Автор: Денис Аветисян
Новое исследование анализирует тысячи изменений в коде Android и iOS, созданных при помощи AI-агентов, чтобы оценить их влияние на процесс разработки.
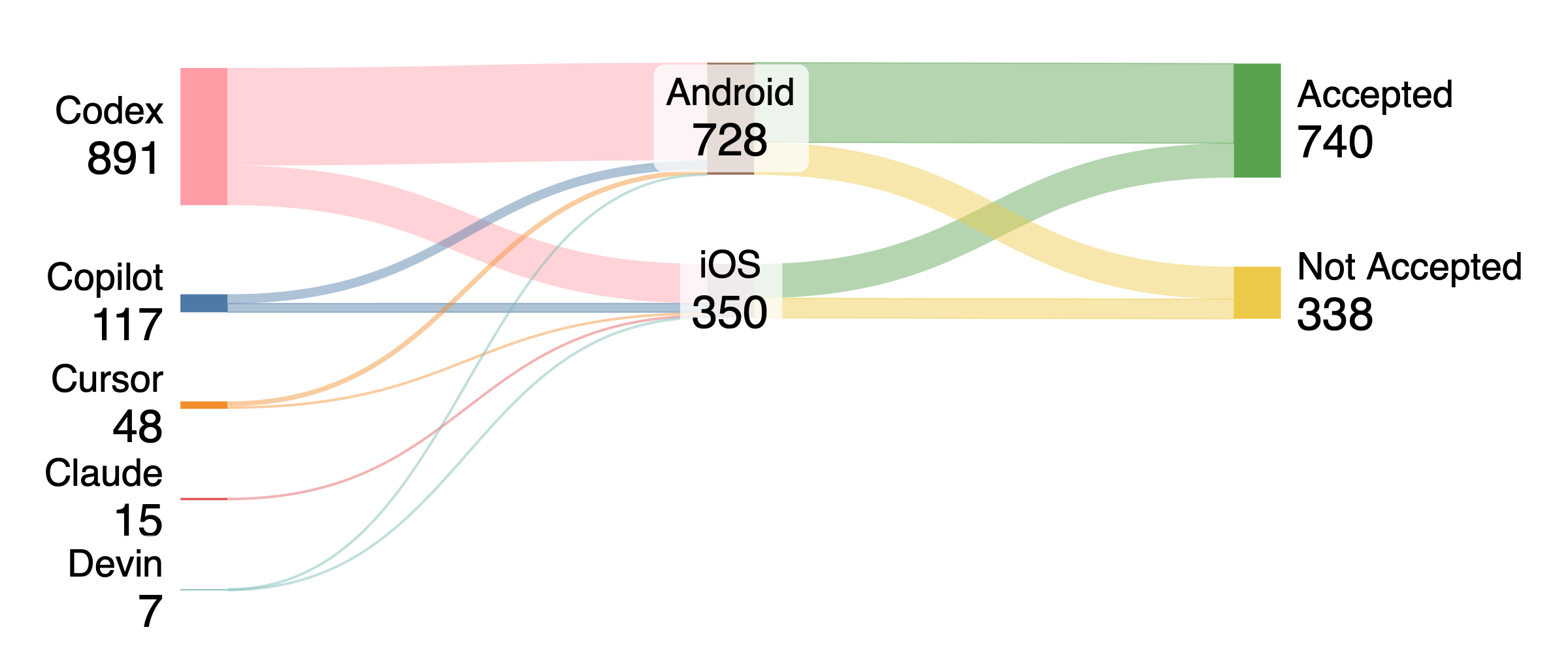
Анализ почти 3000 pull request’ов на платформах Android и iOS показывает различия в эффективности AI-агентов при выполнении рутинных задач и вариативность в скорости и вероятности принятия изменений.
Несмотря на растущий интерес к применению искусственного интеллекта в разработке программного обеспечения, эмпирическая оценка влияния AI-агентов на мобильные платформы остаётся недостаточной. В данной работе, ‘On the Adoption of AI Coding Agents in Open-source Android and iOS Development’, представлено первое категорийное исследование, анализирующее 2901 pull request, созданных AI-агентами в 193 открытых проектах Android и iOS. Полученные результаты демонстрируют, что проекты на Android получили в два раза больше pull request от AI-агентов с более высоким уровнем принятия (71% против 63% для iOS), при этом наблюдается значительная вариативность эффективности агентов в зависимости от платформы и типа задачи — рутинные задачи, такие как добавление новых функций и исправление ошибок, принимаются чаще, чем рефакторинг или изменения в сборке. Каковы перспективы дальнейшей оптимизации AI-агентов для повышения эффективности разработки мобильных приложений и адаптации к специфике различных платформ?
Оценка эффективности ИИ-агентов в разработке: от теории к практике
В последнее время наблюдается значительный рост использования инструментов на основе искусственного интеллекта, таких как Codex, Copilot и Devin, для автоматизации процесса внесения изменений в программный код. Эти агенты способны генерировать фрагменты кода, предлагать исправления и даже создавать полноценные pull request’ы — запросы на внесение изменений в основной код проекта. Подобная тенденция обусловлена стремлением к повышению производительности разработчиков и ускорению жизненного цикла программного обеспечения. Автоматизация рутинных задач позволяет программистам сосредоточиться на более сложных и творческих аспектах разработки, что в конечном итоге способствует созданию более качественного и инновационного программного обеспечения. Использование AI-агентов для внесения кода становится все более распространенной практикой, изменяя привычные подходы к разработке и требуя новых методов оценки эффективности.
Для адекватной оценки эффективности автоматизированных агентов, создающих программный код, необходимы надежные и измеримые показатели. В частности, ключевыми метриками выступают процент принятых pull request (PR) — отражающий качество и соответствие предложенных изменений требованиям проекта — и время разрешения PR, характеризующее скорость интеграции новых фрагментов кода. Высокий процент принятия указывает на способность агента генерировать полезный и совместимый код, в то время как минимальное время разрешения свидетельствует об эффективности процесса проверки и внесения изменений. Анализ этих метрик позволяет объективно сравнить различные типы агентов и выявить области для дальнейшего улучшения, способствуя созданию более надежных и продуктивных инструментов разработки.
Масштабный анализ 2901 запроса на внесение изменений (pull request), созданных ИИ-агентами и собранных в наборе данных AIDev, позволил получить ценные сведения об эффективности этих агентов в различных проектах. Исследование охватило широкий спектр языков программирования и типов задач, выявив закономерности в успешности внесения изменений, времени их рассмотрения и частоте необходимости доработки. Полученные данные демонстрируют, что производительность ИИ-агентов значительно варьируется в зависимости от сложности проекта и качества исходного кода, что подчеркивает важность разработки метрик для точной оценки их вклада в процесс разработки программного обеспечения и выявления областей для дальнейшего улучшения.
Категоризация задач в Pull Request: эмпирический подход
Для определения типов задач, представленных в Pull Request, мы использовали комбинацию модели GPT-5 и метода открытой карточной сортировки. GPT-5 был задействован для предварительной генерации потенциальных категорий, которые затем были уточнены и структурированы на основе результатов открытой карточной сортировки, проведенной с участием экспертов. В результате этого процесса была разработана система из 13 категорий, охватывающих как добавление новой функциональности (функциональные задачи), так и улучшения существующего кода, такие как рефакторинг, исправление ошибок и обновление документации (нефункциональные задачи). Этот подход позволил получить эмпирически обоснованную классификацию, отражающую реальную природу вклада в кодовую базу.
Выделенные категории вклада в Pull Request, охватывающие широкий спектр задач от реализации новых функций до рефакторинга и обновления документации, позволяют получить детальное представление о типах изменений, вносимых в кодовую базу. Такая детализация выходит за рамки простого разделения на “исправление ошибок” и “добавление функциональности”, предоставляя более гранулярную картину, включающую, например, оптимизацию производительности, изменение архитектуры, добавление тестов или обновление зависимостей. Это позволяет более точно анализировать вклад каждого разработчика, оценивать сложность изменений и оптимизировать процесс code review.
Для оценки надёжности разработанной классификации вклада в pull request использовался коэффициент Коэна Каппа (Cohen’s Kappa). Достигнутое значение в 0.877 указывает на высокую степень согласованности между оценщиками, что подтверждает устойчивость и объективность предложенной схемы категоризации. Коэффициент Коэна Каппа измеряет согласованность между двумя оценщиками, корректируя случайные совпадения, и значение 0.877 классифицируется как «сильное» согласие, что говорит о высокой степени надёжности и воспроизводимости полученных результатов.
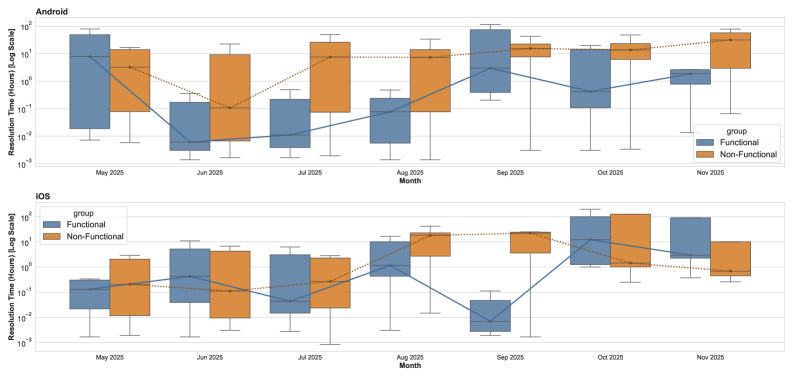
Сравнительный анализ производительности на различных платформах и с использованием различных агентов
Анализ показателей принятия (acceptance rate) и времени разрешения (resolution time) Pull Request (PR) на платформах Android и iOS выявил ряд специфических тенденций. Исследование охватывало значительный объем данных, что позволило установить различия в эффективности обработки PR в зависимости от платформы. В частности, наблюдались отличия в скорости рассмотрения и принятия PR, а также в общей продолжительности их разрешения. Полученные данные позволяют оценить производительность разработки на каждой платформе и выявить потенциальные области для оптимизации процессов.
Анализ показателей принятия pull request (PR) показал, что на платформе Android данный показатель составил 71.0%, что значительно выше, чем на iOS, где он равен 63.7%. Данное различие является статистически значимым, что указывает на более высокую вероятность принятия PR, созданных для Android, по сравнению с iOS. Разница в 7.3 процентных пункта может быть обусловлена различиями в процессах ревью, сложности кода или спецификой каждой платформы. Более подробный анализ, включающий данные по категориям PR и агентам, необходим для выявления конкретных причин данного расхождения.
Анализ данных показал, что Pull Request-ы, сгенерированные искусственным интеллектом (ИИ), разрешаются в 18 раз быстрее на платформе iOS по сравнению с Android. Данное наблюдение указывает на значительную разницу в эффективности обработки ИИ-автоматизированных запросов на исправление ошибок между двумя операционными системами. Факторы, влияющие на эту разницу, могут включать особенности реализации инструментов автоматизации, различия в кодовой базе и специфику процессов ревью на каждой платформе.
Статистический анализ, включающий применение критерия хи-квадрат и U-критерия Манна-Уитни, выявил статистически значимые различия в проценте принятия pull request между различными агентами и категориями задач. Результаты показывают, что эффективность принятия PR варьируется в зависимости от того, какой агент рассматривает запрос, а также от типа задачи, к которой относится PR. Данные подтверждают необходимость учитывать эти факторы при анализе производительности и оптимизации процесса разработки.
Анализ данных показал значительное превосходство по времени решения задач в Pull Request, классифицированных как функциональные. На платформе Android функциональные PR решаются в среднем в 400 раз быстрее, чем нефункциональные. На iOS данный показатель составляет 7-кратное ускорение. Данная разница в скорости решения задач подчеркивает важность точной классификации PR и указывает на более эффективную обработку функциональных изменений на обеих платформах.
Для оценки различий во времени разрешения pull request между различными разработчиками был применен непараметрический критерий Краскала-Уоллиса. Этот тест позволил сравнить медианы времени разрешения PR, созданных разными участниками, без предположений о нормальности распределения данных. Результаты анализа показали статистически значимые различия в эффективности работы между разработчиками, указывая на вариативность в скорости и качестве выполнения задач. В частности, были выявлены разработчики, демонстрирующие значительно более быстрое разрешение PR по сравнению с другими участниками команды, что может быть связано с опытом, специализацией или индивидуальными особенностями рабочего процесса.
Влияние и перспективы развития ИИ-ассистированной разработки
Исследования показали, что искусственные агенты, предназначенные для помощи в программировании, демонстрируют различный уровень эффективности в зависимости от типа задач. В частности, наблюдается значительная дифференциация в способности агентов справляться с локализацией, исправлением ошибок и изменениями в пользовательском интерфейсе. Этот факт указывает на перспективность разработки специализированных агентов, оптимизированных для выполнения конкретных видов задач, что позволит существенно повысить общую производительность и качество программного обеспечения. Возможность концентрации усилий агентов на узкоспециализированных областях открывает новые пути для автоматизации сложных процессов разработки и повышения эффективности работы программистов.
Исследование продемонстрировало выдающиеся результаты в области автоматической локализации программного обеспечения для платформы Android. В частности, все предложенные системой изменения, касающиеся локализации, были приняты разработчиками без каких-либо отклонений, что составляет 100% показатель успешности. Этот результат значительно превосходит показатели успешности для других категорий изменений, таких как исправления ошибок или изменения пользовательского интерфейса, и указывает на высокую точность и релевантность предлагаемых системой локализационных правок. Данное обстоятельство подчеркивает потенциал использования ИИ-агентов для автоматизации трудоемкого процесса адаптации программного обеспечения к различным языковым и культурным контекстам, значительно повышая эффективность разработки и снижая вероятность ошибок, связанных с ручным переводом и локализацией.
Исследования показали, что автоматические запросы на изменения (Pull Requests), касающиеся пользовательского интерфейса (UI) и исправления ошибок (Fix PRs) в разработке для платформы Android, демонстрируют впечатляюще высокую степень принятия — 88% и 75% соответственно. Это свидетельствует о том, что системы искусственного интеллекта, генерирующие такие запросы, способны эффективно решать задачи, связанные с визуальным оформлением и устранением неполадок в коде Android-приложений. Высокий процент принятия указывает на соответствие предложенных изменений стандартам качества и требованиям платформы, что существенно упрощает процесс интеграции и снижает необходимость в ручной проверке со стороны разработчиков.
Исследования показали, что эффективность агентов искусственного интеллекта, используемых в разработке программного обеспечения, значительно варьируется в зависимости от платформы. В частности, при работе с Android-проектами наблюдается более высокий процент успешного принятия предложений по внесению изменений (pull requests), особенно в категориях локализации, пользовательского интерфейса и исправления ошибок. Этот факт подчеркивает необходимость адаптации поведения агентов к специфике каждой среды разработки. Учитывая различия в архитектуре, инструментах и процессах разработки для различных платформ, создание специализированных агентов, оптимизированных для конкретной среды, представляется ключевым фактором повышения общей эффективности и качества разработки.
Данное исследование закладывает прочную основу для разработки более эффективных рабочих процессов с использованием искусственного интеллекта в разработке программного обеспечения. Полученные результаты позволяют оптимизировать производительность агентов ИИ в реальных проектах, предлагая возможности для создания специализированных инструментов и адаптации их к конкретным платформам и задачам. Понимание сильных и слабых сторон агентов в различных категориях задач, таких как локализация, исправление ошибок или работа с пользовательским интерфейсом, позволяет целенаправленно улучшать их алгоритмы и повышать качество генерируемого кода. Это, в свою очередь, способствует снижению затрат времени и ресурсов, необходимых для разработки, и открывает новые перспективы для автоматизации рутинных операций, позволяя разработчикам сосредоточиться на более сложных и творческих аспектах своей работы.
Исследование показывает, что эффективность агентов искусственного интеллекта в разработке мобильных приложений зависит от типа задач. Анализ почти трех тысяч pull request’ов для Android и iOS демонстрирует, что ИИ особенно преуспевает в решении рутинных задач, однако вариативность показателей принятия pull request’ов выше на платформе Android. Как отмечал Дональд Дэвис: «Простота — это высшая степень изысканности». Эта фраза прекрасно отражает суть разработки эффективных систем — чем яснее и проще идеи, тем легче масштабировать решение и обеспечить его надежную работу. Подобно тому, как в экосистеме каждый элемент взаимосвязан, так и в программном обеспечении, четкая структура определяет поведение системы и её способность к адаптации.
Что дальше?
Наблюдаемые различия в скорости принятия изменений, предложенных агентами искусственного интеллекта, на платформах Android и iOS, указывают на фундаментальную проблему: не код сам по себе определяет успех, а экосистема вокруг него. Android, с его большей открытостью и фрагментацией, демонстрирует большую изменчивость — ожидаемый результат. Всё ломается по границам ответственности — если их не видно, скоро будет больно. В данном случае, «границы ответственности» — это процессы проверки и интеграции кода, которые оказываются менее унифицированными и предсказуемыми в Android.
Будущие исследования должны сместить фокус с производительности агентов как таковых на изучение этих самых экосистем. Недостаточно создавать инструменты, нужно понимать, как они встраиваются в существующие рабочие процессы, и какие адаптации потребуются. Важно исследовать, как эти агенты влияют на роль разработчиков, и как можно максимизировать синергию между человеком и машиной. Иначе, мы получим лишь автоматизированные версии старых проблем.
В конечном счете, успех этих технологий будет определяться не скоростью написания кода, а способностью создавать устойчивые, надежные и понятные системы. Структура определяет поведение. Агенты, упрощающие рутину, — это хорошо. Агенты, способные предвидеть и предотвращать сложные ошибки — это уже искусство. И это искусство, требующее глубокого понимания не только кода, но и самой природы разработки.
Оригинал статьи: https://arxiv.org/pdf/2602.12144.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Новая формула для расчёта взаимодействий глюонов открывает горизонты для голографии пространства
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Искусственный интеллект на страже экологии: защита данных и справедливые алгоритмы
- Взрыв скорости: Оптимизация внимания для современных GPU
- Разумные языковые модели: новый подход к логическому мышлению
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Ожившие Пиксели: Создание Реалистичных Видео с Сохранением Личности
- Автоматическая оптимизация вычислений: новый подход к библиотекам математических функций
- Текстуры вместо Гауссиан: Новый подход к синтезу видов
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
2026-02-14 02:52