Автор: Денис Аветисян
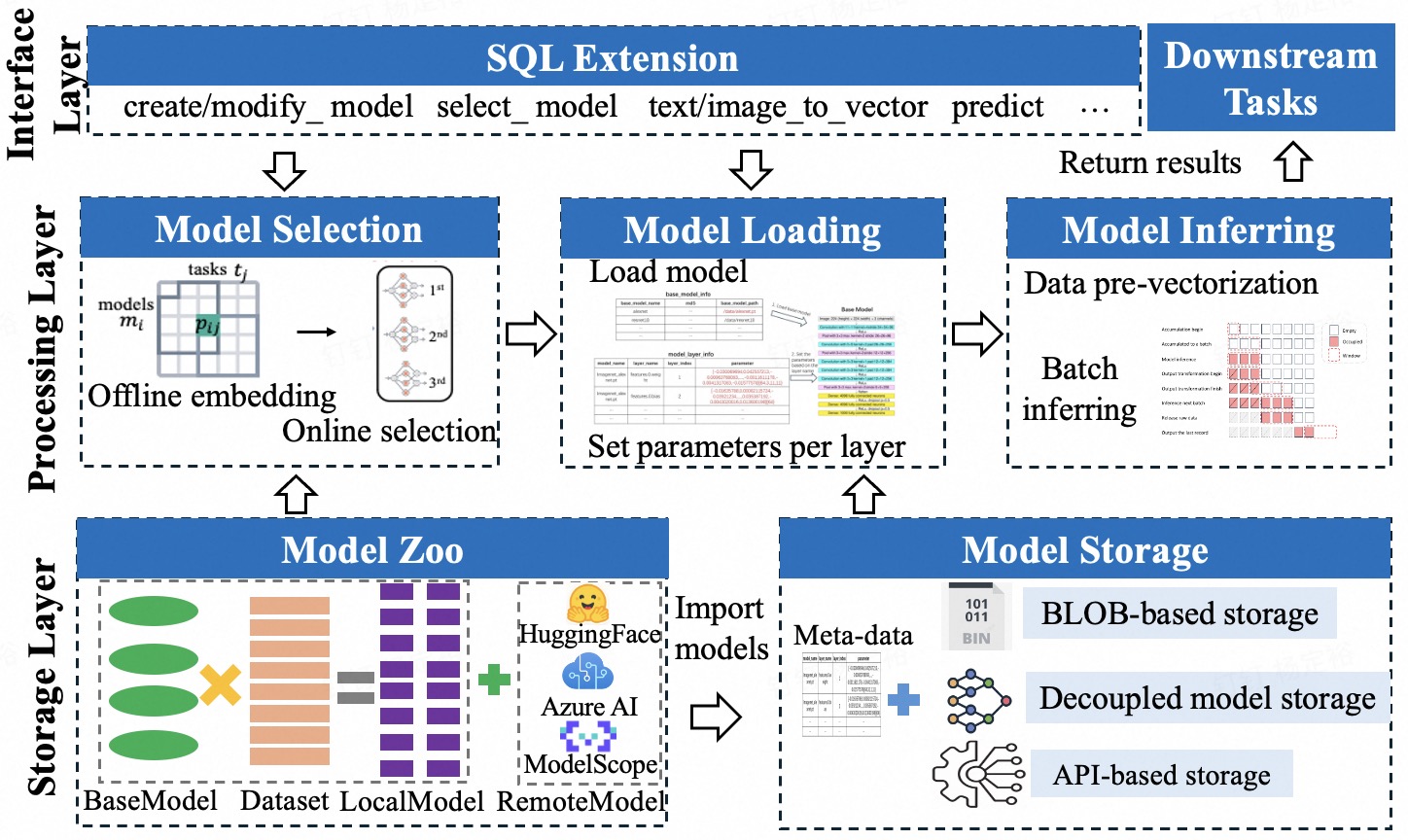
MorphingDB представляет собой расширение PostgreSQL, которое интегрирует возможности машинного обучения непосредственно в систему управления базами данных, упрощая развертывание и использование моделей.

MorphingDB — это AI-native СУБД, ориентированная на задачи, с поддержкой переобучения моделей, векторной обработки и пакетного вывода.
Несмотря на растущий спрос на интеграцию глубинного обучения в базы данных, существующие решения либо требуют ручной настройки моделей, либо характеризуются высокой вычислительной сложностью. В данной работе представлена система MorphingDB: A Task-Centric AI-Native DBMS for Model Management and Inference, реализующая автоматизированное управление моделями и вывод результатов непосредственно в PostgreSQL, ориентируясь на задачу, а не на саму модель. Разработанный подход, включающий трансферное обучение и оптимизации векторного представления и пакетной обработки, позволяет достичь высокой производительности и эффективности использования ресурсов. Сможет ли MorphingDB стать основой для нового поколения интеллектуальных баз данных, способных к самообучению и адаптации к меняющимся требованиям?
Преодолевая Границы Традиционных СУБД: Рождение AI-Native Систем
Традиционные системы управления базами данных (СУБД) изначально разрабатывались для обработки структурированных данных и выполнения простых запросов, что создает значительные трудности при работе с задачами глубокого обучения. В частности, выполнение операций, необходимых для вывода моделей машинного обучения, таких как тензорные вычисления и обработка векторов высокой размерности, требует огромных вычислительных ресурсов и эффективной организации данных, которые не предусмотрены в классических СУБД. Это приводит к узким местам в производительности, задержкам и неэффективному использованию аппаратных ресурсов, особенно при работе с большими объемами данных и требовательными приложениями реального времени. В результате, существующие системы часто не способны обеспечить необходимую скорость и масштабируемость для современных задач, связанных с искусственным интеллектом, что подчеркивает необходимость разработки новых подходов к управлению данными, ориентированных на потребности машинного обучения.
Растущий спрос на приложения искусственного интеллекта, работающие в режиме реального времени, обуславливает необходимость перехода к базам данных, изначально ориентированным на задачи машинного обучения. Традиционные системы управления базами данных (СУБД) разрабатывались для обработки структурированных данных и выполнения транзакций, но испытывают трудности при работе с неструктурированными данными, характерными для глубокого обучения, и при выполнении сложных аналитических запросов, необходимых для получения мгновенных результатов. Поэтому возникает потребность в новых СУБД, способных эффективно хранить, обрабатывать и анализировать данные, необходимые для работы моделей $AI$, обеспечивая низкую задержку и высокую пропускную способность, что критически важно для таких приложений, как автономные транспортные средства, системы обнаружения мошенничества и персонализированные рекомендации.
Существующие системы управления базами данных, ориентированные на искусственный интеллект, такие как EvaDB, MADlib и GaussML, зачастую сталкиваются с ограничениями в масштабируемости и организации рабочих процессов, ориентированных на конкретные задачи. Эти ограничения приводят к заметным провалам в производительности при обработке больших объемов данных и сложных запросов, особенно в сценариях реального времени. Неспособность эффективно адаптироваться к изменяющимся потребностям приложений ИИ и оптимизировать выполнение задач приводит к увеличению задержек и снижению общей эффективности. MorphingDB разработан для устранения этих недостатков, предлагая более гибкую и масштабируемую архитектуру, способную динамически адаптироваться к требованиям конкретных задач и обеспечивать значительное повышение производительности в различных приложениях искусственного интеллекта.

MorphingDB: Система Управления Данными, Ориентированная на Задачи Искусственного Интеллекта
MorphingDB представляет собой систему управления базами данных (СУБД), расширяющую функциональность PostgreSQL с целью интеграции возможностей искусственного интеллекта. В качестве основы используется проверенная временем и масштабируемая архитектура PostgreSQL, что обеспечивает надежность и стабильность системы. Это позволяет MorphingDB сочетать в себе преимущества традиционных реляционных баз данных, такие как транзакционность и целостность данных, с возможностями машинного обучения, предоставляя платформу для создания AI-приложений, требующих высокой производительности и масштабируемости. Использование PostgreSQL в качестве основы также упрощает интеграцию с существующими приложениями и инструментами, использующими эту СУБД.
В основе MorphingDB лежит задача-ориентированный подход, при котором пользователь определяет что необходимо сделать, а не как это реализовать. В отличие от традиционных СУБД, где требуется детальное указание процедур и алгоритмов, MorphingDB позволяет описывать желаемый результат задачи на высокоуровневом языке. Система автоматически определяет оптимальный способ выполнения, используя встроенные модели машинного обучения и механизмы оптимизации. Такой подход упрощает разработку и обслуживание приложений, позволяя разработчикам концентрироваться на бизнес-логике, а не на деталях реализации запросов и операций с данными.
MorphingDB использует двухфазный подход к выбору моделей, состоящий из Оффлайн-фазы Встраивания и Онлайн-фазы Проекции. В Оффлайн-фазе происходит построение подпространства переносимости (transferability subspace) на основе предобученных моделей и данных. Это подпространство представляет собой векторное пространство, в котором модели располагаются в зависимости от их способности к переносу знаний. В Онлайн-фазе, при поступлении нового запроса, модель проецируется в это подпространство, что позволяет быстро определить наиболее подходящую модель для решения задачи без необходимости её обучения с нуля. Эксперименты показывают, что такой подход значительно сокращает время выбора модели, обеспечивая повышение производительности системы по сравнению с традиционными методами.
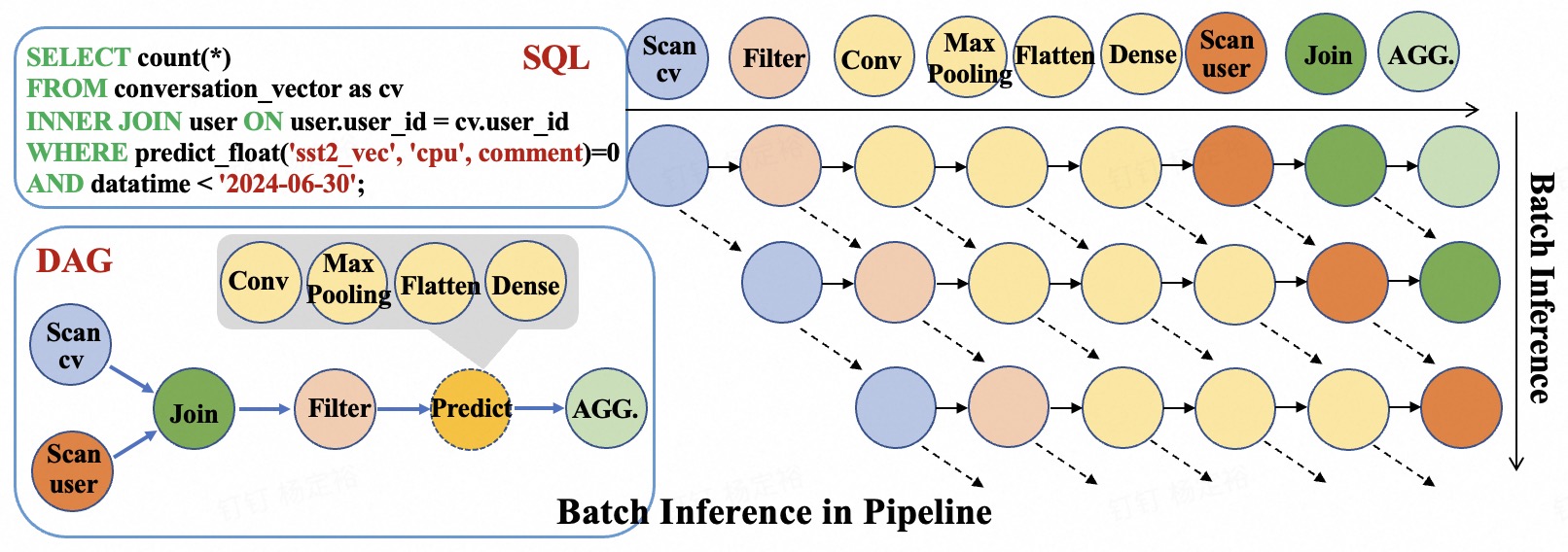
Оптимизация Вывода: DAG-Основанные Конвейеры и Mvec-Представление
MorphingDB использует ориентированный ациклический граф (DAG) для планирования и выполнения задач вывода, что позволяет оптимизировать их последовательность и параллелизацию. Вместо последовательного выполнения операций, DAG позволяет системе идентифицировать независимые задачи и выполнять их одновременно, значительно повышая пропускную способность и снижая задержку. Каждый узел в графе представляет собой операцию, а ребра — зависимости между операциями. Такая структура позволяет эффективно распределять ресурсы и минимизировать время ожидания, особенно при обработке сложных моделей и больших объемов данных. Использование DAG-пайплайна является ключевым фактором, обеспечивающим высокую производительность MorphingDB в задачах машинного обучения.
Формат Mvec является ключевым элементом эффективности MorphingDB, представляя собой структуру данных для хранения и обработки многомерных тензоров. В отличие от традиционных форматов хранения, Mvec оптимизирован для минимизации избыточности и повышения скорости доступа к данным. Это достигается за счет непрерывного хранения тензорных элементов в памяти и использования эффективных алгоритмов индексации. Такая организация данных позволяет значительно ускорить выполнение тензорных операций, что критически важно для задач машинного обучения и обработки данных, особенно при работе с большими объемами информации и сложными моделями. Mvec позволяет эффективно использовать аппаратные ресурсы, такие как кэш-память, и снижает накладные расходы на операции ввода-вывода.
Система MorphingDB использует методы пакетной обработки (Batch Inference), позволяющие параллельно обрабатывать несколько запросов. Данный подход значительно повышает пропускную способность системы при выполнении последовательных задач, демонстрируя прирост в 4 раза по сравнению с альтернативными решениями. Пакетная обработка позволяет эффективно использовать ресурсы оборудования, уменьшая накладные расходы, связанные с последовательной обработкой каждого запроса в отдельности.
Расширение Возможностей Искусственного Интеллекта: Поддерживаемые Когнитивные Задачи
МорфингДБ изначально поддерживает широкий спектр когнитивных задач, что позволяет решать разнообразные прикладные проблемы без необходимости дополнительной адаптации. Система способна эффективно выполнять распознавание изображений и объектов, классификацию тональности текста, обнаружение лиц на изображениях и разрешение сущностей — то есть, идентификацию и связывание различных упоминаний одного и того же объекта в тексте. Такая встроенная поддержка позволяет разработчикам и исследователям легко интегрировать возможности искусственного интеллекта в свои приложения, упрощая процесс создания интеллектуальных систем и аналитических инструментов.
В основе системы MorphingDB лежит использование LibTorch, облегчающего процесс инференса и обеспечивающего полную совместимость с экосистемой PyTorch. Это позволяет разработчикам беспрепятственно интегрировать существующие модели, созданные в PyTorch, в MorphingDB, избегая необходимости их переработки или конвертации. Благодаря этому подходу, развертывание моделей искусственного интеллекта становится значительно проще и быстрее, а также открываются широкие возможности для использования передовых алгоритмов машинного обучения в базах данных. Использование LibTorch также способствует повышению производительности и масштабируемости системы, позволяя эффективно обрабатывать большие объемы данных и решать сложные аналитические задачи.
Система MorphingDB демонстрирует значительное увеличение производительности при выполнении задач машинного обучения, достигая прироста до 70% по сравнению с существующими AI-ориентированными СУБД. При этом, точность результатов остается сопоставимой с показателями современных AutoML-фреймворков, что подтверждает высокую эффективность предложенного подхода. Ключевым фактором, обеспечивающим такую скорость, является архитектура с разделенным хранением данных и моделей, позволяющая существенно сократить время загрузки моделей и оптимизировать процесс инференса. Это позволяет MorphingDB не только ускорить обработку данных, но и повысить общую эффективность систем, использующих машинное обучение.

Изучение MorphingDB заставляет задуматься о самой структуре систем управления данными. Разработчики предлагают не просто хранить информацию, а активно использовать её для выполнения задач, интегрируя AI-модели непосредственно в базу данных. Этот подход, сфокусированный на задачах, а не на данных как таковых, напоминает слова Тима Бернерса-Ли: «Веб — это не просто коллекция веб-страниц, это система для организации знаний». Подобно тому, как Веб объединяет информацию, MorphingDB стремится объединить хранение и анализ, превращая базу данных из пассивного хранилища в активного участника решения задач, используя возможности переноса обучения и векторизации для повышения эффективности. Система словно проверяет границы возможного, ища новые способы организации и использования информации.
Куда же дальше?
Представленная работа, по сути, лишь первый шаг в долгой игре. Интеграция логики вывода непосредственно в СУБД — идея, безусловно, элегантная, но она обнажает куда больше вопросов, чем дает ответов. Авторы сконцентрировались на оптимизации производительности, что похвально, но где гарантии, что предложенный «task-centric» подход не станет узким местом для задач, выходящих за рамки заранее определенных сценариев? Реальный мир редко вписывается в аккуратные схемы.
Особый интерес вызывает вопрос о масштабируемости. Перенос моделей машинного обучения в базу данных — это, конечно, удобно, но как эта архитектура поведет себя при увеличении объемов данных и сложности моделей? Не превратится ли «AI-native» СУБД в очередную черную коробку, требующую все более изощренных методов отладки и оптимизации? Необходимо исследовать возможности динамической адаптации и самооптимизации, чтобы система не стагнировала, а развивалась вместе с потребностями пользователя.
В конечном счете, MorphingDB — это не финальный продукт, а скорее платформа для экспериментов. Дальнейшие исследования должны быть направлены на преодоление ограничений существующих алгоритмов машинного обучения, разработку новых методов представления знаний и, самое главное, на создание систем, способных к самостоятельному обучению и адаптации. Ведь истинная цель — не просто автоматизировать существующие процессы, а создать системы, которые смогут решать задачи, о которых мы пока даже не подозреваем.
Оригинал статьи: https://arxiv.org/pdf/2511.21160.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые сети для моделирования молекул: новый подход
- Квантовые прорывы: Хорошее, плохое и смешное
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
2025-11-29 20:53