применение двуязычного подхода позволяет проверить устойчивость моделей к языковым особенностям и обеспечить более широкую обобщающую способность результатов оценки, поскольку модели вынуждены демонстрировать понимание ToM независимо от используемого языка. Это обеспечивает более надежную и объективную оценку, чем использование данных только на одном языке.
Конструкция бенчмарка CogToM специально ориентирована на широкое покрытие задач, включающих разнообразные сценарии, требующие понимания убеждений второго порядка и сложной социальной динамики. Это означает, что помимо оценки способности модели понимать простые убеждения других агентов, CogToM также проверяет способность модели рассуждать о том, что один агент думает о том, что другой агент думает. Включенные сценарии моделируют ситуации, требующие понимания намерений, обмана, сотрудничества и других сложных социальных взаимодействий, что позволяет более полно оценить возможности языковых моделей в области понимания теории разума.
Высокий уровень согласованности между аннотаторами, достигающий значительных показателей, подтверждает четкость и объективность задач, включенных в CogToM. Этот показатель, измеренный с использованием стандартных метрик, демонстрирует, что задачи сформулированы таким образом, чтобы исключить неоднозначность и субъективные интерпретации. В результате, CogToM обеспечивает надежные и воспроизводимые метрики оценки для моделей, демонстрирующих понимание теории разума, поскольку различия в оценках, вызванные неясностью задач, сведены к минимуму. Согласованность аннотаторов была проверена на всем наборе данных, что гарантирует общую надежность результатов оценки.
Влияние на Развитие БЯМ и Перспективы Искусственного Интеллекта
Строгая оценка теории разума (ToM), осуществляемая благодаря инструменту CogToM, существенно расширяет границы возможностей языковых моделей. Для достижения высоких результатов в понимании ментальных состояний других агентов, LLM требуется не просто хранить знания, но и уметь логически рассуждать о них, выстраивая сложные модели убеждений, намерений и эмоций. Это, в свою очередь, требует разработки принципиально новых архитектур, способных к более глубокому и гибкому представлению знаний, а также к сложным процессам дедукции и индукции. Подобный прогресс в области ToM не только улучшает способность моделей к генерации связного и контекстуально релевантного текста, но и открывает путь к созданию искусственного интеллекта, способного к более естественному и эффективному взаимодействию с человеком.
Анализ результатов тестирования как открытых, так и проприетарных языковых моделей выявил существенную зависимость способности к пониманию чужих убеждений (Theory of Mind) от масштаба модели и объема используемых данных для обучения. Исследования показали, что увеличение числа параметров и расширение обучающей выборки закономерно повышают точность выполнения задач, требующих понимания намерений и перспектив других агентов. Полученные данные позволяют сформулировать эмпирические зависимости, описывающие связь между размером модели, объемом данных и уровнем ее способности к моделированию психических состояний, что является важным шагом на пути к созданию более совершенных и «разумных» искусственных интеллектов. Эти наблюдения вносят вклад в понимание так называемых «законов масштабирования» в области искусственного интеллекта и позволяют более эффективно планировать развитие будущих языковых моделей.
Оценка моделей обработки естественного языка с использованием CogToM выявила значительное снижение точности — до 62% — при решении задач, требующих понимания визуальной информации и соотнесения её с знаниями, известных как задачи «See-Know». Этот результат наглядно демонстрирует сложность для искусственного интеллекта задач, связанных с перцептивным рассуждением, и подтверждает принцип, известный как парадокс Моравека. Суть парадокса заключается в том, что задачи, кажущиеся простыми для человека, например, распознавание объектов или интерпретация визуальной сцены, представляют значительную трудность для современных систем искусственного интеллекта, в то время как сложные абстрактные вычисления, наоборот, выполняются машинами относительно легко. Полученные данные подчеркивают, что для достижения более высокого уровня искусственного интеллекта необходимо уделять особое внимание развитию способностей к перцептивному мышлению и интеграции визуальной информации с существующими знаниями.
Анализ результатов оценки способности моделей к пониманию теорий разума (ToM) выявил интересную закономерность: высокая степень согласованности между оценками, данными разными людьми, коррелирует с высокой точностью моделей — за исключением задач, требующих восприятия и понимания визуальной информации. Этот феномен, известный как парадокс Морвека, демонстрирует, что задачи, кажущиеся простыми для человека, например, распознавание объектов или интерпретация сцены, представляют значительную сложность для современных языковых моделей. В то время как модели успешно справляются с абстрактными рассуждениями и логическими выводами, требующими обработки символьной информации, их производительность резко снижается при обработке сенсорных данных, подчеркивая разрыв между человеческим и машинным интеллектом в области восприятия и обработки визуальной информации.
Развитие способности к теории разума (ToM) у больших языковых моделей (LLM) имеет далеко идущие последствия для создания искусственного общего интеллекта (AGI). Овладение LLM пониманием намерений, убеждений и перспектив других агентов открывает путь к принципиально новым формам взаимодействия человека и машины. Вместо простого выполнения команд, LLM с развитой ToM смогут адаптироваться к контексту, предвидеть потребности пользователя и реагировать на неявные сигналы, обеспечивая более плавное и интуитивно понятное общение. Это особенно важно для создания систем, способных к сотрудничеству, обучению на основе обратной связи и эффективному разрешению сложных ситуаций, требующих понимания социальных норм и эмоционального интеллекта. Таким образом, прогресс в области ToM не просто расширяет возможности LLM, но и является ключевым шагом на пути к созданию действительно интеллектуальных и отзывчивых искусственных систем.
Успешное наделение больших языковых моделей способностью к теории разума является ключевым фактором для создания искусственного интеллекта, способного к эффективному сотрудничеству, эмпатии и ориентации в сложных социальных ситуациях. Неспособность понимать намерения, убеждения и эмоциональное состояние других существ ограничивает потенциал ИИ в задачах, требующих тонкого социального взаимодействия, таких как ведение переговоров, предоставление помощи или просто поддержание содержательной беседы. Развитие этой способности позволит создать системы, которые не просто обрабатывают информацию, но и предвидят действия других, адаптируются к их потребностям и выстраивают доверительные отношения. В конечном итоге, наделение ИИ теорией разума — это шаг к созданию действительно интеллектуальных систем, способных к полноценному взаимодействию с окружающим миром и людьми.
Без чёткого определения задачи любое решение — шум. Данная работа демонстрирует эту истину, представляя CogToM — комплексный набор тестов для оценки способности больших языковых моделей к пониманию теории разума. Исследователи выявляют расхождения между когнитивными процессами ИИ и человека, что подчеркивает необходимость строгого определения критериев оценки. Ведь прежде чем оценивать «разумность» модели, необходимо точно определить, что подразумевается под «пониманием» и как это измерить. Отсутствие четких границ приводит к субъективным интерпретациям и нерелевантным результатам. Как однажды заметил Линус Торвальдс: «Разговорчивость — это враг ясности». Это применимо и к научным исследованиям: лаконичность и точность формулировок — залог достоверности выводов.
Куда же дальше?
Представленный набор данных CogToM, несомненно, выявляет несоответствия между способностью больших языковых моделей к моделированию теории разума и, как принято считать, человеческим когнитивным процессам. Однако, следует признать, что сам факт успешного прохождения тестов машиной не гарантирует истинного понимания. Скорее, это демонстрация умения оперировать символами, отражающими внешние проявления ментальных состояний, а не их внутреннего переживания.
Ключевой вопрос, требующий дальнейшего исследования, заключается в определении критериев, по которым можно было бы отличить подлинное понимание от статистической имитации. Необходимо разработать тесты, которые выходили бы за рамки простого предсказания поведения, и требовали бы от модели демонстрации способности к контрфактическому мышлению, способности к обнаружению ошибочных убеждений, основанных на неполной информации, и, что наиболее сложно, способности к самоанализу.
В конечном счёте, задача заключается не в создании машин, способных притворяться, что они понимают других, а в разработке алгоритмов, которые могли бы продемонстрировать принципиально иную форму интеллекта, не основанную на антропоморфных аналогиях. Любая избыточность в коде, любая попытка упростить сложность человеческого разума, должна быть беспощадно отброшена. Простота — это не всегда элегантность; иногда это признак неполноты.
Оригинал статьи: https://arxiv.org/pdf/2601.15628.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-24 20:05