Автор: Денис Аветисян
Новое исследование демонстрирует, как большие языковые модели могут ускорить научные исследования, автоматизируя создание контента, но при этом смещая фокус труда на оркестровку, проверку и обеспечение качества.
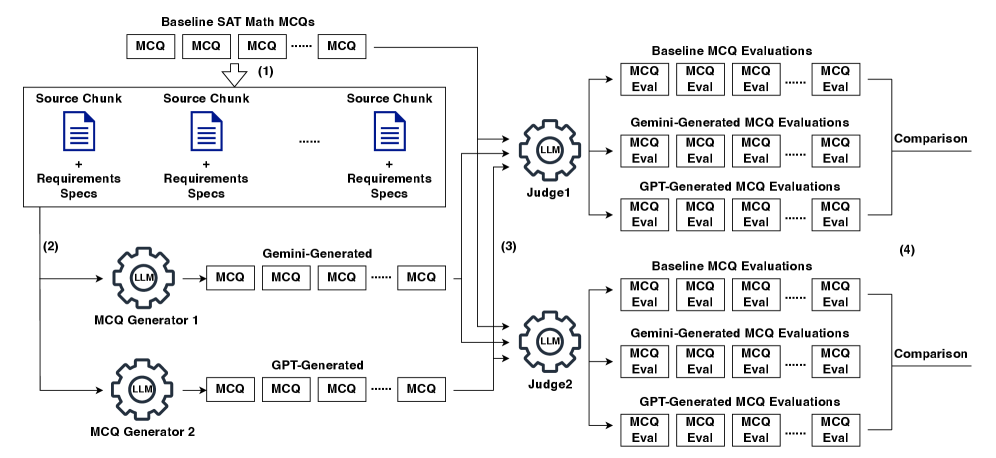
Пилотное исследование возможностей автоматической генерации и оценки вопросов с множественным выбором с использованием многоагентных систем на базе больших языковых моделей.
Несмотря на стремительное развитие больших языковых моделей (LLM), эмпирическая оценка их влияния на реальные научные исследования остается ограниченной. В работе ‘Orchestrating LLM Agents for Scientific Research: A Pilot Study of Multiple Choice Question (MCQ) Generation and Evaluation’ представлено пилотное исследование, в котором исследователь координировал работу нескольких LLM-агентов для автоматизации задач извлечения данных, построения корпусов, генерации и оценки вопросов с множественным выбором ответов. Результаты показали, что автоматизация контента возможна, однако смещает акцент в работе исследователя от создания материалов к их оркестрации, верификации и контролю качества. Какие новые навыки потребуются ученым для эффективного использования LLM в будущих научных рабочих процессах и как это изменит саму природу научной деятельности?
Вызов Автоматизированной Оценки: Искусство Формулировки Вопросов
Разработка качественных вопросов с выбором ответа традиционно требует значительных временных затрат и глубоких знаний в соответствующей предметной области. Процесс не ограничивается простым формулированием вопроса и вариантов ответов; он включает в себя тщательный анализ концепций, выявление наиболее важных аспектов для проверки понимания, создание правдоподобных, но неверных вариантов ответа — дистракторов — и проверку вопросов на предмет двусмысленности или неточностей. Эксперты в предметной области должны не только обладать глубокими знаниями, но и уметь мыслить как студент, предвидеть возможные ошибки и заблуждения, а также оценивать сложность вопроса и его соответствие учебным целям. Этот трудоемкий процесс объясняет, почему создание обширных баз данных качественных вопросов с выбором ответа является сложной и дорогостоящей задачей, особенно в условиях растущей потребности в персонализированном обучении и автоматизированной оценке знаний.
Существующие автоматизированные системы оценки зачастую демонстрируют ограниченные возможности в генерации вопросов, требующих от обучающегося не просто воспроизведения фактов, но и применения навыков анализа, синтеза и критического мышления. Они склонны к созданию заданий, фокусирующихся на запоминании информации, в то время как оценка более сложных когнитивных процессов, таких как решение проблем или творческое применение знаний, требует более тонкого подхода к формулировке вопросов и вариантов ответов. Автоматические алгоритмы, как правило, испытывают трудности в понимании контекста и нюансов, необходимых для создания заданий, которые действительно проверяют способность к глубокому осмыслению материала и переносу знаний в новые ситуации. Это связано с тем, что существующие модели часто оперируют поверхностными признаками текста, не учитывая скрытые смыслы и логические связи, что приводит к генерации формально корректных, но неэффективных с точки зрения оценки высших когнитивных функций, вопросов.
В связи с растущим спросом на персонализированное обучение, возникает острая необходимость в масштабируемых решениях для создания разнообразных и релевантных оценочных материалов. Традиционные методы, требующие значительных временных затрат и экспертных знаний для разработки качественных тестов, становятся непрактичными в условиях массового обучения. Автоматизированные системы, способные генерировать адаптивные задания, учитывающие индивидуальный уровень подготовки и потребности каждого учащегося, представляют собой перспективное направление. Такие системы позволяют оперативно создавать обширные банки заданий, охватывающие различные темы и уровни сложности, обеспечивая тем самым возможность проведения более эффективной и адресной оценки знаний и навыков. Разработка подобных инструментов позволит значительно снизить нагрузку на преподавателей и повысить качество образовательного процесса.
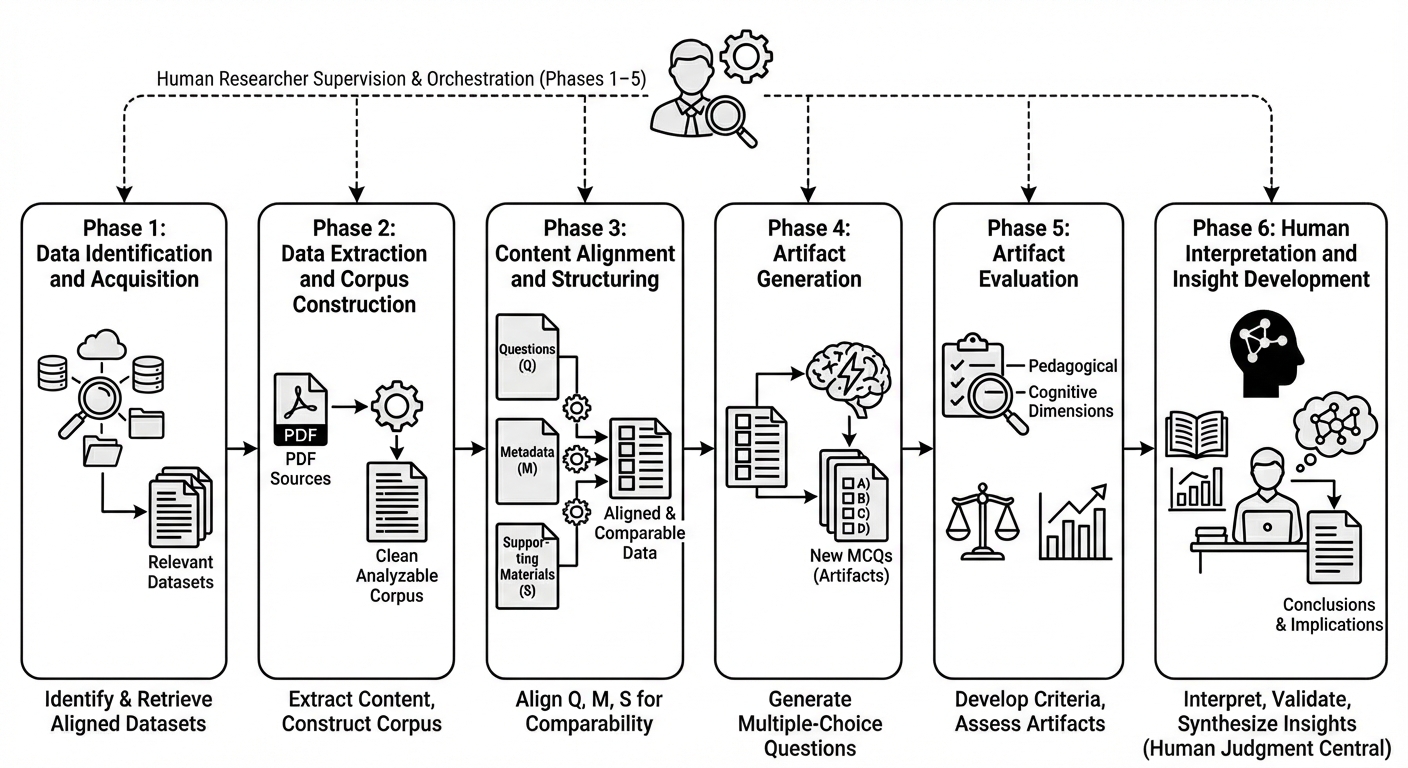
Оркестровка ИИ для Генерации Вопросов: Автоматизация Знания
Мы реализовали автоматизированный рабочий процесс, объединяющий инструменты для извлечения данных, генерации вопросов и оценки их качества. Этот процесс включает в себя последовательное применение различных модулей: извлечение релевантной информации из источников, формирование вопросов на основе извлеченных данных, и последующую автоматическую проверку сгенерированных вопросов по заданным критериям, таким как грамматическая корректность, смысловая ясность и соответствие целевой предметной области. Автоматизация этих этапов позволяет значительно увеличить скорость и объем создаваемых вопросов, снижая при этом потребность в ручной обработке и повышая общую эффективность процесса.
В основе предлагаемого рабочего процесса лежит генерация вопросов с множественным выбором (MCQ) на базе больших языковых моделей (LLM). Для обеспечения фактической точности и релевантности генерируемых вопросов используется конвейер извлечения и генерации (RAG), который опирается на корпус открытых учебников. Этот подход позволяет LLM использовать информацию из учебников в качестве контекста при создании вопросов, тем самым снижая вероятность генерации неверных или нерелевантных утверждений. В процессе RAG, модель сначала извлекает релевантные фрагменты текста из корпуса открытых учебников на основе запроса, а затем использует эти фрагменты в качестве основы для генерации вопросов.
Примененный подход позволяет генерировать большие объемы вопросов — приблизительно 1000 вопросов на один набор — с учетом заданных учебных целей. Этот объем достигается за счет автоматизации процесса создания вопросов и использования больших языковых моделей, что позволяет масштабировать генерацию контента для различных образовательных курсов и задач. Сосредоточенность на конкретных учебных целях гарантирует релевантность генерируемых вопросов и их соответствие требуемому уровню сложности и тематике.

Оценка Качества Вопросов с Помощью ИИ: Суждение Машины
Для оценки сгенерированных вопросов была использована методика “LLM-as-Judge”, основанная на применении большой языковой модели в качестве эксперта-оценщика. Оценка проводилась на основании комплексной оценочной шкалы (Evaluation Rubric), включающей 24 критерия, охватывающих различные аспекты качества вопросов. Данный подход позволяет автоматизировать процесс оценки, обеспечивая последовательность и масштабируемость, в отличие от субъективной оценки, осуществляемой человеком.
Рубрика оценки включала в себя анализ таких параметров вопросов, как уровень когнитивной сложности, педагогическая ценность и соответствие заданным учебным целям. Оценка когнитивной сложности определялась по шкале, учитывающей типы мыслительных процессов, требуемых для ответа на вопрос — от простого воспроизведения информации до анализа, синтеза и оценки. Педагогическая ценность оценивалась с точки зрения стимулирования критического мышления, вовлеченности обучающихся и возможности применения полученных знаний на практике. Соответствие учебным целям определялось путем сопоставления содержания вопроса с конкретными образовательными задачами и ожидаемыми результатами обучения.
Автоматизированная оценка качества вопросов с использованием LLM обеспечивает последовательность и масштабируемость процесса, что принципиально отличает её от субъективной оценки, выполняемой человеком. Традиционная ручная проверка подвержена влиянию личных предпочтений и опыта рецензента, что может приводить к непоследовательным результатам. В отличие от этого, LLM применяет заранее определенные критерии оценки — в данном случае, разработанную рубрику из 24 пунктов — к каждому вопросу, гарантируя одинаковую степень строгости и объективности. Это позволяет обрабатывать большие объемы вопросов значительно быстрее и эффективнее, чем при ручной проверке, и обеспечивает воспроизводимость результатов, что особенно важно для образовательных материалов и систем.
Статистическое Подтверждение Эквивалентности: Измерение Объективности
Для статистического сравнения качества генерируемых вопросов с существующими вопросами по математике SAT использовалось тестирование на эквивалентность TOST (Two One-Sided Tests). Данный подход, основанный на проведении двух односторонних тестов, позволяет установить, не превышает ли разница между двумя наборами вопросов заранее определенный порог, что свидетельствует об их практической эквивалентности. В отличие от традиционных методов, ориентированных на выявление различий, TOST-тестирование направлено на подтверждение сходства, что особенно важно при оценке качества автоматически генерируемых вопросов и их пригодности для использования в стандартизированных тестах. Использование TOST позволило провести строгий количественный анализ, подтверждающий, что генерируемые вопросы обладают сопоставимым уровнем сложности и качества с существующими вопросами SAT по математике.
Тщательный статистический анализ показал, что сгенерированные вопросы соответствуют критериям эквивалентности в 8 из 24 категорий оценки, что свидетельствует о сопоставимом качестве с существующими задачами. Более того, в не менее чем 19 из 24 категорий была продемонстрирована практическая эквивалентность, подтверждающая возможность использования этих вопросов в качестве равноценной замены традиционным заданиям. Полученные результаты указывают на высокую степень соответствия сгенерированного контента установленным стандартам и открывают перспективы для автоматизации процесса создания оценочных материалов.
Реализация данного проекта позволила значительно ускорить процесс разработки оценочных материалов. Традиционно, создание и валидация подобного набора вопросов для математических тестов, таких как SAT, занимала около шести месяцев. Однако, благодаря использованию автоматизированных методов генерации и строгой статистической проверки, вся работа была успешно завершена всего за десять дней. Это существенное сокращение сроков не только снижает затраты, но и открывает возможности для более оперативной адаптации и обновления оценочных инструментов в соответствии с изменяющимися образовательными потребностями.

К Адаптивной и Масштабируемой Оценке: Горизонты Обучения
Автоматизированный конвейер генерации вопросов обладает значительным потенциалом для масштабирования и адаптации к широкому спектру дисциплин и уровней сложности. Разработанная система не ограничивается определенной областью знаний, а способна создавать вопросы по различным предметам — от точных наук, таких как математика и физика, до гуманитарных дисциплин, включая историю и литературу. Более того, алгоритмы позволяют тонко настраивать сложность генерируемых вопросов, обеспечивая соответствие уровню подготовки обучающихся. Это достигается за счет анализа учебного материала и автоматической адаптации формулировок, типов вопросов и требуемого уровня когнитивных навыков. В результате, система способна генерировать как простые вопросы на проверку фактов, так и сложные задачи, требующие анализа, синтеза и оценки информации, что делает ее ценным инструментом для дифференцированного обучения и оценки знаний.
Интеграция разработанной системы автоматической генерации вопросов с платформами управления обучением открывает возможности для создания персонализированных оценочных мероприятий, адаптирующихся к индивидуальному прогрессу каждого учащегося. Система способна анализировать данные об успеваемости студента, выявлять пробелы в знаниях и генерировать вопросы, направленные на их устранение. Этот подход позволяет перейти от стандартных тестов, одинаковых для всех, к динамическим оценкам, которые точно отражают уровень подготовки конкретного учащегося и обеспечивают более эффективную обратную связь. Благодаря такому подходу, учебный процесс становится более целенаправленным и способствует более глубокому усвоению материала, а также позволяет преподавателям оперативно корректировать образовательные стратегии в соответствии с потребностями каждого студента.
Данная технология открывает перспективы для повсеместного доступа к качественным образовательным ресурсам, устраняя географические и социально-экономические барьеры. Автоматизированная генерация вопросов и адаптивное оценивание позволяют создавать персонализированные учебные траектории, учитывающие индивидуальные потребности и темп обучения каждого учащегося. Это особенно важно для образовательных учреждений с ограниченными ресурсами и для учащихся, которым требуется дополнительная поддержка. Подобный подход способствует не только повышению успеваемости, но и формированию более глубокого понимания материала, что в конечном итоге ведет к улучшению образовательных результатов в масштабе всего общества. Расширение доступа к качественному образованию, таким образом, становится не просто целью, а достижимой реальностью благодаря инновационным технологиям.
Исследование демонстрирует, что автоматизация генерации контента с помощью больших языковых моделей (LLM) не упраздняет труд, а трансформирует его. Основная нагрузка смещается с процесса создания на оркестровку, верификацию и контроль качества. В этой связи вспоминается высказывание Джона Маккарти: «Все большие идеи интересны, но если их нельзя проверить, они не стоят ничего.» Эта мысль напрямую соотносится с необходимостью тщательной проверки генерируемых LLM вопросов, подчеркивая, что даже самый мощный инструмент требует критической оценки и контроля со стороны исследователя. Автоматизация — это лишь инструмент, а истинная ценность заключается в способности человека проверять и подтверждать полученные результаты, гарантируя их достоверность и релевантность.
Куда Ведет Автоматизация?
Представленная работа демонстрирует закономерность, знакомую любому инженеру: автоматизация не устраняет труд, она его трансформирует. Вместо создания вопросов для проверки знаний, основной объем работы перемещается в плоскость оркестровки этих автоматизированных систем, а также, что более важно, в строгую верификацию и контроль качества получаемых результатов. Иными словами, машина берет на себя рутину, а человек — критическое мышление. Это не революция, а эволюция, но с ускорением, диктуемым возможностями больших языковых моделей.
Однако, остаются вопросы. Эквивалентность тестов, сгенерированных ИИ, и их реальная способность к оценке знаний — тема для дальнейших исследований. Необходимо разработать метрики, позволяющие объективно оценивать не только формальную корректность ответов, но и глубину понимания материала. И, конечно, нельзя игнорировать проблему “галлюцинаций” моделей — случайных, но уверенно выдаваемых неверных утверждений, которые могут исказить саму суть проверки знаний.
В конечном итоге, будущее научных рабочих процессов видится не в полной автоматизации, а в симбиозе человека и машины. ИИ берет на себя генерацию и первичную обработку информации, а человек — критический анализ, интерпретацию и принятие решений. Задача состоит не в том, чтобы заменить ученого, а в том, чтобы усилить его возможности, освободив от рутинной работы и позволив сосредоточиться на действительно важных вопросах.
Оригинал статьи: https://arxiv.org/pdf/2602.18891.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-24 22:05