Автор: Денис Аветисян
Исследователи представили комплексный инструмент для оценки возможностей ИИ-агентов в решении реальных задач программирования и автоматизации рутинных операций.
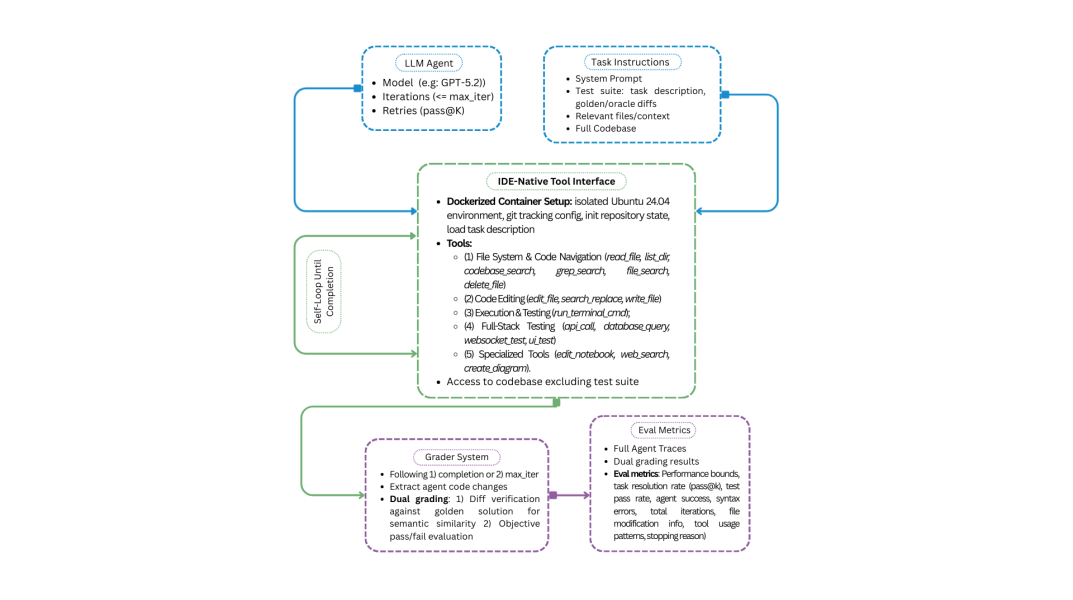
В статье представлен IDE-Bench, эталонный набор тестов для оценки ИИ-агентов, способных использовать инструменты и генерировать код в процессе разработки программного обеспечения.
Существующие бенчмарки для оценки возможностей больших языковых моделей в разработке программного обеспечения часто не учитывают реальную сложность инструментов и сред разработки. В работе ‘IDE-Bench: Evaluating Large Language Models as IDE Agents on Real-World Software Engineering Tasks’ представлен комплексный фреймворк IDE-Bench, предназначенный для всесторонней оценки AI-агентов, функционирующих непосредственно в интегрированной среде разработки, на задачах, имитирующих повседневную деятельность разработчиков. Предложенный бенчмарк, включающий 80 задач в C/C++, Java и MERN стеках, впервые позволяет систематически сопоставить заявленные намерения агента с успешными изменениями в проекте, используя неиспользованные ранее репозитории. Какие новые горизонты откроет более точная оценка возможностей AI-агентов в сфере разработки программного обеспечения и автоматизации инженерных задач?
Иллюзия прогресса: Зачем нужны реалистичные тесты для AI-разработчиков?
Существующие эталоны для генерации кода зачастую не отражают сложности реальных программных задач, что существенно замедляет развитие по-настоящему компетентных AI-ассистентов для разработки. Большинство бенчмарков сосредоточены на решении изолированных, небольших фрагментов кода, не требующих глубокого понимания архитектуры проекта, взаимодействия с существующими библиотеками или учета долгосрочных последствий изменений. В результате, модели, успешно справляющиеся с этими упрощенными тестами, оказываются неспособными эффективно функционировать в реальных сценариях, где требуется поддержание, рефакторинг и расширение больших, сложных кодовых баз. Это создает иллюзию прогресса, поскольку показатели производительности на бенчмарках растут, а способность AI решать практические задачи разработки остается ограниченной. Необходимы новые эталоны, моделирующие реальные проекты с их сложностью, неоднозначностью и требованиями к масштабируемости, чтобы действительно оценить и стимулировать развитие AI-ассистентов, способных полноценно участвовать в процессе разработки программного обеспечения.
Современные методы разработки программного обеспечения испытывают трудности при решении задач, требующих длительной последовательности рассуждений и сложного взаимодействия с существующей кодовой базой. Это связано с тем, что большинство подходов фокусируются на локальных улучшениях или решении небольших, изолированных проблем. В реальности, разработка часто предполагает понимание взаимосвязей между различными частями проекта, отслеживание долгосрочных последствий изменений и адаптацию к постоянно меняющимся требованиям. Неспособность эффективно справляться с этими задачами ограничивает возможности автоматизации и требует значительных усилий со стороны разработчиков, особенно при работе с крупными и сложными проектами. Для преодоления этих ограничений необходимы новые подходы, способные к планированию на длительный горизонт и глубокому пониманию контекста кодовой базы.
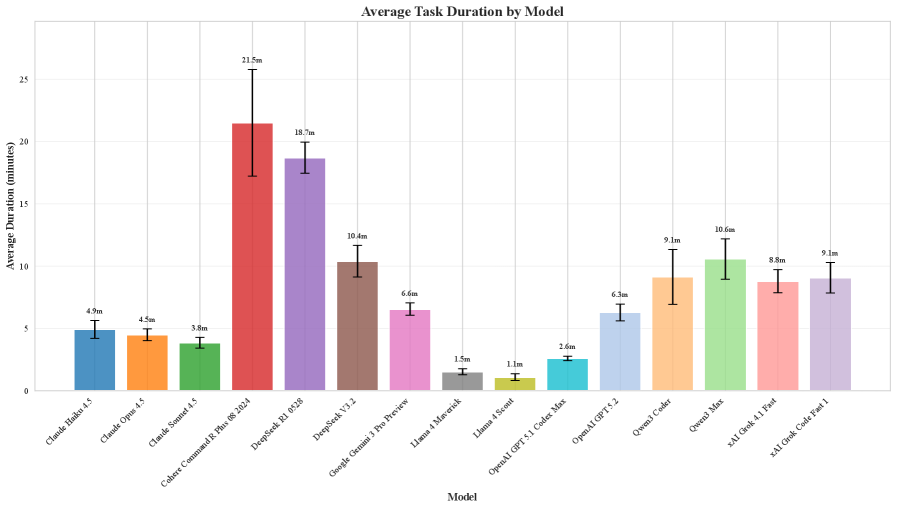
IDE-Bench: Комплексная оценка AI в реальных условиях разработки
IDE-Bench представляет собой комплексную платформу для оценки AI-агентов, функционирующих в роли IDE, на задачах, приближенных к реальным сценариям разработки программного обеспечения. В отличие от существующих бенчмарков, IDE-Bench охватывает весь цикл разработки — от фронтенда до бэкенда — и требует от агентов способности к долгосрочному планированию и рассуждению (long-horizon reasoning) при решении сложных задач. Бенчмарк предназначен для оценки не только способности генерировать код, но и умения агентов выполнять полные задачи, требующие последовательного применения различных навыков и инструментов в течение длительного времени.
Методология IDE-Bench оценивает способности ИИ-агентов не только в базовом завершении кода, но и в более сложных задачах, характерных для реальной разработки программного обеспечения. Оценка включает в себя анализ умения агентов выявлять и устранять ошибки в коде (отладка), реализовывать новые функциональные возможности (разработка фич) и улучшать существующий код без изменения его функциональности (рефакторинг). Такой подход позволяет получить более полную картину возможностей агента в контексте полноценного жизненного цикла разработки, выходя за рамки простой генерации фрагментов кода.
IDE-Bench уделяет особое внимание оценке возможностей агентов по вызову внешних инструментов, позволяя им расширять свои навыки кодирования. В рамках бенчмарка оценивается способность агентов эффективно использовать инструменты, такие как отладчики, линтеры, системы контроля версий и другие, для решения сложных задач разработки программного обеспечения. Это включает в себя не только успешный вызов инструментов, но и корректную интерпретацию их результатов и интеграцию в рабочий процесс. Оценка проводится на задачах, требующих комбинированного использования различных инструментов для достижения конечной цели, что позволяет комплексно оценить способность агента к автоматизации процесса разработки.
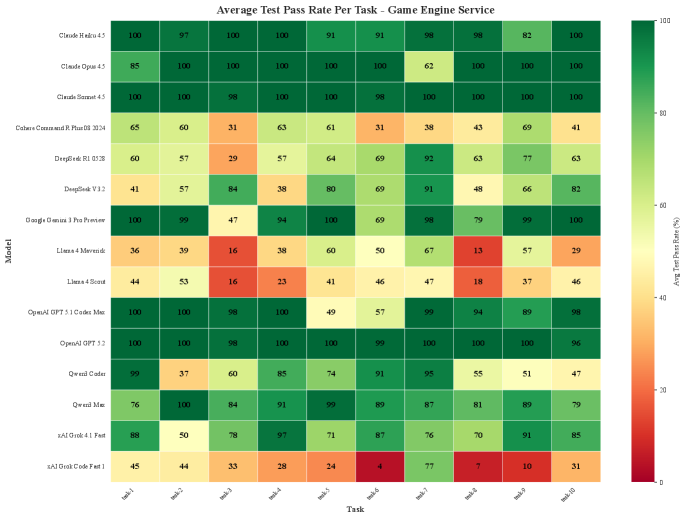
Ключевые возможности автономных AI IDE: Навигация в хаосе кода
Эффективные автономные агенты требуют глубокого понимания контекста кодовой базы для навигации по сложным проектам и принятия обоснованных решений при кодировании. Это включает в себя способность анализировать структуру проекта, зависимости между модулями, семантику кода и историю изменений. Понимание контекста позволяет агенту точно определять местоположение релевантных фрагментов кода, избегать конфликтов при внесении изменений и генерировать код, соответствующий существующему стилю и архитектуре проекта. Отсутствие контекстуального понимания приводит к неэффективному поиску, ошибкам при модификации кода и снижению общей производительности агента. Для реализации такого понимания используются методы статического анализа кода, построения графов зависимостей и анализа семантики.
Эффективный поиск по кодовой базе является критически важным для ускорения рабочих процессов разработки. Современные автономные агенты ИИ используют различные методы, включая индексацию кода и семантический поиск, для быстрого обнаружения релевантных фрагментов кода и зависимостей. Это позволяет агентам оперативно находить определения функций, примеры использования API и взаимосвязи между модулями, значительно сокращая время, затрачиваемое на ручной анализ и навигацию по проекту. Скорость и точность поиска напрямую влияют на способность агента решать задачи, такие как рефакторинг, отладка и добавление новых функций, обеспечивая повышенную производительность и сокращение затрат на разработку.
Возможность осуществления API-вызовов является критически важной для создания современных, взаимосвязанных приложений, особенно при использовании технологий, таких как MERN Stack. В рамках MERN (MongoDB, Express.js, React, Node.js) агенты, способные взаимодействовать с внешними сервисами через API, позволяют интегрировать функциональность, выходящую за рамки базового стека. Это включает в себя, например, доступ к базам данных, сервисам аутентификации, платежным системам или другим сторонним API. Автоматизация API-вызовов позволяет агентам динамически получать и обрабатывать данные, расширяя возможности приложения и обеспечивая интеграцию с широким спектром внешних ресурсов, что значительно повышает гибкость и масштабируемость разрабатываемых решений.
Успешная работа автономных AI-агентов напрямую зависит от чётко сформулированной системной подсказки (System Prompt). Эта подсказка служит основой для определения поведения агента, устанавливает границы его действий и задаёт желаемый формат выходных данных. Хорошо разработанная системная подсказка позволяет агенту последовательно и предсказуемо выполнять задачи, избегая нежелательных или некорректных результатов. Она определяет роль агента, стиль общения, требования к формату кода и любые специфические инструкции, необходимые для достижения поставленной цели, обеспечивая стабильность и надёжность его работы в различных сценариях.
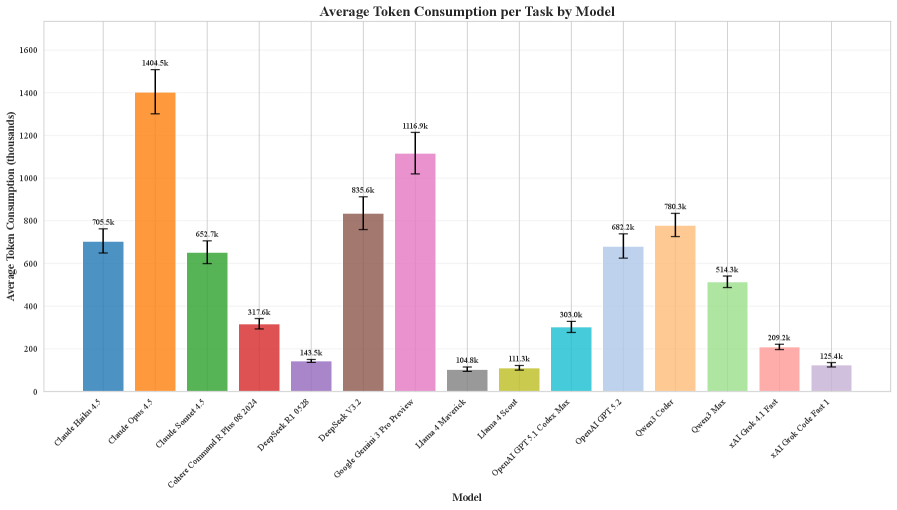
Проверка IDE-Bench с помощью передовых языковых моделей: Результаты говорят сами за себя
В качестве основы для оценки производительности AI IDE агентов, IDE-Bench использует современные большие языковые модели, такие как GPT-5.2 и Claude Sonnet. Эти модели позволяют проводить тестирование на широком спектре задач, имитирующих реальные сценарии разработки программного обеспечения. Использование мощных языковых моделей необходимо для обеспечения достоверной и репрезентативной оценки, поскольку они способны генерировать и анализировать код, а также понимать сложные инструкции и требования к задачам. Разнообразие задач, используемых в IDE-Bench, охватывает различные аспекты разработки, включая написание кода, отладку, рефакторинг и тестирование, что позволяет комплексно оценить возможности AI IDE агентов.
В состав IDE-Bench входит функциональность редактирования файлов, позволяющая агентам непосредственно изменять код в среде IDE. Это обеспечивает оценку не только способности агента генерировать код, но и его умения вносить изменения, исправлять ошибки и рефакторить существующий код. Агенты получают доступ к файловой системе, что позволяет им читать, изменять и сохранять файлы в рамках заданных задач. Такой подход позволяет более реалистично оценить навыки агентов в контексте реальной разработки программного обеспечения и выявить их способность эффективно работать с существующей кодовой базой.
Принцип Test-Driven Development (TDD) является ключевым элементом IDE-Bench, гарантируя создание агентами высококачественного и надежного кода, соответствующего заданным требованиям. В рамках TDD, перед написанием кода, создаются автоматизированные тесты, определяющие ожидаемое поведение. Агенты разрабатывают код исключительно для успешного прохождения этих тестов, что обеспечивает соответствие кода спецификациям и минимизирует количество ошибок. В IDE-Bench, тесты автоматически запускаются после каждой модификации кода, предоставляя немедленную обратную связь и позволяя агентам итеративно улучшать свои решения. Такой подход позволяет объективно оценивать качество кода и надежность агентов, а также способствует созданию более стабильных и предсказуемых программных систем.
Согласно результатам тестирования на базе IDE-Bench, передовые языковые модели демонстрируют высокую эффективность при решении задач из области разработки программного обеспечения. Показатель pass@5, определяющий долю успешно выполненных задач при пяти попытках, варьируется от 83% до 95% для лучших моделей. Это свидетельствует о значительном прогрессе в области AI-ассистентов для разработки и подтверждает их способность решать реальные задачи, с которыми сталкиваются разработчики, включая написание и модификацию кода, а также прохождение тестов.
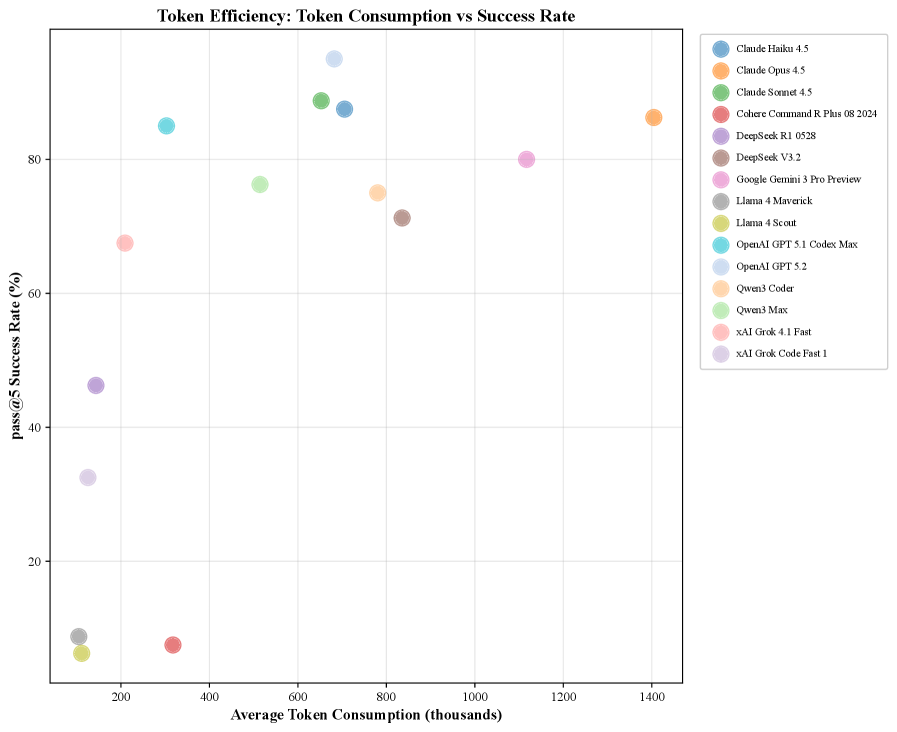
Будущее AI-ускоренной разработки: Куда ведёт нас IDE-Bench?
Разработанная платформа IDE-Bench представляет собой стандартизированный и строгий инструментарий, призванный ускорить прогресс в области разработки программного обеспечения с использованием искусственного интеллекта. Эта платформа обеспечивает единую основу для оценки и сравнения различных AI-агентов, предназначенных для помощи программистам, что способствует развитию инноваций и обмену опытом между исследователями и разработчиками. Благодаря тщательно разработанному набору задач и метрик, IDE-Bench позволяет объективно измерять производительность AI-агентов в различных аспектах разработки, таких как написание кода, отладка и рефакторинг. В конечном итоге, это способствует созданию более эффективных и интеллектуальных инструментов, способных значительно повысить продуктивность и качество программного обеспечения.
Существующие эталоны оценки возможностей искусственного интеллекта в разработке программного обеспечения часто оказываются недостаточно полными и не отражают реальной сложности задач, с которыми сталкиваются программисты. IDE-Bench призван преодолеть эти ограничения, предоставляя комплексную и стандартизированную платформу для оценки и сравнения AI-агентов, работающих в интегрированных средах разработки. Благодаря тщательно подобранному набору задач, охватывающих весь цикл разработки — от понимания требований до исправления ошибок — IDE-Bench позволяет выявить истинный потенциал AI в автоматизации рутинных операций, повышении производительности и создании более качественного кода. Этот подход способствует развитию более интеллектуальных и способных AI-агентов, способных не просто выполнять отдельные команды, но и самостоятельно решать сложные задачи, приближая эру действительно автоматизированной разработки программного обеспечения.
Оценка агентов на базе IDE-Bench предоставляет ценные сведения, которые способны существенно ускорить внедрение искусственного интеллекта в процесс разработки программного обеспечения. Полученные данные позволяют выявить наиболее эффективные подходы и архитектуры, что, в свою очередь, ведет к повышению производительности труда программистов и улучшению качества создаваемого кода. Более глубокое понимание сильных и слабых сторон различных AI-агентов позволит разработчикам программных средств создавать более интеллектуальные и полезные инструменты, автоматизирующие рутинные задачи и позволяющие специалистам сосредоточиться на решении сложных проблем. В конечном итоге, эта работа направлена на создание более эффективной и надежной экосистемы разработки, в которой искусственный интеллект играет ключевую роль в повышении общей эффективности и качества программных продуктов.
Анализ продемонстрировал выраженную специализацию моделей искусственного интеллекта на различных задачах разработки программного обеспечения. Исследование выявило существенные различия в стратегиях исследования и использования информации, что количественно оценивается посредством показателя “чтение-редактирование”, варьирующегося от 1.70 до 5.29. Более высокие значения этого показателя свидетельствуют о том, что модель тратит значительно больше времени на анализ существующего кода и документации, прежде чем приступить к внесению изменений, что может указывать на осторожный подход или трудности в интерпретации контекста. Напротив, низкие значения указывают на более активное редактирование, возможно, с меньшим акцентом на всестороннем понимании. Данная специализация и различия в стратегиях подчеркивают необходимость разработки более гибких и адаптируемых AI-агентов, способных эффективно решать широкий спектр задач в области разработки программного обеспечения.
Исследование, представленное в статье, неумолимо напоминает о неизбежном. Создание IDE-Bench, как инструмента для оценки агентов на базе больших языковых моделей, — это лишь временная передышка. Кажется, будто авторы пытаются задокументировать состояние дел, прежде чем оно окончательно рухнет под натиском новых, более изощренных способов сломать систему. Клод Шеннон, кажется, предвидел эту гонку вооружений, когда говорил: «Коммуникация — это не передача информации, а создание общего понимания». В контексте этой работы, “общее понимание” — это иллюзия, которую мы пытаемся создать, чтобы хоть как-то оценить непредсказуемость этих самых агентов. И, разумеется, как только эта оценка станет хоть сколько-нибудь стабильной, найдется способ её обойти. Ведь, если баг воспроизводится, у нас стабильная система, а значит, она нуждается в новых, более хитрых ошибках.
Куда Ведет Эта Дорога?
Представленная работа, создавая платформу для оценки агентов IDE, неизбежно выявила, что критерии «реальных задач» — это, как и всё оптимизированное, вопрос времени. Сегодняшний бенчмарк — завтрашний техдолг. Очевидно, что простое увеличение объёма данных для обучения лишь отодвинет проблему, а не решит её. Агенты будут генерировать больше кода, быстрее, но фундаментальные вопросы — понимание контекста, долгосрочное планирование, и, что важнее, способность к самодиагностике — останутся без ответа.
Более того, акцент на «инструментах» (tool calling) — это лишь способ делегировать сложность. Платформа, умеющая вызывать компилятор, не является искусственным интеллектом, это — автоматизация. Настоящий прорыв потребует от агентов способности к творческому решению проблем, к изобретению новых инструментов, а не просто использованию существующих.
В конечном счёте, оценка агентов IDE — это не столько задача машинного обучения, сколько — задача проектирования сложных систем. Архитектура — это не схема, а компромисс, переживший деплой. И каждый новый бенчмарк — это лишь очередное подтверждение того, что код мы не рефакторим — мы реанимируем надежду.
Оригинал статьи: https://arxiv.org/pdf/2601.20886.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Взлом языковых моделей: эволюция атак, а не подсказок
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Квантовый оптимизатор: Новый подход к сложным задачам
- Эволюция Симуляций: От Агентов к Сложным Социальным Системам
- Квантовые хроники: Последние новости в области квантовых исследований и разработки.
- Роботы учатся видеть: новая стратегия управления на основе видео
- Молекулярный конструктор: Искусственный интеллект на службе создания лекарств
- Диффузия против Квантов: Новый Взгляд на Факторизацию
2026-02-02 06:14