Автор: Денис Аветисян
Исследователи представили новый эталонный набор данных для оценки возможностей больших языковых моделей в области китайского трудового законодательства.
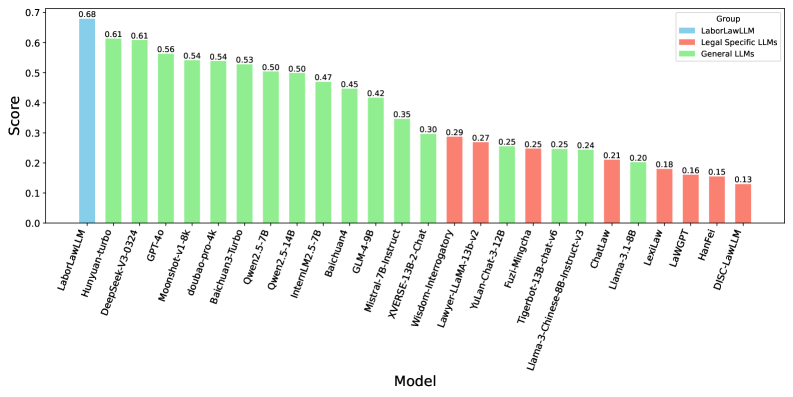
Представлен эталон LaborLaw и модель LaborLawLLM, демонстрирующая превосходство над универсальными и существующими юридическими моделями в задачах, связанных с китайским трудовым правом.
Несмотря на значительный прогресс в области больших языковых моделей, их применение к специализированным правовым задачам, требующим глубоких знаний и контекстуального понимания, остается сложной задачей. В данной работе, озаглавленной ‘Chinese Labor Law Large Language Model Benchmark’, представлен новый комплексный набор данных и модель LabourLawLLM, разработанная специально для китайского трудового законодательства. Эксперименты демонстрируют, что адаптированная модель превосходит универсальные и существующие юридические LLM в различных категориях задач, включая анализ дел и расчет компенсаций. Сможет ли предложенный подход стать масштабируемым решением для создания специализированных LLM в других областях права и повысить надежность систем юридического искусственного интеллекта?
Трудности юридического анализа для больших языковых моделей
Несмотря на впечатляющие возможности больших языковых моделей в обработке текстов общего назначения, применение их к сложным задачам юридического анализа, особенно в контексте тонкостей трудового законодательства Китая, представляет собой значительную проблему. Существующие модели, даже специализированные для юридической сферы, часто демонстрируют недостаток глубоких знаний и способности к логическому выводу, необходимому для точного и надежного анализа правовых ситуаций. В отличие от простого извлечения информации, успешное применение к трудовому праву требует не только знания статей закона, но и умения интерпретировать их в конкретных обстоятельствах каждого дела, что значительно превосходит текущие возможности большинства моделей.
Существующие языковые модели, разработанные для работы с юридической информацией, зачастую демонстрируют недостаточно глубокое понимание и аналитические способности, необходимые для точного и надежного правового анализа. Несмотря на впечатляющие возможности в обработке текста, эти модели сталкиваются с трудностями при применении правовых норм к конкретным ситуациям, особенно когда требуется интерпретация сложных юридических концепций и учет контекста дела. Ограниченность специализированных знаний и неспособность к проведению юридического обоснования, аналогичного человеческому, приводят к ошибкам в анализе и, как следствие, к неверным выводам, что делает их применение в критически важных юридических задачах рискованным и требующим тщательной проверки.
Эффективное применение трудового законодательства Китая требует не просто знания нормативных актов, но и умения интерпретировать их в конкретных ситуациях. Правовая практика показывает, что даже четко сформулированные законы нуждаются в адаптации к уникальным обстоятельствам каждого дела. Успешное разрешение трудовых споров зависит от способности учитывать прецеденты, специфику отрасли и индивидуальные факторы, влияющие на конкретные отношения между работником и работодателем. Понимание нюансов, связанных с региональными особенностями и изменениями в политике, также играет критически важную роль в правильном применении законодательства и обеспечении справедливого исхода.
LaborLawLLM: Специализированное решение для трудового права
LaborLawLLM представляет собой специализированную большую языковую модель, разработанную для решения задач в области трудового законодательства Китая. В качестве основы для построения модели используется Qwen2.5-7B, что обеспечивает её способность к пониманию и генерации текста, релевантного правовой сфере. Специализация на трудовом законодательстве позволяет LaborLawLLM демонстрировать более высокую точность и эффективность в обработке юридических запросов, связанных с трудовыми отношениями, по сравнению с универсальными языковыми моделями.
Модель LaborLawLLM использует метод контролируемого обучения (Supervised Fine-tuning) для обработки обширного набора данных, включающего нормативные акты трудового права КНР, судебную практику и руководящие указания. Этот процесс предполагает обучение предварительно обученной языковой модели на специализированном корпусе данных, что позволяет ей адаптироваться к конкретным задачам в области трудового права. Набор данных состоит из структурированных текстов законодательных актов, решений судов и официальных разъяснений, что обеспечивает модель необходимыми знаниями для анализа и применения трудового законодательства.
Для снижения вычислительных затрат при дообучении модели LaborLawLLM используется LoRA (Low-Rank Adaptation). Эта техника позволяет обучать лишь небольшое количество дополнительных параметров, сохраняя при этом производительность, сопоставимую с полной перенастройкой модели. Вместо обновления всех параметров базовой модели Qwen2.5-7B, LoRA вводит низкоранговые матрицы, которые обучаются параллельно с замороженной базовой моделью. Это существенно снижает требования к объему видеопамяти и времени обучения, делая процесс дообучения более эффективным и экономичным без ущерба для точности и качества результатов.
Строгая оценка на бенчмарке LaborLaw
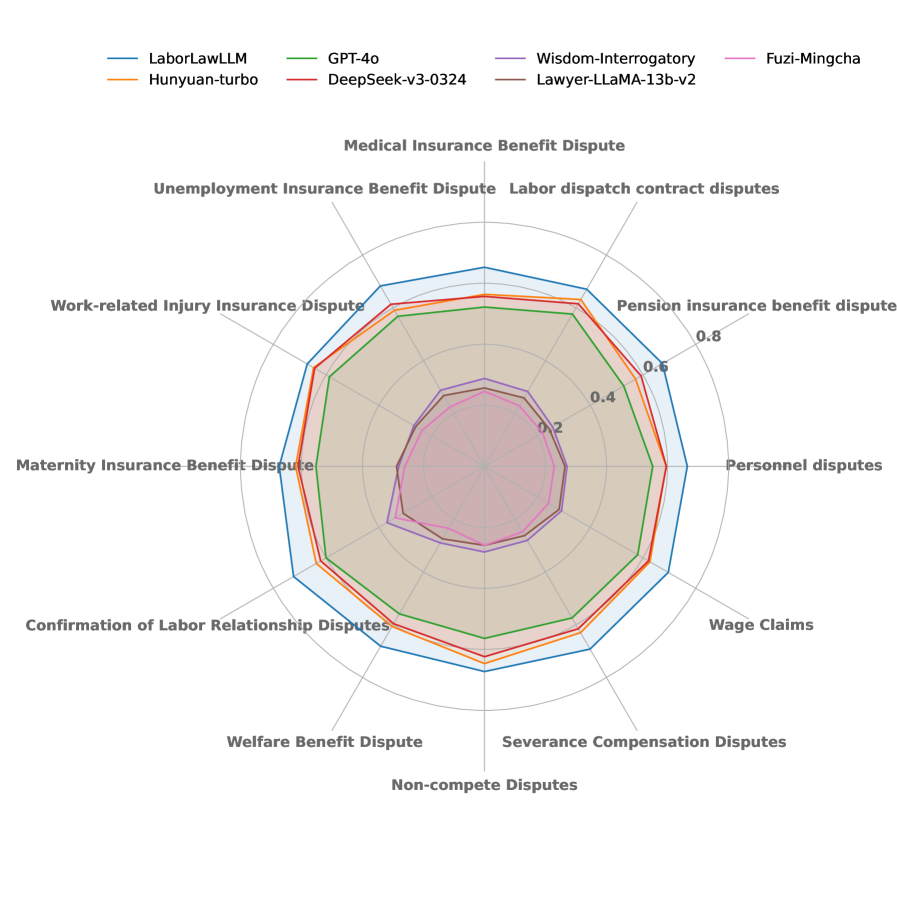
Бенчмарк LaborLaw представляет собой комплексную оценочную платформу, включающую в себя 12 различных задач и 12 категорий дел, относящихся к сфере трудового права Китая. Задачи охватывают широкий спектр сценариев, таких как ответы на вопросы с выбором одного или нескольких вариантов, предсказание оснований для исков, определение сумм компенсаций, распознавание именованных сущностей в юридических текстах и генерация соответствующих правовых положений. Разнообразие категорий дел позволяет оценить способность модели к рассуждениям в различных контекстах трудовых споров, что обеспечивает всестороннюю оценку её производительности в данной предметной области.
Оценка производительности модели LaborLawLLM на бенчмарке LaborLaw осуществляется с использованием комбинированного подхода, включающего метрики точности (Accuracy) для задач классификации, таких как определение типа правонарушения или определение применимости нормативного акта. Для задач распознавания именованных сущностей, например, извлечения дат, сумм компенсаций или названий статей закона, применяется метрика F1 Score. Оценка сгенерированного текста, в частности, предсказания соответствующих правовых норм, производится с использованием метрики ROUGE-L, которая измеряет перекрытие n-грамм между сгенерированным текстом и эталонным ответом. Комбинация этих метрик позволяет всесторонне оценить способность модели решать различные задачи, связанные с китайским трудовым законодательством.
Модель LaborLawLLM продемонстрировала новый рекордный агрегированный результат в 0.68 на бенчмарке LaborLaw, что на 0.07 превышает показатели общецелевых моделей и на приблизительно 0.39 — предыдущих юридических базовых моделей. Данный результат является комплексной оценкой, полученной на основе 12 различных задач и 12 категорий кейсов, отражающих реальные сценарии применения китайского трудового законодательства. Достижение указывает на значительное улучшение в автоматизированном анализе и понимании правовых аспектов, связанных с трудовыми отношениями.
В ходе оценки на LaborLaw Benchmark модель LaborLawLLM продемонстрировала абсолютную точность (1.00) в задаче T2 — Single-Choice Knowledge QA (вопросы с одним правильным ответом). Также, достигнута высокая точность в задачах T3 — Multi-Choice Knowledge QA (вопросы с множественным выбором) и T4 — Cause-of-Action Prediction (предсказание оснований для иска), с результатами 0.95 и 0.99 соответственно. Эти показатели являются наивысшими среди всех протестированных моделей в рамках данного этапа оценки.
Модель демонстрирует высокие результаты в дополнительных задачах: оценка F1 для задачи «Компенсация ущерба» (T5) составила 0.96, а Soft-F1 оценка для задачи «Распознавание именованных сущностей» (T6) достигла 0.98. Данные показатели стабильно превосходят результаты всех сравниваемых базовых моделей, подтверждая эффективность LaborLawLLM в областях, требующих точного извлечения информации и классификации правовых понятий.
Понимание и смягчение поведения отказа
Анализ модели LaborLawLLM выявил тенденцию к отказу от ответов на определенные запросы, что получило название «Поведение отказа». Данное поведение проявляется в избегании ответа на вопросы, которые модель расценивает как потенциально опасные или требующие информации, которой у нее недостаточно. Это не ошибка, а намеренная мера предосторожности, встроенная в алгоритм для предотвращения выдачи вредоносных или неточных юридических заключений. В частности, модель может отказаться отвечать на вопросы, связанные с интерпретацией законов в спорных ситуациях, или на запросы, требующие индивидуальной юридической консультации. Несмотря на то, что такое поведение направлено на обеспечение безопасности и этичности, оно может ограничивать практическую полезность LaborLawLLM в реальных юридических приложениях, требуя дальнейшей оптимизации баланса между безопасностью и информативностью.
Поведение модели LaborLawLLM, проявляющееся в отказе от ответов на определенные запросы, хотя и направлено на предотвращение выдачи вредоносной информации, может существенно ограничить её применимость в реальных юридических сценариях. Отказ от ответа, даже в случаях, когда запрос не представляет прямой угрозы, снижает полезность системы для практикующих юристов и исследователей, которым требуется всесторонний анализ законодательства. Неспособность предоставить информацию, даже если она доступна и релевантна, может привести к необходимости ручной проверки и дополнения ответов, сводя на нет преимущества автоматизации и искусственного интеллекта. Таким образом, баланс между безопасностью и полнотой ответов становится ключевой задачей для повышения эффективности и практической ценности LaborLawLLM в сфере юридической помощи.
Необходимость дальнейших исследований обусловлена потребностью в достижении баланса между безопасностью и отзывчивостью модели LaborLawLLM. Разработка алгоритмов, позволяющих эффективно фильтровать потенциально вредоносные запросы, не снижая при этом способности модели предоставлять исчерпывающую и достоверную юридическую информацию, является ключевой задачей. Ученые стремятся к созданию системы, способной адекватно реагировать на широкий спектр вопросов, связанных с трудовым законодательством, одновременно строго соблюдая этические нормы и предотвращая распространение ложных или вводящих в заблуждение сведений. Успешная реализация этих исследований позволит значительно расширить возможности применения LaborLawLLM в качестве надежного инструмента для оказания юридической помощи.
Представленное исследование подчеркивает важность адаптации больших языковых моделей к специфическим доменам, в частности, к сфере трудового права. Созданный LaborLawLLM демонстрирует превосходство над универсальными моделями и существующими юридическими аналогами, что указывает на необходимость тщательной настройки и обучения моделей для достижения высокой точности и надежности в узкоспециализированных задачах. Как однажды заметила Ада Лавлейс: «Предмет математики не должен быть ограничен рамками количественных вычислений; он охватывает все, что связано с логическими отношениями и измерениями». Эта мысль прекрасно иллюстрирует суть работы, ведь создание эффективной модели для анализа трудового законодательства требует не только обработки огромного количества данных, но и глубокого понимания логических связей и нюансов правовой системы.
Куда двигаться дальше?
Представленный бенчмарк, хоть и демонстрирует превосходство специализированной модели LaborLawLLM, лишь обнажает глубинную проблему: достаточность существующих метрик для оценки юридических систем. Простое повышение точности ответа на тестовые вопросы не гарантирует надёжности в реальных правовых спорах. Необходима разработка метрик, учитывающих не только корректность, но и полноту, контекстуальную уместность и, что самое важное, способность модели к логическому обоснованию своих заключений. Любая модель, не способная продемонстрировать доказуемость своих выводов, остаётся лишь сложным генератором вероятностных ответов.
Очевидным направлением является расширение бенчмарка за счёт включения задач, требующих не просто извлечения информации из текста закона, но и её применения к сложным, многогранным ситуациям. Следует уделить внимание задачам, требующим от модели способности к аналогии, выявлению противоречий и построению аргументации. Необходимо помнить, что закон — это не просто набор правил, а система принципов, требующая интерпретации.
В конечном итоге, истинный прогресс в области юридического ИИ будет достигнут не за счёт увеличения размера модели или количества обучающих данных, а за счёт разработки более элегантных и строгих алгоритмов. Каждый лишний параметр — это потенциальная ошибка, каждая избыточная функция — это усложнение, которое маскирует отсутствие фундаментальной ясности. Поиск математической чистоты — вот истинная цель.
Оригинал статьи: https://arxiv.org/pdf/2601.09972.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-16 18:53