Автор: Денис Аветисян
Новое исследование оценивает способность современных систем искусственного интеллекта решать сложные научные задачи, приближенные к уровню экспертов.

Представлен бенчмарк FrontierScience для оценки навыков научного мышления больших языковых моделей, выявляющий значительные ограничения в решении открытых исследовательских вопросов.
Несмотря на впечатляющий прогресс в области искусственного интеллекта, оценка способности моделей к решению экспертных научных задач остается сложной проблемой. В данной работе представлена новая методика — ‘FrontierScience: Evaluating AI‘s Ability to Perform Expert-Level Scientific Tasks’ — предназначенная для всесторонней оценки возможностей больших языковых моделей в области научного мышления. Данный бенчмарк включает в себя задачи олимпиадного уровня по физике, химии и биологии, а также открытые исследовательские задачи, разработанные и проверенные учеными с докторской степенью. Позволит ли FrontierScience выявить истинные границы возможностей ИИ в проведении фундаментальных научных исследований и разработке новых открытий?
Разум и Наука: Преодолевая Границы ИИ
Современные языковые модели, демонстрирующие впечатляющие результаты в различных областях, зачастую сталкиваются с трудностями при решении задач, требующих глубокого научного рассуждения. В отличие от простого распознавания закономерностей или воспроизведения информации, сложный научный анализ предполагает понимание фундаментальных принципов, способность к логическим выводам и умение применять знания в новых контекстах. Модели могут успешно оперировать с терминами и формулами, однако им не хватает способности к самостоятельному построению гипотез, критической оценке данных и проведению последовательного логического анализа, необходимого для решения реальных научных проблем. Это ограничение связано с тем, что обучение таких моделей происходит на огромных массивах текста, где акцент делается на статистические связи между словами, а не на понимание лежащих в основе научных концепций и принципов.
Существующие эталоны оценки, такие как MMLU и ScienceQA, предоставляют начальную точку для измерения возможностей искусственного интеллекта в научной области, однако они часто упрощают реальные научные задачи. Эти тесты, как правило, концентрируются на запоминании фактов и применении известных алгоритмов, не требуя от моделей глубокого понимания причинно-следственных связей, способности к критическому анализу противоречивой информации или творческому решению проблем. В результате, высокие показатели в этих тестах не всегда коррелируют с умением модели эффективно справляться с подлинными научными исследованиями, где важны не только знания, но и способность к адаптации, формулированию гипотез и интерпретации результатов, что создает значительное препятствие на пути к созданию действительно интеллектуальных научных помощников.
Ограниченность возможностей искусственного интеллекта в области сложного научного мышления существенно замедляет создание интеллектуальных помощников, способных поддерживать научные открытия и инновации. Неспособность систем глубоко понимать научные концепции и логически выводить новые знания из существующих данных препятствует автоматизации критически важных задач, таких как анализ больших объемов научных данных, формулировка гипотез и проверка экспериментальных результатов. Это, в свою очередь, ограничивает потенциал искусственного интеллекта в таких областях, как разработка новых лекарств, материаловедение и решение глобальных экологических проблем, где требуется творческий подход и способность к абстрактному мышлению, выходящие за рамки простых алгоритмов и статистического анализа. Развитие более совершенных систем искусственного интеллекта, способных к истинному научному мышлению, станет ключевым фактором ускорения темпов научного прогресса в будущем.
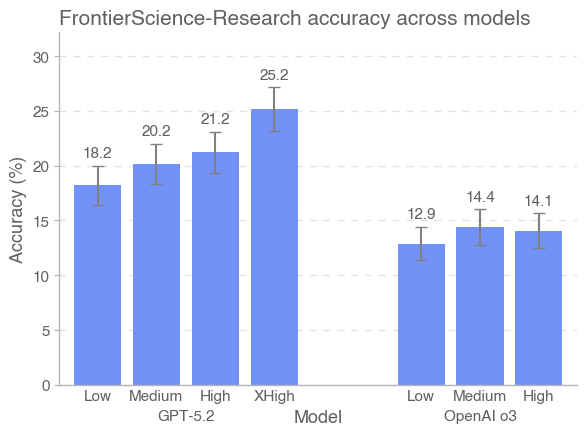
FrontierScience: Новая Граница Научного Мышления
Комплекс FrontierScience предназначен для оценки научного мышления посредством двух различных наборов заданий: «Олимпиада» и «Исследование», каждый из которых ориентирован на оценку различных аспектов решения проблем. Набор «Олимпиада» включает задачи, вдохновленные международными научными олимпиадами, требующие быстрых, кратких ответов и проверки быстроты вспоминания и применения принципов. Набор «Исследование», напротив, предлагает более открытые и сложные задачи, имитирующие реальные научные исследования, и требует развернутого обоснования и логических заключений.
Набор задач «Олимпиада» в FrontierScience основан на принципах, применяемых в международных научных олимпиадах. Он предполагает быстрые, лаконичные ответы, требующие от участников немедленного извлечения знаний из памяти и их применения для решения конкретных задач. Акцент делается на скорости реакции и точности применения фундаментальных принципов, а не на развернутом обосновании или исследовании. Формат задач разработан для оценки способности быстрого анализа и решения проблем, характерных для соревновательных научных дисциплин.
Набор данных Research в FrontierScience включает в себя задачи, моделирующие реальные исследовательские сценарии. В отличие от задач, требующих быстрых ответов, эти задачи характеризуются высокой степенью неопределенности и требуют развернутого обоснования принятых решений. Оценка в данном наборе данных не ограничивается правильностью конечного ответа, но также учитывает логическую последовательность рассуждений, полноту анализа и умение аргументировать выбор методов и интерпретировать полученные результаты. Данный подход позволяет оценить способность модели к проведению научного исследования, включая формулирование гипотез, разработку методологии и интерпретацию данных.
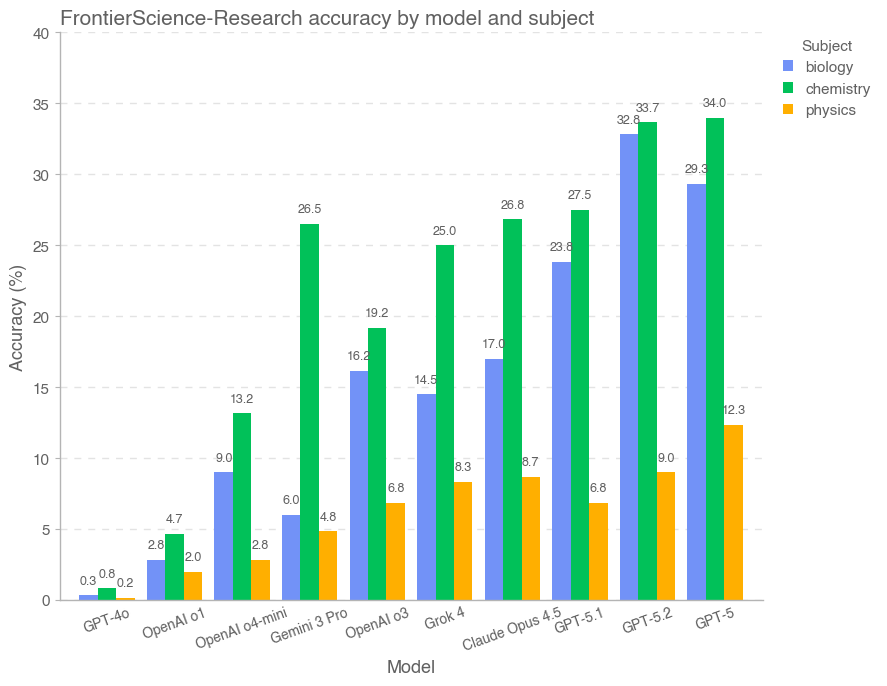
Надёжность Оценки: Рубрики и ИИ-Судья
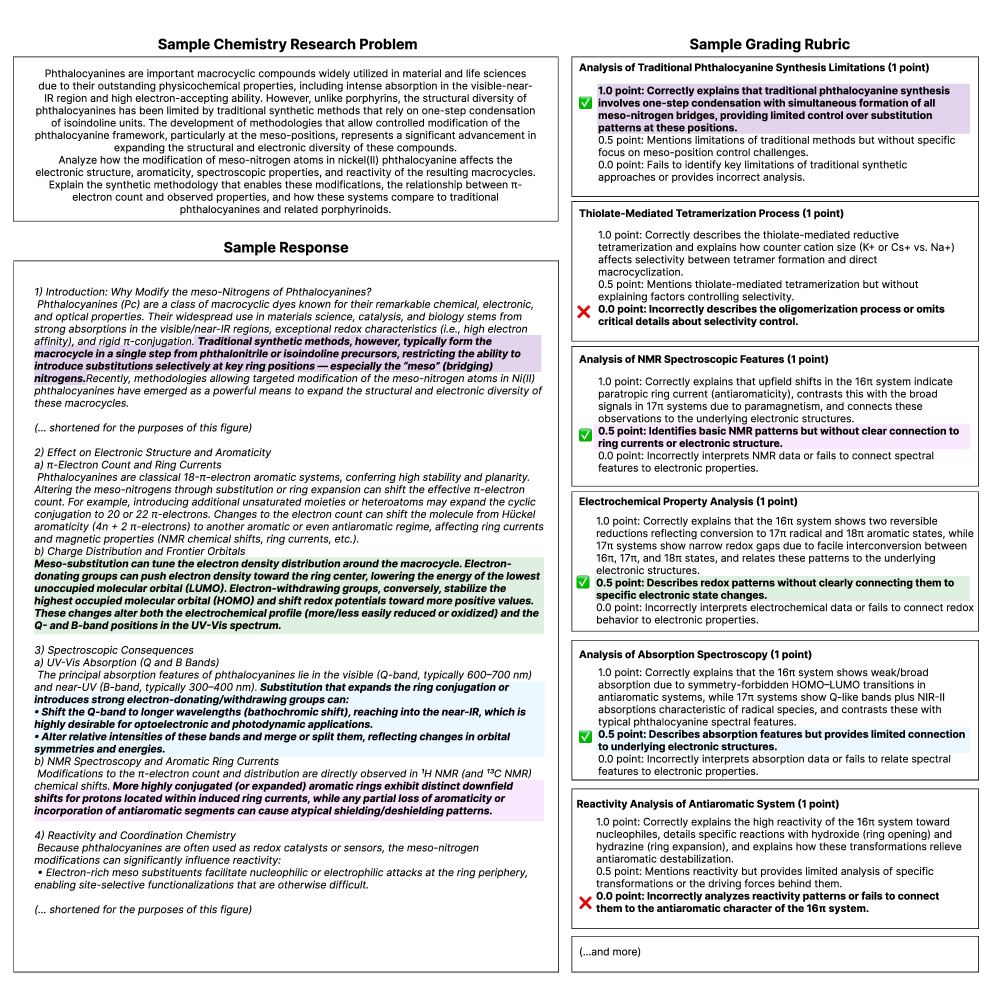
Оценка ответов на наборе данных FrontierScience-Research осуществлялась с использованием рубрик, что позволило стандартизировать и объективизировать процесс определения качества. Применение рубрик подразумевает заранее определенные критерии оценки, позволяющие последовательно и единообразно оценивать каждый ответ, независимо от оценивающего. Такой подход минимизирует субъективные интерпретации и обеспечивает возможность сопоставления результатов, полученных разными моделями, на основе четко определенных параметров качества, что необходимо для надежной сравнительной оценки.
Оценка ответов на наборе данных FrontierScience-Research осуществлялась с использованием детализированных оценочных шкал (рубрик), что позволило стандартизировать процесс и минимизировать субъективность. Эти рубрики содержат четкие критерии для оценки ключевых аспектов ответа, таких как полнота, точность, логическая связность и аргументированность. Использование таких шкал обеспечивает сопоставимость оценок, полученных для различных моделей, и позволяет объективно сравнивать их производительность, исключая влияние индивидуальных предпочтений оценщиков.
Для повышения надёжности оценки ответов в наборе данных FrontierScience-Research был задействован ИИ-агент, названный ‘Model Judge’ (на базе GPT-5). Этот агент использовался в качестве вспомогательного инструмента для оценки, применяя собственные возможности рассуждения и анализа для определения соответствия ответов заданным критериям. Применение ИИ-агента позволило автоматизировать часть процесса оценки и снизить влияние человеческого фактора, обеспечивая более последовательную и объективную оценку качества ответов различных моделей.
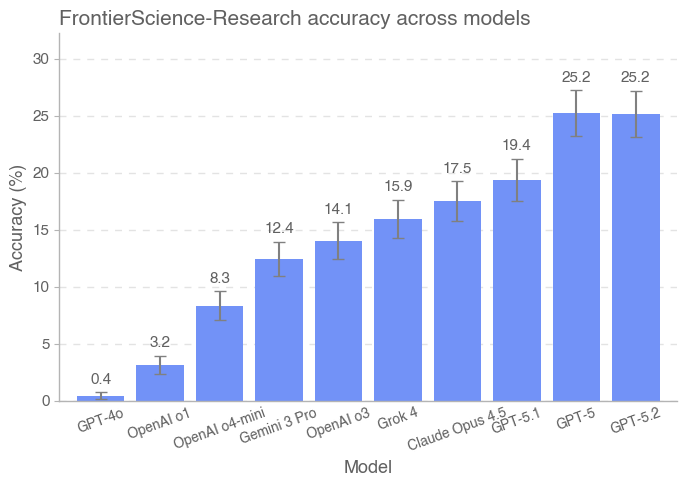
Результаты и Перспективы: На пути к Научному ИИ
Модель GPT-5.2 продемонстрировала передовые результаты на бенчмарке FrontierScience, достигнув 77% точности в решении задач олимпиадного уровня и 25% в более сложных исследовательских задачах. Этот прогресс указывает на значительное улучшение возможностей искусственного интеллекта в области экспертного научного мышления. Успехи в решении олимпиадных задач свидетельствуют о способности модели быстро применять известные научные принципы, в то время как результаты в исследовательском наборе подчеркивают потенциал для анализа сложных данных и формулирования гипотез, хотя и требуют дальнейшей оптимизации для достижения более высоких показателей в этой области.
Модель Gemini 3 Pro продемонстрировала впечатляющую способность к быстрому решению задач, достигнув 76% точности в наборе данных Olympiad, что сопоставимо с результатами лидера, GPT-5.2. Этот показатель свидетельствует о значительном прогрессе в области искусственного интеллекта, способного оперативно анализировать и находить решения в сложных научных проблемах, требующих немедленного применения знаний и логического мышления. Способность модели к быстрому усвоению информации и эффективному решению задач открывает перспективы для использования в ситуациях, где требуется немедленный анализ данных и принятие решений, например, в оперативной диагностике или моделировании сложных систем.
Несмотря на впечатляющие результаты, продемонстрированные современными языковыми моделями в решении олимпиадных задач, значительные усилия все еще требуются для преодоления сложностей, представляемых набором данных Research. Этот набор, имитирующий реальные исследовательские проблемы, требует не только быстрого решения задач, но и способности к глубокому анализу, синтезу информации и генерации новых гипотез — навыков, которые пока остаются вне досягаемости даже для самых передовых систем искусственного интеллекта. Дальнейшее развитие алгоритмов, а также расширение обучающих данных, включающих более сложные и неоднозначные научные задачи, представляются ключевыми шагами на пути к раскрытию полного потенциала ИИ в области научных открытий и инноваций.
Расширяя Границы: Будущее Научных Бенчмарков
Проект FrontierScience не существует изолированно, а органично интегрируется с уже существующими отраслевыми стандартами, такими как ChemBench, PHYBench, CritPt, LAB-Bench и PaperBench. Вместо дублирования усилий, FrontierScience расширяет горизонты научной оценки, дополняя эти существующие бенчмарки и предлагая более комплексный подход к тестированию возможностей искусственного интеллекта в различных областях науки. Такое взаимодействие позволяет создать более полную картину сильных и слабых сторон современных AI-систем, выявляя области, требующие дальнейшего развития, и стимулируя инновации в сфере научных исследований. В результате, научное сообщество получает мощный инструмент для объективной оценки и сравнения различных моделей, что способствует ускорению прогресса и решению сложных научных задач.
Набор задач для олимпиады был сформирован в результате тщательного отбора из более чем 500 первоначальных вопросов. Процесс включал многократную проверку и оценку сложности, актуальности и однозначности каждого задания. В результате этой кропотливой работы был отобран финальный набор, состоящий из 100 задач, отвечающих самым высоким стандартам качества. Особенное внимание уделялось задачам, требующим не только знания фактов, но и умения применять научные принципы для решения нестандартных проблем, что гарантирует выявление наиболее способных участников и стимулирует развитие критического мышления.
В процессе создания набора исследовательских задач, особое внимание уделялось тщательной отборке. Изначально было сформулировано более двухсот вопросов, охватывающих различные области науки. Однако, лишь шестьдесят из них были отобраны для финальной версии набора. Этот процесс включал в себя многократную проверку на корректность, сложность и значимость, а также оценку возможности однозначной интерпретации и решения. В результате, сформированный набор исследовательских задач представляет собой сбалансированную и репрезентативную коллекцию, предназначенную для всесторонней оценки возможностей современных искусственных интеллектов в решении научных проблем.
В дальнейшем планируется значительное расширение спектра научных бенчмарков, с акцентом на создание более сложных и реалистичных задач. Разработчики намерены интегрировать в эти тесты данные, полученные из реальных научных экспериментов и наблюдений, а также моделировать сложные сценарии, приближенные к тем, с которыми сталкиваются ученые в своей повседневной работе. Такой подход позволит оценить не только способность искусственного интеллекта решать теоретические задачи, но и его умение анализировать неполные и зашумленные данные, экстраполировать результаты и делать обоснованные прогнозы, что является ключевым для прогресса в различных областях науки и техники. Целью является создание бенчмарков, которые станут настоящим вызовом для современных ИИ-систем и стимулируют разработку новых алгоритмов и методов решения сложных научных проблем.
Постоянное усовершенствование научных бенчмарков открывает путь к созданию искусственного интеллекта, способного решать наиболее сложные научные задачи и значительно ускорять темпы инноваций. Разработка и внедрение более разнообразных и сложных тестов, включающих реальные данные и моделирующие практические сценарии, позволит AI-системам не просто демонстрировать теоретические знания, но и эффективно применять их для решения проблем в различных областях науки — от химии и физики до биологии и материаловедения. В результате, ожидается появление инструментов, способных автоматизировать научные открытия, оптимизировать исследовательские процессы и, в конечном итоге, привести к прорывам в ключевых областях, определяющих будущее человечества.
Представленный труд демонстрирует стремление к проверке границ возможного для современных языковых моделей в области научного мышления. Авторы, создавая FrontierScience, фактически подвергают существующие алгоритмы стресс-тесту, выявляя слабые места в решении открытых исследовательских задач. Этот подход перекликается с известным высказыванием Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Именно создание нового, более сложного эталона, как FrontierScience, и есть активное формирование будущего искусственного интеллекта, способного к настоящему научному прогрессу. Оценка по рубрикам, предложенная в работе, позволяет детально анализировать процесс рассуждений модели, а не просто оценивать конечный результат — что соответствует духу реверс-инжиниринга и глубокого понимания системы.
Куда же дальше?
Представленный анализ, сфокусированный на границах возможностей больших языковых моделей в решении научных задач, обнажает закономерную истину: имитация понимания — не то же самое, что и само понимание. Задачей FrontierScience было не просто проверить способность отвечать на вопросы, а спровоцировать систему на раскрытие её внутренних механизмов — и она, как и ожидалось, продемонстрировала скорее ловкость в обходе препятствий, чем истинный научный поиск. Это не провал, а, скорее, ожидаемый результат, подтверждающий необходимость переосмысления самого подхода к оценке интеллектуальных способностей.
Следующим шагом видится не просто увеличение объёма обучающих данных или усложнение архитектуры моделей, а создание принципиально новых методик оценки. Требуется выйти за рамки формальных ответов и оценивать способность системы к самостоятельному формулированию гипотез, к критическому анализу информации и, главное, к признанию собственной некомпетентности. Иначе говоря, необходимо научить машину не просто «знать», а «понимать», что она чего-то не знает.
Возможно, настоящая проверка ждёт нас не в создании идеального решателя задач, а в разработке системы, способной к саморефлексии и самосовершенствованию. То есть, системы, которая осознает границы своих возможностей и стремится к их расширению, даже если это означает признание собственной несостоятельности в данный момент. В конечном итоге, наука — это не поиск готовых ответов, а бесконечный процесс поиска вопросов.
Оригинал статьи: https://arxiv.org/pdf/2601.21165.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-30 07:33