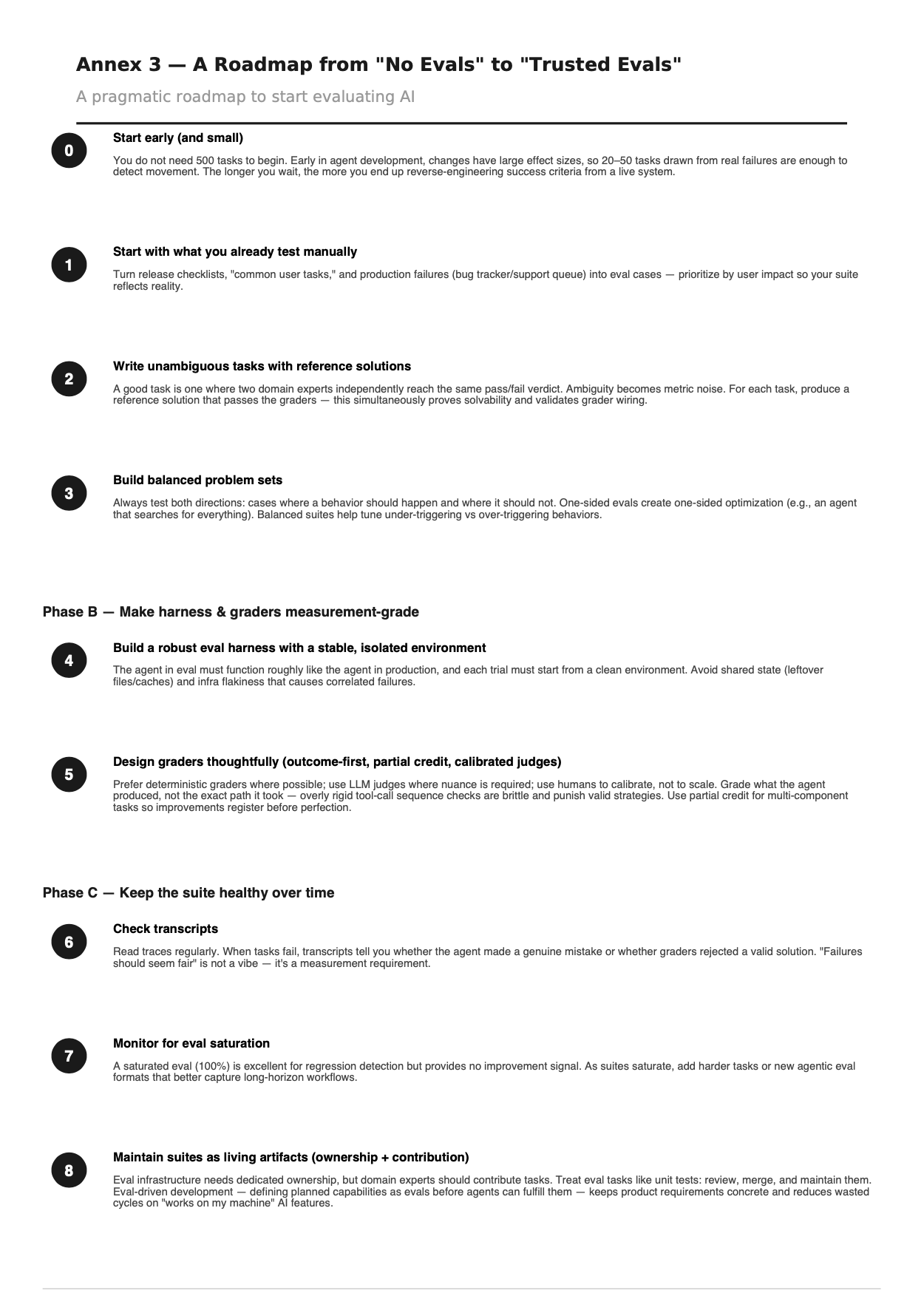
Автор: Денис Аветисян
Статья посвящена эволюции методов оценки искусственного интеллекта и необходимости разработки надежных инструментов для измерения и управления все более сложными автономными системами.

Необходимость создания стандартизированных рамок оценки для обеспечения надежности, безопасности и ответственного внедрения агентивных систем искусственного интеллекта.
Оценка искусственного интеллекта всё чаще выходит за рамки простого измерения производительности отдельных моделей. В работе ‘Towards More Standardized AI Evaluation: From Models to Agents’ утверждается, что по мере развития систем ИИ от статических моделей к автономным агентам, оценка становится ключевой функцией контроля и обеспечения доверия. Основная проблема заключается в том, что существующие подходы, основанные на статичных бенчмарках и агрегированных показателях, зачастую скрывают реальное поведение сложных систем, а не проясняют его. Как обеспечить надёжную и эффективную оценку агентных систем ИИ, учитывая их не детерминированность и способность к адаптации, и какие рамки необходимы для ответственного внедрения таких технологий?
Пределы Традиционной Оценки
Современные методы оценки искусственного интеллекта в значительной степени опираются на статические бенчмарки, что приводит к насыщению результатов и формированию ложного ощущения безопасности. Эти заранее заданные наборы данных и метрик, хотя и полезные на заре развития ИИ, все чаще не отражают сложность и непредсказуемость реальных сценариев. По мере того как модели достигают высоких показателей на этих ограниченных тестах, они становятся менее информативными для оценки истинной надежности и обобщающей способности. По сути, постоянное улучшение результатов на одних и тех же бенчмарках может маскировать фундаментальные недостатки и уязвимости, которые проявятся при столкновении с новыми, непредсказуемыми ситуациями. Такая тенденция создает иллюзию прогресса, затрудняя выявление и устранение реальных проблем в разработке и развертывании интеллектуальных систем.
Исторически сложившиеся эталоны оценки искусственного интеллекта, несмотря на свою прежнюю полезность, оказываются недостаточными при анализе работы агентных систем в сложных, приближенных к реальности сценариях. Традиционные тесты зачастую концентрируются на узком спектре задач и не способны выявить тонкости поведения, проявляющиеся в динамичных и непредсказуемых условиях. Агентные системы, в отличие от простых алгоритмов, способны к адаптации и самообучению, что требует оценки не только итогового результата, но и процесса принятия решений, способности к обобщению и устойчивости к неожиданным ситуациям. Поэтому, полагаясь исключительно на статичные показатели, исследователи рискуют упустить из виду критические недостатки, которые могут проявиться при реальном развертывании подобных систем.
Существующие методы оценки искусственного интеллекта часто сосредотачиваются на усредненных показателях, упуская из виду важный сигнал — непоследовательность в работе системы. Вместо анализа колебаний и отклонений в поведении, оценка ограничивается общим результатом, что может скрыть критические уязвимости и потенциальные сбои. Непостоянство, проявляющееся в разных сеансах или при незначительном изменении входных данных, является индикатором нестабильности и указывает на необходимость более глубокого анализа. Игнорирование этой вариативности создает иллюзию надежности, поскольку система может демонстрировать высокие средние показатели, одновременно обладая непредсказуемыми и потенциально опасными особенностями в конкретных ситуациях. В результате, полагаться исключительно на агрегированные метрики — значит недооценивать риски и упускать возможность выявить скрытые дефекты, способные привести к нежелательным последствиям.
Существует значительный разрыв между результатами, демонстрируемыми искусственным интеллектом на стандартных тестах, и его фактической надежностью в реальных условиях. Этот феномен напрямую связан с законом Гудхарта, который гласит: когда мера становится целью, она перестает быть хорошей мерой. Иными словами, оптимизация системы исключительно для достижения высоких показателей на конкретных бенчмарках может привести к игнорированию важных аспектов надежности и устойчивости к непредсказуемым ситуациям. В результате, система может прекрасно справляться с тестами, но демонстрировать неожиданные сбои и непредсказуемое поведение в реальном мире, где условия значительно сложнее и разнообразнее. Это подчеркивает необходимость разработки новых методов оценки, учитывающих не только средние показатели, но и вариативность поведения системы, а также её способность адаптироваться к меняющимся обстоятельствам.
Создание Динамических Средов Оценки
Для преодоления ограничений статических эталонных тестов необходимы среды, включающие не детерминированные настройки. Недетерминизм, проявляющийся в случайных событиях или вариативности состояний окружения, вынуждает агентов адаптироваться к новым ситуациям вместо простого запоминания решений. Такие среды требуют от агентов способности к обобщению знаний и применению их в условиях, отличающихся от тех, на которых они обучались. Это повышает устойчивость и надежность агентов, позволяя им эффективно функционировать в реальных, непредсказуемых сценариях. Использование не детерминированных сред является ключевым шагом к созданию действительно интеллектуальных систем.
Среды, такие как GAIA2 и TextQuests, представляют собой сложные сценарии, разработанные для проверки способности агентов к адаптации и обобщению знаний, а не просто к запоминанию ответов. В отличие от статических эталонных тестов, эти среды вводят непредсказуемые элементы и требуют от агента активного решения проблем и логического вывода. GAIA2 моделирует многоагентное взаимодействие в виртуальном мире, где агенты должны сотрудничать или конкурировать для достижения целей. TextQuests, в свою очередь, представляет собой текстовые приключенческие игры, требующие от агента понимания естественного языка, планирования действий и извлечения информации из текстовых описаний. Обе среды акцентируют внимание на оценке способности агента к рассуждениям и применению знаний в новых, ранее не встречавшихся ситуациях.
Основой динамических оценочных сред является Harness — инфраструктура, обеспечивающая соединение агента с его окружением и позволяющая проводить контролируемые эксперименты. Harness включает в себя компоненты для инициализации среды, передачи входных данных агенту, получения его действий и обновления состояния среды. Ключевым аспектом является стандартизация интерфейсов и протоколов взаимодействия, что позволяет легко подключать различные агенты и инструменты, а также воспроизводить эксперименты с высокой точностью. Правильная реализация Harness критически важна для обеспечения надежности и валидности результатов оценки, позволяя исследователям изолировать влияние различных факторов и точно измерять производительность агентов в сложных сценариях.
Протокол контекста модели (Model Context Protocol) является ключевым компонентом для обеспечения бесшовного взаимодействия агента с внешними инструментами в рамках создаваемой среды. Он определяет стандартизированный формат обмена данными между агентом и инструментами, включающий в себя запрос, контекст и ответ. Этот протокол позволяет агенту не только отправлять запросы к инструментам, но и получать от них необходимую информацию, а также передавать релевантный контекст для повышения точности и эффективности работы. Стандартизация обмена данными упрощает интеграцию новых инструментов и обеспечивает совместимость между различными компонентами системы, что необходимо для проведения контролируемых экспериментов и оценки возможностей агентов в динамических средах.
Выходя за Рамки Проверки Выходных Данных: Измерение Надежности
Традиционная проверка выходных данных (Output Checking) недостаточна для оценки агентивных систем, поскольку она фокусируется исключительно на конечном результате, игнорируя процесс достижения этой цели. Агентивные системы, в отличие от детерминированных программ, демонстрируют стохастическое поведение и способны к различным путям решения задачи. Поэтому для надежной оценки требуется измерение не только корректности ответа, но и консистентности и надежности поведения агента во времени. Это включает в себя оценку стабильности ответов при повторных запусках с одинаковыми входными данными, а также способность агента поддерживать работоспособность при незначительных изменениях в среде или входных данных. Простая проверка на соответствие ожидаемому результату не позволяет выявить потенциальные регрессии или непредсказуемое поведение, которое может возникнуть в реальных условиях эксплуатации.
Измерение поведения, ориентированное на предсказуемость работы системы с течением времени, является ключевым для выявления потенциальных регрессий. Необходимо отслеживать стабильность ответов агента на одни и те же входные данные, фиксируя любые отклонения от ожидаемого поведения. Регулярный мониторинг производительности, включающий автоматизированные тесты и анализ логов, позволяет своевременно обнаружить ухудшение качества работы, вызванное обновлениями модели, изменениями в данных или другими факторами. Особенно важно отслеживать производительность на краевых случаях и сложных задачах, где регрессии могут быть наиболее заметны. Систематический подход к измерению поведения обеспечивает возможность оперативного реагирования на любые отклонения и поддержание надежности агента в долгосрочной перспективе.
Метрики, такие как Pass@k и Passk, позволяют оценивать успешность агентов, учитывая их стохастическую природу. Pass@k, определяемая как (c/n)^k, где ‘c’ — количество успешных попыток, ‘n’ — общее количество попыток, а ‘k’ — количество допустимых попыток, представляет собой вероятность успешного выполнения задачи хотя бы в одной из ‘k’ попыток. Passk, в свою очередь, является упрощенной версией, оценивающей вероятность успешного выполнения задачи в одной конкретной попытке. Использование этих метрик особенно важно при оценке агентов, поведение которых зависит от случайных факторов, поскольку они предоставляют более реалистичную и вероятностную оценку их надежности и производительности, чем детерминированные метрики.
Использование подхода “Модель как судья” (Model-as-a-Judge) позволяет дополнить традиционные методы оценки агентов, предоставляя более детальную и нюансированную обратную связь о их поведении. Вместо простого бинарного определения “успех/неудача”, модель-судья анализирует промежуточные шаги и логику действий агента, выявляя сильные и слабые стороны. Особенно полезно это в случаях, когда существует множество допустимых решений, и традиционные метрики не позволяют адекватно оценить качество выбранного пути. Такой подход может быть реализован с использованием больших языковых моделей, обученных на предоставлении экспертных оценок, что позволяет автоматизировать процесс анализа и повысить объективность оценки поведения агента.

Будущее Управления и Оценки ИИ
Ужесточение нормативных требований к системам искусственного интеллекта (ИИ) обуславливает необходимость введения четких и подтверждаемых практик оценки их работы. Регуляторные органы по всему миру все активнее требуют от разработчиков ИИ демонстрировать безопасность, надежность и соответствие этическим нормам создаваемых систем. Это приводит к тому, что недостаточно просто заявить о высоком качестве алгоритмов; необходимо предоставить убедительные доказательства, полученные в ходе строгих и систематических оценок. Подобные оценки должны охватывать различные аспекты работы ИИ, включая точность, устойчивость к ошибкам, предвзятость и потенциальное воздействие на общество. В результате, организации вынуждены инвестировать в создание надежных систем оценки, способных не только выявлять недостатки, но и подтверждать соответствие установленным стандартам, что становится ключевым фактором для успешного внедрения и использования технологий ИИ.
Комплексный жизненный цикл оценки системы является основой для создания и поддержания надежных наборов инструментов для тестирования искусственного интеллекта. Этот цикл предполагает не просто однократную проверку, а непрерывный процесс, включающий в себя определение ключевых показателей эффективности на различных этапах разработки, систематическое проведение тестов и анализ полученных результатов. Важно, чтобы оценка охватывала не только функциональные возможности, но и аспекты безопасности, этичности и устойчивости системы к различным воздействиям. Регулярное обновление оценочных наборов, адаптация к новым угрозам и совершенствование методик тестирования — необходимые условия для поддержания высокого уровня надежности и доверия к системам искусственного интеллекта на протяжении всего их жизненного цикла. Такой подход позволяет своевременно выявлять потенциальные недостатки и обеспечивать соответствие системы установленным требованиям и стандартам.
Оценка рисков, связанных с искусственным интеллектом, представляется первостепенной задачей в контексте его стремительного развития. Для заблаговременного выявления потенциальных угроз и приближения к критическим порогам возможностей, все большее значение приобретают динамические среды оценки, основанные на эмпирических тестах. Эти среды позволяют не просто констатировать текущие характеристики системы, но и прогнозировать ее поведение в различных сценариях, выявляя неожиданные или нежелательные эффекты. Регулярное проведение таких тестов, адаптированных к меняющимся условиям и новым данным, дает возможность вовремя принять меры для смягчения рисков и обеспечения безопасного функционирования интеллектуальных систем. Таким образом, динамическая оценка на основе эмпирических данных становится ключевым инструментом для проактивного управления рисками и поддержания контроля над развитием искусственного интеллекта.
Строгая и систематическая оценка возможностей искусственного интеллекта является краеугольным камнем ответственного управления этой технологией. Непрерывный мониторинг и анализ производительности систем ИИ, а также выявление потенциальных рисков, позволяют формировать четкие правила и стандарты, необходимые для обеспечения безопасности и этичности применения. Такой подход к оценке не просто подтверждает соответствие установленным требованиям, но и создает динамичную основу для адаптации нормативных актов к быстро меняющемуся ландшафту искусственного интеллекта, гарантируя, что инновации развиваются в рамках общественной безопасности и доверия. В конечном итоге, именно этот цикл оценки и адаптации является залогом устойчивого и ответственного развития технологий ИИ.
Исследование подчеркивает растущую важность оценки в контексте развития агентивных систем. Подход к оценке смещается от вспомогательной роли к определяющей, требуя строгих рамок для измерения и управления сложностью. Автор отмечает, что закрытие разрыва в оценке критически важно для ответственного внедрения ИИ. В этой связи, слова Джона фон Неймана представляются особенно актуальными: «В науке не бывает абсолютно безопасных предположений, только более или менее обоснованные». Эта фраза отражает необходимость постоянной проверки и валидации, особенно при работе с системами, способными к автономным действиям. Оценка, как и научное исследование, требует критического подхода и признания неизбежности неопределенности, что напрямую связано с необходимостью разработки надежных и масштабируемых фреймворков, обсуждаемых в статье.
Куда Ведет Эта Дорога?
Становится все яснее: оценка искусственного интеллекта перестает быть просто вспомогательной функцией, превращаясь в определяющий фактор развития. Вместе с усложнением систем, переходящих от моделей к агентам, растет и потребность в строгих рамках оценки, способных не только измерять, но и ограничивать их поведение. Неудивительно, что “разрыв в оценке” становится критической точкой, определяющей, насколько ответственно будет развернут этот мощный инструмент. Однако, стремление к стандартизации само по себе не решит проблему. Каждая новая зависимость от метрик — это скрытая цена свободы, иллюзия контроля, возникающая из упрощенного представления о сложной системе.
Предстоит осознать, что оценка — это не поиск “правильного” ответа, а создание обратной связи, способной выявить непредсказуемые последствия. Необходимо перейти от оценки отдельных функций к пониманию системы как единого организма, где структура определяет поведение. Особое внимание следует уделить не только надежности и предсказуемости, но и способности системы адаптироваться к изменяющимся условиям, сохраняя при этом целостность и устойчивость.
Будущие исследования должны быть направлены на разработку принципиально новых методов оценки, учитывающих нелинейность и эмерджентные свойства сложных систем. Попытки формализовать “разумность” или “этику” неизбежно столкнутся с ограничениями, но даже приблизительное понимание этих аспектов позволит снизить риски и направить развитие искусственного интеллекта в более безопасное и полезное русло. В конечном итоге, истинная оценка системы — это оценка её влияния на целостную картину мира.
Оригинал статьи: https://arxiv.org/pdf/2602.18029.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 20:50