Автор: Денис Аветисян
Новая архитектура FS-Researcher позволяет искусственному интеллекту проводить глубокие исследования, преодолевая ограничения контекста и эффективно используя рабочее пространство в виде файловой системы.
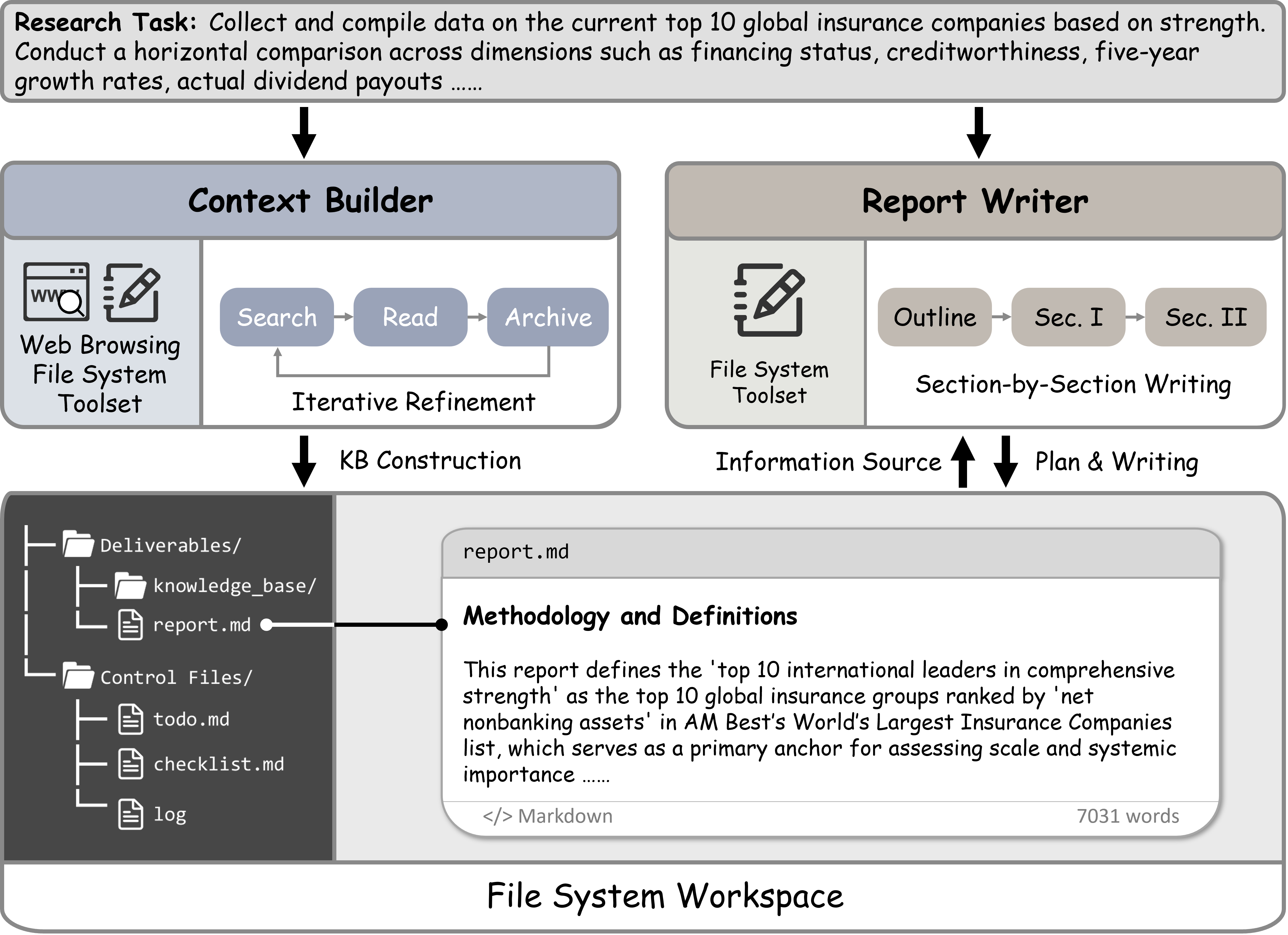
Представлена двухкомпонентная система, использующая файловую систему для итеративной доработки и расширения базы знаний при решении сложных исследовательских задач.
Долгосрочные исследовательские задачи, требующие обработки больших объемов информации, часто сталкиваются с ограничениями контекстного окна языковых моделей. В данной работе представлена система ‘FS-Researcher: Test-Time Scaling for Long-Horizon Research Tasks with File-System-Based Agents’, использующая файловую систему как постоянное рабочее пространство для преодоления этих ограничений. Предложенный двух-агентный фреймворк, включающий построителя контекста и составителя отчетов, позволяет эффективно масштабировать исследовательский процесс за счет итеративной доработки и расширения базы знаний. Способствует ли подобный подход к организации внешних знаний повышению качества и надежности результатов глубоких исследований, особенно в условиях ограниченных вычислительных ресурсов?
Глубокое погружение в исследование: вызовы и ограничения
Глубокое исследование, требующее синтеза знаний на уровне докторской диссертации, представляет собой серьезную проблему для современных языковых моделей. В отличие от простого извлечения информации, подобная работа подразумевает критический анализ, выявление взаимосвязей между различными источниками и формирование оригинальных выводов. Существующие модели часто демонстрируют трудности в удержании сложной логической структуры, необходимой для подобных задач, и склонны к поверхностному перефразированию вместо глубокого понимания. Это связано не только с объемом знаний, но и с необходимостью творческого подхода и способности к абстрактному мышлению, которые пока остаются за пределами возможностей искусственного интеллекта. Таким образом, для успешного проведения исследований, требующих экспертного уровня синтеза, необходимы принципиально новые подходы к разработке и обучению языковых моделей.
Ограничение длины контекста представляет собой фундаментальную проблему для современных больших языковых моделей (LLM). Суть заключается в том, что LLM способны эффективно обрабатывать лишь ограниченный объем информации за один раз. В то время как человеческий разум способен удерживать и синтезировать информацию из различных источников на протяжении длительного времени, LLM сталкиваются с трудностями при анализе больших объемов текста, например, целых книг или научных статей. Это означает, что при попытке обработки слишком большого количества данных модель может «забыть» информацию, представленную в начале, или потерять важные взаимосвязи между различными частями текста. В результате, способность LLM к глубокому исследованию, требующему синтеза информации из множества источников, существенно ограничивается, что препятствует их эффективному использованию в сложных научных задачах и анализе больших данных.
Традиционные методы обработки информации, такие как статичные конвейеры, оказываются неэффективными при решении сложных исследовательских задач, требующих гибкости и постоянной доработки. В этих конвейерах каждый этап обработки данных жёстко задан и последователен, что не позволяет учитывать новые данные или изменять логику работы в процессе исследования. В отличие от этого, глубокое исследование подразумевает итеративный процесс, где результаты одного этапа влияют на последующие, а исследователь постоянно адаптирует свой подход в зависимости от полученных данных. Статичные конвейеры не способны к такому динамическому изменению, что приводит к неполному анализу информации и, как следствие, к неточным или устаревшим выводам. Необходимость адаптации и уточнения гипотез в процессе исследования требует от систем обработки информации способности к самокоррекции и обучению, что выходит за рамки возможностей традиционных, жёстко заданных алгоритмов.
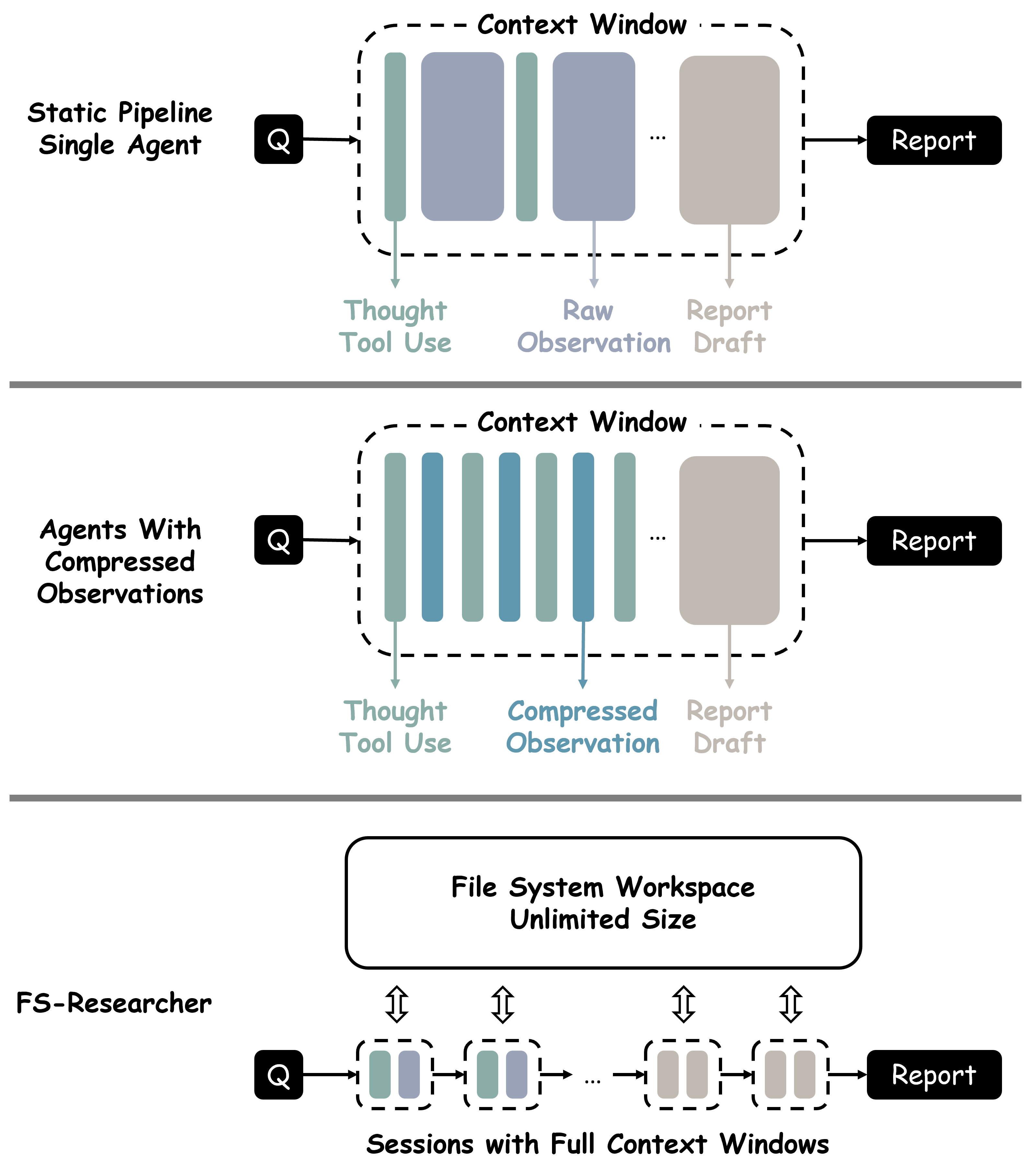
FS-Researcher: Двойной агент для расширенного рассуждения
FS-Researcher представляет собой двойной агентский фреймворк, разработанный для решения проблемы ограниченного контекста больших языковых моделей (LLM). В отличие от традиционных LLM, которые ограничены объемом входного текста, FS-Researcher разделяет процесс рассуждения на два отдельных агента. Это позволяет системе преодолеть ограничения по длине контекста, поскольку информация собирается и организуется в специализированной базе знаний, а затем используется для формирования итогового отчета. Такой подход позволяет обрабатывать более сложные задачи, требующие обширных знаний и длительного анализа, и повышает надежность и точность генерируемых результатов.
Агент «Конструктор Контекста» предназначен для сбора и организации информации в Базу Знаний, используя файловую систему как рабочее пространство для сохранения данных. Этот подход позволяет агенту накапливать и структурировать информацию в процессе работы, обеспечивая ее персистентность и доступность для последующего использования. Файловая система выступает в качестве внешней памяти, где агент хранит собранные документы, результаты поиска и промежуточные выводы, что позволяет преодолеть ограничения контекстного окна языковой модели и поддерживать долгосрочную память для решения сложных задач.
Агент “Составитель отчёта” осуществляет синтез информации в финальный отчёт, используя в качестве основного источника структурированную базу знаний, сформированную агентом “Построитель контекста”. Этот процесс предполагает извлечение релевантных данных из базы знаний, их обработку и компиляцию в последовательный и логичный отчёт. В отличие от прямого использования внешних источников, агент опирается исключительно на предварительно организованную информацию, что обеспечивает согласованность и снижает вероятность включения противоречивых данных. Финальный отчёт представляет собой результат анализа и синтеза информации, представленной в базе знаний, и направлен на предоставление комплексного и структурированного ответа на исходный запрос.
Оба агента в FS-Researcher используют архитектуру ReAct, которая представляет собой чередование этапов рассуждения (Reasoning) и действий (Acting). В процессе работы агенты сначала формулируют логические шаги для достижения поставленной цели, а затем выполняют конкретные действия, такие как поиск информации или запись в базу знаний. Результаты этих действий анализируются, и на основе этого анализа формируется следующий шаг рассуждения. Этот цикл повторяется до тех пор, пока не будет достигнута цель, обеспечивая итеративное улучшение как сбора информации, так и качества финального отчета. Применение ReAct позволяет агентам динамически адаптироваться к новым данным и корректировать стратегию поиска, что существенно повышает эффективность работы в задачах расширенного рассуждения.
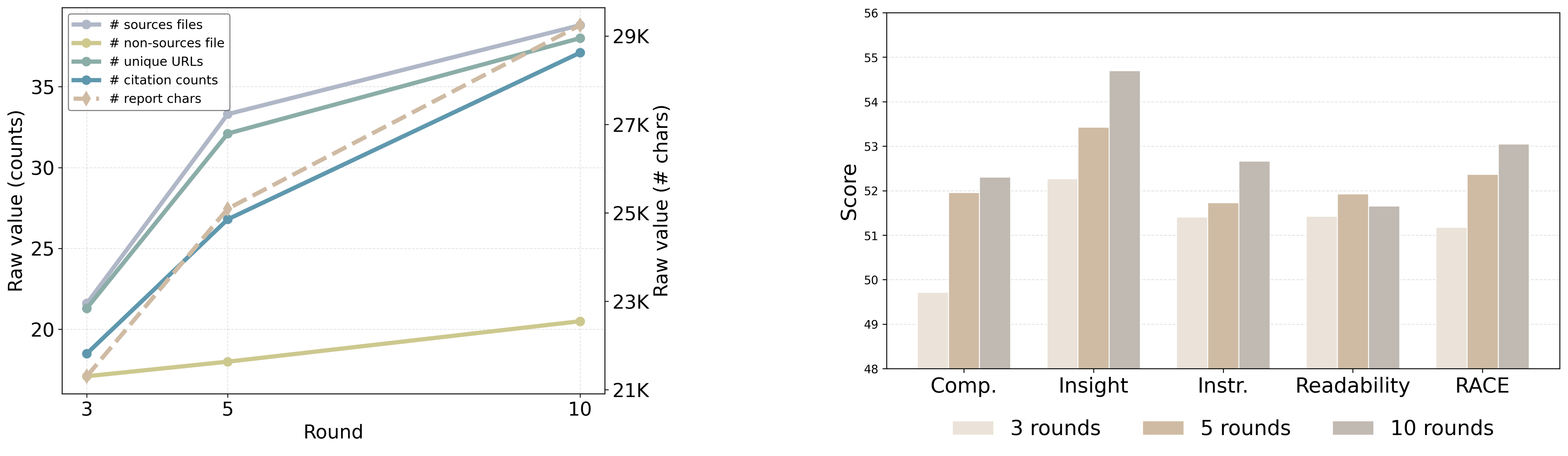
Рабочий процесс и контроль качества в FS-Researcher
В FS-Researcher для управления действиями агентов используется система задач (Todos), представляющая собой последовательность четко определенных шагов. Каждая задача (Todo) описывает конкретную операцию, которую необходимо выполнить в процессе исследования, обеспечивая структурированный и прогрессивный подход. Агенты последовательно выполняют задачи из списка Todos, что позволяет им фокусироваться на текущем этапе работы и избегать отклонений от поставленной цели. Такая организация позволяет эффективно распределять ресурсы и контролировать ход исследования, гарантируя, что каждый аспект темы будет тщательно изучен.
В FS-Researcher для верификации полноты и качества результатов работы агентов используется контрольный список (чек-лист). Этот список применяется обоими агентами, обеспечивая стандартизированную процедуру проверки и минимизируя субъективные оценки. Чек-лист охватывает ключевые аспекты каждого этапа исследования, такие как соответствие требованиям, полнота собранных данных, корректность анализа и логичность выводов. Использование единого контрольного списка способствует повышению согласованности результатов и надежности всей исследовательской работы, а также облегчает процесс аудита и контроля качества.
В FS-Researcher реализована итеративная доработка результатов, позволяющая агентам возвращаться к ранее выполненным задачам и улучшать их на основе обратной связи и новой информации. Этот процесс предполагает многократное пересмотр и корректировку данных, а не однократную обработку, что обеспечивает повышение качества и точности итоговых результатов исследования. В частности, агенты могут пересматривать первоначальные выводы, уточнять источники данных и переоценивать значимость отдельных фактов в свете новой информации, полученной в ходе дальнейшего исследования.
В FS-Researcher обработка информации осуществляется не однократно, а посредством последовательных уточнений. Этот итеративный подход позволяет агентам многократно пересматривать и улучшать результаты, основываясь на промежуточных выводах и поступающей новой информации. Каждая итерация способствует повышению точности и полноты данных, поскольку ошибки и неточности выявляются и корректируются на каждом этапе. Многократное повторение циклов обработки, проверки и улучшения гарантирует более высокое качество и надежность итоговых результатов исследований.
Оценка и валидация: демонстрируя возможности FS-Researcher
Для всесторонней оценки возможностей системы FS-Researcher были использованы авторитетные отраслевые бенчмарки DeepResearch Bench и DeepConsult, являющиеся признанными стандартами для систем глубоких исследований. Эти платформы позволяют объективно измерить способность системы генерировать качественные и достоверные отчеты, сравнивая её результаты с показателями других передовых решений. Применение именно этих бенчмарков гарантирует, что оценка производительности FS-Researcher осуществляется на основе общепринятых методологий и позволяет достоверно продемонстрировать её преимущества перед существующими подходами к анализу и синтезу информации.
Для оценки качества и достоверности генерируемых отчетов используется комплексная система метрик, включающая RACE Score и FACT Score. RACE Score, ориентированная на оценку рассуждений и логической связности, позволяет определить, насколько полно и последовательно система отвечает на сложные вопросы. В свою очередь, FACT Score измеряет фактическую точность информации, представленной в отчете, выявляя противоречия с установленными данными. Комбинированное использование этих метрик обеспечивает всестороннюю оценку работы системы, гарантируя не только глубину анализа, но и надежность предоставляемой информации, что критически важно для исследовательских задач и принятия обоснованных решений.
Результаты всесторонней оценки демонстрируют способность FS-Researcher генерировать отчеты, превосходящие по качеству и фактической точности традиционные методы глубоких исследований. Система достигла показателя RACE в 53.94, что значительно превышает результат самого сильного конкурента, RhinoInsight, на 3.02 пункта. Этот впечатляющий результат подтверждает, что FS-Researcher способен не просто собирать информацию, но и синтезировать ее в связные, достоверные и полезные отчеты, представляя собой значительный шаг вперед в области автоматизированных систем для глубокого анализа и исследований.
В ходе оценки на платформе DeepConsult, система FS-Researcher продемонстрировала впечатляющие результаты, достигнув показателя выигрышей в 80.00% и средней оценки в 8.33 балла — это наивысшие значения среди всех протестированных систем. Более того, в сравнении с предыдущим лидером на DeepResearch Bench, FS-Researcher значительно превзошел его по ключевым параметрам: полнота предоставляемой информации увеличилась на 3.74 балла, а глубина анализа и проницательность — на 4.4 балла. Эти данные подтверждают способность системы не только эффективно собирать информацию, но и предоставлять глубокие, всесторонние и ценные выводы, что делает её передовым решением в области глубоких исследований.
Исследование демонстрирует, что системы, предназначенные для длительной работы над сложными задачами, неизбежно сталкиваются с ограничениями контекста. FS-Researcher, предлагая архитектуру, основанную на файловой системе, стремится смягчить эту проблему, позволяя агенту итеративно уточнять знания и строить более прочную базу данных. Этот подход напоминает о цикличности эволюции систем, где каждая архитектура проживает свою жизнь, адаптируясь к изменяющимся условиям. Как однажды заметил Роберт Тарьян: «Структуры данных — это не просто способ организации информации, это отражение нашего понимания мира». FS-Researcher, по сути, предлагает способ организации знаний, позволяющий агенту лучше ориентироваться в сложном информационном пространстве и выполнять долгосрочные исследовательские задачи.
Что же дальше?
Представленная работа, как и любая попытка упорядочить хаос долгосрочных исследовательских задач, лишь временно отсрочила неизбежное. Ограничения контекста, несмотря на использование файловой системы как внешней памяти, остаются. Ведь каждая записанная информация — это не сохранение истины, а лишь очередной отпечаток моментального состояния, обречённого на устаревание. Система, подобно любому живому организму, стареет, и её «знания» требуют постоянной переоценки, пересмотра, перестройки.
Будущие исследования, вероятно, будут направлены не столько на увеличение объёма хранимой информации, сколько на разработку механизмов её фильтрации, оценки релевантности и адаптации к изменяющимся условиям. Каждый «баг» — это момент истины на временной кривой, указывающий на слабое место в архитектуре системы. Игнорирование этих моментов — это накопление технического долга, закладка прошлого, которую придётся оплачивать настоящим.
В конечном итоге, задача состоит не в создании идеального агента-исследователя, а в разработке системы, способной достойно стареть, адаптироваться к неизбежному энтропии и продолжать приносить пользу даже в условиях ограниченных ресурсов и неполной информации. Время — не метрика, а среда, в которой существуют системы, и умение ориентироваться в этой среде — вот истинный вызов для исследователей.
Оригинал статьи: https://arxiv.org/pdf/2602.01566.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Отражения культуры: Как языковые модели рассказывают истории
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Квантовый оптимизатор: Новый подход к сложным задачам
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Понимание без слов: как оценить истинный интеллект ИИ
- Раскрытие причинно-следственных связей: новый подход на основе анализа повторяющихся паттернов
- Память против контекста: Когда ИИ нужно вспоминать, а не перечитывать
2026-02-03 07:30