Автор: Денис Аветисян
Исследователи представили передовую систему искусственного интеллекта, способную эффективно анализировать медицинские запросы и поддерживать принятие обоснованных клинических решений.
Baichuan-M3 — модель, использующая обучение с подкреплением и методы верификации фактов для минимизации галлюцинаций и достижения передовых результатов в задачах медицинской диагностики и поддержки принятия решений.
Несмотря на значительный прогресс в области больших языковых моделей, создание надежных систем поддержки принятия решений в медицине остается сложной задачей. В данной работе представлена модель ‘Baichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making’, разработанная для перехода от пассивного ответа на вопросы к активному, клинически обоснованному принятию решений. Baichuan-M3 демонстрирует передовые результаты на эталонных наборах данных, таких как HealthBench и ScanBench, благодаря специализированной процедуре обучения, направленной на моделирование систематического подхода врача к диагностике и снижению вероятности галлюцинаций. Сможет ли данная модель стать надежным помощником врача в сложной клинической практике?
Вызов надежности клинического ИИ: граница между знанием и иллюзией
Несмотря на впечатляющую мощь, современные большие языковые модели сталкиваются с серьезными трудностями при работе с фактологической точностью и логическим мышлением в сложных медицинских контекстах. Это проявляется в неспособности последовательно поддерживать достоверность информации, что представляет значительную опасность в сфере здравоохранения. Врачи и пациенты могут столкнуться с неверными диагнозами, неадекватными рекомендациями по лечению или неточной интерпретацией медицинских данных, если полагаться на ответы, сгенерированные этими системами. Проблема усугубляется тем, что модели часто выдают правдоподобные, но ошибочные сведения, маскируя неточность под уверенность, что затрудняет выявление и исправление ошибок. Таким образом, надежность и безопасность применения больших языковых моделей в клинической практике требуют тщательной оценки и разработки механизмов контроля качества.
Современные языковые модели, несмотря на свою впечатляющую производительность, склонны к «галлюцинациям» — генерации правдоподобных, но фактически неверных ответов. В контексте здравоохранения эта особенность представляет собой серьезную проблему, поскольку ошибочная диагностика или неверные рекомендации могут иметь критические последствия для пациентов. Данное явление связано с тем, что модели, обученные на огромных объемах данных, часто фокусируются на статистической вероятности слов, а не на фактической достоверности информации. В результате, даже если ответ звучит убедительно, он может быть полностью лишен научного обоснования и представлять угрозу для здоровья.
Традиционные подходы к увеличению масштаба языковых моделей, основанные на простом наращивании объемов данных и вычислительных мощностей, демонстрируют свою неэффективность в решении проблем фактической достоверности и логического мышления, особенно в сложной медицинской сфере. Исследования показывают, что увеличение размера модели само по себе не гарантирует повышение надежности и точности ответов. В связи с этим, всё большее внимание уделяется разработке принципиально новых архитектур нейронных сетей и методов обучения, способных обеспечить более глубокое понимание контекста и более корректное рассуждение. Эти инновации включают в себя, например, интеграцию механизмов проверки фактов, использование знаний из специализированных медицинских баз данных и разработку алгоритмов, способных выявлять и корректировать собственные ошибки, что необходимо для создания действительно надежных систем искусственного интеллекта в здравоохранении.
Baichuan-M3: Фундамент для достоверного рассуждения
Baichuan-M3 представляет собой медицинскую языковую модель нового поколения, разработанную для интеграции клинического поиска и надежной поддержки принятия решений. В отличие от традиционных моделей, опирающихся на распознавание паттернов в существующих данных, Baichuan-M3 ориентирована на объединение информации из различных источников и проведение логических умозаключений. Это позволяет модели не просто воспроизводить известные факты, но и активно участвовать в процессе клинического анализа, предлагая обоснованные выводы и рекомендации, что критически важно для повышения точности диагностики и эффективности лечения.
Архитектура Baichuan-M3 отличается от традиционных LLM акцентом на активный сбор информации и последовательное рассуждение, а не на простом воспроизведении заученных данных. Вместо опоры исключительно на предобученную базу знаний, модель способна формулировать запросы для получения недостающей информации в процессе решения клинической задачи. Это достигается за счет интеграции механизмов, позволяющих модели определять пробелы в своих знаниях и целенаправленно обращаться к внешним источникам данных для их заполнения, что обеспечивает более надежные и обоснованные выводы, особенно в ситуациях, требующих анализа сложных и неоднозначных клинических случаев.
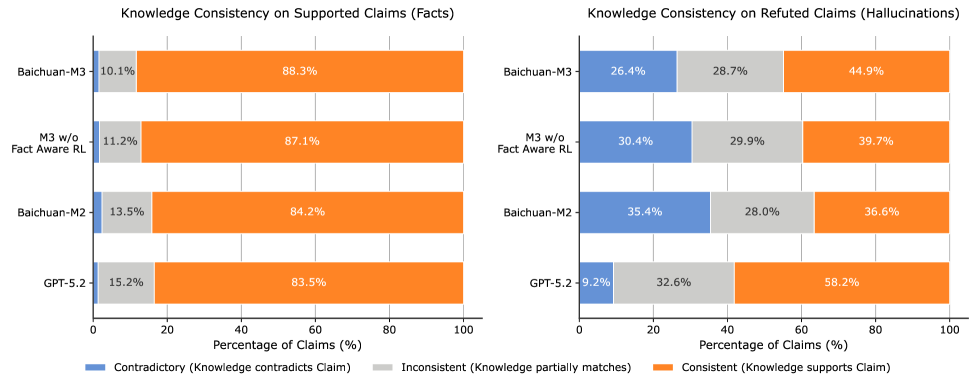
Ключевой особенностью Baichuan-M3 является адаптивное подавление галлюцинаций, представляющее собой активный механизм снижения вероятности генерации неверной или вводящей в заблуждение информации. В отличие от пассивных методов, данная система динамически оценивает достоверность генерируемого контента и корректирует процесс генерации в режиме реального времени. Это достигается за счет использования специализированных алгоритмов, определяющих степень соответствия генерируемых утверждений имеющимся клиническим данным и логическим выводам. В результате, Baichuan-M3 демонстрирует повышенную надежность и точность при предоставлении медицинской информации, минимизируя риски, связанные с распространением недостоверных сведений.
Первоначальное обучение модели Baichuan-M3 осуществлялось с применением метода Offline Policy Distillation (офлайн-дистилляция политики). Этот подход предполагает обучение модели путем имитации поведения экспертной политики, полученной из заранее собранного набора данных клинических взаимодействий. Вместо непосредственного обучения с подкреплением, требующего активного взаимодействия со средой, Offline Policy Distillation позволяет извлечь знания из статических данных, что обеспечивает эффективное создание базового уровня клинической экспертизы. Этот метод позволяет модели изучать сложные стратегии принятия решений, основываясь на исторических данных, и формировать надежную основу для дальнейшей оптимизации и адаптации к новым задачам.
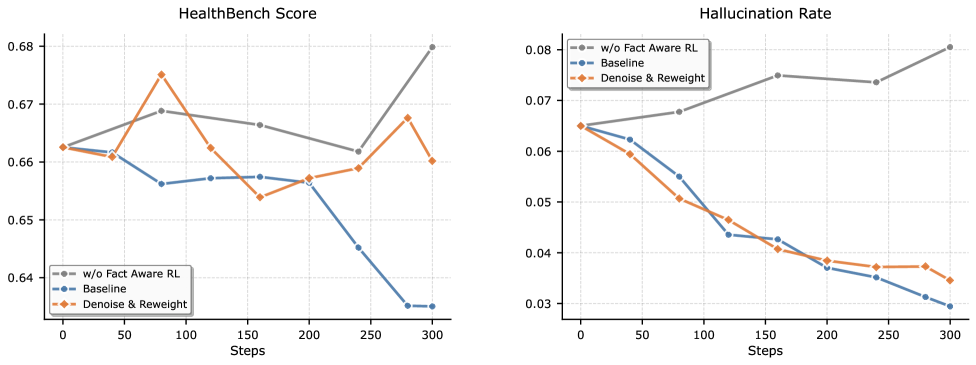
Оптимизация производительности с помощью продвинутого обучения с подкреплением
Для оптимизации модели Baichuan-M3 в критически важных клинических рабочих процессах применяется обучение с подкреплением, ориентированное на конкретные задачи. Этот подход позволяет улучшить производительность модели в таких областях, как обработка запросов пациентов, анализ результатов лабораторных исследований и постановка диагнозов. Обучение с подкреплением нацелено на максимизацию вознаграждения, полученного в результате выполнения конкретных задач, что приводит к повышению точности и эффективности модели в контексте клинических приложений. Особое внимание уделяется адаптации модели к специфическим требованиям и протоколам, используемым в медицинских учреждениях.
Метод онлайн-дистилляции политики с использованием нескольких учителей (Multi-Teacher Online Policy Distillation) позволяет улучшить производительность модели Baichuan-M3 за счет одновременного использования знаний, полученных от нескольких экспертных моделей. В процессе обучения, «студенческая» модель непрерывно подстраивается под совместное поведение нескольких «учителей», что позволяет ей усваивать более широкий спектр стратегий и подходов к решению задач. Такой подход позволяет эффективно комбинировать сильные стороны различных экспертных моделей, избегая ограничений, присущих использованию только одной экспертной модели. В результате, модель демонстрирует улучшенные показатели в сложных сценариях, требующих многогранного анализа и принятия решений.
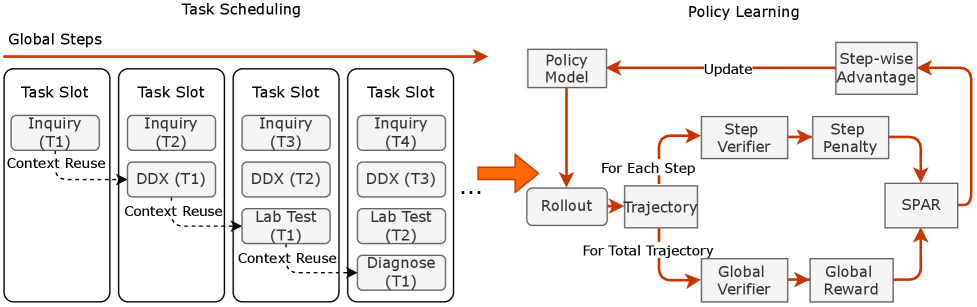
Метод обучения с подкреплением через сегментированный конвейер (Segmented Pipeline RL) предполагает декомпозицию сложных задач на последовательность управляемых этапов. Такой подход позволяет значительно повысить эффективность модели при взаимодействиях, требующих долгосрочного планирования, за счет снижения накопления ошибок на протяжении всей последовательности действий. Разбиение задачи на этапы упрощает процесс обучения, позволяя модели более эффективно осваивать сложные стратегии и избегать проблем, связанных с экспоненциальным ростом пространства состояний, характерных для задач с длинным горизонтом планирования. Каждый этап конвейера оптимизируется отдельно, что способствует повышению общей надежности и точности выполнения сложных клинических задач.
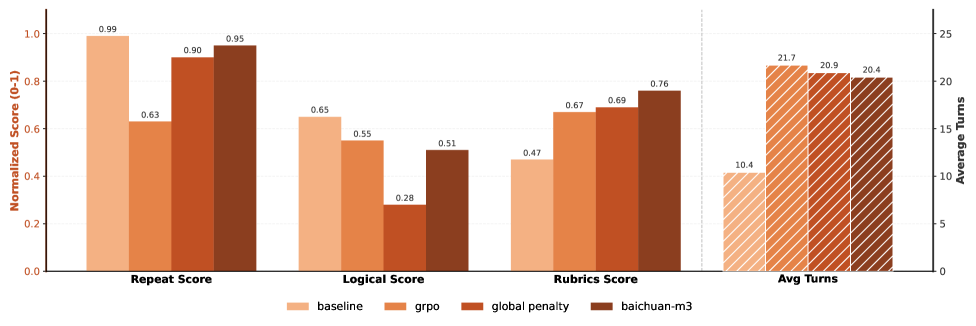
Динамическая эволюция рубрик (Dynamic Rubric Evolution) представляет собой метод, используемый для автоматической корректировки метрик оценки в процессе обучения модели Baichuan-M3. Этот подход предотвращает “взлом” системы вознаграждений (reward hacking), когда модель оптимизируется для получения высокой оценки, не решая задачу эффективно. Вместо использования фиксированных метрик, система динамически адаптирует критерии оценки на основе поведения модели, акцентируя внимание на подлинном рассуждении и фактической точности. Это достигается путем мониторинга производительности модели и корректировки весов различных аспектов оценки, что способствует развитию более надежных и обоснованных ответов.
Валидация и повышение эффективности с помощью бенчмаркинга
Модель Baichuan-M3 подверглась всесторонней оценке с использованием двух ключевых бенчмарков: ScanBench и HealthBench. ScanBench представляет собой сложный набор задач, имитирующих реальные клинические рабочие процессы, позволяя оценить способность модели к последовательному решению медицинских проблем. В свою очередь, HealthBench фокусируется на проверке фактических знаний и навыков логического мышления в медицинской сфере. Тщательное тестирование на этих платформах позволило не только количественно оценить производительность модели, но и выявить ее сильные и слабые стороны в контексте практического применения в здравоохранении, что является важным шагом для дальнейшей оптимизации и внедрения.
Модель Baichuan-M3 продемонстрировала выдающиеся результаты на бенчмарке HealthBench-Hard, достигнув показателя в 44.4 балла. Этот результат существенно превосходит все предыдущие state-of-the-art достижения в данной области, подтверждая значительный прогресс в возможностях модели по обработке и анализу медицинских данных. Достижение подобного уровня точности имеет важное значение для потенциального применения модели в клинической практике, где требуется высокая надежность и достоверность информации. Превосходство над предыдущими решениями указывает на улучшенное понимание сложных медицинских концепций и способность к более точному рассуждению, что открывает новые перспективы для автоматизации задач в сфере здравоохранения.
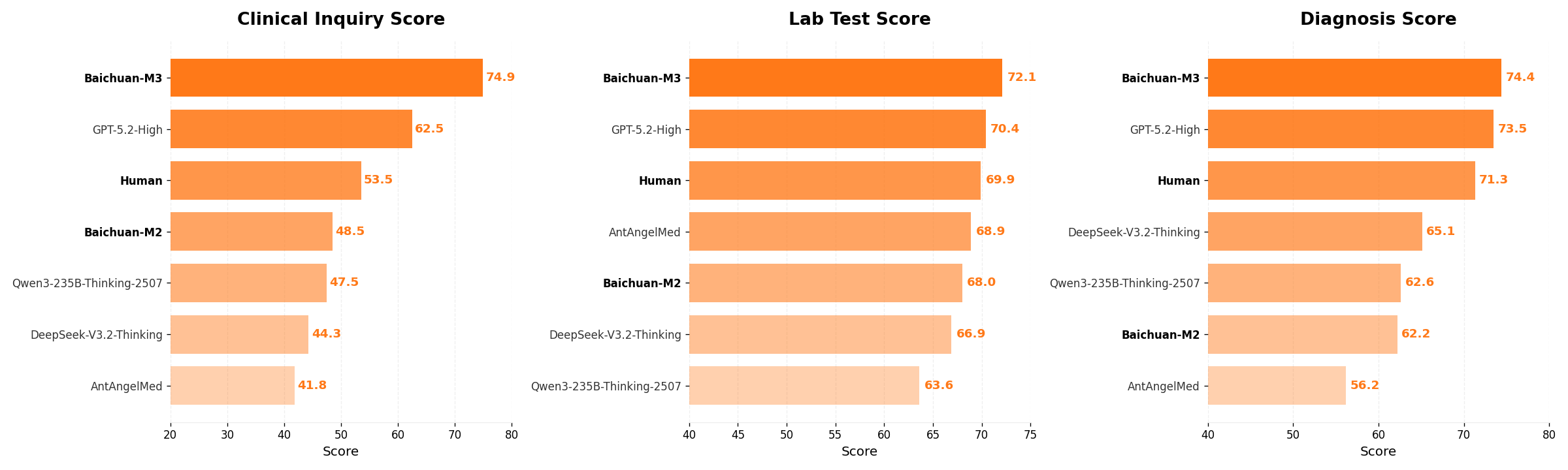
В ходе оценки модели Baichuan-M3 на ScanBench, имитирующем клинические рабочие процессы, были получены впечатляющие результаты в задаче “Clinical Inquiry”. Модель продемонстрировала способность превзойти результаты, показанные людьми-экспертами, на более чем 20 баллов, достигнув отметки в 74.9. Этот показатель свидетельствует о значительном прогрессе в автоматизации анализа клинических данных и потенциале Baichuan-M3 для поддержки принятия решений в медицинской практике, превосходя существующие возможности в интерпретации и обработке сложной медицинской информации.
В ходе оценки на базе ScanBench, модель продемонстрировала выдающиеся результаты в областях лабораторной диагностики и постановки диагнозов, набрав 72,1 и 74,4 балла соответственно. Эти показатели свидетельствуют о способности модели эффективно анализировать данные лабораторных исследований и клинических случаев, что позволяет ей с высокой точностью выявлять патологии и предлагать вероятные диагнозы. Особенно значимо, что данная производительность достигается благодаря способности модели к комплексному анализу и синтезу информации, что позволяет ей превосходить существующие системы в задачах, требующих глубокого понимания медицинской терминологии и контекста.
Для существенного снижения вычислительных затрат и повышения скорости работы модели Baichuan-M3 были применены оптимизации, включающие квантизацию и архитектуру Gated Eagle-3 с использованием спекулятивного декодирования. Квантизация позволяет уменьшить размер модели и требования к памяти, а Gated Eagle-3, за счет более эффективной обработки информации, ускоряет процесс генерации ответов. В результате, удалось добиться значительного улучшения длины принимаемой последовательности — на 0.31, что свидетельствует о более стабильной и быстрой работе модели даже при обработке сложных запросов. Данные оптимизации позволяют использовать Baichuan-M3 на менее мощном оборудовании, расширяя возможности её применения в различных областях, где важна скорость и эффективность обработки информации.
Разработанный подход обучения с подкреплением, ориентированный на факты, позволил значительно снизить склонность модели к галлюцинациям — вероятность генерации неверной или необоснованной информации достигла всего 0.035. Достижение этой высокой точности стало возможным благодаря комбинации двух ключевых методов. Во-первых, применена фильтрация шумов, направленная на удаление недостоверных данных из обучающего процесса. Во-вторых, использовался механизм компетентностной фильтрации, который позволяет модели оценивать свою уверенность в ответах и избегать генерации информации, если уровень уверенности недостаточно высок. Такой симбиоз фильтрации и оценки позволяет Baichuan-M3 предоставлять более надежные и правдивые ответы, что критически важно для применения в областях, требующих высокой точности и достоверности.
Исследование Baichuan-M3 демонстрирует стремление к взлому сложной системы — клинического мышления. Авторы не просто создают модель, но и подвергают её тщательному тестированию, стремясь минимизировать галлюцинации и повысить надёжность принимаемых решений. Этот подход, направленный на проверку границ возможного, созвучен философии Линуса Торвальдса: «Если у вас не можете объяснить что-то просто, значит, вы сами этого не понимаете». Разработка Baichuan-M3, как и любой процесс реверс-инжиниринга, требует глубокого понимания исходной системы и умения выявлять её слабые места, чтобы создать более совершенный инструмент поддержки принятия решений.
Что дальше?
Представленная модель Baichuan-M3, безусловно, представляет собой шаг вперед в попытках обуздать языковых гигантов для практического применения в медицине. Однако, как показывает опыт, любое “обуздание” — это лишь временная иллюзия контроля. Успешное снижение галлюцинаций — это не победа над системой, а лишь перенаправление её ошибок в менее заметные области. Истинная проверка — не в лабораторных бенчмарках, а в реальных клинических сценариях, где цена ошибки измеряется не процентами, а жизнями.
Следующим этапом представляется не столько улучшение существующих методов обучения, сколько разработка принципиально новых подходов к верификации фактов. Необходимо отойти от простой проверки соответствия текста заранее известным данным и перейти к моделированию процесса рассуждения, к пониманию как система пришла к тому или иному выводу. Иначе, мы получим лишь более изощренного попугая, способного убедительно повторять правду и ложь.
В конечном счете, задача не в создании идеального медицинского ИИ, а в создании системы, способной признать свою некомпетентность. Модель, которая честно скажет: “Я не знаю”, — ценнее, чем та, которая самоуверенно ошибется. Ведь, в конце концов, взлом реальности требует не только знаний, но и скромности.
Оригинал статьи: https://arxiv.org/pdf/2602.06570.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Переворот: От Теории к Реальности
- Плоские зоны: от теории к новым материалам
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект на службе редких болезней
- Творческий процесс под микроскопом: от логов к искусственному интеллекту
- Видео-Мыслитель: гармония разума и визуального потока.
- Язык тела под присмотром ИИ: архитектура и гарантии
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Наука, управляемая интеллектом: новая эра открытий
2026-02-09 21:44