Автор: Денис Аветисян
Новый метод, основанный на анализе критических симптомов и абдуктивных объяснениях, позволяет оценить и улучшить соответствие между логикой искусственного интеллекта и принятием клинических решений.
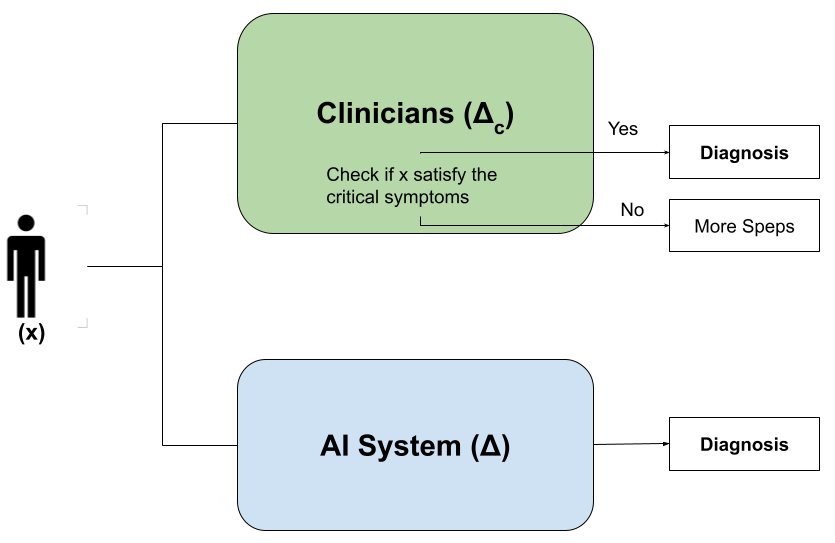
Исследование предлагает методологию использования абдуктивных объяснений и анализа критических симптомов для повышения согласованности между рассуждениями ИИ и клиническим мышлением в медицинской диагностике.
Несмотря на впечатляющие успехи искусственного интеллекта в клинической диагностике, его рассуждения часто расходятся со структурированными подходами, принятыми в медицине. В статье ‘Bridging AI and Clinical Reasoning: Abductive Explanations for Alignment on Critical Symptoms’ предложен метод, использующий формальные адуктивные объяснения для выявления и согласования ключевых симптомов, важных для принятия клинических решений. Разработанный подход позволяет не только сохранить прогностическую точность, но и обеспечить прозрачность и интерпретируемость логики работы ИИ. Позволит ли это создать действительно надежные и доверенные системы искусственного интеллекта для поддержки врачей в сложных диагностических задачах?
Диагностическая дилемма: ИИ и клиническое мышление
Несмотря на растущую роль искусственного интеллекта в диагностике заболеваний, существует существенный разрыв между его прогнозами и устоявшимися процессами клинического мышления. Врачи традиционно полагаются на комплексный анализ симптомов, анамнеза и результатов исследований, формируя диагностическую гипотезу на основе глубокого понимания патофизиологии. В отличие от этого, многие системы искусственного интеллекта, хоть и способны выявлять закономерности в больших данных, часто не предоставляют четкого объяснения своих выводов. Это несоответствие подрывает доверие к результатам, полученным с помощью ИИ, и затрудняет их интеграцию в повседневную клиническую практику, поскольку врачу необходимо понимать почему система пришла к определенному заключению, а не просто что она предсказывает.
Несмотря на растущую роль искусственного интеллекта в диагностике, существенное расхождение наблюдается между его предсказаниями и устоявшимися принципами клинического мышления. Это несоответствие обусловлено так называемой «черной коробкой» многих моделей ИИ, что затрудняет понимание логики принятия решений. Количественный анализ, проведенный на наборе данных о раке молочной железы с использованием нейронной сети, выявил, что примерно в 14% случаев предсказания модели не соответствуют логике, применяемой врачами-клиницистами. Данный факт создает препятствия для доверия к системам ИИ и их эффективной интеграции в клиническую практику, поскольку отсутствие прозрачности в процессе принятия решений может вызывать обоснованные опасения у медицинского персонала.
Отсутствие прозрачности в процессе принятия решений искусственным интеллектом представляет собой серьезную проблему как для врачей, так и для пациентов. Когда алгоритм выдает диагноз или рекомендацию, но логика, лежащая в основе этого заключения, остается непонятной, возникает недоверие и затрудняется возможность критической оценки. Врачи, лишенные понимания того, как ИИ пришел к определенному выводу, испытывают сложности с интеграцией этих технологий в свою практику, опасаясь полагаться на «черный ящик». Пациенты, в свою очередь, нуждаются в объяснении, почему был поставлен тот или иной диагноз, и не могут получить его, если решение принято непрозрачным алгоритмом. Это порождает тревогу, снижает приверженность лечению и может привести к отказу от медицинской помощи, основанной на рекомендациях ИИ. Таким образом, преодоление этой непрозрачности является ключевым условием для успешного внедрения искусственного интеллекта в здравоохранение и обеспечения доверия со стороны всех заинтересованных сторон.
Вскрывая «черный ящик»: Подходы объяснимого ИИ
Методы постобработки, такие как SHAP (SHapley Additive exPlanations) и LIME (Local Interpretable Model-agnostic Explanations), предназначены для повышения прозрачности моделей машинного обучения путем выявления наиболее значимых признаков, влияющих на конкретные прогнозы. SHAP использует принципы теории игр для определения вклада каждого признака в предсказание, обеспечивая глобальную интерпретируемость. LIME, в свою очередь, приближает поведение сложной модели локально линейной моделью вокруг конкретного экземпляра данных, позволяя понять, какие признаки были наиболее важны для этого конкретного предсказания. Оба подхода не требуют изменений в самой модели и могут быть применены к любым моделям машинного обучения, что делает их ценными инструментами для анализа и отладки.
Абдуктивное объяснение представляет собой формальный метод интерпретации решений моделей искусственного интеллекта, отличающийся от пост-хок техник, таких как SHAP и LIME. Вместо оценки вклада каждой характеристики, абдуктивное объяснение стремится определить минимальный набор признаков, достаточный для обоснования конкретного предсказания модели. Это достигается путем поиска наименьшего подмножества входных данных, которое, при подаче в модель, приводит к тому же результату, что и исходный набор данных. Фактически, это позволяет выявить критически важные признаки, без которых предсказание было бы невозможно, предоставляя более четкое и строго обоснованное объяснение логики принятия решений.
Несмотря на ценность методов пост-хок объяснения, таких как SHAP и LIME, а также абдуктивных объяснений, необходимо проводить их строгую проверку и валидацию для обеспечения соответствия объяснений фактическому поведению модели. Это включает в себя тестирование на различных наборах данных, оценку стабильности объяснений при небольших изменениях входных данных, и сравнение объяснений с экспертными знаниями в предметной области. Отсутствие валидации может привести к ложным интерпретациям, неверным выводам и, как следствие, к ошибочным решениям, основанным на ненадежных объяснениях работы модели. Важно учитывать, что объяснения являются лишь приближением к внутренним процессам модели и не всегда полностью отражают ее сложное поведение.
Валидация и сравнение: Наборы данных и модели
Для оценки возможностей ИИ в области диагностики используются три ключевых набора данных: Cleveland Heart Disease Dataset, Wisconsin Diagnostic Breast Cancer Dataset и Mental Health in Tech Survey Dataset. Cleveland Heart Disease Dataset содержит информацию о пациентах с сердечно-сосудистыми заболеваниями, позволяя оценивать точность выявления признаков заболевания. Wisconsin Diagnostic Breast Cancer Dataset предоставляет данные о случаях рака молочной железы, служа для оценки моделей в задаче классификации злокачественных и доброкачественных новообразований. Mental Health in Tech Survey Dataset, в свою очередь, содержит анонимные ответы респондентов, что позволяет оценивать возможности ИИ в области диагностики психического здоровья и выявления факторов риска. Использование этих наборов данных обеспечивает стандартизированный подход к оценке и сравнению различных моделей и алгоритмов диагностики.
В качестве сравнительных базовых моделей используются алгоритмы логистической регрессии и нейронные сети, что позволяет оценить прирост объяснимости, достигаемый при использовании более сложных методов интерпретации. Логистическая регрессия, благодаря своей линейности и простоте, предоставляет четкую и понятную интерпретацию весов признаков, в то время как нейронные сети, обладая большей выразительной способностью, требуют дополнительных техник для объяснения своих предсказаний. Сравнение результатов, полученных с использованием этих базовых моделей и более сложных методов объяснимого ИИ, позволяет количественно оценить, насколько улучшается понимание процесса принятия решений и насколько успешно новые методы преодолевают ограничения, присущие традиционным алгоритмам.
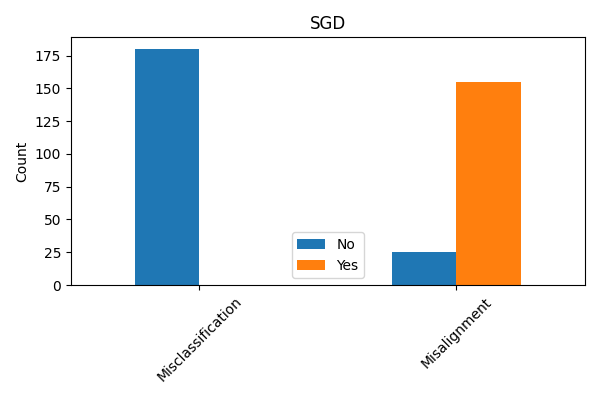
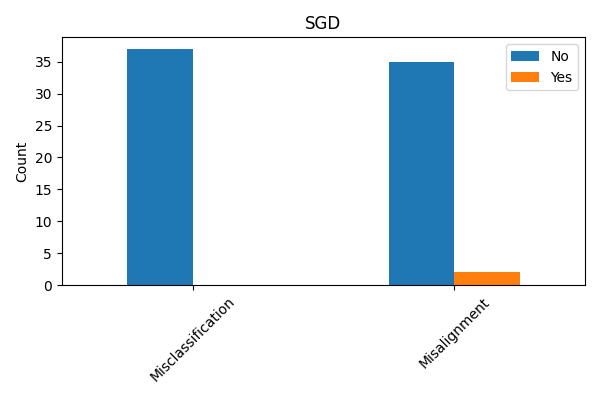
Для количественной оценки эффективности методов объяснения решений моделей машинного обучения, помимо стандартной метрики точности, необходимы строгие оценочные метрики, позволяющие измерить степень соответствия объяснений фактическому поведению модели (fidelity) и их интерпретируемость. Проведенные исследования с использованием набора данных о сердечно-сосудистых заболеваниях (Cleveland Heart Disease Dataset) и модели стохастического градиентного спуска (SGD) показали, что примерно в 6% случаев объяснения, предоставляемые моделью, не соответствуют реальным факторам, влияющим на предсказание. Данный показатель демонстрирует наличие расхождений между объяснением и истинным поведением модели, подчеркивая важность использования дополнительных метрик для более полной оценки качества объяснений.
Анализ данных выявил существенные различия в степени соответствия между наборами данных. В наборе данных по диагностике рака молочной железы (Wisconsin Diagnostic Breast Cancer Dataset) было идентифицировано критическое свойство, охватывающее 180 случаев, в то время как в наборе данных по заболеваниям сердца (Cleveland Heart Disease Dataset) аналогичное свойство было выявлено лишь в 37 случаях. Данный разброс указывает на то, что эффективность и применимость методов интерпретации ИИ может существенно варьироваться в зависимости от специфики используемого набора данных и лежащих в его основе характеристик.
Соединяя разрозненное: Влияние и перспективы
Повышенная прозрачность искусственного интеллекта (ИИ) играет ключевую роль в формировании доверия со стороны медицинских работников, что, в свою очередь, облегчает интеграцию этих систем в клиническую практику. Когда алгоритмы ИИ не являются «черным ящиком», а предоставляют понятные объяснения своих выводов, врачи могут более уверенно использовать их в качестве вспомогательного инструмента, а не полагаться на них слепо. Это особенно важно в критических ситуациях, где требуется тщательная оценка и подтверждение диагноза. Улучшенная интерпретируемость позволяет специалистам сопоставлять предсказания ИИ со своими знаниями и опытом, выявлять потенциальные ошибки и принимать обоснованные решения, что в конечном итоге повышает качество медицинской помощи и безопасность пациентов.
Исследования показывают, что выявление ключевых симптомов, определяющих прогнозы искусственного интеллекта, значительно расширяет возможности врачей в процессе клинического мышления. Вместо слепого доверия к алгоритмам, специалисты получают возможность понять, на основании каких конкретно признаков была сделана та или иная диагностическая оценка. Это не заменяет, а скорее дополняет опыт врача, позволяя более глубоко анализировать клиническую картину, выявлять потенциальные ошибки и принимать обоснованные решения. Таким образом, методы, акцентирующие внимание на критических симптомах, способствуют не просто автоматизации диагностики, а укреплению взаимосвязи между искусственным интеллектом и профессиональным суждением врача, что в конечном итоге повышает качество медицинской помощи.
Перспективные исследования направлены на создание более надежных и масштабируемых методов объяснения работы систем искусственного интеллекта, что позволит преодолеть существующие ограничения в их применении. Особое внимание уделяется возможности адаптации этих методов к задачам персонализированной медицины, где индивидуальные особенности пациента играют ключевую роль. Разработка таких инструментов позволит не только понимать логику принятия решений искусственным интеллектом, но и учитывать уникальные характеристики каждого пациента для повышения точности диагностики и эффективности лечения. Это предполагает создание алгоритмов, способных генерировать объяснения, понятные врачам, и интегрировать их в клиническую практику, открывая новые возможности для улучшения качества медицинской помощи.
Исследование, посвященное выстраиванию соответствия между логикой искусственного интеллекта и клиническим мышлением, закономерно напоминает о вечной борьбе теории и практики. Авторы предлагают использовать адуктивные объяснения для анализа критически важных симптомов, стремясь к соответствию между признаками, используемыми ИИ, и теми, на которые обращают внимание врачи. Как метко заметил Дональд Дэвис: «Продукция всегда найдёт способ сломать элегантную теорию». Именно поэтому попытки добиться идеального соответствия между моделью и реальностью — задача бесконечная, но необходимая. Иначе, все эти адуктивные объяснения останутся лишь красивой абстракцией, не способной выдержать суровую проверку клинической практики. Ведь, в конечном счете, важна не элегантность алгоритма, а его способность не давать сбоев в понедельник.
Что дальше?
Предложенная методология, безусловно, добавляет ещё один уровень сложности в и без того запутанную проблему выравнивания искусственного интеллекта и клинической практики. Однако, стоит помнить, что каждая элегантная схема рано или поздно столкнётся с реальностью — с неполнотой данных, с изменчивостью симптоматики, и, конечно же, с неизбежной необходимостью “латать дыры” в продакшене. Анализ критических симптомов — полезный инструмент, но он лишь задерживает неизбежное — поиск новых, ещё более сложных паттернов, которые система рано или поздно начнёт интерпретировать не совсем так, как ожидалось.
Очевидно, что простого выравнивания по признакам недостаточно. Неизбежен переход к моделям, учитывающим контекст, историю болезни, и, что самое сложное, неопределённость. Иначе говоря, необходимо научить систему не просто “диагностировать”, а “справляться с диагнозом” — то есть, принимать решения в условиях неполной информации и высокой вероятности ошибки. А это уже, как известно, область, где даже опытные врачи не всегда преуспевают.
В конечном счёте, все эти “инструменты выравнивания” — лишь временные меры. Система продолжит развиваться, а вместе с ней и её способность находить неожиданные (и не всегда полезные) решения. И тогда придётся снова пересматривать принципы, искать новые признаки, и, возможно, смириться с тем, что идеального выравнивания не существует. Ведь, как гласит старая истина, мы не чиним продакшен — мы просто продлеваем его страдания.
Оригинал статьи: https://arxiv.org/pdf/2602.13985.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Языковые модели и границы возможного: что делает язык человеческим?
- Визуальное мышление машин: новый вызов для ИИ
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Разумные языковые модели: новый подход к логическому мышлению
- Взрыв скорости: Оптимизация внимания для современных GPU
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Ребусы для ИИ: новый масштабный тест на сообразительность
- Квантовый разум: Новая эра языковых моделей
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Обучение языковых моделей по предпочтениям: новый подход к повышению точности
2026-02-17 10:03