Автор: Денис Аветисян
Новые подходы искусственного интеллекта открывают беспрецедентные возможности для понимания и модификации T- и B-клеточных рецепторов, приближая эру персонализированной иммунотерапии.

Обзор последних достижений в области применения моделей машинного обучения и генеративного ИИ для моделирования, проектирования и улучшения терапевтических свойств иммунных рецепторов.
Несмотря на возрастающую сложность адаптивного иммунитета, моделирование Т- и В-клеточных рецепторов остается сложной задачей. В работе ‘AI Developments for T and B Cell Receptor Modeling and Therapeutic Design’ рассматриваются последние достижения в применении искусственного интеллекта, в частности, моделей языков белков и генеративных алгоритмов, для моделирования и конструирования иммунных рецепторов. Показано, что интеграция мультимодальных данных и анализ крупномасштабных наборов данных позволяют оптимизировать кандидаты для терапевтического дизайна и лучше понять разнообразие иммунных реакций. Какие перспективы открываются для создания более эффективных и персонализированных иммунотерапевтических стратегий на основе этих разработок?
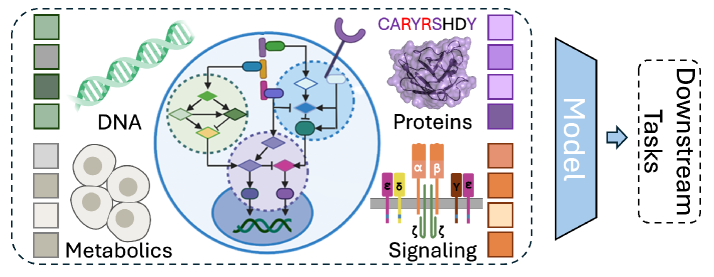
Расшифровка Иммунного Разнообразия: Узкое Место в Дизайне Рецепторов
Разработка новых иммунных рецепторов сталкивается с непреодолимым препятствием — колоссальным разнообразием иммунного репертуара. Представьте себе пространство, содержащее миллиарды потенциальных рецепторов, каждый из которых способен взаимодействовать с антигеном. Полный перебор и тестирование всех этих вариантов практически невозможен, даже с использованием самых современных вычислительных мощностей и высокопроизводительного скрининга. Это связано с тем, что количество возможных комбинаций генов, формирующих рецепторы, экспоненциально велико. В результате, поиск рецептора с желаемой специфичностью и аффинностью к конкретному антигену превращается в задачу, требующую не только значительных ресурсов, но и инновационных подходов, позволяющих обойти необходимость в исчерпывающем поиске и сосредоточиться на наиболее перспективных кандидатах. Необходимость преодоления этого “узкого места” является ключевой проблемой в разработке эффективных иммунотерапевтических стратегий.
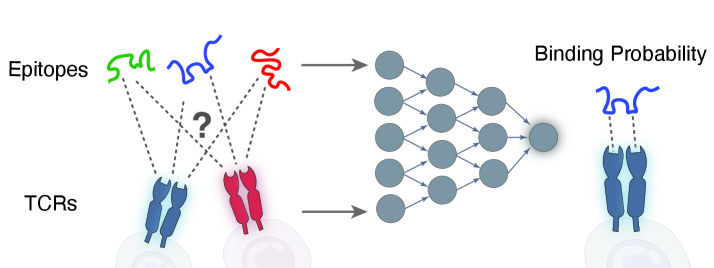
Традиционные методы предсказания взаимодействия рецепторов и антигенов часто оказываются недостаточно точными, что существенно ограничивает эффективность иммунотерапевтических подходов. Существующие алгоритмы, основанные на анализе структуры и аминокислотных последовательностей, не способны учесть всю сложность конформационных изменений и динамических процессов, происходящих при связывании. Это приводит к тому, что разработанные рецепторы могут демонстрировать низкую аффинность к целевому антигену или, наоборот, неспецифическое связывание с другими молекулами, что вызывает нежелательные побочные эффекты. Учитывая, что успешная иммунотерапия требует высокоспецифичного и прочного взаимодействия между рецептором и антигеном, повышение точности предсказания этих взаимодействий является критически важной задачей для разработки новых, более эффективных методов лечения.
Понимание принципов, определяющих специфичность антигена и перекрестную реактивность, является ключевым фактором в рациональном дизайне иммунных рецепторов. Исследования показывают, что способность рецептора распознавать не только конкретный антиген, но и схожие молекулы, играет важную роль в обеспечении широкого иммунного ответа. Специфичность достигается за счет тонкой настройки аминокислотной последовательности в связывающем участке рецептора, в то время как перекрестная реактивность возникает благодаря структурному сходству между различными антигенами. Изучение этих механизмов позволяет ученым разрабатывать рецепторы, способные эффективно нейтрализовать широкий спектр патогенов и, в перспективе, создавать более эффективные иммунотерапевтические стратегии, направленные на борьбу с инфекционными заболеваниями и онкологическими новообразованиями. Оптимизация баланса между специфичностью и перекрестной реактивностью представляется сложной, но решающей задачей для создания принципиально новых иммунных препаратов.
Генеративное Моделирование для Инноваций в Дизайне Рецепторов
Генеративные модели представляют собой мощный инструментарий для de novo дизайна рецепторов, позволяющий создавать последовательности с заданными характеристиками. В отличие от традиционных методов, основанных на оптимизации существующих структур, генеративные модели способны создавать совершенно новые последовательности, удовлетворяющие определенным критериям, таким как аффинность к конкретному антигену или улучшенная стабильность. Этот подход основан на обучении модели на больших наборах данных существующих рецепторов, что позволяет ей изучить основные принципы дизайна и генерировать последовательности, обладающие высокой вероятностью функциональности. Возможность задавать желаемые свойства рецепторов в процессе генерации открывает перспективы для создания терапевтических средств и диагностических инструментов с улучшенными характеристиками.
Диффузионные модели и модели на основе потоков представляют собой передовые подходы к генерации разнообразных и реалистичных последовательностей рецепторов. Диффузионные модели, работая путем постепенного добавления шума к данным, а затем обучая модель для его удаления, позволяют генерировать новые последовательности, сохраняя при этом их биологическую правдоподобность. Модели на основе потоков используют обратимые преобразования для отображения данных в простое распределение, что облегчает генерацию новых образцов. Оба подхода демонстрируют превосходство в создании последовательностей, отличающихся от тех, что представлены в обучающих данных, и способны генерировать структуры, потенциально обладающие новыми функциональными свойствами.
Для обучения генеративных моделей используются существующие базы данных последовательностей рецепторов, такие как Observed TCR Space и Observed Antibody Space. Эти ресурсы содержат более 558 миллионов последовательностей тяжелых и легких цепей, что позволяет моделям извлекать базовые принципы дизайна рецепторов. Использование данных такого масштаба необходимо для обучения моделей, способных генерировать разнообразные и реалистичные последовательности, имитирующие естественные иммунные рецепторы и обладающие заданными свойствами.
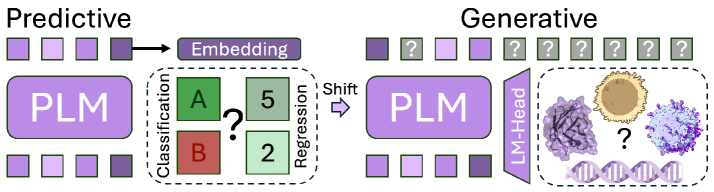
Протеиновые Языковые Модели: Раскрытие Биологии Рецепторов
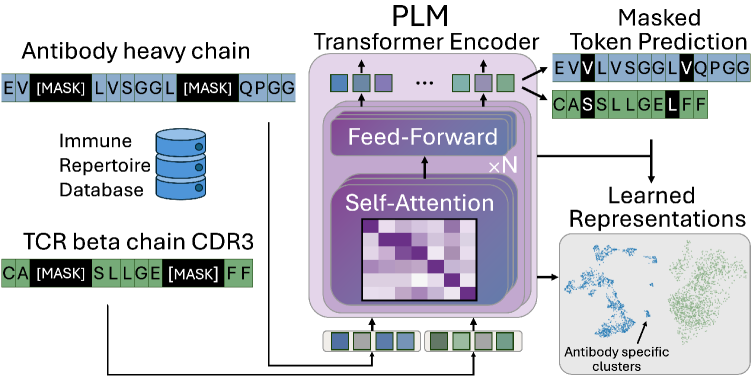
Протеиновые языковые модели (PLM) используют обширные массивы данных о последовательностях аминокислот для выявления закономерностей, определяющих биологию белков. В отличие от традиционных методов, основанных на ручном определении характеристик или ограниченных наборах данных, PLM обучаются на миллионах последовательностей, что позволяет им автоматически выявлять сложные взаимосвязи и паттерны, предсказывающие структуру, функцию и взаимодействие белков. Этот подход обеспечивает значительное повышение точности и эффективности в задачах, связанных с анализом и проектированием белков, особенно в областях, где доступ к экспериментальным данным ограничен.
Архитектура Transformer является ключевым компонентом успешной работы моделей языков белков (PLM), поскольку она позволяет учитывать долгосрочные зависимости в последовательностях рецепторов. В отличие от рекуррентных нейронных сетей, Transformer использует механизм внимания (attention), позволяющий модели одновременно анализировать все элементы последовательности и устанавливать связи между удаленными аминокислотами. Это особенно важно для рецепторов, где функционально значимые участки могут быть разделены значительным количеством аминокислот в первичной структуре. Само-внимание (self-attention) позволяет модели взвешивать вклад каждого аминокислотного остатка в контексте всей последовательности, выявляя сложные паттерны, определяющие структуру и функцию рецептора, и значительно превосходя традиционные методы, не способные эффективно обрабатывать длинные последовательности.
Включение структурной информации, предсказанной AlphaFold, значительно повышает точность предсказаний взаимодействия рецептор-антиген в моделях языков белков (PLM). AlphaFold предоставляет трехмерные модели структуры белка, которые позволяют PLM учитывать не только аминокислотную последовательность, но и пространственное расположение аминокислот, что критически важно для определения сайтов связывания и аффинности. Использование структурных данных позволяет PLM более эффективно различать истинные взаимодействия от ложных, что приводит к повышению специфичности и чувствительности в задачах идентификации связывающих белков и разработке новых терапевтических средств. В частности, интеграция структурных признаков улучшает способность PLM предсказывать влияние мутаций на взаимодействие рецептора и антигена.
Применение методов переноса обучения (Transfer Learning) и аугментации данных значительно повышает эффективность моделей языкового моделирования белков (PLM). Перенос обучения позволяет использовать знания, полученные при обучении на больших наборах данных последовательностей белков, для решения задач, связанных с предсказанием взаимодействия рецепторов и антигенов. Аугментация данных, включающая создание искусственно измененных последовательностей, увеличивает объем обучающей выборки и повышает устойчивость модели к вариациям. В результате, наблюдается улучшение точности идентификации связывающих белков и существенное сокращение числа кандидатов, требующих экспериментальной проверки в лаборатории, что снижает затраты и ускоряет процесс разработки лекарственных препаратов.
Валидация Предсказаний: Соединение Теории с Биологической Реальностью
Молекулярные динамические симуляции (МДС) представляют собой важный инструмент для проверки предсказаний, полученных с помощью моделей предсказания лигандов (PLM), путем моделирования физических взаимодействий между рецепторами и антигенами. МДС позволяют рассчитать энергию связывания, стабильность комплекса и конформационные изменения, происходящие при взаимодействии. Симуляции используют классическую механику для расчета сил, действующих на атомы в системе, и позволяют отслеживать движение атомов во времени. Анализ траекторий МДС позволяет определить ключевые аминокислотные остатки, участвующие в связывании, и оценить влияние мутаций на аффинность. Полученные данные могут быть использованы для подтверждения или опровержения предсказаний PLM и для уточнения моделей предсказания.
Последовательное секвенирование TCR (T-клеточных рецепторов) и BCR (B-клеточных рецепторов) позволяет детально охарактеризовать репертуары этих рецепторов в организме. Эти методы выявляют разнообразие последовательностей генов, кодирующих рецепторы, и позволяют оценить специфичность рецепторов к различным антигенам. Анализ секвенированных данных включает в себя определение частоты встречаемости различных клонов рецепторов, выявление преобладающих мотивов последовательностей и определение степени перекрестной реактивности рецепторов с различными антигенами. Полученные данные используются для оценки иммунного ответа, мониторинга прогрессирования заболеваний и разработки новых вакцин и терапевтических стратегий.
Одноклеточная РНК-секвенирование (scRNA-seq) предоставляет информацию о контексте экспрессии рецепторов на уровне отдельных клеток, что позволяет получить более полное представление об их функциональности. Анализ транскриптома каждой клетки позволяет определить, в каких клеточных популяциях экспрессируются конкретные рецепторы, а также выявить корреляции между экспрессией рецепторов и другими генами, участвующими в иммунном ответе. Это особенно важно, поскольку функция рецепторов может варьироваться в зависимости от клеточного типа и микроокружения, и scRNA-seq позволяет учесть эти факторы при интерпретации данных. Более того, анализ экспрессии рецепторов в сочетании с анализом других генов позволяет идентифицировать сигнальные пути и регуляторные механизмы, контролирующие функцию рецепторов.
Интеграция методов одноклеточного секвенирования РНК (scRNA-seq) и секвенирования доступности хроматина (scATAC-seq) в моделях анализа значительно улучшает кластеризацию и аннотацию клеток. scRNA-seq предоставляет информацию об экспрессии генов в каждой клетке, а scATAC-seq — о доступности хроматина, отражающей регуляторные элементы и активность генов. Комбинирование этих данных позволяет более точно идентифицировать субпопуляции клеток и определить регуляторные механизмы, влияющие на функцию рецепторов, что приводит к более полному пониманию клеточного ответа и повышает достоверность предсказаний.
Будущее Инженерии Рецепторов: Персонализированная Иммунотерапия
Сочетание генеративных моделей, языковых моделей для белков и строгих методов валидации открывает возможности для создания рецепторов с беспрецедентной специфичностью и эффективностью. Этот подход позволяет предсказывать структуру и функцию белковых рецепторов, оптимизируя их взаимодействие с целевыми молекулами. Используя алгоритмы машинного обучения, исследователи могут «обучать» модели на огромных массивах данных о белках, что позволяет создавать новые рецепторы с заданными характеристиками. Тщательная экспериментальная проверка, включающая анализ связывания и функциональные исследования, обеспечивает надежность и безопасность разработанных рецепторов. Такой комплексный подход обещает революцию в разработке терапевтических средств, направленных на точное воздействие на отдельные клетки или молекулы, открывая путь к более эффективным и персонализированным методам лечения.
Персонализированная иммунотерапия, основанная на точном конструировании рецепторов, открывает принципиально новые возможности в лечении различных заболеваний. Вместо универсальных подходов, учитывающих лишь общие характеристики болезни, предлагается создание терапевтических средств, адаптированных к индивидуальному генетическому профилю и иммунному ответу каждого пациента. Это достигается путем анализа уникальных антигенов, представленных опухолевыми клетками или патогенами, и последующего конструирования рецепторов, способных с высокой специфичностью распознавать и нейтрализовать именно эти антигены. Такой подход позволяет минимизировать побочные эффекты и максимизировать эффективность лечения, поскольку иммунная система направляется точно на пораженные клетки, избегая атаки на здоровые ткани. Ожидается, что персонализированная иммунотерапия станет ключевым направлением в борьбе с онкологическими заболеваниями, инфекционными болезнями и аутоиммунными расстройствами, предлагая надежду на более эффективное и безопасное лечение.
Возможность предсказывать и конструировать поведение рецепторов открывает принципиально новые горизонты в терапии инфекционных заболеваний, онкологических патологий и аутоиммунных расстройств. Традиционные подходы зачастую сталкиваются с ограничениями в специфичности и эффективности, однако точное моделирование взаимодействия рецепторов с целевыми молекулами позволяет создавать препараты, нацеленные непосредственно на пораженные клетки или патогены. Персонализированный подход, основанный на индивидуальных особенностях организма пациента, позволяет минимизировать побочные эффекты и максимизировать терапевтический эффект. Ожидается, что такое целенаправленное воздействие на клеточном уровне значительно повысит эффективность лечения и улучшит качество жизни пациентов, страдающих от этих сложных заболеваний.
Современные подходы, основанные на искусственном интеллекте, демонстрируют значительный прорыв в скорости и эффективности поиска новых рецепторов, в частности, антител. Исследования показывают, что применение алгоритмов машинного обучения позволило достичь двузначных показателей успешности — более 10% — при скрининге библиотек антител. Это существенный прогресс по сравнению с традиционными методами, где успешные результаты достигались лишь в единичных случаях. Такой прирост эффективности обусловлен способностью ИИ предсказывать структуру и функциональность белков, оптимизируя процесс отбора наиболее перспективных кандидатов для дальнейшей разработки терапевтических средств, что открывает новые возможности для лечения широкого спектра заболеваний.
Исследование, представленное в статье, демонстрирует элегантность подхода к моделированию иммунных рецепторов, используя возможности искусственного интеллекта. Вместо хаотичного перебора вариантов, предлагается гармоничное сочетание вычислительных методов и данных о структуре белков. Как однажды заметил Стивен Хокинг: «Интеллект — это способность адаптироваться к изменениям». Эта фраза особенно актуальна в контексте стремительного развития алгоритмов генеративного ИИ, позволяющих создавать новые белковые конструкции с заданными свойствами. Успешное применение этих моделей для инженерии TCR и BCR не просто оптимизирует процесс разработки терапевтических средств, но и углубляет понимание фундаментальных механизмов адаптивного иммунитета, подтверждая, что красота и эффективность неразрывно связаны в научном прогрессе.
Что Дальше?
Представленный обзор, бесспорно, демонстрирует стремительное внедрение искусственного интеллекта в моделирование иммунных рецепторов. Однако, кажущаяся простота генерации новых последовательностей TCR и BCR не должна вводить в заблуждение. Элегантность решения — не в количестве сгенерированных вариантов, а в их осмысленной валидации. Пока что, значительная часть усилий направлена на предсказание структуры и аффинности, в то время как понимание динамики взаимодействия рецептора с антигеном, его конформационных изменений и влияния микроокружения остаётся областью для глубоких исследований.
Наиболее сложной задачей видится интеграция мультимодальных данных — геномных, протеомных, клинических. Простое объединение наборов данных не равно пониманию. Необходимо разрабатывать алгоритмы, способные выявлять скрытые корреляции и причинно-следственные связи, а не просто статистические закономерности. Иначе, рискуем создать инструменты, которые красиво оперируют данными, но не приближают нас к истинному пониманию иммунной системы.
В конечном счете, успех этой области будет зависеть не от мощности вычислительных ресурсов или сложности алгоритмов, а от способности к рефакторингу — к редактированию, а не перестройке существующих моделей. Поиск не новых, революционных подходов, а утончённых, изящных решений, основанных на глубоком понимании фундаментальных принципов иммунологии, представляется наиболее перспективным путём.
Оригинал статьи: https://arxiv.org/pdf/2601.17138.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-27 13:53