Автор: Денис Аветисян
Вместо гигантских нейросетей, будущее ИИ строится на эффективной координации небольших, узкоспециализированных моделей и инструментов.
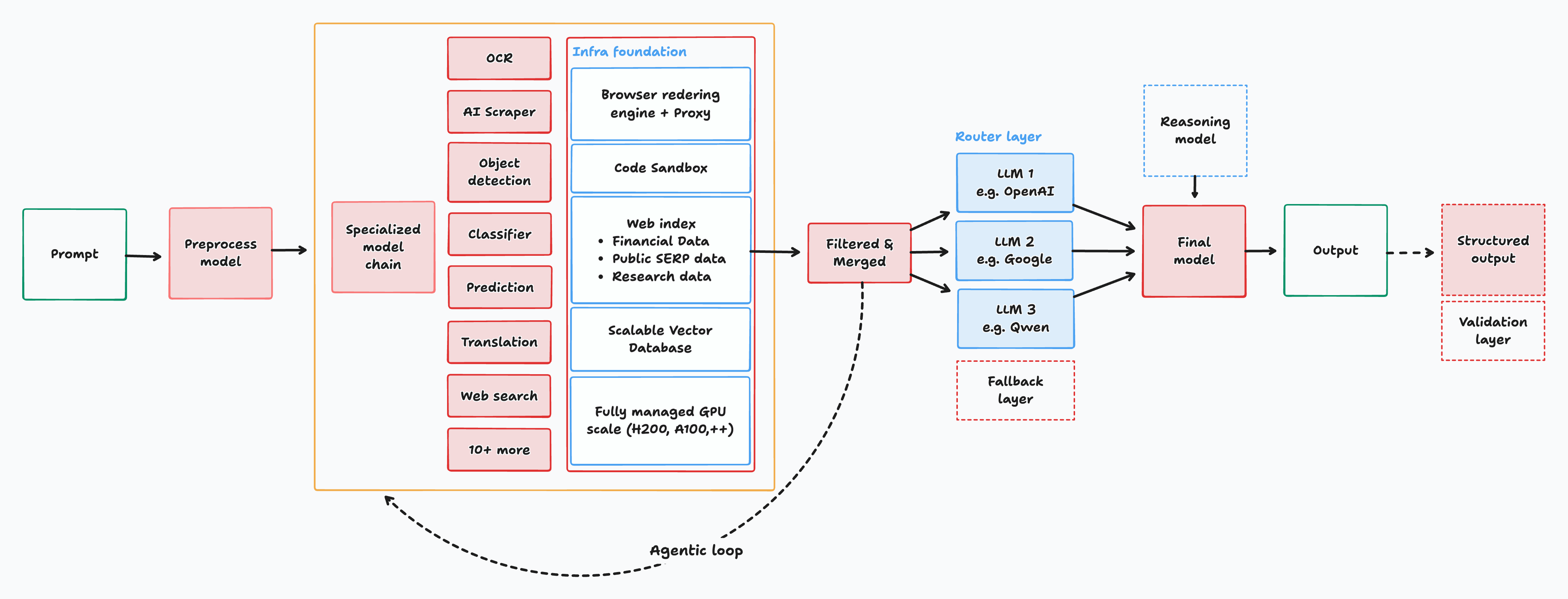
Представлена архитектура Interfaze, обеспечивающая конкурентоспособные результаты в мультимодальном анализе и логических рассуждениях за счет управления контекстом с помощью стека специализированных моделей.
Современные подходы к созданию интеллектуальных систем часто полагаются на монолитные языковые модели, что ограничивает их эффективность и масштабируемость. В данной работе представлена система ‘Interfaze: The Future of AI is built on Task-Specific Small Models’ — архитектура, использующая стек специализированных небольших моделей и инструментов для построения и управления контекстом, а также оркестровки их работы. Показано, что такой подход позволяет достичь конкурентоспособных результатов на мультимодальных и логических бенчмарках, перенося основную вычислительную нагрузку с крупных моделей на более эффективные компоненты. Возможно ли создание действительно гибких и адаптивных интеллектуальных систем, способных эффективно решать широкий спектр задач, опираясь на принципы модульности и специализированного подхода?
За пределами Трансформеров: Необходимость Контекстно-Ориентированного ИИ
Несмотря на впечатляющую способность больших языковых моделей распознавать закономерности в данных, их возможности в области сложного рассуждения и интеграции внешних знаний часто оказываются ограниченными. Это приводит к возникновению фактических неточностей и хрупкости в работе системы — даже незначительные изменения во входных данных могут вызвать существенные ошибки. Модели, обученные на огромных массивах текста, зачастую лишь поверхностно понимают информацию, не обладая глубоким пониманием причинно-следственных связей или контекста. В результате, они могут генерировать правдоподобно звучащие, но не соответствующие действительности утверждения, что ставит под сомнение их надежность в критически важных приложениях и подчеркивает необходимость разработки более совершенных подходов к искусственному интеллекту.
Традиционные подходы к созданию искусственного интеллекта часто рассматривают контекст как вторичный элемент, добавляемый уже после обработки основных данных. Это приводит к тому, что системы испытывают трудности с эффективным использованием внешней информации и поддержанием связности в сложных задачах. Ограниченность в понимании контекста проявляется в неспособности правильно интерпретировать неоднозначные запросы, делать логические выводы, требующие знаний, выходящих за рамки тренировочного набора, и, как следствие, в генерации неточных или бессмысленных ответов. Вместо того, чтобы интегрировать контекст в саму архитектуру системы, многие модели полагаются на поверхностное сопоставление шаблонов, что делает их хрупкими и уязвимыми к изменениям в формулировках или при добавлении новых знаний. В результате, полноценное понимание и эффективное использование информации, необходимой для решения сложных задач, остаётся сложной проблемой.
Необходимость в новой парадигме искусственного интеллекта обусловлена ограничениями существующих моделей, которые зачастую оперируют поверхностными закономерностями, а не глубоким пониманием контекста. Вместо того чтобы рассматривать контекст как дополнение, предлагается сделать его основополагающим элементом системы. Такой подход подразумевает структурирование информации, что позволяет ИИ не только более эффективно использовать внешние знания, но и обеспечивать повышенную надежность и устойчивость к ошибкам. Внедрение структурированного контекста позволит создавать системы, способные к более сложному рассуждению, более точному моделированию реальности и, как следствие, к более эффективному решению широкого спектра задач.
Interfaze: Архитектура, Ставящая Контекст на Первое Место
Архитектура Interfaze представляет собой новый подход к построению систем искусственного интеллекта, отличающийся приоритетом создания надежного и структурированного ‘Контекста’ из различных источников. Традиционные методы часто сталкиваются с ограничениями в обработке неструктурированных данных и поддержании актуальности знаний. Interfaze решает эту проблему, активно собирая и интегрируя информацию из внешних источников, обеспечивая динамическую и актуальную базу знаний, необходимую для принятия обоснованных решений и повышения общей эффективности системы. В отличие от подходов, фокусирующихся на прямой обработке входных данных, Interfaze предварительно формирует контекст, что позволяет более точно интерпретировать запросы и генерировать релевантные ответы.
В архитектуре Interfaze для эффективной обработки входящих данных и сбора релевантной информации используются небольшие глубокие нейронные сети (Small DNNs) и слои семантической памяти (SLMs). Small DNNs выполняют специализированные задачи восприятия, такие как распознавание объектов или анализ текста, требуя значительно меньше вычислительных ресурсов по сравнению с крупными моделями. SLMs, в свою очередь, функционируют как быстродействующие базы данных, обеспечивая быстрый доступ к извлеченной информации и позволяя системе динамически адаптироваться к изменяющимся условиям. Комбинация этих компонентов позволяет Interfaze эффективно обрабатывать сложные входные данные и оперативно извлекать необходимые знания из различных источников.
Слой построения контекста (Context Construction Layer) в архитектуре Interfaze функционирует как активный сборщик информации, осуществляя непрерывный обход (crawling) внешних источников данных. Этот процесс включает в себя индексацию полученной информации для обеспечения быстрого доступа и последующий синтаксический анализ (parsing) с целью извлечения релевантных фактов и связей. В результате формируется динамическая и актуальная база знаний, которая постоянно обновляется, обеспечивая систему наиболее свежей информацией для принятия решений и выполнения задач. Использование автоматизированного сбора и обработки данных позволяет Interfaze поддерживать контекстную осведомленность без непосредственного вмешательства человека.
Оркестровка Восприятия и Рассуждения с Interfaze
Слой действий (Action Layer), управляемый контроллером, представляет собой ключевой компонент системы, отвечающий за интеллектуальный выбор и последовательное применение цепочек инструментов (Tool Chains) для обработки запросов и доступа к информации. Контроллер анализирует входящие запросы и динамически формирует оптимальную последовательность инструментов, необходимых для их выполнения. Каждая цепочка инструментов состоит из специализированных модулей, предназначенных для решения конкретных задач, таких как извлечение данных, анализ изображений или преобразование речи в текст. Такой подход позволяет системе эффективно использовать ресурсы и адаптироваться к различным типам запросов, обеспечивая высокую производительность и точность обработки.
В состав Interfaze входят специализированные инструменты для извлечения и интеграции данных различных типов. Модели оптического распознавания символов (OCR) преобразуют изображения в текстовый формат. Модули парсинга диаграмм и графиков извлекают информацию из визуальных представлений данных. Системы автоматического распознавания речи (ASR) преобразуют аудиозаписи в текст. Системы извлечения информации (Retrieval Systems) осуществляют поиск и извлечение релевантных данных из различных источников, обеспечивая комплексный подход к обработке запросов.
Модульная архитектура Interfaze и эффективное использование ресурсов позволяют системе обрабатывать сложные задачи с повышенной скоростью и точностью по сравнению с традиционными методами. Разделение функциональности на независимые модули обеспечивает гибкость и масштабируемость, что сокращает время обработки запросов. Оптимизация потребления вычислительных ресурсов, включая использование параллельных вычислений и кэширования, минимизирует задержки и повышает общую производительность системы. В результате, Interfaze демонстрирует улучшенные показатели в задачах, требующих обработки большого объема данных и сложных алгоритмов анализа, по сравнению с монолитными архитектурами и менее оптимизированными решениями.
Тестирование Interfaze: Результаты в Различных Областях
В ходе сравнительного тестирования, Interfaze-Beta продемонстрировал передовые результаты по ряду бенчмарков. На тесте MMLU модель достигла точности 91.38%, что на 1.18% превышает показатели GPT-4.1. В бенчмарке MMLU-Pro Interfaze-Beta показал точность 83.6%. При оценке по тесту GPQA-Diamond, точность модели составила 81.31%, что на 15.01% выше, чем у GPT-4.1.
Эффективность Interfaze в обработке мультимодальных данных подтверждается результатами тестов на наборах данных ‘ChartQA’ и ‘Common Voice’. На ‘ChartQA’, предназначенном для анализа графиков и диаграмм, Interfaze достиг точности 90.88%. Тесты ‘Common Voice’, оценивающие распознавание речи, показали точность в 90.8%. Эти показатели демонстрируют способность модели эффективно интегрировать и анализировать информацию, поступающую из различных источников данных, включая визуальные и звуковые.
В ходе сравнительного тестирования Interfaze продемонстрировал значительные результаты на ряде бенчмарков. На бенчмарке AIME-2025 Interfaze достиг показателя 90.0, что на 55.3 пункта выше, чем у GPT-4.1. На бенчмарке AI2D Interfaze показал результат 91.51, превзойдя GPT-4.1 на 5.61 пункта. Кроме того, на бенчмарке MMMU Interfaze достиг точности 77.33, что на 2.53 пункта выше, чем у GPT-4.1, а на LiveCodeBench v5 — 57.77, опережая GPT-4.1 на 12.07 пункта.
Интерфейс включает в себя механизм “песочницы” (Sandboxing) для обеспечения безопасного выполнения операций. Данная технология изолирует процесс выполнения кода от основной системы, предотвращая несанкционированный доступ к ресурсам и ограничивая потенциальный ущерб от вредоносного или некорректного кода. Это достигается путем создания виртуализированной среды, в которой код выполняется с ограниченными привилегиями и доступом к системным ресурсам, что значительно повышает надежность и безопасность операций, выполняемых Интерфейсом.
Будущее Рассуждений: Масштабирование Контекста для Общего ИИ
Interfaze представляет собой заметный прогресс в создании искусственного интеллекта, способного эффективно рассуждать, бесшовно интегрировать знания и адаптироваться к сложным условиям. Эта архитектура отличается от традиционных подходов тем, что делает акцент на построении контекста, позволяя системе не просто обрабатывать данные, но и понимать их взаимосвязь. Вместо того чтобы полагаться на огромные массивы заранее запрограммированных правил, Interfaze динамически формирует представление о ситуации, используя специализированные модули для извлечения и обработки релевантной информации. Такой подход позволяет системе не только решать конкретные задачи, но и демонстрировать гибкость и способность к обучению в новых, непредсказуемых обстоятельствах, приближая искусственный интеллект к уровню человеческого мышления.
В отличие от традиционных подходов к искусственному интеллекту, которые часто сталкиваются с трудностями при обработке сложных и многогранных задач, система Interfaze делает акцент на построении контекста. Этот подход позволяет преодолеть ограничения, связанные с недостаточным пониманием взаимосвязей между различными элементами информации. Вместо того, чтобы полагаться на общие модели, Interfaze использует специализированные модули, каждый из которых отвечает за определенный аспект контекста. Такая модульная архитектура обеспечивает гибкость и масштабируемость, позволяя системе эффективно интегрировать знания из различных источников и адаптироваться к новым условиям. В результате, Interfaze демонстрирует улучшенные показатели в решении задач, требующих логического мышления и понимания сложных взаимосвязей, открывая новые перспективы для развития общего искусственного интеллекта.
Дальнейшие исследования направлены на расширение архитектуры Interfaze для решения задач возрастающей сложности, что позволит полностью раскрыть потенциал контекстно-ориентированного искусственного интеллекта. Увеличение масштаба системы предполагает не только обработку больших объемов информации, но и разработку более эффективных алгоритмов для динамического построения и управления контекстом. Предполагается, что такая масштабируемость приведет к существенным прорывам в области общего искусственного интеллекта, позволяя создавать системы, способные к более гибкому и адаптивному мышлению, приближая их к человеческим когнитивным способностям. В частности, ожидается улучшение способности к решению неоднозначных задач, эффективному планированию и креативному поиску решений в различных областях знаний.
Представленная архитектура Interfaze, с её упором на специализированные небольшие модели и инструменты для построения контекста, закономерно вызывает скепсис. Заявления о конкурентоспособности и даже превосходстве над огромными языковыми моделями звучат…наивно. История учит, что элегантная теория неизбежно упрется в стену реальности, когда в дело вмешается продакшен. Впрочем, подход к управлению контекстом, разбиение сложной задачи на более мелкие, решаемые модули — это, пожалуй, единственная разумная стратегия. Как метко заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не оказывали нежелательного влияния на другие». Иначе говоря, рано или поздно все эти «революционные» подходы превратятся в очередной техдолг, который придется расхлебывать.
Что дальше?
Архитектура, предложенная в данной работе, закономерно возвращает к идее специализированных компонентов. Иллюзия единой, всемогущей большой языковой модели постепенно рассеивается, уступая место прагматичному признанию необходимости в оркестровке множества небольших, отточенных инструментов. Не стоит, однако, обольщаться. Каждая новая «революция» — это лишь новый уровень технического долга, ожидающего своего часа. Продакшен найдёт способ сломать даже самую элегантную систему, выявив неочевидные граничные случаи и скрытые зависимости.
Основной вызов, по-видимому, заключается не в создании самих моделей, а в управлении сложностью их взаимодействия. Конструирование контекста, о котором идёт речь в статье, — это не просто склейка фрагментов информации, а тонкий процесс согласования противоречий и разрешения неоднозначностей. Вполне вероятно, что будущие исследования будут сосредоточены на разработке автоматизированных методов верификации и отладки таких систем. Воспоминания о лучших временах, когда можно было просто «попросить» модель сделать что-то полезное, постепенно уходят в прошлое.
И, конечно, не стоит забывать о фундаментальной проблеме: даже идеальная система, основанная на специализированных моделях, останется лишь приближением к истинному пониманию. Баги, в конце концов, — это всего лишь знак того, что система ещё жива, а значит, и учится. Мы не чиним продакшен — мы просто продлеваем его страдания.
Оригинал статьи: https://arxiv.org/pdf/2602.04101.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Визуальное мышление машин: проверка на прочность
- Генерация изображений: Новый взгляд на скорость и детализацию
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-05 16:35