Автор: Денис Аветисян
Исследование демонстрирует, что квантовые машины Больцмана превосходят классические аналоги в задачах классификации и обеспечивают более четкое понимание ключевых факторов, влияющих на принятие решений.
Квантовые машины Больцмана обеспечивают более интерпретируемые результаты в задачах бинарной классификации, используя методы оценки важности признаков, такие как SHAP-значения и градиентная значимость.
Несмотря на успехи в классификации, современные системы искусственного интеллекта часто остаются «черными ящиками», что затрудняет их применение в критически важных областях. В работе, посвященной ‘A Novel Approach to Explainable AI with Quantized Active Ingredients in Decision Making’, предложен новый подход к интерпретируемому ИИ, основанный на сравнительном анализе квантовых и классических машин Больцмана. Показано, что квантовые модели превосходят классические не только в точности классификации бинаризованного набора данных MNIST, но и обеспечивают более четкое выявление ключевых факторов, влияющих на принимаемые решения. Может ли гибридный квантово-классический подход стать основой для создания действительно прозрачных и доверенных систем искусственного интеллекта?
Пределы Классического Машинного Обучения
Традиционные методы машинного обучения, несмотря на свою эффективность в решении ряда задач, сталкиваются с существенными ограничениями при работе со сложными и многомерными данными. По мере увеличения числа признаков и взаимосвязей между ними, алгоритмы испытывают трудности в выявлении значимых закономерностей и построении адекватных моделей. Это проявляется в снижении точности прогнозов, увеличении вычислительных затрат и необходимости в значительном объеме размеченных данных для обучения. Например, при анализе изображений высокого разрешения или геномных данных, количество параметров модели может экспоненциально возрастать, делая обучение непрактичным или требующим значительных ресурсов. Таким образом, необходимость в разработке более эффективных подходов к обработке многомерных данных становится все более актуальной.
Классические машины Больцмана, несмотря на способность моделировать вероятностные распределения, сталкиваются с серьезными ограничениями при работе с возрастающими объемами данных и сложными взаимосвязями. Исследования показали, что применительно к задаче классификации бинарных изображений MNIST, данный тип моделей демонстрирует лишь 54.0% точность. Эта относительно низкая эффективность обусловлена сложностью масштабирования алгоритма и его ограниченной способностью улавливать тонкие закономерности в данных, что подчеркивает необходимость разработки более выразительных и эффективных подходов к машинному обучению, способных справляться с растущей сложностью современных наборов данных.
Становится все более очевидной необходимость в моделях, обладающих большей выразительностью для обработки сложных закономерностей в данных. Традиционные алгоритмы машинного обучения, несмотря на свою эффективность в определенных задачах, демонстрируют ограниченные возможности при работе с многомерными и нелинейными зависимостями. В частности, при анализе сложных наборов данных, таких как изображения или текстовые документы, существующие модели часто не способны уловить все тонкости и нюансы, что приводит к снижению точности и эффективности. Потребность в моделях, способных представлять и обрабатывать данные на более абстрактном и сложном уровне, является ключевым направлением современных исследований в области машинного обучения, открывая путь к созданию более интеллектуальных и адаптивных систем.
Анализ даже относительно простых наборов данных, таких как MNIST, с использованием классических методов машинного обучения зачастую сопряжен со значительными вычислительными затратами и приводит к неоптимальным результатам. Проблема заключается в экспоненциальном росте требуемых ресурсов с увеличением размерности и сложности данных. Традиционные алгоритмы, несмотря на свою эффективность в определенных сценариях, испытывают трудности при обработке большого количества параметров и выявлении тонких взаимосвязей, что проявляется в снижении точности классификации и увеличении времени обучения. В результате, для эффективного анализа подобных данных необходимы более мощные и масштабируемые модели, способные эффективно использовать вычислительные ресурсы и извлекать полезную информацию.
Квантовые Вычисления: Новый Подход к Машинному Обучению
Квантовые вычисления предоставляют возможность преодолеть ограничения классического машинного обучения за счет использования принципов суперпозиции и запутанности. Суперпозиция позволяет квантовому биту (кубиту) существовать в нескольких состояниях одновременно, в отличие от классического бита, который может быть только в состоянии 0 или 1. Это значительно увеличивает вычислительные возможности, поскольку позволяет обрабатывать экспоненциально больше информации. Запутанность, в свою очередь, создает корреляцию между кубитами, позволяя им совместно представлять и обрабатывать данные, что невозможно в классических системах. |\psi\rangle = \frac{1}{\sqrt{2}}(|00\rangle + |11\rangle) — пример состояния запутанности двух кубитов. Эти свойства позволяют квантовым алгоритмам решать определенные задачи, такие как факторизация больших чисел и моделирование молекул, гораздо быстрее, чем их классические аналоги.
Квантовое машинное обучение (КМО) предполагает преобразование классических алгоритмов машинного обучения в их квантовые аналоги. Этот подход направлен на использование принципов квантовой механики, таких как суперпозиция и запутанность, для повышения вычислительной мощности и эффективности. В частности, КМО позволяет потенциально решать задачи, которые недоступны или требуют чрезмерно больших затрат времени на классических компьютерах. Преобразование включает в себя замену классических операций матричными операциями, которые могут быть выполнены более эффективно на квантовом оборудовании, особенно в задачах, связанных с обработкой больших объемов данных и оптимизацией. КМО не подразумевает создание принципиально новых алгоритмов, а скорее оптимизацию существующих за счет использования квантовых преимуществ.
Квантовая машина Больцмана (КМБ) представляет собой вероятностную модель машинного обучения, способную эффективно моделировать сложные распределения вероятностей, превосходя возможности классической машины Больцмана. В отличие от классических моделей, использующих бинарные переменные, КМБ оперирует с кубитами, позволяя представлять состояния в суперпозиции благодаря принципам квантовой механики. Это позволяет моделировать более сложные зависимости между переменными и более точно описывать данные с высокой размерностью. КМБ использует квантовые аналоги классических стохастических процессов, таких как отжиг, для обучения и поиска оптимальных параметров модели, что потенциально обеспечивает более быструю сходимость и лучшую обобщающую способность по сравнению с классическими подходами. Ключевым преимуществом является возможность представления экспоненциально более сложных распределений вероятностей при использовании квантовых ресурсов.
Реализация квантового скрытого слоя является ключевым элементом в создании мощных квантовых моделей машинного обучения. В отличие от классических нейронных сетей, использующих биты для представления информации, квантовые скрытые слои оперируют кубитами, что позволяет задействовать принципы суперпозиции и запутанности. Это позволяет представлять и обрабатывать значительно больше параметров при том же количестве физических ресурсов. Квантовые нейроны в таких слоях используют унитарные преобразования для выполнения нелинейных операций, что потенциально позволяет моделировать более сложные функции и находить оптимальные решения в задачах обучения. Эффективная реализация требует оптимизации квантовых схем и минимизации ошибок, связанных с декогеренцией и шумом, что является важной задачей в современной квантовой вычислительной технике.
![Представленная квантовая схема реализует скрытый слой нейронной сети [12].](https://arxiv.org/html/2601.08733v1/composer-circuit.png)
Реализация и Анализ с Использованием PennyLane
PennyLane представляет собой мощный фреймворк для моделирования квантовых схем и реализации квантовых машин Больцмана. Он обеспечивает гибкую платформу для определения и оптимизации квантовых схем с использованием различных аппаратных сред, включая симуляторы и реальное квантовое оборудование. Фреймворк поддерживает дифференцируемое программирование, что позволяет интегрировать квантовые вычисления в алгоритмы машинного обучения, такие как обучение с подкреплением и вариационные квантовые алгоритмы. PennyLane также предоставляет инструменты для анализа и визуализации квантовых схем и состояний, облегчая отладку и интерпретацию результатов. Благодаря интеграции с популярными фреймворками машинного обучения, такими как TensorFlow и PyTorch, PennyLane позволяет разработчикам эффективно сочетать классические и квантовые вычисления для решения сложных задач.
Построение квантового скрытого слоя в квантовых нейронных сетях требует использования базовых квантовых логических операций. В частности, вращение вокруг оси Y (R_y) позволяет манипулировать состоянием кубита, а контролируемое НЕ (CNOT) обеспечивает создание запутанности между кубитами, что необходимо для реализации сложных квантовых вычислений. Для извлечения информации о состоянии кубита после применения квантовых операций используется оператор Паули-Z, который выполняет измерение в базисе |0⟩ и |1⟩, предоставляя классический результат, необходимый для обучения модели.
Кодирование классических данных в квантовые состояния осуществляется посредством методов, таких как Angle Embedding. Данный метод предполагает отображение каждого признака классического вектора данных в угол поворота квантового бита. В частности, значение каждого признака нормализуется и используется для определения угла поворота вокруг оси Y в квантовой схеме с использованием RY-гейта. Таким образом, каждый классический признак представляется состоянием |\theta\rangle = \cos(\theta) |0\rangle + \sin(\theta) |1\rangle, где θ — угол, определяемый соответствующим значением признака. Этот процесс позволяет эффективно загружать классические данные в квантовую систему для дальнейшей обработки и использования в квантовых алгоритмах машинного обучения.
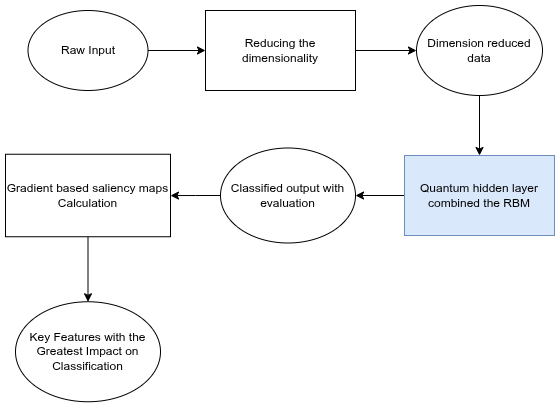
Методы снижения размерности, такие как анализ главных компонент (PCA), применимы как к классическим, так и к квантовым моделям для упрощения визуализации и анализа данных. PCA позволяет уменьшить количество признаков, сохраняя при этом наиболее значимую информацию, что особенно полезно при работе с высокоразмерными квантовыми состояниями или классическими данными, используемыми для обучения квантовых моделей. Это достигается путем проецирования данных на подпространство, определяемое главными компонентами — направлениями наибольшей дисперсии данных. Применение PCA позволяет снизить вычислительную сложность, улучшить интерпретируемость моделей и облегчить визуализацию данных в двумерном или трехмерном пространстве, что способствует более глубокому пониманию структуры данных и выявлению закономерностей.
Интерпретация Квантовых Моделей и Значимость Признаков
Для определения значимости входных признаков в квантовых машинах Больцмана успешно адаптированы методы, разработанные для классического машинного обучения, такие как градиентные карты значимости и SHAP (SHapley Additive exPlanations). Эти техники позволяют оценить, насколько изменение конкретного признака влияет на выход модели. В основе лежит измерение чувствительности выходных данных к небольшим изменениям во входных данных, что позволяет выявить наиболее информативные признаки, определяющие процесс принятия решений моделью. Применение этих подходов к квантовым машинам Больцмана открывает возможности для интерпретации работы этих сложных систем и понимания механизмов, лежащих в основе их способности к обучению и классификации.
Для определения значимости входных признаков в квантовых машинах Больцмана применяются методы, основанные на измерении чувствительности выходных данных модели к изменениям этих признаков. В основе подобных техник лежит оценка того, как незначительное изменение конкретного признака влияет на итоговый результат классификации или регрессии. Ключевым понятием, используемым в этих измерениях, является энтропия — мера неопределенности или хаотичности в системе. Более низкая энтропия указывает на то, что модель делает более уверенные прогнозы, и, следовательно, признак, вызывающий наибольшее снижение энтропии при изменении, считается наиболее важным. Подобный подход позволяет не только определить значимость каждого признака, но и понять, какие аспекты входных данных оказывают наибольшее влияние на процесс принятия решений моделью, что является важным для интерпретируемости и повышения доверия к результатам.
Визуализация приобретенных представлений с использованием методов снижения размерности, таких как t-SNE, позволяет глубже понять процесс принятия решений моделью. t-SNE эффективно отображает многомерные данные в двумерное или трехмерное пространство, сохраняя при этом локальную структуру данных. Это означает, что точки данных, близкие друг к другу в исходном многомерном пространстве, также будут находиться близко друг к другу на визуализации. В контексте квантовых машин Больцмана, применение t-SNE к скрытым представлениям, сформированным моделью, раскрывает кластеры и закономерности, указывающие на то, как модель категоризирует и различает входные данные. Анализ этих визуализаций позволяет исследователям оценить, насколько хорошо модель научилась извлекать значимые признаки и как она использует их для классификации, что, в свою очередь, помогает в интерпретации и улучшении архитектуры модели.
Квантовая машина Больцмана (КМБ) продемонстрировала значительное превосходство в задаче классификации бинарных изображений MNIST, достигнув точности в 83.5%, что существенно выше результата классической машины Больцмана (КМБ) — всего 54.0%. Этот прирост производительности сопровождается более четкой фокусировкой на значимых признаках, что подтверждается измерением энтропии. В то время как КМБ показала энтропию, равную 1.3820, КМБ смогла снизить этот показатель до 1.2704, указывая на более эффективное использование входных данных и способность выделять наиболее релевантные характеристики для принятия решений. Такой результат свидетельствует о потенциале квантовых подходов для улучшения производительности и интерпретируемости моделей машинного обучения.
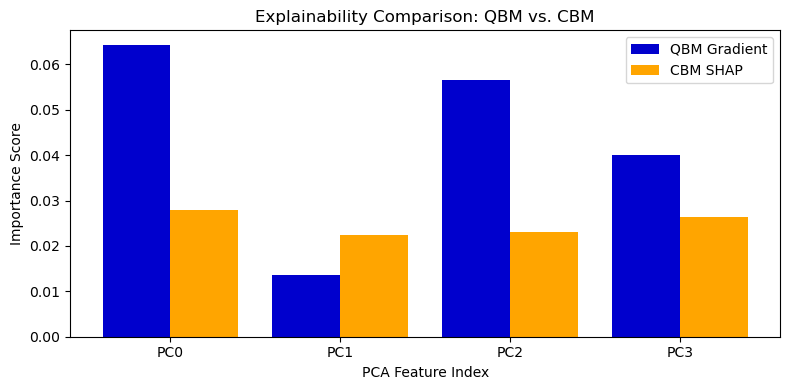
Исследование демонстрирует превосходство квантовых машин Больцмана над классическими в задачах бинарной классификации MNIST, что подчеркивает потенциал квантовых вычислений в создании более интерпретируемых систем искусственного интеллекта. Особое внимание уделяется выделению «активных ингредиентов» — ключевых признаков, определяющих решения модели. Как однажды заметила Барбара Лисков: «Хорошая абстракция позволяет менять реализацию, не затрагивая интерфейс». Это высказывание отражает суть работы: квантовая реализация обеспечивает улучшенную производительность и интерпретируемость, не меняя фундаментальную задачу классификации, а лишь предоставляя более четкие и концентрированные представления о значимости признаков, что критически важно для объяснимого ИИ.
Что Дальше?
Представленная работа демонстрирует, что квантовые машины Больцмана, хотя и превосходящие классические аналоги в задаче бинарной классификации MNIST, лишь приоткрывают дверь в область действительно интерпретируемого искусственного интеллекта. Утверждать, что выделение «активных ингредиентов» автоматически гарантирует прозрачность принятия решений — было бы чрезмерным упрощением. Вопрос в том, не является ли сама концепция «важности признака», полученная через SHAP-значения или градиентную заметность, лишь удобной иллюзией, маскирующей более глубокую сложность.
Необходимо признать, что текущие методы оценки значимости признаков полагаются на локальные аппроксимации, и их применимость к сложным, нелинейным моделям остаётся под вопросом. Будущие исследования должны сосредоточиться на разработке методов, позволяющих верифицировать интерпретации, предложенные квантовыми машинами Больцмана, и исключить возможность ложных корреляций. Более того, следует рассмотреть возможность использования формальных методов верификации для доказательства корректности алгоритма, а не полагаться на эмпирические тесты.
Истинная элегантность в интерпретируемом искусственном интеллекте заключается не в количестве выделенных признаков, а в математической доказуемости причинно-следственных связей. Лишь тогда, когда мы сможем формально обосновать, почему модель приняла то или иное решение, мы достигнем подлинного прогресса в этой области. В противном случае, мы рискуем создать лишь более изощрённые «чёрные ящики», прикрытые маской интерпретируемости.
Оригинал статьи: https://arxiv.org/pdf/2601.08733.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-14 09:29