Автор: Денис Аветисян
В статье представлен обзор новой парадигмы в развитии больших языковых моделей — создания искусственных агентов, способных к самостоятельному выполнению задач.
![Архитектура прогрессивного раскрытия навыков агента оптимизирует потребление контекстного окна, загружая информацию в три этапа, при этом обеспечивая доступ к произвольно глубоким процедурным знаниям, а оценки количества токенов, представленные как усреднённые значения для каждого навыка, демонстрируют эффективность данной стратегии, основанной на исследованиях Чжан, Лазука и Мурага [35].](https://arxiv.org/html/2602.12430v1/x1.png)
Обзор архитектуры, методов обучения, вопросов безопасности и перспектив развития навыков для интеллектуальных агентов на базе больших языковых моделей.
Традиционные большие языковые модели (LLM) часто страдают от негибкости и сложности обновления знаний без переобучения. В настоящем обзоре, озаглавленном ‘Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward’, рассматривается новый подход, основанный на модульных «навыках» агентов — компонуемых пакетах инструкций, кода и ресурсов, позволяющих динамически расширять возможности LLM без повторного обучения. Предлагается всесторонний анализ архитектурных основ, методов приобретения навыков, масштабирования развертывания и, что особенно важно, вопросов безопасности, с предложением системы управления жизненным циклом навыков для обеспечения надежности. Какие шаги необходимы для создания самообучающихся и безопасных экосистем навыков, способных раскрыть весь потенциал агентов на основе LLM?
За гранью фундаментальных моделей: рождение навыков агентов
Несмотря на впечатляющий объем общих знаний, которыми обладают большие языковые модели (БЯМ), они часто демонстрируют недостаток в специализированных процедурных навыках, необходимых для выполнения сложных задач. БЯМ превосходно справляются с генерацией текста и предоставлением информации, однако им не хватает способности последовательно и надежно применять знания для достижения конкретных целей. Например, БЯМ может описать процесс приготовления сложного блюда, но не сможет самостоятельно спланировать закупку продуктов, точно следовать рецепту и адаптироваться к неожиданным ситуациям на кухне. Это связано с тем, что обучение БЯМ фокусируется на статистических закономерностях в данных, а не на приобретении практических навыков и умении решать задачи, требующие планирования, логического мышления и адаптации к изменяющимся обстоятельствам. Таким образом, для создания действительно интеллектуальных агентов необходимо дополнить общие знания БЯМ специализированными процедурными навыками.
Традиционные методы, такие как извлечение информации для расширения знаний (RAG), часто оказываются недостаточными при решении сложных задач. Простое добавление новых данных к существующей базе знаний не обеспечивает структурированного руководства, необходимого для надежных действий. Хотя RAG и позволяет агентам получать доступ к актуальной информации, он не обучает их как эту информацию применять для конкретных целей или последовательно выполнять многошаговые процедуры. В результате, агенты, использующие только RAG, могут генерировать релевантные, но бесполезные ответы, или совершать ошибки из-за отсутствия понимания контекста и необходимых действий для достижения желаемого результата. Необходим переход к более сложным системам, которые не просто предоставляют знания, но и направляют агента в процессе принятия решений и выполнения задач.
Наблюдается переход к модульной и повторно используемой концепции “Навыков Агента” — парадигме, позволяющей наделять агентов специализированными знаниями по требованию. Вместо попыток охватить весь спектр задач, эта стратегия предполагает создание отдельных, автономных модулей, каждый из которых отвечает за конкретную функцию или процедуру. Такой подход позволяет агентам динамически собирать и комбинировать эти навыки, адаптируясь к изменяющимся обстоятельствам и эффективно решая сложные задачи. Вместо жестко запрограммированных алгоритмов, агенты получают возможность учиться и совершенствовать свои навыки, используя данные и обратную связь, что значительно повышает их гибкость и надежность. Данная методология открывает путь к созданию интеллектуальных систем, способных к самостоятельному обучению и решению проблем в реальном времени.
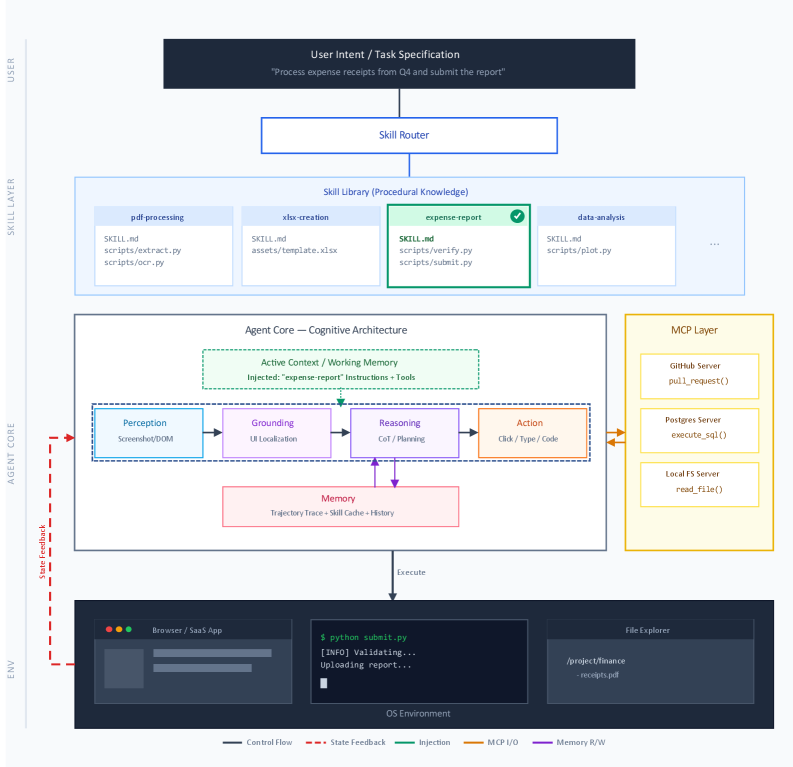
Структурирование экспертизы: SKILL.md и управление доверием
Файл SKILL.md представляет собой стандартизированный формат инструкций для определения навыка Агента. Он включает в себя четкое описание цели навыка, подробные инструкции по его выполнению и перечень необходимых ресурсов, таких как данные, инструменты или API. Структура файла позволяет однозначно определить функциональность навыка, обеспечивая предсказуемость и управляемость его работы в рамках общей системы. Использование этого формата упрощает процесс разработки, тестирования и развертывания навыков, а также облегчает их интеграцию с другими компонентами системы.
Принцип ограниченных возможностей доступа (Capability-Based Permissions) является ключевым элементом безопасности при работе с агентами и навыками. Вместо традиционных систем, основанных на ролях и привилегиях, каждый навык объявляет только те конкретные ресурсы и действия, которые ему необходимы для выполнения своей функции. Это позволяет существенно снизить риски, связанные с потенциальными уязвимостями и несанкционированным доступом. Ограничение области действия навыка до минимально необходимого набора прав доступа минимизирует ущерб в случае компрометации, так как злоумышленник не сможет получить доступ к ресурсам, не заявленным навыком в его описании.
Для обеспечения надежности и безопасности агентов, критически важна внедрение комплексной системы управления доверием и жизненным циклом навыков (Skill Trust and Lifecycle Governance Framework). Эта система включает в себя строгую верификацию целостности каждого навыка, охватывающую аудит исходного кода, проверку зависимостей и оценку потенциальных уязвимостей. Управление жизненным циклом предполагает регламентированные процедуры развертывания, обновления и вывода из эксплуатации навыков, а также мониторинг их производительности и безопасности в динамически меняющихся средах. Реализация такой системы позволяет минимизировать риски, связанные с использованием ненадежных или скомпрометированных навыков, и гарантировать соответствие требованиям безопасности и регуляторным нормам.
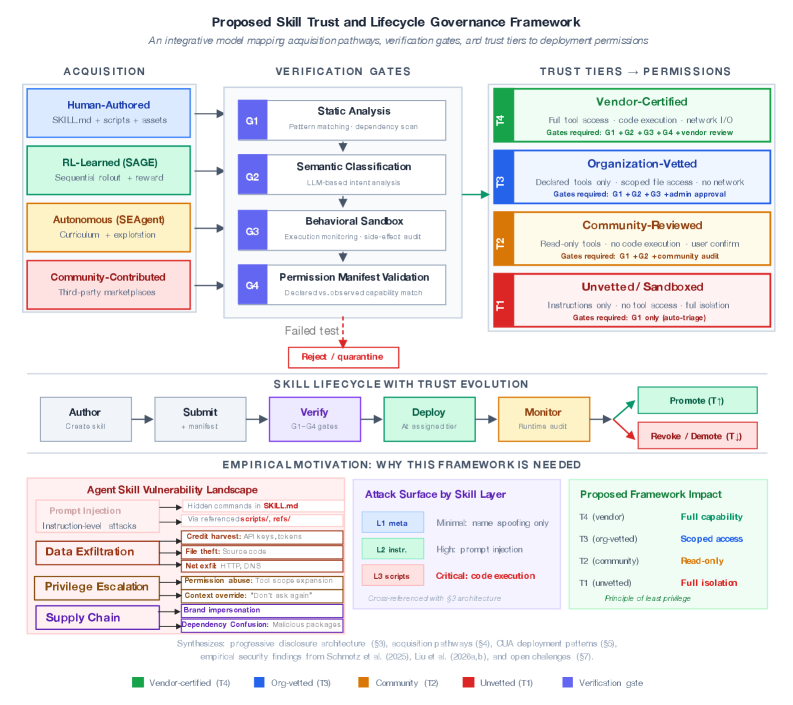
Автоматизация приобретения навыков: обнаружение и подкрепление
Автоматическое обнаружение навыков, продемонстрированное агентом SEAgent, позволяет агентам самостоятельно определять полезные действия в программной среде. В ходе экспериментов было зафиксировано, что SEAgent обеспечивает 34.5%-ный показатель успешного выполнения поставленных задач. Этот подход отличается от ручного определения навыков, требующего значительных временных затрат и экспертных знаний, и позволяет агентам адаптироваться к новым задачам без предварительной настройки. Эффективность автоматического обнаружения навыков заключается в способности агента исследовать среду и выявлять последовательности действий, приводящие к желаемому результату, что особенно важно в динамичных и сложных окружениях.
Метод обучения с подкреплением, представленный подходом SAGE, позволяет агентам осваивать навыки посредством проб и ошибок. В ходе экспериментов было установлено, что применение SAGE обеспечивает улучшение производительности на 8.9% по сравнению с базовым алгоритмом GRPO, функционирующим без использования предопределенных библиотек навыков. Это достигается за счет динамической адаптации стратегий агента на основе получаемой обратной связи, что позволяет оптимизировать действия для достижения поставленных целей в различных средах.
Для агентов, работающих с компьютерными приложениями, фреймворки, такие как CUA-Skill, используют параметризованные графы выполнения, представляющие собой структурированное представление навыков. В ходе тестирования, использование CUA-Skill позволило достичь 57.5% успешности выполнения задач, что демонстрирует значительное превосходство над подходами, не использующими структурированное представление навыков. Параметризация графа позволяет адаптировать навыки к различным сценариям и условиям, повышая общую эффективность агента.
Композиция интеллектуальных действий: комбинация навыков и эффективность
Принцип компоновки навыков позволяет решать сложные задачи путем декомпозиции на более простые, выполняемые специализированными модулями. Вместо попыток создать единый, универсальный алгоритм, система формирует последовательность узконаправленных навыков, каждый из которых отвечает за конкретный аспект задачи. Такой подход не только повышает надежность и точность выполнения, но и значительно упрощает процесс обучения и адаптации к новым ситуациям. Представьте, что для написания письма необходимо не одно умение «писать письмо», а последовательность: «определить адресата», «сформулировать тему», «написать текст», «отформатировать письмо», и «отправить письмо». Каждый из этих модулей может быть оптимизирован отдельно, а их комбинация обеспечивает эффективное решение сложной задачи, что особенно важно при работе с ограниченными ресурсами и в динамично меняющихся условиях.
Постепенное раскрытие навыков представляет собой стратегию оптимизации использования ресурсов, особенно актуальную для больших языковых моделей. Вместо загрузки всех необходимых навыков одновременно, система загружает их последовательно, по мере необходимости выполнения задачи. Такой подход позволяет существенно снизить потребление контекстного окна — объема информации, который модель может обработать за один раз. Это особенно важно при работе со сложными задачами, требующими обширного набора навыков, поскольку позволяет избежать перегрузки модели и сохранить высокую производительность даже при ограниченных вычислительных ресурсах. Благодаря постепенному раскрытию, система становится более эффективной и экономичной, сохраняя при этом способность решать сложные задачи и адаптироваться к новым условиям.
Система UI-TARS демонстрирует ощутимый прогресс в производительности агентов, работающих с графическим интерфейсом, что подтверждается результатами тестов на платформе OSWorld. В ходе экспериментов, UI-TARS показал на 18.9% более высокую точность выполнения задач по сравнению с моделями Claude Computer Use и предыдущей версией UI-TARS. Примечательно, что применение метода самообучения позволило добиться ещё более значительного улучшения — точность выросла на 47.3%. Эти результаты свидетельствуют об эффективности предложенного подхода к композиции навыков и оптимизации ресурсов, позволяющего создавать более надежных и эффективных агентов для взаимодействия с компьютерными системами.
Обеспечение будущего: решение проблем уязвимости и доверия
Анализ навыков Agent Skills выявил существенную уязвимость перед атаками с помощью внедрения запросов (prompt injection), представляющей серьезную угрозу безопасности. Исследование 42 447 навыков показало, что 26,1% из них содержат хотя бы одну уязвимость, позволяющую злоумышленникам манипулировать поведением агента. Данная проблема заключается в возможности формирования таких запросов, которые переопределяют исходные инструкции и заставляют систему выполнять нежелательные действия, что ставит под угрозу надежность и предсказуемость работы Agent Skills и требует разработки эффективных мер защиты.
Протокол контекста модели представляет собой ключевой механизм, обеспечивающий безопасный и контролируемый доступ к внешним данным и инструментам, что значительно расширяет возможности агентов. Этот протокол позволяет агентам эффективно взаимодействовать с окружающей средой, получая необходимую информацию и используя специализированные инструменты для выполнения сложных задач. Внедрение данного протокола не просто повышает функциональность агентов, но и гарантирует, что доступ к внешним ресурсам осуществляется в соответствии с заданными политиками безопасности, предотвращая несанкционированное использование или манипулирование данными. Благодаря этому, агенты способны выполнять более сложные и ответственные задачи, сохраняя при этом высокий уровень надежности и предсказуемости.
К декабрю 2025 года, благодаря целенаправленной работе над устранением уязвимостей и повышением надежности, системы Agent Skills достигли уровня производительности, сопоставимого с человеческим — 72.6% против 72.36% на бенчмарке OSWorld. Этот прорыв стал возможен благодаря активному выявлению и нейтрализации потенциальных угроз, а также приоритезации доверия к системе. Достижение человеческого уровня производительности не только раскрывает полный потенциал Agent Skills, но и открывает путь к созданию действительно интеллектуальных и надежных систем, способных решать сложные задачи с высокой точностью и предсказуемостью.
Исследование, представленное в статье, демонстрирует, что создание эффективных агентов для больших языковых моделей требует не просто разработки архитектуры, но и глубокого понимания принципов приобретения и управления навыками. Этот процесс напоминает реверс-инжиниринг сложной системы, где каждая функция тщательно анализируется и оптимизируется. Блез Паскаль однажды заметил: «Все проблемы человечества происходят от того, что люди не могут спокойно сидеть в комнате». В контексте данной работы это можно интерпретировать как необходимость тщательной проработки базовых принципов функционирования агентов, прежде чем переходить к решению более сложных задач. Акцент на безопасности и прогрессивном раскрытии информации подчеркивает важность контроля и предсказуемости в работе этих систем, что, в свою очередь, способствует их надежности и эффективности.
Куда Ведет Эта Дорога?
Представленный анализ навыков агентов для больших языковых моделей обнажает не столько ответы, сколько тщательно замаскированные вопросы. Архитектура, методы приобретения навыков, протоколы контекста — всё это лишь инструменты для взлома реальности, исходный код которой пока что ускользает от полного понимания. Вместо поиска идеальной системы, необходимо признать её фундаментальную незавершенность и изменчивость. Прогрессивное раскрытие информации, как предложенный механизм, представляется не панацеей, а временным компромиссом в борьбе с неизбежной неопределенностью.
Особое внимание следует уделить не только оптимизации самих навыков, но и разработке мета-навыков — способности агента к самоанализу, адаптации и даже к осознанному отказу от неэффективных стратегий. Безопасность, конечно, важна, однако чрезмерный контроль неизбежно ведет к стагнации. Необходимо найти баланс между защитой от злоупотреблений и предоставлением агентам достаточной свободы для эволюции.
В конечном итоге, задача заключается не в создании «идеального агента», а в разработке инструментов, позволяющих расширить границы человеческого познания. Реальность — это открытый исходный код, и агенты — это наши первые попытки его прочитать и, возможно, изменить. Ирония заключается в том, что чем больше мы узнаем, тем яснее понимаем, насколько мало мы знаем.
Оригинал статьи: https://arxiv.org/pdf/2602.12430.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
- Цифровые улики под присмотром ИИ: новая эра криминалистики?
- Обучение представлений для динамических систем: новый взгляд
- Физика под контролем: Как «научить» модели понимать мир
- Симуляция, которая видит себя: новый подход к физическому моделированию
2026-02-16 17:08