Автор: Денис Аветисян
Обзор посвящен стремительно развивающейся области применения генеративных моделей искусственного интеллекта для создания и оптимизации ферментов, открывающих новые горизонты в промышленном биокатализе.
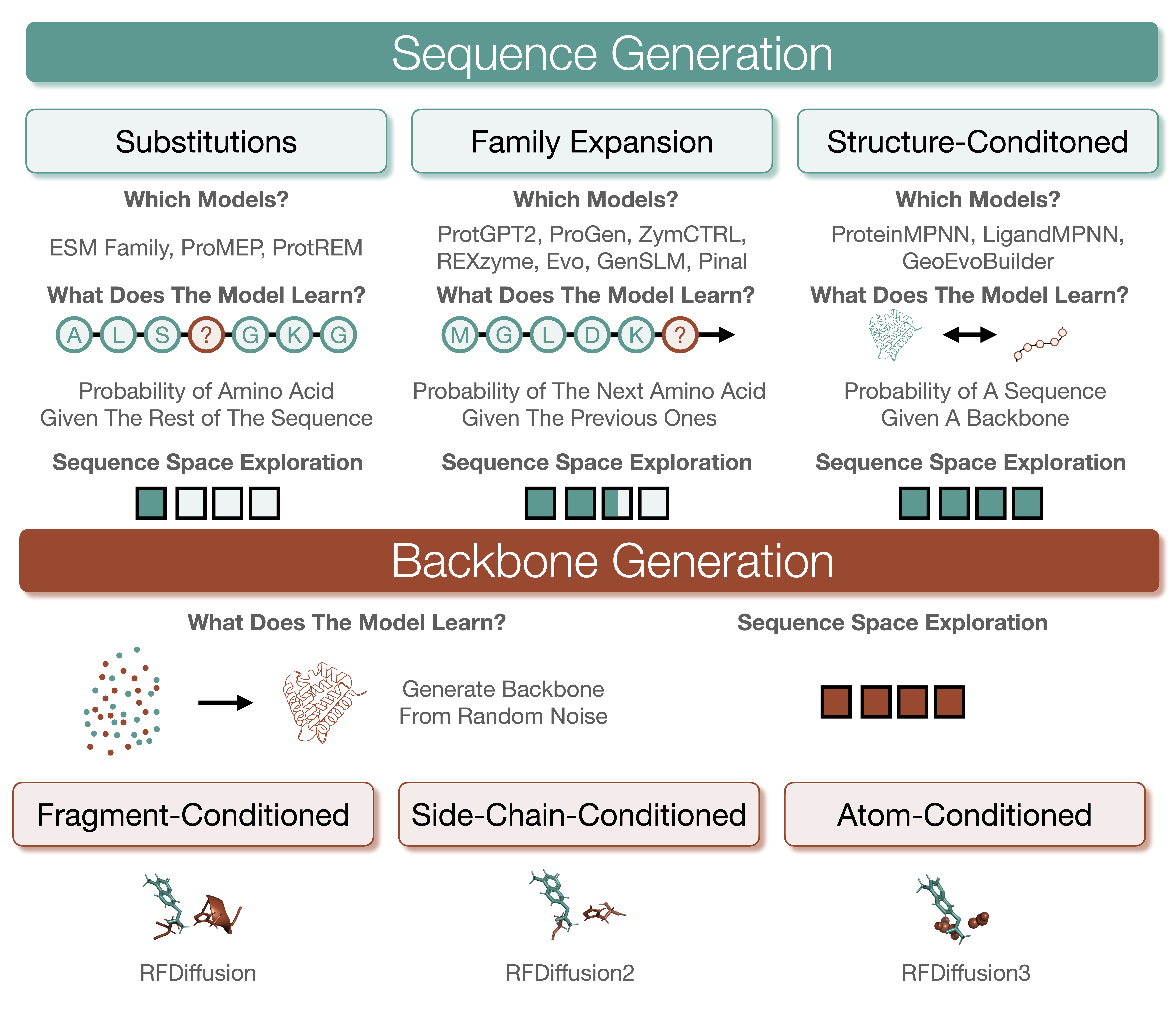
В статье рассматриваются возможности и ограничения генеративных моделей, включая модели последовательностей и спинов, для разработки инновационных и улучшенных ферментов.
Несмотря на десятилетия усилий в области направленного эволюционного дизайна, создание ферментов с заданными свойствами оставалось сложной задачей. В настоящем обзоре, озаглавленном ‘Generative AI for Enzyme Design and Biocatalysis’, рассматривается стремительное развитие генеративных моделей искусственного интеллекта — включая генераторы последовательностей и структур — для конструирования новых и усовершенствованных ферментов, пригодных для промышленного применения. Показано, что современные модели демонстрируют зрелость, позволяющую оптимизировать ферменты для биокатализа, однако требуют экспериментальной верификации и обратной связи. Какие новые подходы к интеграции генеративного ИИ и экспериментальных данных позволят ускорить разработку биокатализаторов нового поколения?
За гранью модификации: Поиск новых путей в дизайне ферментов
Традиционные методы ферментной инженерии, основанные на модификации уже существующих белков, часто сталкиваются с ограничениями, обусловленными эволюционной историей этих молекул. Эволюция не оптимизирует белки для всех возможных задач, а скорее для выживания и репродукции в конкретной среде. Поэтому, стремясь улучшить каталитические свойства существующих ферментов, исследователи неизбежно достигают определенных пределов, так как дальнейшие изменения могут нарушить стабильность белка или его способность связываться с субстратом. Эти эволюционные «узкие места» ограничивают потенциал существующих ферментов в новых биотехнологических приложениях, где требуются свойства, отличные от тех, что встречаются в природе. Таким образом, существующие ферменты могут быть неспособны эффективно катализировать реакции в нетипичных условиях или с нестандартными субстратами, что подчеркивает необходимость новых подходов к созданию катализаторов.
Разработка ферментов de novo открывает принципиально новые возможности в области биокатализа, позволяя создавать катализаторы с заданными свойствами, которые превосходят ограничения, присущие модификации существующих белков. В отличие от традиционных методов, где улучшения ограничены эволюционным контекстом, de novo дизайн позволяет проектировать ферменты, оптимизированные для конкретных задач — от производства фармацевтических препаратов до разработки экологически чистых промышленных процессов. Такой подход дает возможность преодолеть естественные барьеры, создавая ферменты с повышенной активностью, селективностью и стабильностью, а также адаптированные к экстремальным условиям, недоступным для природных аналогов. В результате, перспективные области применения включают синтез новых материалов, утилизацию отходов и разработку инновационных биотехнологий.
Создание ферментов de novo сталкивается с колоссальной проблемой — необходимостью поиска в практически бесконечном пространстве возможных аминокислотных последовательностей. Каждый фермент — это уникальная трехмерная структура, определяющая его каталитическую активность, и предсказание этой структуры по последовательности представляет собой сложную вычислительную задачу. Несмотря на значительный прогресс в области вычислительной биологии и методов машинного обучения, точное моделирование конформации белка и предсказание его функции остаются серьезными препятствиями. Успешное преодоление этих сложностей требует разработки новых алгоритмов и подходов, способных эффективно исследовать пространство белковых структур и выявлять последовательности, кодирующие ферменты с заданными свойствами, что открывает перспективы для создания биокатализаторов с беспрецедентной эффективностью и специфичностью.

Генеративный искусственный интеллект: Новый подход к созданию белков
Генеративные модели искусственного интеллекта совершают революцию в области проектирования белков, обучаясь фундаментальным принципам, определяющим их структуру и функции, на основе анализа огромных массивов данных. Успешность кампаний по созданию новых белков с заданными свойствами удваивается каждые два года, что свидетельствует о стремительном прогрессе в данной области. Этот рост обусловлен способностью моделей выявлять сложные взаимосвязи между аминокислотной последовательностью и трехмерной структурой белка, позволяя создавать последовательности, соответствующие требуемым функциональным характеристикам и стабильности. Обучение на больших данных позволяет моделям преодолевать ограничения традиционных методов проектирования белков, которые часто требуют значительных временных и вычислительных затрат.
Модели, генерирующие последовательности, использующие архитектуры, такие как Transformer, способны создавать новые аминокислотные последовательности с заданными характеристиками. В основе работы этих моделей лежит способность предсказывать вероятности различных аминокислот на каждой позиции в последовательности, что позволяет формировать белки с целевыми свойствами, например, определенной стабильностью или связывающей способностью. Архитектура Transformer, благодаря механизму внимания, эффективно обрабатывает длинные последовательности аминокислот и выявляет сложные зависимости между ними, что критически важно для генерации функциональных белков. Использование таких моделей позволяет существенно расширить возможности направленного дизайна белков, преодолевая ограничения традиционных методов.
Включение физико-химических априорных знаний (physicochemical priors) в модели генеративного ИИ существенно повышает эффективность процесса проектирования белков. Эти априорные знания представляют собой фундаментальные ограничения, обусловленные физическими и химическими свойствами аминокислот и их взаимодействиями. Они включают в себя такие факторы, как гидрофобность, заряд, размер и способность к образованию водородных связей. Интеграция этих ограничений в алгоритм генерации позволяет модели создавать последовательности аминокислот, которые более вероятно будут стабильными, правильно свернутыми и функциональными, тем самым снижая количество нереалистичных или неработоспособных предложений и направляя процесс дизайна к более вероятным кандидатам на белки.
Авторегрессионные модели последовательностей предсказывают следующий аминокислотный остаток в цепи, основываясь на предыдущих остатках. Этот процесс позволяет генерировать совершенно новые последовательности белков, не встречающиеся в природе. В основе работы лежит вероятностное моделирование, где вероятность каждого последующего аминокислотного остатка определяется условной вероятностью, зависящей от всей предыдущей последовательности. По сути, модель изучает закономерности в существующих белковых последовательностях и использует эти знания для создания новых, потенциально функциональных белков, расширяя возможности направленного дизайна белков.
Структурно-обусловленный дизайн: Управление последовательностями с помощью геометрии
Структурно-обусловленные модели, такие как ProteinMPNN и LigandMPNN, расширяют возможности генерации аминокислотных последовательностей, интегрируя информацию о трехмерной структуре белка. В отличие от традиционных методов, которые генерируют последовательности независимо от структуры, эти модели фокусируются на проектировании белков, ориентированном на активный центр. Это достигается за счет использования графов, представляющих структуру белка, где узлы соответствуют аминокислотным остаткам, а ребра — пространственным взаимодействиям. В процессе генерации модели оценивают правдоподобие аминокислотных остатков в каждой позиции активного центра, учитывая как последовательность, так и структурный контекст, что позволяет создавать белки с заданными свойствами и повышенной аффинностью к целевым молекулам.
Модели, генерирующие основу белка, такие как RFDiffusion, создают начальные трехмерные структуры, предоставляя каркас для последующей оптимизации аминокислотной последовательности. В отличие от подходов, ориентированных исключительно на последовательность, эти модели сначала формируют пространственную конфигурацию белка, определяя взаимное расположение атомов. Этот пространственный каркас затем используется для поиска оптимальной аминокислотной последовательности, совместимой с заданной структурой и соответствующей заданным функциональным требованиям. Использование предварительно сформированной структуры значительно сокращает пространство поиска возможных последовательностей и позволяет более эффективно конструировать белки с желаемыми свойствами, такими как стабильность и каталитическая активность.
Сочетание информации о последовательности и структуре позволяет новым моделям проектировать белки с повышенной стабильностью и функциональностью. Это достигается за счет оптимизации аминокислотной последовательности с учетом трехмерной структуры, что приводит к улучшению сворачивания белка и повышению его устойчивости к денатурации. Такой подход открывает возможности для целенаправленного биокатализа, позволяя создавать ферменты с заданными свойствами, такими как повышенная активность, селективность или устойчивость к экстремальным условиям, что важно для промышленных процессов и биотехнологий.
Множественные выравнивания последовательностей (Multiple Sequence Alignments, MSA) используются для усовершенствования сгенерированных белковых последовательностей путем интеграции эволюционной информации. Анализ консервативности аминокислотных остатков в MSA позволяет выявить критически важные позиции для сохранения структуры и функции белка. Последовательности, полученные моделями генерации, оцениваются на соответствие паттернам, наблюдаемым в MSA, и подвергаются мутациям, направленным на повышение сходства с эволюционно родственными белками. Этот процесс способствует улучшению стабильности, активности и специфичности проектируемых белков, поскольку эволюция отбирает наиболее функциональные и стабильные варианты.
Валидация сгенерированных ферментов: Бенчмаркинг и совершенствование
Семейство моделей ESM (Evolutionary Scale Modeling) в настоящее время представляет собой передовые последовательностные модели, широко применяемые в области инженерии ферментов. Эти модели, основанные на глубоком обучении, способны предсказывать вероятности аминокислотных остатков в белках, используя информацию об эволюционных связях и больших базах данных белковых последовательностей. Они позволяют оценивать стабильность и функциональные характеристики новых белковых вариантов, что делает их незаменимым инструментом для рационального дизайна ферментов и оптимизации их свойств. В отличие от более ранних методов, ESM-модели демонстрируют повышенную точность в предсказании структуры и функции белков, что способствует более эффективному процессу создания новых ферментов с заданными характеристиками.
ProteinGym представляет собой ключевой инструмент для оценки соответствия между вероятностями аминокислот, предсказанных моделями искусственного интеллекта, и результатами экспериментальных исследований. Эта платформа позволяет количественно оценивать корреляцию между in silico предсказаниями и фактической биохимической активностью разработанных ферментов. В рамках валидации, ProteinGym использует стандартизированные наборы данных и протоколы для измерения каталитической эффективности и других ключевых параметров, обеспечивая объективную оценку производительности моделей, таких как ESM Family. Полученные результаты позволяют выявлять сильные и слабые стороны алгоритмов, направляя дальнейшее развитие методов дизайна ферментов и обеспечивая надежность предсказаний.
Процесс валидации позволяет подтвердить, что искусственно сгенерированные ферменты обладают предсказанными свойствами и пригодны для практического применения. Некоторые разработанные конструкции демонстрируют каталитические эффективности, достигающие 2.2 \times 10^5 \text{ M}^{-1} \text{ s}^{-1}, что сопоставимо со средними показателями для природных серингидролаз. Это подтверждает, что модели искусственного интеллекта способны генерировать ферменты, не уступающие по эффективности своим природным аналогам, что открывает перспективы для их использования в различных биотехнологических приложениях.
Полурациональный дизайн, объединяющий предсказания искусственного интеллекта с направленной эволюцией, позволяет существенно улучшить характеристики и расширить область применения разработанных ферментов. В частности, применительно к протеазе TEV, данный подход продемонстрировал 26-кратное увеличение активности по сравнению с природным типом, а также повышение температуры плавления на 40°C. Это свидетельствует о возможности целенаправленной оптимизации ферментов не только в отношении каталитической эффективности, но и термостабильности, что критически важно для промышленных применений и увеличения срока службы биокатализаторов.
Будущее ферментной инженерии: К созданию специализированных биокатализаторов
Сочетание генеративного искусственного интеллекта и направленной эволюции белков открывает новую эру в биокатализе, позволяя создавать ферменты с заданными свойствами для широкого спектра промышленных применений. Этот симбиоз технологий позволяет не просто модифицировать существующие ферменты, но и конструировать принципиально новые, оптимизированные для конкретных задач — от разработки инновационных лекарственных препаратов до создания экологически чистых химических процессов и производства новых материалов. Использование алгоритмов машинного обучения для предсказания структуры и функции белков в сочетании с высокопроизводительным скринингом и направленной эволюцией значительно ускоряет процесс разработки, позволяя получать биокатализаторы с повышенной активностью, стабильностью и селективностью, что ранее казалось недостижимым.
Сочетание генеративного искусственного интеллекта и инженерии белков открывает новые возможности для решения ключевых задач в различных областях науки и промышленности. Данная технология способна значительно ускорить процессы разработки лекарственных препаратов, обеспечивая создание более эффективных и специфичных катализаторов для синтеза сложных молекул. В области устойчивой химии, оптимизированные ферменты позволяют разрабатывать экологически безопасные методы производства химических веществ, снижая потребность в традиционных, часто токсичных, катализаторах. Результаты исследований демонстрируют существенное повышение активности ферментов: для tP4H, стабилизированные варианты показали 80-кратное увеличение активности, а активность дикого типа tP4H возросла в 6 раз. Эти достижения также актуальны для материаловедения, где ферменты могут использоваться для создания новых материалов с уникальными свойствами, открывая перспективы для разработки инновационных продуктов и технологий.
Современные усовершенствования алгоритмов искусственного интеллекта и методов валидации значительно ускоряют процесс разработки ферментов, открывая новые возможности для создания ферментов de novo. Недавние исследования продемонстрировали впечатляющий 7,7-кратный прирост активности кетостероид-изомеразы, разработанной с использованием этих технологий. При этом, созданные ферменты сохраняют минимальное сходство в 35% с другими известными ферментами, что подтверждает возможность получения принципиально новых катализаторов. Такой подход позволяет не только улучшать существующие ферменты, но и создавать совершенно новые биокатализаторы с заданными свойствами, расширяя их применение в различных областях, от фармацевтики до устойчивой химии.
Стабилизация переходного состояния продолжает оставаться фундаментальным принципом в разработке высокоэффективных катализаторов. Исследования показывают, что целенаправленное конструирование ферментов для имитации переходного состояния реакции позволяет значительно снизить энергию активации и, следовательно, увеличить скорость катализа. Этот подход, основанный на детальном понимании механизма реакции и структурных особенностях фермента, позволяет создавать биокатализаторы с улучшенной активностью и селективностью. Ученые применяют вычислительные методы и анализ структурных данных для идентификации аминокислотных остатков, которые могут взаимодействовать с переходным состоянием, и вносят соответствующие изменения в структуру фермента, добиваясь существенного повышения его каталитической эффективности. Такой подход открывает новые возможности для создания ферментов с заданными свойствами, востребованных в различных областях, включая фармацевтику, химическую промышленность и биотехнологии.
Исследование возможностей генеративного искусственного интеллекта в проектировании ферментов демонстрирует, что структура действительно определяет поведение. Как отмечает Фрэнсис Бэкон: «Знание — сила». Представленная работа, исследуя применение моделей генерации последовательностей и каркасов, подчеркивает стремление к оптимизации не только активности, но и стабильности ферментов для промышленного применения. Успех в этой области требует целостного подхода, понимания взаимосвязей между аминокислотной последовательностью, трехмерной структурой и каталитической активностью, а не изолированного улучшения отдельных параметров. Генеративные модели, позволяя создавать ферменты с заданными свойствами, открывают новые горизонты для биокатализа, но требуют тщательного анализа и валидации для обеспечения надежности и эффективности.
Куда Ведут Эти Пути?
Подобно искуссному алхимику, современная энзимология всё активнее обращается к генеративным моделям искусственного интеллекта. Однако, следует помнить: элегантность структуры не гарантирует функциональную совершенность. Создание новых ферментов — задача не только последовательностная, но и конформационная, и упрощение одной проблемы часто оборачивается усложнением другой. Недостаточно генерировать последовательности; необходимо предсказывать и контролировать трёхмерную архитектуру, стабильность и, что самое главное, каталитическую активность в реальных промышленных условиях.
Очевидным направлением является интеграция генеративных моделей с экспериментальными данными, создание замкнутых циклов “дизайн — синтез — тестирование”. Но истинный прогресс потребует не только увеличения объёма данных, но и разработки более глубокого понимания взаимосвязи между структурой, динамикой и функцией ферментов. Игнорирование этого, стремление к автоматизации ради автоматизации, может привести к созданию множества “почти подходящих” ферментов, а не к действительно революционным решениям.
В конечном счёте, успех этой области будет зависеть не только от мощи алгоритмов, но и от способности учёных видеть лес за деревьями, понимать ограничения моделей и признавать, что даже самый сложный искусственный интеллект — лишь инструмент, а не замена для критического мышления и глубоких знаний в области биохимии и энзимологии.
Оригинал статьи: https://arxiv.org/pdf/2602.03779.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Ожившие Миры: Новая Эра Видеогенерации
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Генерация изображений: Новый взгляд на скорость и детализацию
- Эволюция Симуляций: От Агентов к Сложным Социальным Системам
2026-02-04 08:50