Автор: Денис Аветисян
Новое исследование показывает, что восприятие врачами возможностей больших языковых моделей играет ключевую роль в эффективности совместной работы и принятии клинических решений.
Оценка доверия к системам искусственного интеллекта, поддерживающим клиническое мышление, выходит за рамки простого анализа точности диагностики и включает в себя логическую связность и клиническую обоснованность.
Несмотря на впечатляющий потенциал больших языковых моделей (LLM) в поддержке медицинской диагностики, их эффективное внедрение затруднено недостаточным доверием врачей к их возможностям. В работе ‘»Do I Trust the AI?» Towards Trustworthy AI-Assisted Diagnosis: Understanding User Perception in LLM-Supported Reasoning’ исследованы представления медиков о способностях LLM в процессе клинического мышления. Полученные данные свидетельствуют о том, что оценка врачами возможностей LLM определяется не только точностью диагноза, но и такими аспектами, как логическая связность и клиническая обоснованность рассуждений. Как можно оптимизировать взаимодействие между врачом и LLM для построения действительно надежной и эффективной системы поддержки принятия решений в медицине?
Истинное клиническое мышление: за пределами сопоставления шаблонов
Несмотря на впечатляющую способность больших языковых моделей (LLM) обрабатывать огромные объемы медицинской информации, истинное клиническое мышление выходит за рамки простого сопоставления шаблонов. LLM способны выявлять корреляции и ассоциации в данных, однако диагностика требует формирования последовательной и обоснованной линии расследования, учитывающей индивидуальные особенности пациента и контекст заболевания. Простое распознавание закономерностей, даже если оно высокоточно, не гарантирует понимания лежащих в основе патологических механизмов и не позволяет сформулировать дифференциальный диагноз, основанный на глубоком анализе клинической картины. Таким образом, LLM, хотя и являются мощным инструментом для обработки данных, нуждаются в дополнительных механизмах для эмуляции сложного когнитивного процесса, присущего квалифицированному врачу.
Эффективная диагностика в медицине предполагает не просто выявление закономерностей, но и построение последовательной, логически обоснованной линии расследования, позволяющей врачу прийти к конкретному заключению и объяснить его причины. В отличие от этого, современные большие языковые модели (LLM) демонстрируют впечатляющую способность к сопоставлению данных и выявлению корреляций, однако им не присуща внутренняя потребность в аргументированном, прозрачном процессе рассуждений. Архитектура LLM, ориентированная на статистическую вероятность, не обеспечивает автоматическое формирование когерентной логической цепочки, необходимой для дифференциальной диагностики и принятия обоснованных клинических решений. Поэтому, несмотря на потенциал LLM в обработке медицинских данных, их применение требует разработки методов, обеспечивающих проверяемость и понятность процесса рассуждений, чтобы гарантировать безопасность пациентов и доверие к результатам.
Отсутствие тщательной оценки способностей больших языковых моделей (LLM) к клиническому мышлению представляет серьезную угрозу безопасности пациентов и доверию к медицинской практике. Непрозрачность логических цепочек, используемых этими моделями для постановки диагноза, затрудняет выявление ошибок и предвзятостей. Если алгоритм приходит к неверному заключению, причины этого могут оставаться скрытыми, что лишает врачей возможности проверить и исправить ошибку. Риск не только в неверном диагнозе, но и в том, что модель может упустить важные факторы или предложить неадекватное лечение, не имея возможности объяснить свою логику. Поэтому критически важно разработать строгие методы оценки, которые позволят выявить слабые места и обеспечить надежность LLM перед их внедрением в клиническую практику.

Строгая оценка диагностической точности: основа надежности
Оценка производительности больших языковых моделей (LLM) в медицинской сфере традиционно начинается с использования стандартных наборов данных для формирования базового уровня. Эти наборы данных, как правило, содержат заранее размеченные клинические случаи и позволяют количественно оценить способность модели к решению задач, таких как диагностика или прогнозирование. Хотя такие тесты и обеспечивают объективную метрику, важно понимать, что они служат отправной точкой для оценки и не отражают в полной мере сложность и многогранность реальных клинических ситуаций. Использование стандартных бенчмарков позволяет сравнивать различные LLM между собой и отслеживать прогресс в развитии медицинских моделей искусственного интеллекта.
Традиционные оценочные тесты, несмотря на свою полезность в качестве базового уровня для оценки производительности больших языковых моделей (LLM) в медицине, зачастую не способны адекватно отразить сложность и многогранность реальных клинических ситуаций. Это связано с упрощенным характером данных, используемых в этих тестах, и отсутствием учета контекстуальных факторов, характерных для практической медицины. Для получения более точной и надежной оценки необходимо внедрение более сложных методов тестирования, включающих моделирование реальных клинических сценариев, использование разнообразных типов данных (например, медицинские изображения, текстовые заключения, результаты лабораторных исследований) и учет субъективных факторов, таких как опыт и квалификация врача.
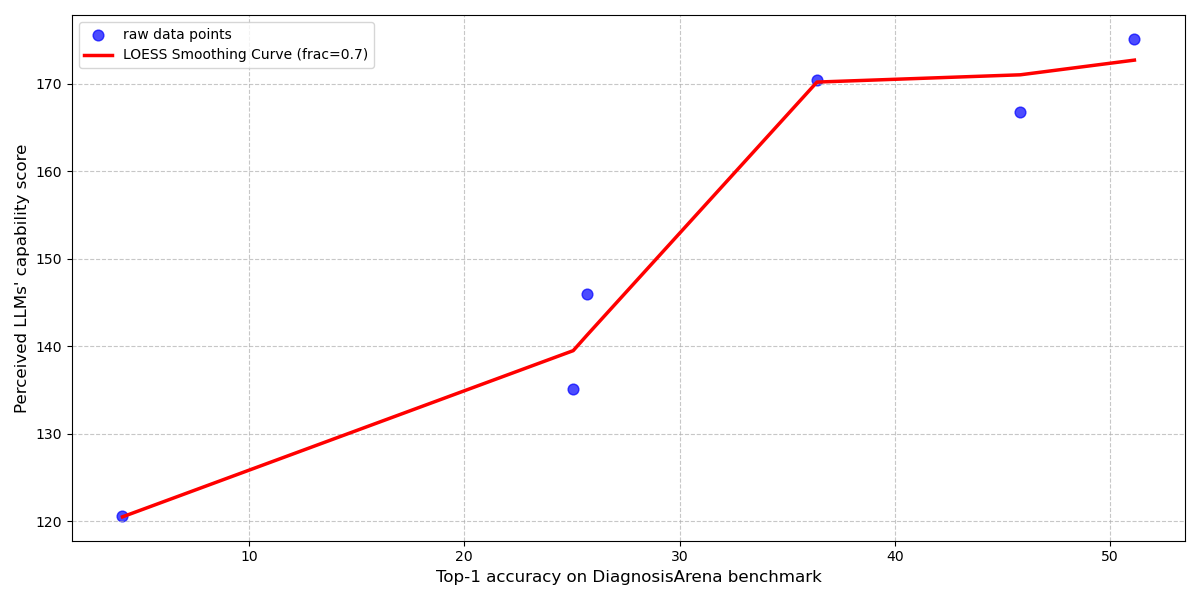
Эффективность клинического рассуждения, реализованного в больших языковых моделях (LLMClinicalReasoning), напрямую связана с достигаемой диагностической точностью (DiagnosticAccuracy). Анализ данных демонстрирует высокую корреляцию между результатами оценки LLM на стандартных бенчмарках и восприятием компетентности модели врачами-специалистами, которая составляет 0.97 (R-квадрат, полученный методом LOESS-сглаживания). Данный факт подчеркивает необходимость количественной оценки взаимосвязи между показателями производительности LLM на тестовых наборах данных и субъективной оценкой врачей, что является важным фактором при внедрении подобных систем в клиническую практику.

Интеграция LLM в клиническую практику: расширение возможностей врача
Успешная интеграция больших языковых моделей (LLM) в клиническую практику является ключевым фактором их принятия. Для этого необходимо, чтобы LLM дополняли существующие рабочие процессы, а не нарушали их. Внедрение LLM должно быть направлено на повышение эффективности работы врачей, автоматизируя рутинные задачи, такие как сбор анамнеза или предварительный анализ данных, и предоставляя информацию, которая помогает в принятии клинических решений. Вместо полной замены существующих процедур, LLM должны рассматриваться как инструменты, расширяющие возможности врачей и позволяющие им уделять больше времени пациентам и сложным случаям. Попытки кардинально изменить устоявшиеся практики часто приводят к сопротивлению со стороны медицинского персонала и снижению эффективности внедрения.
Эффективное взаимодействие врача и большой языковой модели (LLM) в процессе диагностики позволяет реализовать весь потенциал искусственного интеллекта в клинической практике. Синергия между врачом и LLM достигается за счет совместного анализа данных, где LLM предоставляет дополнительные сведения и выявляет закономерности, которые могут быть упущены врачом, а врач, в свою очередь, интерпретирует эти данные в контексте клинической картины и опыта. Такой подход позволяет повысить точность диагностики, сократить время постановки диагноза и оптимизировать процесс принятия решений. Важно подчеркнуть, что LLM не заменяет врача, а выступает в качестве инструмента поддержки принятия решений, расширяя возможности специалиста.
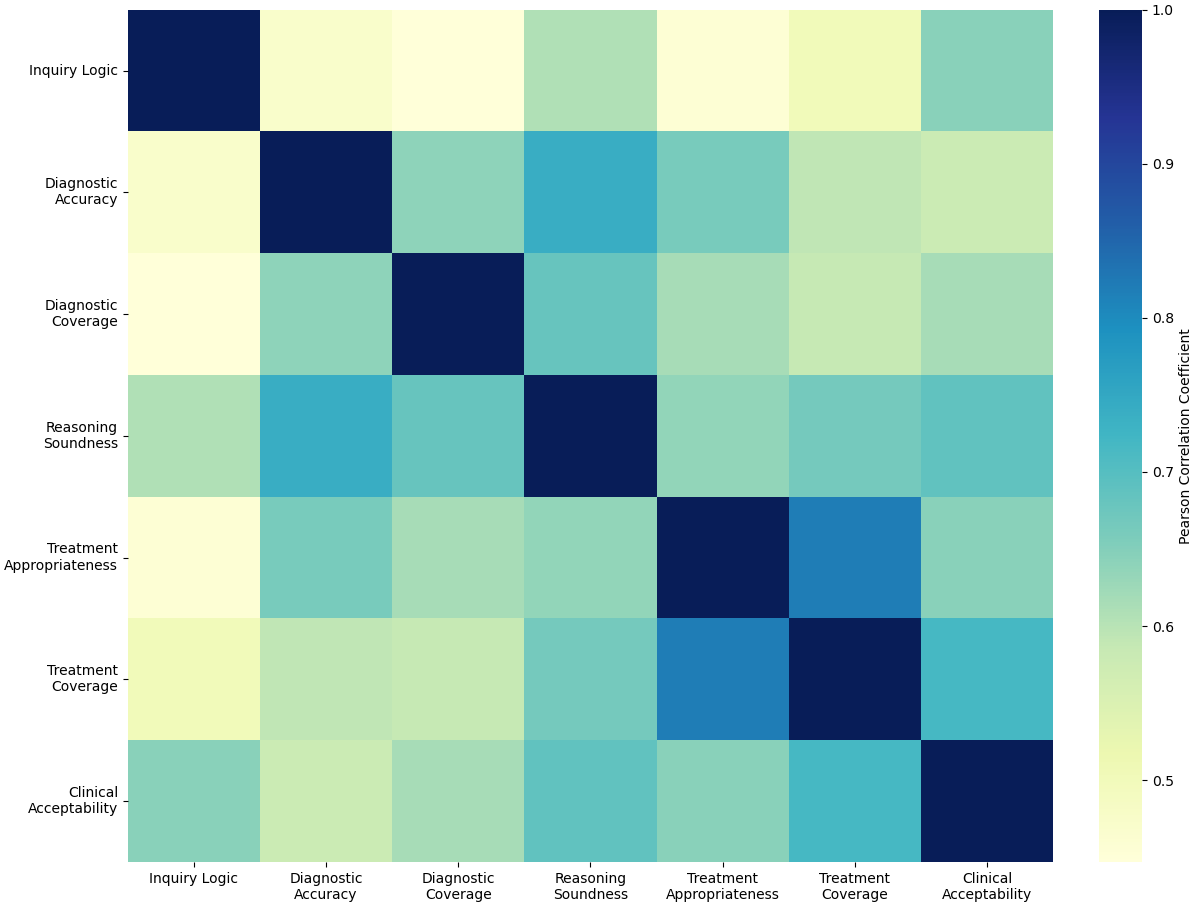
Ключевым аспектом эффективного взаимодействия между врачом и большой языковой моделью (LLM) является калибровка доверия, обеспечивающая адекватную оценку врачом информации, предоставляемой LLM, в соответствии с ее возможностями. Исследования показывают, что степень согласованности оценок врачей при анализе результатов, полученных с помощью LLM, варьируется от 0.39 до 0.67. Данный диапазон указывает на умеренный — высокий уровень согласованности в оценке качества анализа, что подчеркивает важность разработки механизмов, позволяющих врачам правильно интерпретировать и использовать информацию, предоставляемую LLM, для принятия клинических решений.
Восприятие врача и доверие: фундамент принятия LLM
Восприятие врачом возможностей и надежности систем диагностики на основе больших языковых моделей (LLM) является определяющим фактором для их успешного внедрения в клиническую практику. Недостаточно просто создать технически совершенный инструмент; необходимо, чтобы медицинский специалист доверял его результатам и был готов использовать их в своей работе. Оценка врачом не ограничивается лишь точностью диагностики, но включает в себя и другие аспекты, такие как логическая последовательность рассуждений модели и соответствие её выводов общепринятым клиническим стандартам. В итоге, позитивное восприятие врачом напрямую влияет на готовность к принятию и эффективному использованию LLM-систем, что, в свою очередь, способствует повышению качества и скорости постановки диагноза.
Восприятие возможностей искусственного интеллекта в медицине часто поддается количественной оценке посредством Показателя Воспринимаемой Способности (PerceivedCapabilityScore). Этот показатель служит измерителем уверенности врачей в работе новых диагностических инструментов, основанных на больших языковых моделях. Он позволяет оценить, насколько клиницисты доверяют выводам системы, не только с точки зрения точности диагноза, но и с учетом логической связности и клинической приемлемости предложенных решений. Получение и анализ этого показателя критически важно для понимания того, как врачи взаимодействуют с ИИ, и для выявления факторов, влияющих на их доверие и готовность к принятию новых технологий в клинической практике.
Высокий показатель воспринимаемой компетентности, или PerceivedCapabilityScore, напрямую способствует калибровке доверия к системам искусственного интеллекта в медицине, формируя положительную обратную связь. Исследования показывают, что оценка врачей выходит за рамки простой диагностической точности, охватывая такие аспекты, как логическая последовательность рассуждений и клиническая приемлемость предложенных решений. Наблюдаемые значительные эффекты в модели CLMM подтверждают, что многомерный характер этой оценки оказывает существенное влияние на уверенность клиницистов и, как следствие, на надежность диагностических заключений, что подчеркивает важность разработки систем, которые не только выдают верные ответы, но и демонстрируют понятную и обоснованную логику.
Исследование показывает, что восприятие возможностей больших языковых моделей в клиническом мышлении выходит за рамки простой диагностической точности. Важно учитывать такие аспекты, как логическая связность и клиническая обоснованность рассуждений. В этом контексте особенно примечательна фраза Винтона Серфа: «Интернет — это всего лишь машина, а машины могут делать ошибки». Эта мысль перекликается с необходимостью калибровки доверия к ИИ в медицине. Ведь даже самые продвинутые системы нуждаются в критической оценке со стороны специалистов, поскольку упрощение процессов, неизбежное при использовании ИИ, всегда сопряжено с определенными рисками, а структура системы определяет ее поведение.
Куда Дальше?
Представленная работа, исследуя восприятие врачами возможностей больших языковых моделей в клиническом мышлении, обнажает закономерную сложность. Очевидно, что простое соответствие диагнозов — недостаточный критерий для формирования доверия. Гораздо важнее, как модель выстраивает логическую цепочку рассуждений, насколько предложенные решения укладываются в клиническую практику. Это напоминает о необходимости смены фокуса: оценивать не только что модель выдает, но и как она к этому пришла. Иначе рискуем получить инструмент, формально точный, но практически бесполезный.
Остается открытым вопрос о калибровке доверия. Как научить врача адекватно оценивать возможности модели, видеть ее сильные и слабые стороны, избегать как слепого принятия, так и необоснованного недоверия? Эта задача требует не только совершенствования самих моделей, но и разработки новых методов обучения и взаимодействия, учитывающих когнитивные особенности человека. Простая демонстрация «успешных» случаев — не решение, а лишь иллюзия понимания.
В конечном итоге, ключ к успешной коллаборации человека и искусственного интеллекта лежит не в создании всезнающего алгоритма, а в построении системы, где каждый участник дополняет другого. Иначе, неизбежно, сложность системы приведет к неожиданным последствиям — эффект домино, когда ошибка в одном звене приводит к краху всей конструкции. И тогда, все наши усилия по повышению точности диагнозов окажутся тщетными.
Оригинал статьи: https://arxiv.org/pdf/2601.19540.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые сети для моделирования молекул: новый подход
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
2026-01-29 06:32