Автор: Денис Аветисян
Новая мультимодальная модель на 10 миллиардах параметров демонстрирует передовые возможности в обработке изображений и текста благодаря эффективному обучению и параллельному анализу.
В статье представлен Step3-VL-10B — мультимодальная большая языковая модель, использующая обучение с подкреплением и масштабирование для достижения передовых результатов в области восприятия и рассуждений.
Современные мультимодальные модели часто требуют огромных вычислительных ресурсов, ограничивая их практическое применение. В настоящей работе, представленной в ‘STEP3-VL-10B Technical Report’, описывается новая модель STEP3-VL-10B, демонстрирующая передовые результаты при компактном размере в 10 миллиардов параметров. Достигнуто это благодаря унифицированной стратегии обучения, масштабированию обучения с подкреплением и параллельному алгоритму рассуждений. Сможет ли STEP3-VL-10B стать эффективной базовой моделью для широкого спектра мультимодальных задач и открыть новые горизонты в области искусственного интеллекта?
Визуальный разум: от текста к пониманию мира
Традиционные языковые модели, несмотря на впечатляющие успехи в обработке текста, испытывают значительные трудности при решении задач, требующих понимания визуальной информации и сложных рассуждений. Они оперируют исключительно с текстовыми данными, не имея встроенных механизмов для анализа изображений, видео или других нетекстовых форматов. Это приводит к тому, что даже простые задачи, требующие сопоставления текста с визуальным контентом, оказываются непосильными. Например, описание содержания изображения или ответы на вопросы, связанные с визуальной сценой, часто вызывают ошибки. Неспособность интегрировать визуальную информацию ограничивает возможности этих моделей в широком спектре приложений, от автоматического создания подписей к изображениям до разработки интеллектуальных систем, способных понимать окружающий мир подобно человеку.
Переход к мультимодальным большим языковым моделям представляется ключевым шагом в преодолении разрыва между восприятием и познанием. Традиционные языковые модели, оперирующие исключительно текстом, испытывают значительные трудности при решении задач, требующих анализа визуальной информации и комплексного рассуждения. Мультимодальные модели, напротив, способны интегрировать и обрабатывать данные из различных источников — текст, изображения, аудио, видео — что позволяет им формировать более полное и глубокое понимание окружающего мира. Это открывает новые возможности в таких областях, как робототехника, медицинская диагностика и автоматизированный анализ данных, где способность к комплексному восприятию и рассуждению является критически важной.
Step3-VL-10B: Архитектура, побеждающая сложность
Архитектура Step3-VL-10B использует 10 миллиардов параметров, что позволяет достичь передовых результатов в задачах рассуждения и восприятия. Несмотря на относительно небольшой размер, модель демонстрирует производительность, сопоставимую с гораздо более крупными моделями, достигающими 235 миллиардов параметров. Данное достижение обусловлено оптимизацией архитектуры и эффективным использованием параметров для максимизации способности модели к обобщению и решению сложных задач, требующих как визуального, так и языкового понимания.
Модель Step3-VL-10B использует специализированный Perception Encoder для обработки визуальных данных. Этот энкодер преобразует изображения в векторные представления, которые затем выравниваются с лингвистическими признаками, извлеченными из текстовых данных. Такое выравнивание позволяет модели эффективно сопоставлять визуальную информацию с соответствующими текстовыми описаниями, обеспечивая более точное понимание и обработку мультимодальных данных. Архитектура Perception Encoder оптимизирована для извлечения релевантных визуальных признаков, что способствует повышению общей производительности модели в задачах, требующих совместного анализа изображений и текста.
В Step3-VL-10B используется единый этап предварительного обучения (Unified Pre-training) с полностью размороженными параметрами. Такой подход, в отличие от многоступенчатого обучения или заморозки части параметров, позволяет модели использовать весь свой потенциал для усвоения знаний из данных. Полностью размороженные параметры обеспечивают возможность адаптации каждой части сети во время обучения, что максимизирует её обучающую способность и способствует более эффективному извлечению признаков и обобщению информации. Это приводит к улучшению производительности модели при решении различных задач, требующих как понимания языка, так и обработки визуальных данных.
Масштабируемое обучение с подкреплением: от теории к практике
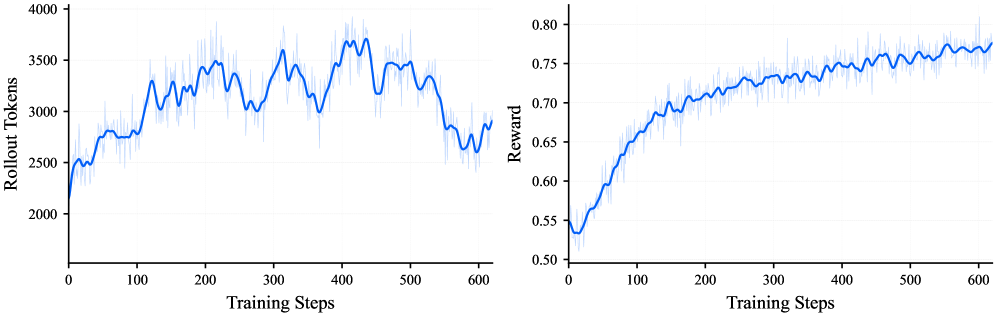
Модель Step3-VL-10B подверглась доработке посредством масштабируемого мультимодального обучения с подкреплением, сочетающего в себе предварительное обучение с учителем и два метода обратной связи: обучение с подкреплением на основе проверяемых вознаграждений (RLVR) и обучение с подкреплением на основе обратной связи от человека (RLHF). RLVR использует автоматически генерируемые сигналы вознаграждения, основанные на проверяемых фактах, для улучшения производительности модели в задачах, требующих обоснованных ответов. RLHF, в свою очередь, использует оценки, предоставленные людьми-оценщиками, для корректировки поведения модели и приведения его в соответствие с человеческими предпочтениями, что повышает субъективное качество генерируемого контента и согласованность с ожиданиями пользователей.
Для ускорения обучения и повышения скорости сходимости модели используются передовые методы оптимизации. AdamW, являясь вариантом алгоритма Adam, включает в себя регуляризацию весов, что способствует предотвращению переобучения. Muon представляет собой оптимизатор второго порядка, использующий приближение матрицы Гессе для более эффективного обновления параметров модели. Deepstack, в свою очередь, оптимизирует процесс обучения за счет динамического масштабирования размера батча, что позволяет адаптироваться к различным этапам обучения и ускорить сходимость. Комбинация этих методов позволяет значительно сократить время обучения и повысить производительность модели.
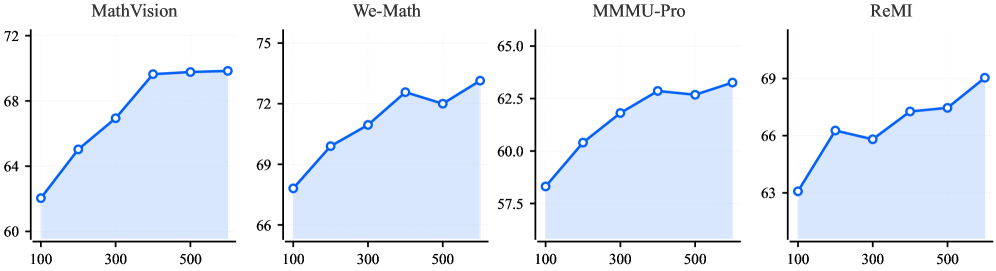
Для повышения способности к рассуждениям используется PaCoRe (Parallel Coordinated Reasoning) — метод, распределяющий вычислительные ресурсы во время тестирования и агрегирующий данные, полученные в результате параллельного визуального анализа. В ходе тестирования на наборе данных All-Angles-Bench, применение PaCoRe позволило увеличить эффективность рассуждений на 7.50% по сравнению со стандартными подходами, что демонстрирует его способность эффективно использовать вычислительные ресурсы для повышения точности и надежности ответов.
Подтвержденное превосходство: бенчмарки и валидация
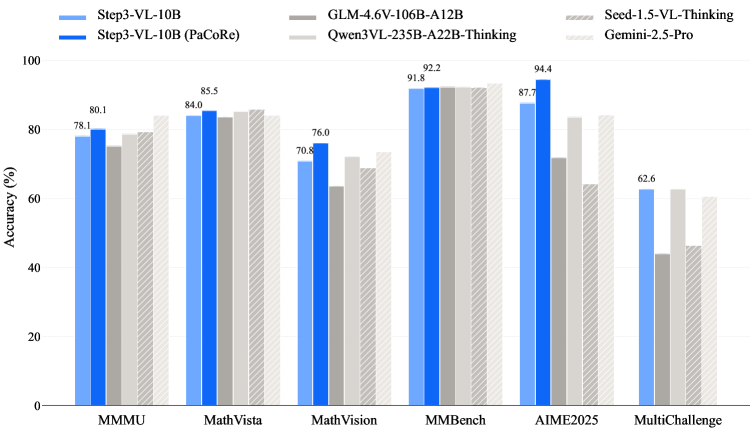
Модель Step3-VL-10B демонстрирует передовые результаты на ключевых бенчмарках, подтверждая ее способность к многомодальному пониманию и рассуждениям. На тестах MathVision достигнута точность 75.95%, а на MMMU — 80.11%. Особенно впечатляют результаты на AIME2025, где точность составляет 94.43%, и на MMBench, где средняя точность достигает 92.17%. Эти показатели свидетельствуют о значительном прогрессе в области мультимодальных моделей и подтверждают эффективность разработанной архитектуры в решении сложных задач, требующих интеграции визуальной и текстовой информации.
Для подтверждения возможностей модели Step3-VL-10B в области следования мультимодальным инструкциям, была проведена валидация на бенчмарке MM-MT-Bench. Результаты демонстрируют высокую эффективность модели в понимании и выполнении задач, требующих обработки и интеграции информации из различных источников, таких как изображения и текст. Способность модели точно интерпретировать сложные инструкции и генерировать соответствующие ответы подтверждает ее продвинутые навыки в мультимодальном анализе и рассуждениях, что делает ее ценным инструментом для широкого спектра приложений, требующих взаимодействия с визуальным и текстовым контентом.
Модель Step3-VL-10B продемонстрировала превосходство над GLM-4.6V, значительно более крупной моделью, содержащей 106 миллиардов параметров, в решении задач MathVision. Для повышения надежности и точности получаемых ответов, Step3-VL-10B использует GPT-OSS-120B в качестве инструмента верификации. Этот подход позволяет не только генерировать решения, но и удостоверяться в их корректности, обеспечивая более высокий уровень доверия к результатам, полученным в области визуального и математического рассуждения. Такое сочетание производительности и надежности делает Step3-VL-10B перспективным решением для широкого спектра задач, требующих комплексного анализа и обработки информации.
Взгляд в будущее: к обобщенному искусственному интеллекту
Архитектура и процесс обучения модели Step3-VL-10B представляют собой многообещающий путь к созданию более обобщенных и устойчивых систем искусственного интеллекта. В отличие от многих существующих моделей, ориентированных на узкие задачи, Step3-VL-10B демонстрирует способность к переносу знаний и адаптации к новым, ранее не встречавшимся ситуациям. Это достигается благодаря инновационному подходу к обучению, включающему в себя предварительное обучение на масштабном и разнообразном наборе данных, а также использование продвинутых методов регуляризации и оптимизации. Данный подход позволяет модели не просто запоминать информацию, а извлекать общие закономерности и принципы, что является ключевым фактором для достижения истинной интеллектуальной гибкости и надежности в различных условиях. Подобная архитектура открывает перспективы для создания ИИ-систем, способных эффективно решать широкий спектр задач, не требуя постоянной перенастройки и обучения для каждой новой ситуации.
Дальнейшие исследования направлены на расширение масштабов применяемых техник, предполагая использование ещё более обширных наборов данных и моделей. Увеличение объёма обучающих данных позволит системе лучше обобщать полученные знания и адаптироваться к новым, ранее не встречавшимся ситуациям. Параллельно, наращивание вычислительных мощностей и совершенствование алгоритмов обучения позволит создавать модели, обладающие большей сложностью и способностью к решению более сложных задач. Ожидается, что подобный подход приведет к значительному повышению надежности и универсальности искусственного интеллекта, приближая его к уровню человеческого мышления и открывая новые горизонты в различных областях науки и техники.
Интеграция модели Step3-VL-10B в практические приложения открывает перспективы для значительных преобразований в различных областях. В робототехнике, система способна обеспечить более гибкое и адаптивное управление, позволяя роботам эффективно взаимодействовать с динамично меняющейся средой и выполнять сложные задачи. В сфере образования, модель может стать основой для персонализированных систем обучения, адаптирующихся к индивидуальным потребностям каждого ученика и предлагающих интерактивные образовательные материалы. В здравоохранении, Step3-VL-10B может использоваться для анализа медицинских изображений, помощи в диагностике заболеваний и разработки индивидуальных планов лечения, что потенциально повысит точность и эффективность медицинской помощи. Реализация этих возможностей потребует дальнейших исследований и адаптации модели к специфическим требованиям каждой области, но потенциал для улучшения качества жизни и оптимизации рабочих процессов представляется весьма значительным.
В отчете о Step3-VL-10B вновь подтверждается старая истина: масштабирование само по себе не решает проблем, а лишь усложняет их. Акцент на эффективном обучении и параллельном рассуждении — это, конечно, хорошо, но всё это уже проходили. Авторы утверждают о достижении передовых результатов, однако, как показывает опыт, каждое «революционное» улучшение неизбежно порождает новые сложности в поддержке и эксплуатации. Как метко заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть полезен людям, а не просто впечатлять». Иначе все эти 10 миллиардов параметров превратятся в дорогостоящий и трудноподдерживаемый монолит, который рано или поздно потребует переработки. Зелёные тесты, как обычно, ничего не гарантируют.
Что дальше?
Модель Step3-VL-10B, безусловно, демонстрирует впечатляющие результаты, но давайте не будем строить воздушные замки. Очевидно, что масштабирование — это лишь один из способов временно отложить неизбежное столкновение с ограничениями железа и здравого смысла. Эффективность обучения — это хорошо, пока кто-нибудь не решит увеличить размер датасета в десять раз, и все начнётся сначала. Параллельное рассуждение, конечно, элегантно, но кто-нибудь уже пишет скрипт, который найдёт способ зациклить эту систему, не так ли?
Более интересным представляется не столько достижение новых рекордов в бенчмарках, сколько понимание того, почему эти модели иногда выдают абсурдные ответы. Обучение с подкреплением, как известно, — это искусство превращения простых задач в невероятно сложные, и Step3-VL-10B, вероятно, лишь усложнит эту проблему. В конечном итоге, все эти инновации — всего лишь временное облегчение симптомов, а не лечение болезни.
Так что, что дальше? Вероятно, нас ждёт новый виток гонки вооружений за вычислительные ресурсы, а затем — внезапное осознание, что мы потратили все деньги на решение задачи, которая никому не нужна. И, конечно же, новая волна статей о том, как «искусственный интеллект скоро заменит нас всех». История повторяется.
Оригинал статьи: https://arxiv.org/pdf/2601.09668.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-18 12:35