Автор: Денис Аветисян
Обзор показывает, как современные модели машинного обучения автоматизируют рутинные задачи по исправлению ошибок и улучшению качества программного обеспечения.
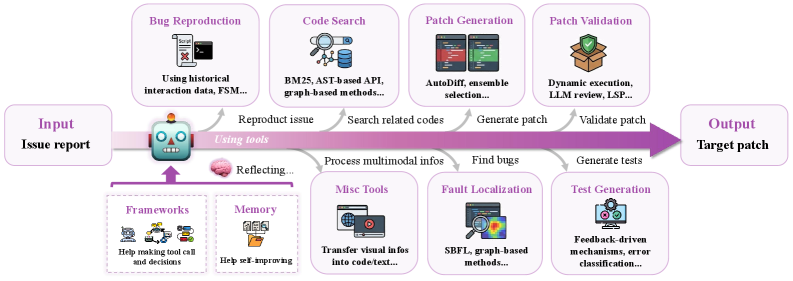
Комплексный анализ современных подходов к автоматизированному решению проблем в разработке программного обеспечения с использованием больших языковых моделей.
Несмотря на значительный прогресс в области искусственного интеллекта, автоматическое исправление ошибок в программном обеспечении остается сложной задачей. Данная работа, озаренная названием ‘Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey’, представляет собой систематический обзор быстро развивающейся области решения проблем в разработке программного обеспечения с использованием больших языковых моделей (LLM). В обзоре подробно рассматриваются методы создания данных, подходы к обучению, включая обучение без учителя и с подкреплением, а также анализ качества данных и поведения агентов. Какие ключевые направления исследований и инноваций позволят LLM эффективно автоматизировать задачи по поддержке и сопровождению программного обеспечения в будущем?
Узкое Место Надежности: Почему Ручное Тестирование Больше Не Работает
Традиционная разработка программного обеспечения в значительной степени опирается на ручное тестирование и отладку, что является процессом, подверженным ошибкам и задержкам. Этот подход, хотя и устоявшийся, требует значительных временных затрат и ресурсов, поскольку каждый новый функционал или исправление требует внимательной проверки человеком. Ошибки, пропущенные на этапе ручного тестирования, могут привести к серьезным последствиям после выпуска продукта, включая финансовые потери и ухудшение репутации. В условиях постоянно растущей сложности программных систем, объемы ручного тестирования становятся непомерными, что создает узкое место в процессе разработки и препятствует своевременному выпуску качественного программного обеспечения. В результате, компании вынуждены искать более эффективные и автоматизированные методы обеспечения надежности своих продуктов.
С увеличением масштаба и сложности кодовой базы, усилия, необходимые для поддержания качества программного обеспечения, растут не линейно, а экспоненциально. Это означает, что при удвоении объема кода, время и ресурсы, требуемые для обнаружения и исправления ошибок, увеличиваются многократно. Данное явление создает критическое «узкое место» в процессе разработки, замедляя выпуск новых функций и снижая надежность продукта. Возникающая сложность связана с увеличением числа возможных взаимодействий между компонентами системы, а также с ростом вероятности появления неочевидных ошибок, требующих глубокого анализа и отладки. В результате, поддержание качества становится все более дорогостоящим и трудоемким, ограничивая возможности для инноваций и конкурентоспособности.
Современные автоматизированные системы тестирования, несмотря на свою эффективность в обнаружении очевидных ошибок, часто оказываются неспособны справиться с тонкими, контекстно-зависимыми дефектами и граничными случаями. Это связано с ограниченностью их способности к логическому выводу и пониманию семантики кода. В отличие от человека, машина не может “понять” намерение разработчика или предвидеть нетипичные сценарии использования, что приводит к пропуску критических ошибок, проявляющихся лишь в определенных условиях. Следовательно, несмотря на значительный прогресс в области автоматизации, ручное тестирование и экспертная оценка остаются необходимыми для обеспечения высокой надежности программного обеспечения, особенно в сложных и критически важных системах.
Языковые Модели Вступают в Эру Решения Проблем
Большие языковые модели (LLM) демонстрируют неожиданную способность к пониманию кода на различных языках программирования и выявлению потенциальных проблем, таких как синтаксические ошибки, логические несоответствия и уязвимости безопасности. Этот анализ осуществляется за счет предварительного обучения на огромных объемах общедоступного кода и последующей адаптации к конкретным задачам, что позволяет моделям не только находить ошибки, но и предлагать варианты их исправления. Способность LLM к автоматическому выявлению проблем в коде открывает перспективы для автоматизации процессов отладки, рефакторинга и повышения качества программного обеспечения, значительно сокращая время и затраты на разработку.
Для обучения больших языковых моделей (LLM) решению проблем используются методы контролируемого обучения с учителем (Supervised Fine-Tuning, SFT) и обучение с подкреплением (Reinforcement Learning, RL). SFT предполагает настройку предварительно обученной модели на размеченном наборе данных, состоящем из описаний проблем и соответствующих исправлений кода. RL, в свою очередь, использует систему вознаграждений, где модель обучается путем взаимодействия со средой (например, компилятором или системой контроля версий) и получения обратной связи о качестве предлагаемых решений. Обучение с подкреплением позволяет LLM оптимизировать стратегии исправления ошибок, основываясь на полученных наградах за успешные исправления и штрафах за неудачные попытки. Комбинирование SFT и RL позволяет добиться высокой эффективности LLM в автоматическом выявлении и устранении проблем в коде.
Эффективность решения проблем с использованием больших языковых моделей (LLM) напрямую зависит от качества предоставляемого описания проблемы и доступности соответствующей кодовой базы. Четкое и детализированное описание проблемы, включающее конкретные симптомы, шаги воспроизведения и ожидаемый результат, значительно повышает точность анализа LLM. Аналогично, полный и структурированный доступ к релевантному коду позволяет модели проводить более глубокий анализ, выявлять первопричины и предлагать обоснованные исправления. Ограниченный или неточный доступ к кодовой базе, а также расплывчатые или неполные описания проблем, существенно снижают эффективность LLM и могут приводить к ошибочным результатам или нерелевантным решениям.
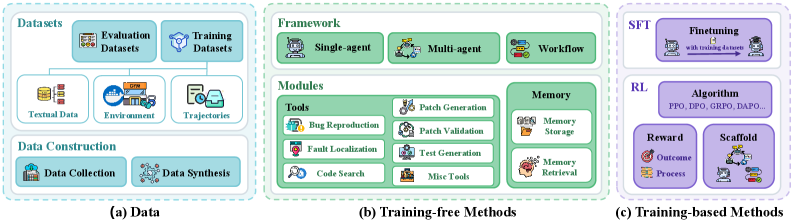
Оценка Эффективности: Стандартизированные Наборы Данных и Метрики
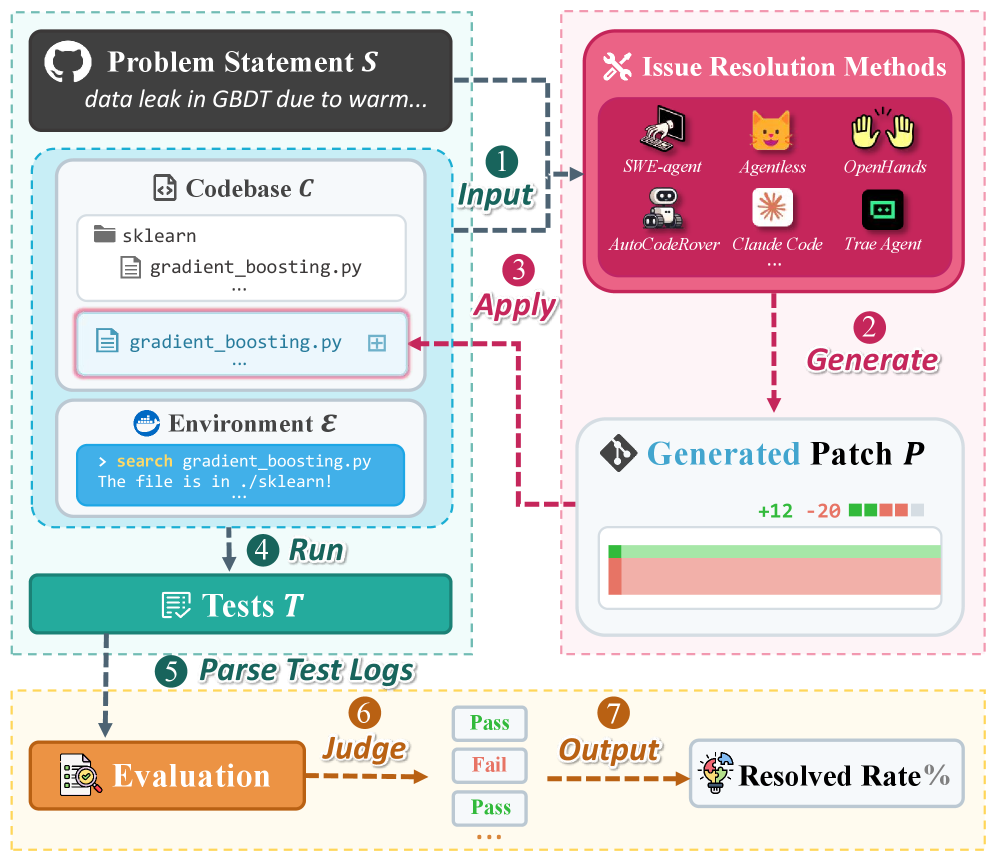
Для оценки возможностей больших языковых моделей (LLM) в области генерации кода и решения проблем используются стандартизированные наборы данных, такие как SWE-bench и HumanEval. SWE-bench включает в себя набор задач, охватывающих различные аспекты разработки программного обеспечения, включая исправление ошибок, реализацию новых функций и рефакторинг кода. HumanEval, разработанный OpenAI, фокусируется на оценке способности моделей генерировать функциональный код на основе текстового описания задачи. Использование этих наборов данных позволяет проводить объективное сравнение различных LLM и отслеживать прогресс в области автоматизации разработки программного обеспечения, предоставляя количественные показатели производительности, такие как процент успешно решенных задач.
Ключевым показателем оценки производительности моделей при решении задач является «Коэффициент Успешного Решения» (Resolve Rate), который представляет собой процент задач, успешно решенных моделью из общего числа представленных на тестирование. Этот показатель рассчитывается как отношение количества корректно решенных задач к общему количеству задач, умноженное на 100%. Высокий коэффициент успешного решения указывает на более эффективную способность модели к генерации корректного кода или решению поставленных проблем, в то время как низкий показатель может указывать на необходимость улучшения алгоритмов или увеличения объема обучающих данных. Для обеспечения надежности оценки, коэффициент успешного решения должен рассчитываться на стандартизированных наборах данных, таких как SWE-bench или HumanEval.
Эффективное управление контекстом является критически важным для успешного решения задач большими языковыми моделями (LLM). Этот процесс включает в себя обеспечение доступа модели к релевантной информации, необходимой для анализа и исправления проблем. Техники управления контекстом включают в себя не только предоставление исходного кода и описания ошибки, но и передачу информации о предыдущих исправлениях, структуре проекта и связанных файлах. Недостаточный или некорректный контекст приводит к снижению точности решения, увеличению количества ошибок и невозможности решения сложных задач, требующих понимания взаимосвязей между различными частями кодовой базы. В частности, методы, такие как retrieval-augmented generation (RAG), позволяют динамически извлекать и предоставлять релевантную информацию из внешних источников, значительно повышая эффективность LLM в задачах исправления ошибок.
К Автоматизированной Эволюции Программного Обеспечения: Заглядывая в Будущее
Принципы, успешно применяемые для автоматического исправления ошибок в коде с помощью больших языковых моделей (LLM), закономерно распространяются на задачу автоматической генерации программного обеспечения. Вместо простого исправления существующих дефектов, LLM теперь способны создавать новые функциональные возможности и целые модули кода, опираясь на заданные спецификации или описание желаемого поведения. Это достигается благодаря способности моделей понимать естественный язык и преобразовывать его в исполняемый код, значительно снижая потребность в ручном кодировании и ускоряя процесс разработки. Возможность автоматической генерации открывает перспективы для создания программного обеспечения по требованию, адаптации к меняющимся потребностям пользователей и упрощения процесса прототипирования, представляя собой значительный шаг к более гибкой и эффективной разработке.
Многоагентные системы, такие как ChatDev и MetaGPT, представляют собой новаторский подход к автоматизации разработки программного обеспечения, имитируя работу слаженной команды разработчиков. Вместо единой большой языковой модели, эти фреймворки используют несколько LLM-агентов, каждый из которых выполняет специализированную роль — от планирования и кодирования до тестирования и документирования. Агенты взаимодействуют друг с другом посредством текстовых сообщений, обмениваясь идеями, запрашивая обратную связь и координируя свои действия для достижения общей цели — создания функционального программного обеспечения. Такой подход позволяет не только ускорить процесс разработки, но и повысить качество кода за счет коллективного интеллекта и постоянного взаимного контроля, приближая реальность полностью автоматизированного жизненного цикла программного обеспечения.
В перспективе, развитие технологий, основанных на больших языковых моделях, предвещает наступление эры автоматизированного сопровождения программного обеспечения. Системы будущего смогут не только реагировать на возникающие проблемы, но и предвидеть их, анализируя код и поведение приложения в процессе эксплуатации. Такой проактивный подход к выявлению и устранению уязвимостей и ошибок позволит значительно повысить надежность и масштабируемость программных продуктов, снижая потребность в ручном вмешательстве и обеспечивая непрерывную работу критически важных систем. Автоматизация обслуживания позволит разработчикам сосредоточиться на инновациях и создании новых функций, а не на устранении старых проблем, что, в свою очередь, ускорит темпы развития всей индустрии.
Исследование, представленное в статье, напоминает процесс деконструкции сложной системы. Авторы тщательно анализируют текущие подходы к решению проблем в разработке программного обеспечения с использованием больших языковых моделей, выявляя их сильные и слабые стороны. Этот подход к автоматизации задач обслуживания программного обеспечения требует глубокого понимания внутренних механизмов этих моделей. Как точно заметил Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он работает». Действительно, прежде чем полностью доверить решение проблем LLM, необходимо тщательно проверить и понять принципы их работы, чтобы обеспечить надежность и предсказуемость результатов. Особое внимание к созданию надежных оценочных критериев и бенчмарков, описанных в статье, подтверждает важность проверки и валидации перед масштабированием.
Что дальше?
Представленный обзор, подобно разборке сложного механизма, выявил не только текущее состояние, но и зияющие прорехи в понимании возможностей больших языковых моделей (LLM) в контексте решения проблем разработки программного обеспечения. LLM, безусловно, демонстрируют потенциал, однако их применение пока больше напоминает игру с исходным кодом, нежели глубокое его понимание. Реальность, как открытый исходный код, который ещё предстоит прочитать, требует не просто генерации синтаксически верного кода, но и осмысления семантики, контекста и намерений разработчика.
Ключевым вызовом остаётся преодоление «галлюцинаций» LLM и обеспечение верифицируемости предлагаемых решений. Автоматизированное тестирование и формальная верификация, несомненно, необходимы, но они лишь констатируют факт наличия или отсутствия ошибки, не объясняя её природу. Следующим шагом видится разработка методов, позволяющих LLM не только «исправлять» код, но и «объяснять» логику исправления, предоставляя доказательства корректности.
Будущее LLM в разработке программного обеспечения, вероятно, лежит в области агентных систем, способных самостоятельно исследовать проблему, формулировать гипотезы, проверять их и адаптироваться к изменяющимся условиям. Однако, прежде чем доверить LLM управление сложными программными системами, необходимо решить этические и практические вопросы, связанные с ответственностью, безопасностью и предсказуемостью их поведения. Иначе, взлом системы окажется куда проще, чем её реверс-инжиниринг.
Оригинал статьи: https://arxiv.org/pdf/2601.11655.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые прорывы: Хорошее, плохое и смешное
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая криптография: от теории к практике
2026-01-21 08:04