Автор: Денис Аветисян
Новая модель SAM 3 и бенчмарк SA-Co открывают возможности для точной сегментации изображений и видео, основываясь на концептуальных запросах.
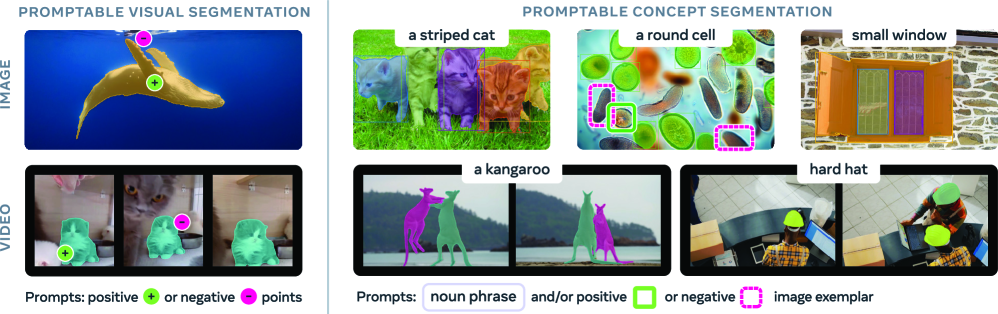
SAM 3 отделяет распознавание, локализацию и отслеживание объектов, используя движок данных с аннотациями, созданными как людьми, так и искусственным интеллектом.
Несмотря на значительные успехи в области компьютерного зрения, выделение и отслеживание объектов по словесным описаниям остается сложной задачей. В настоящей работе представлена модель SAM 3: Segment Anything with Concepts, объединяющая обнаружение, сегментацию и отслеживание объектов в изображениях и видео на основе концептуальных подсказок, включающих как текстовые фразы, так и визуальные примеры. Достигнуто двукратное повышение точности в задачах концептуальной сегментации изображений и видео благодаря разделению процессов распознавания, локализации и отслеживания, а также использованию масштабируемого движка для создания высококачественного набора данных. Открывает ли это новые горизонты для создания интеллектуальных систем, способных к гибкому и интуитивному взаимодействию с визуальным миром?
Трудности точного понимания визуального мира
Традиционные методы сегментации изображений зачастую сталкиваются с трудностями при анализе сложных, реалистичных сцен. Они демонстрируют ограниченную способность к точному выделению объектов и понятий, требующих детального понимания контекста и мелких визуальных признаков. Например, попытка автоматического определения различных пород собак или типов листьев растений часто приводит к неточностям, поскольку алгоритмы не способны уловить тонкие различия, заметные для человеческого глаза. Это связано с тем, что существующие подходы ориентированы на выделение заранее определенных категорий, а не на гибкое распознавание произвольных объектов или понятий в контексте сложной визуальной информации. В результате, точность сегментации значительно снижается при переходе от контролируемых лабораторных условий к реальным, зашумленным изображениям с множеством перекрывающихся объектов.
Определение и сегментация произвольных концепций, то есть объектов или явлений, не включенных в обучающую выборку, продолжает оставаться серьезным вызовом для визуального искусственного интеллекта. Существующие алгоритмы, как правило, ограничены заранее заданными категориями, что препятствует их адаптации к новым, неожиданным объектам в реальном мире. Именно эта неспособность к обобщению и пониманию новых концепций, не встречавшихся ранее, является ключевым препятствием на пути к созданию действительно универсальных и гибких систем компьютерного зрения, способных эффективно работать в сложных и непредсказуемых условиях.
Существующие методы сегментации изображений, требующие индивидуального обучения для каждого нового понятия, создают значительные трудности в масштабировании систем, способных понимать произвольные запросы. Традиционно, для распознавания и выделения объектов на изображениях, модели нуждаются в большом количестве размеченных данных для каждого конкретного объекта или категории. Это означает, что при появлении нового объекта, который модель ранее не видела, необходимо повторное обучение с использованием нового набора данных. Такой подход не только трудоемок, но и ограничивает возможности оперативного реагирования на изменяющиеся условия и новые потребности, особенно в задачах, требующих быстрой адаптации к новым визуальным концепциям. В результате, масштабируемость систем, способных к сегментации по запросу, становится серьезным препятствием для развития более гибких и универсальных систем компьютерного зрения.

SAM3: Основа для сегментации по запросу
SAM3 расширяет функциональность SAM2, обеспечивая возможность сегментации как по текстовым, так и по визуальным запросам. Это позволяет реализовать сегментацию по произвольным запросам (open-vocabulary segmentation), то есть создавать маски объектов, не ограничиваясь заранее определенными категориями. В отличие от предыдущих моделей, требующих обучения для каждой категории объектов, SAM3 может сегментировать объекты, описанные в текстовом запросе, или на основе визуального примера, представленного на изображении. Данная возможность достигается за счет использования архитектуры, способной эффективно сопоставлять текстовые и визуальные признаки с областями изображения, определяя границы объектов.
Архитектура SAM3 характеризуется модульным дизайном, включающим общий энкодер зрения (Vision Encoder), который обрабатывает входное изображение для извлечения признаков, используемых всеми последующими компонентами. Ключевым элементом является отделение задач распознавания объектов и определения их местоположения посредством “головы присутствия” (Presence Head). Эта “голова” отвечает за прогнозирование наличия объекта в каждом пикселе изображения, что позволяет отделить задачу классификации от точного определения границ объекта, повышая эффективность и точность сегментации.
В основе SAM3 лежит архитектура обнаружения объектов DETR (DEtection TRansformer), что позволяет эффективно обрабатывать видеопоследовательности. DETR использует трансформеры для прямого предсказания множества объектов, устраняя необходимость в ручном определении предложений или этапах постобработки, характерных для традиционных методов. В сочетании с подходом Tracking-by-Detection, SAM3 последовательно отслеживает объекты между кадрами видео, используя обнаруженные объекты в предыдущем кадре в качестве отправной точки для следующего. Это значительно снижает вычислительные затраты, так как не требуется пересчитывать обнаружения с нуля для каждого кадра, а позволяет использовать информацию из предыдущих кадров для повышения скорости и точности сегментации в видео.

Создание и контроль качества данных для обучения
Для создания высококачественного обучающего набора данных для SAM3 используется Data Engine, который объединяет работу людей-аннотаторов и ИИ-верификаторов. Люди-аннотаторы выполняют первичную разметку данных, а затем ИИ-верификаторы автоматически проверяют и подтверждают качество этой разметки. Такой гибридный подход позволяет сочетать точность ручной разметки с масштабируемостью автоматизированной проверки, обеспечивая формирование надежного и точного обучающего набора данных, необходимого для эффективной работы модели SAM3.
Для автоматизации проверки качества и полноты аннотаций используется система AI-верификаторов, основанная на моделях, таких как Llama3. Данная система позволяет повысить качество псевдо-меток, что приводит к улучшению метрики cgF1 на 7.2%. Автоматизированная проверка позволяет оперативно выявлять и корректировать неточности в аннотациях, обеспечивая более надежный и качественный набор обучающих данных для SAM3.
Гибридный подход к генерации данных сочетает в себе высокую точность ручной разметки, выполняемой людьми, с возможностью масштабирования, обеспечиваемой автоматизированной проверкой на основе искусственного интеллекта. Такая комбинация позволяет создать надежный обучающий набор данных для SAM3, поскольку человеческий фактор обеспечивает качество исходной разметки, а алгоритмы ИИ — эффективную проверку на полноту и корректность, что в совокупности повышает устойчивость и надежность модели.

Оценка и обобщение с использованием SA-Co
Модель SAM3 подверглась всестороннему тестированию на наборе данных SA-Co, который служит эталоном для сегментации объектов по текстовым запросам. Результаты демонстрируют передовые показатели, значительно превосходящие предыдущие системы — достигнуто двукратное увеличение эффективности. Данный набор данных позволяет оценить способность модели к точному выделению объектов на изображениях, основываясь исключительно на текстовых подсказках, что подтверждает значительный прогресс в области компьютерного зрения и понимания изображений.
Способность модели обобщать знания на ранее невиданные концепции обеспечивается использованием открытых вокабулярных моделей, таких как CLIP, DINOv и T-Rex2. Эти модели, предварительно обученные на огромных массивах данных, позволяют системе понимать и распознавать объекты и сцены, даже если они не встречались в процессе обучения. Благодаря этому, модель может успешно сегментировать изображения, содержащие новые, неизвестные концепции, без необходимости дополнительной переподготовки. Использование этих моделей значительно расширяет возможности применения системы в реальных условиях, где часто встречаются объекты и ситуации, не предусмотренные в обучающей выборке, и обеспечивает более надежную и универсальную работу.
Исследования показали, что модель SAM3 демонстрирует значительное улучшение в точности сегментации при использовании интерактивных подсказок в виде ограничивающих рамок. В частности, зафиксировано увеличение показателя cgF1 на 21,6 процентных пункта, что свидетельствует о более качественном выделении объектов на изображениях. Кроме того, модель продемонстрировала улучшение на 18,3 процентных пункта в метрике Average Precision на общепризнанном наборе данных COCO, подтверждая её способность к точной локализации объектов и снижению количества ложных срабатываний. Эти результаты указывают на высокую эффективность использования интерактивных подсказок для повышения производительности модели SAM3 в задачах компьютерного зрения.

Изучение модели SAM 3 и её способности к концептуальной сегментации напоминает алхимический поиск философского камня, способного преобразовывать хаос пикселей в осмысленные образы. Разделение процессов распознавания, локализации и отслеживания — это как разделение стихий, каждая из которых подчиняется своим законам, но в совокупности создаёт иллюзию порядка. Как заметил Ян Лекун: «Машинное обучение — это, по сути, построение сложных функций, которые аппроксимируют данные». Эта аппроксимация, подкреплённая данными, полученными как от человека, так и от искусственного интеллекта, позволяет модели SAM 3 «уговаривать» хаос изображений, выделяя нужные объекты с поразительной точностью. Подобно заклинанию, эффективность этой «функции» проверяется лишь в суровых условиях реальной эксплуатации.
Что дальше?
Представленное исследование, словно зеркало, отражает не столько достигнутое, сколько осознание границ. Разделение распознавания, локализации и отслеживания — элегантный трюк, но и лишь временная передышка. Ведь хаос, заключенный в данных, не поддается полному расщеплению. Этот “движок данных”, напичканный аннотациями людскими и машинным разумом, лишь отсрочивает неизбежное столкновение с непредсказуемостью.
Вопрос не в том, чтобы научить машину “видеть” концепции, а в том, чтобы смириться с её неспособностью постичь их во всей полноте. Каждая сегментация — это не приближение к истине, а лишь проекция вероятностей на ткань реальности. Будущее, вероятно, лежит не в совершенствовании алгоритмов, а в разработке инструментов, позволяющих нам взаимодействовать с этой неточностью, принимать её как данность.
Пока же, SA-Co, словно красивый артефакт, заманивает исследователей в ловушку иллюзий. Следующий шаг — не улучшение метрик, а признание того, что любая модель — это заклинание, работающее до первого же кадра, не вписывающегося в предсказанный узор. И тогда, возможно, мы сможем увидеть истину, прячущуюся за пределами агрегатов.
Оригинал статьи: https://arxiv.org/pdf/2511.16719.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовые прорывы: Хорошее, плохое и смешное
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Квантовая криптография: от теории к практике
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Лунный гелий-3: Охлаждение квантового будущего
2025-11-24 07:58