Автор: Денис Аветисян
Новая модель искусственного интеллекта позволяет автоматически генерировать патентные заявки, адаптируясь к различным правовым системам и приближаясь к качеству, оцениваемому экспертами.
Представлена трехступенчатая адаптивная система генерации патентных формул с унифицированной оценкой качества, использующая многоголовое внимание и доменную адаптацию.
Несмотря на значительный прогресс в области автоматической генерации патентов, существующие системы часто сталкиваются с трудностями при адаптации к различным юрисдикциям и обеспечении высокого качества генерируемых формул изобретений. В статье ‘Adaptive Multi-Stage Patent Claim Generation with Unified Quality Assessment’ представлен новый трехэтапный фреймворк, решающий эти проблемы посредством анализа семантических связей, доменной адаптации и унифицированной оценки качества. Разработанный подход демонстрирует существенное улучшение производительности по сравнению с современными моделями, приближая автоматическую генерацию патентов к экспертным оценкам. Способны ли подобные системы в будущем кардинально упростить и ускорить процесс патентного поиска и оформления?
Разоблачение Слабых Мест: Качество Патентных Формулировок Под Угрозой
Автоматизированная генерация патентных формул притязаний сталкивается с существенной проблемой — отсутствием надежных метрик оценки качества. Современные системы, стремясь к автоматизации, зачастую не способны обеспечить достаточную семантическую точность, что приводит к формулировкам, не полностью отражающим суть изобретения и потенциально уязвимым с юридической точки зрения. Это связано с тем, что оценка семантической корректности требует понимания не только технических деталей, но и контекста изобретения, а также соответствия требованиям патентного законодательства. Недостаточная точность приводит к увеличению числа патентных споров и снижению ценности генерируемых формул, подчеркивая необходимость разработки более совершенных методов оценки качества, способных учитывать нюансы семантического смысла и юридической обоснованности.
Существующие методы автоматической генерации патентных претензий сталкиваются с трудностями в улавливании тонких семантических оттенков и юридической состоятельности, необходимых для создания надежных формулировок. Это приводит к тому, что генерируемые претензии часто оказываются недостаточно точными в определении объема изобретения, что снижает их ценность и повышает риск оспаривания в суде. Проблемой является сложность точного представления технических деталей и юридических требований в алгоритмической форме, что приводит к неполным или двусмысленным формулировкам. В результате, автоматизированные системы зачастую выдают претензии, требующие значительной ручной доработки со стороны патентных поверенных для обеспечения их соответствия правовым нормам и защиты интеллектуальной собственности.
Архитектура Инноваций: Адаптивный Многоступенчатый Фреймворк
Предлагаемый адаптивный многоступенчатый фреймворк объединяет анализ семантической близости с учетом взаимосвязей между сущностями, генерацию патентных формул с адаптацией к специфике различных патентных ведомств, и унифицированную оценку качества полученных формул. Данная интеграция позволяет учитывать контекст и взаимосвязи между элементами изобретения при генерации формул, что повышает их релевантность и юридическую значимость. Единая система оценки качества обеспечивает комплексный анализ генерируемых формул по заданным критериям, включая новизну, неочевидность и полноту раскрытия изобретения. Фреймворк предназначен для автоматизации и оптимизации процесса составления патентных формул.
Предлагаемый фреймворк использует методы адаптации низкого ранга (LoRA) и динамического выбора адаптеров для оптимизации производительности в различных патентных ведомствах. LoRA позволяет эффективно адаптировать предварительно обученные модели к специфике каждого ведомства, используя лишь небольшое количество обучаемых параметров. Динамический выбор адаптеров автоматически определяет наиболее подходящую конфигурацию адаптеров для конкретного патентного ведомства и типа запроса, что повышает точность и эффективность генерации и оценки патентных претензий. Такой подход позволяет избежать дорогостоящей переподготовки всей модели для каждого нового ведомства и обеспечивает масштабируемость системы.
Для эффективной обработки длинных патентных документов в рамках предложенной системы, используются механизмы адаптивного разбиения (Adaptive Chunking) и кросс-внимания (Cross-Attention). Адаптивное разбиение динамически определяет оптимальный размер фрагментов текста, учитывая структуру и содержание документа, что позволяет избежать потери контекста при обработке больших объемов информации. Механизм кросс-внимания позволяет модели устанавливать связи между различными фрагментами текста, выделяя наиболее релевантные части документа для решения поставленной задачи. Данный подход позволяет эффективно обрабатывать документы, превышающие лимиты контекстного окна стандартных моделей, и повышает точность анализа патентной информации.
Строгий Контроль Качества: Доказательства Эффективности Оценки
Модуль оценки качества использует унифицированный многозадачный подход к оценке, одновременно учитывая несколько ключевых параметров качества. Вместо проведения отдельных оценок по каждому параметру, система выполняет комплексный анализ, оценивая такие аспекты, как релевантность, согласованность, грамматическая корректность и информативность в рамках единого процесса. Это позволяет получить более целостную и объективную оценку, избегая искажений, которые могут возникнуть при изолированной оценке отдельных параметров. Такой подход повышает эффективность и точность оценки, а также снижает вычислительные затраты по сравнению с использованием нескольких независимых моделей.
Для повышения точности оценки используется метод контрастного обучения. Этот подход предполагает обучение модели различать семантически схожие и различные фрагменты текста, что позволяет ей более эффективно понимать нюансы значения и контекст. В процессе обучения модель подвергается воздействию пар примеров, состоящих из положительных (семантически близких) и отрицательных (семантически различных) образцов. Затем модель оптимизируется для максимизации сходства между положительными парами и минимизации сходства между отрицательными, что приводит к более глубокому пониманию семантики и, как следствие, к более точной оценке качества текста.
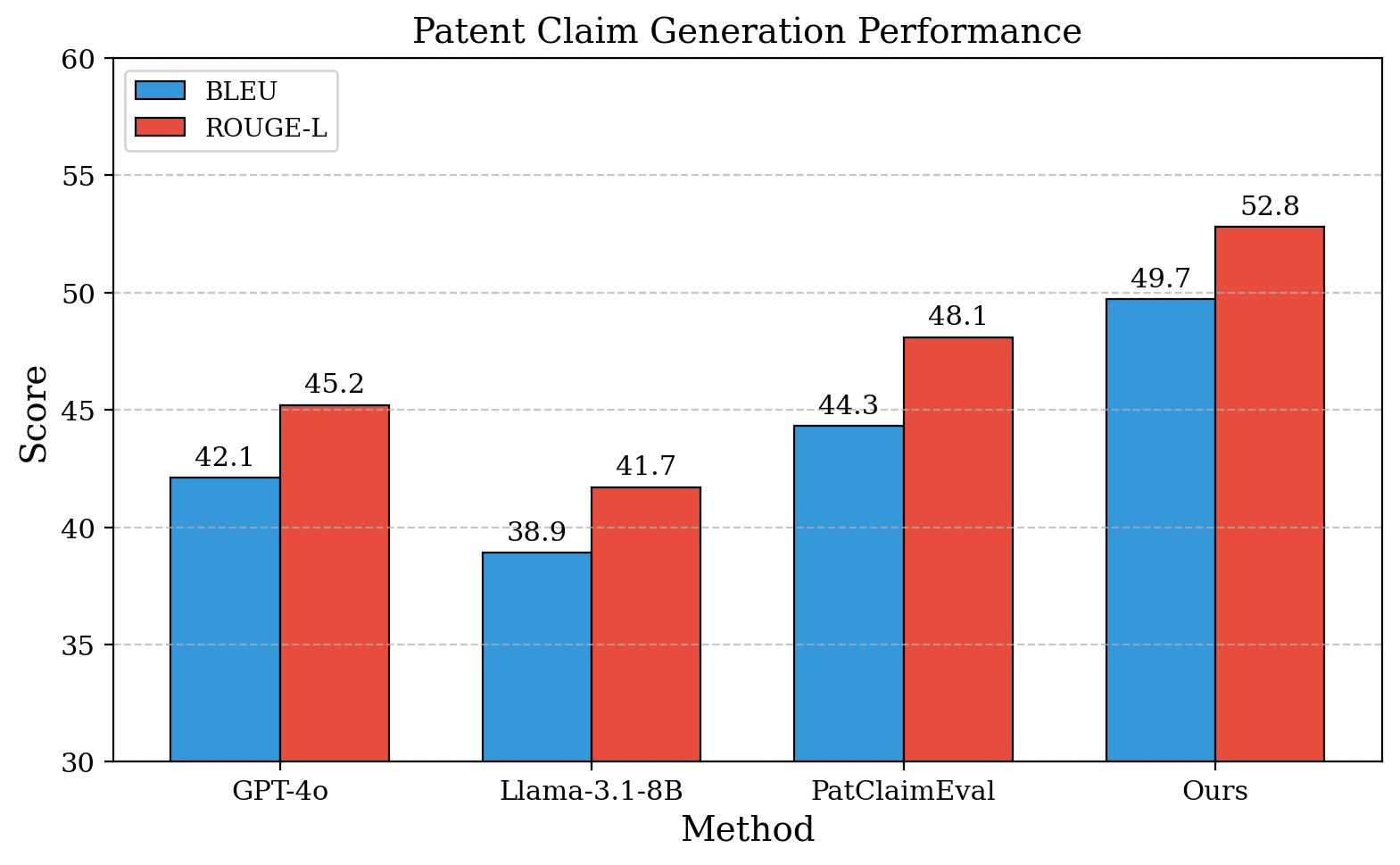
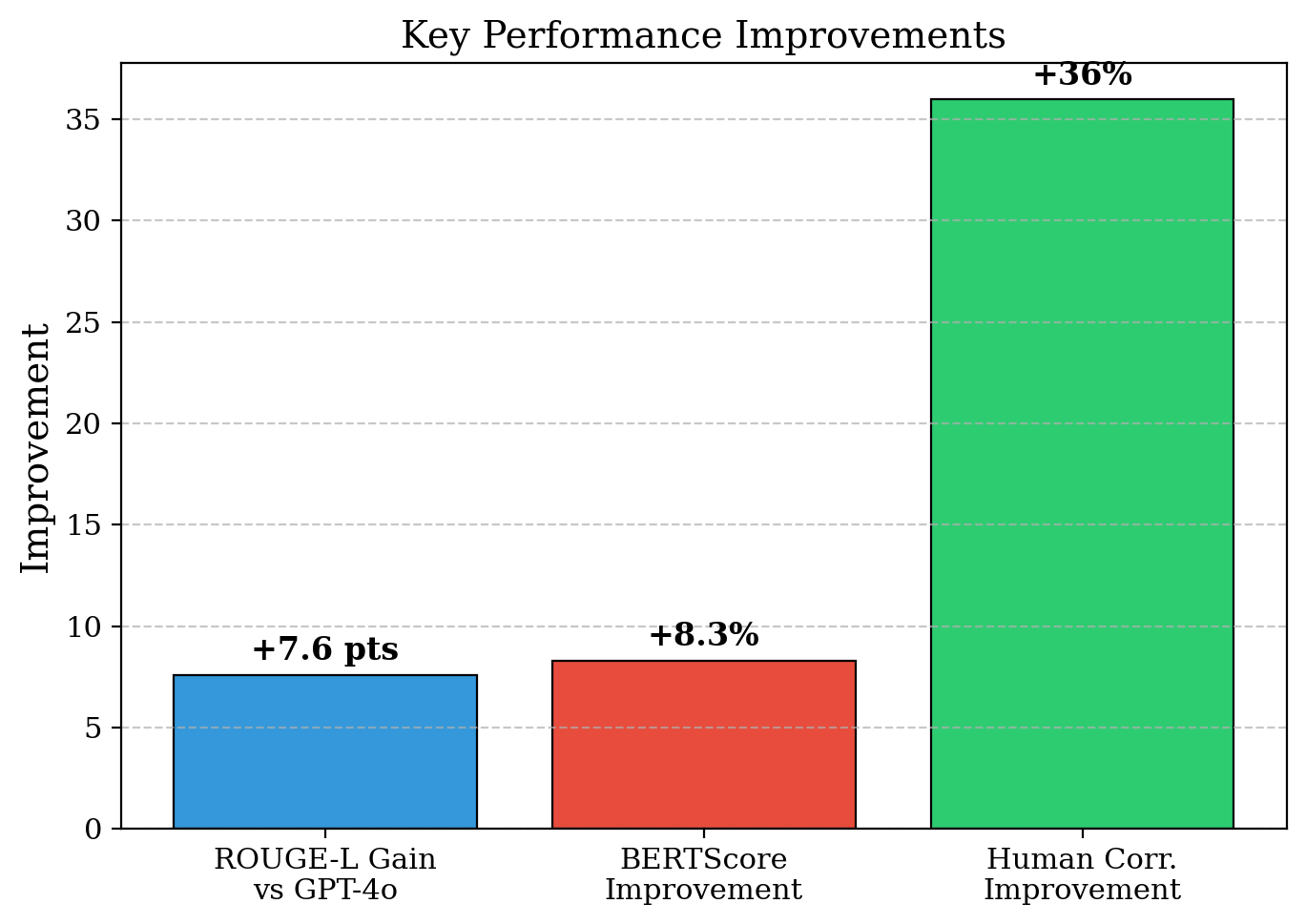
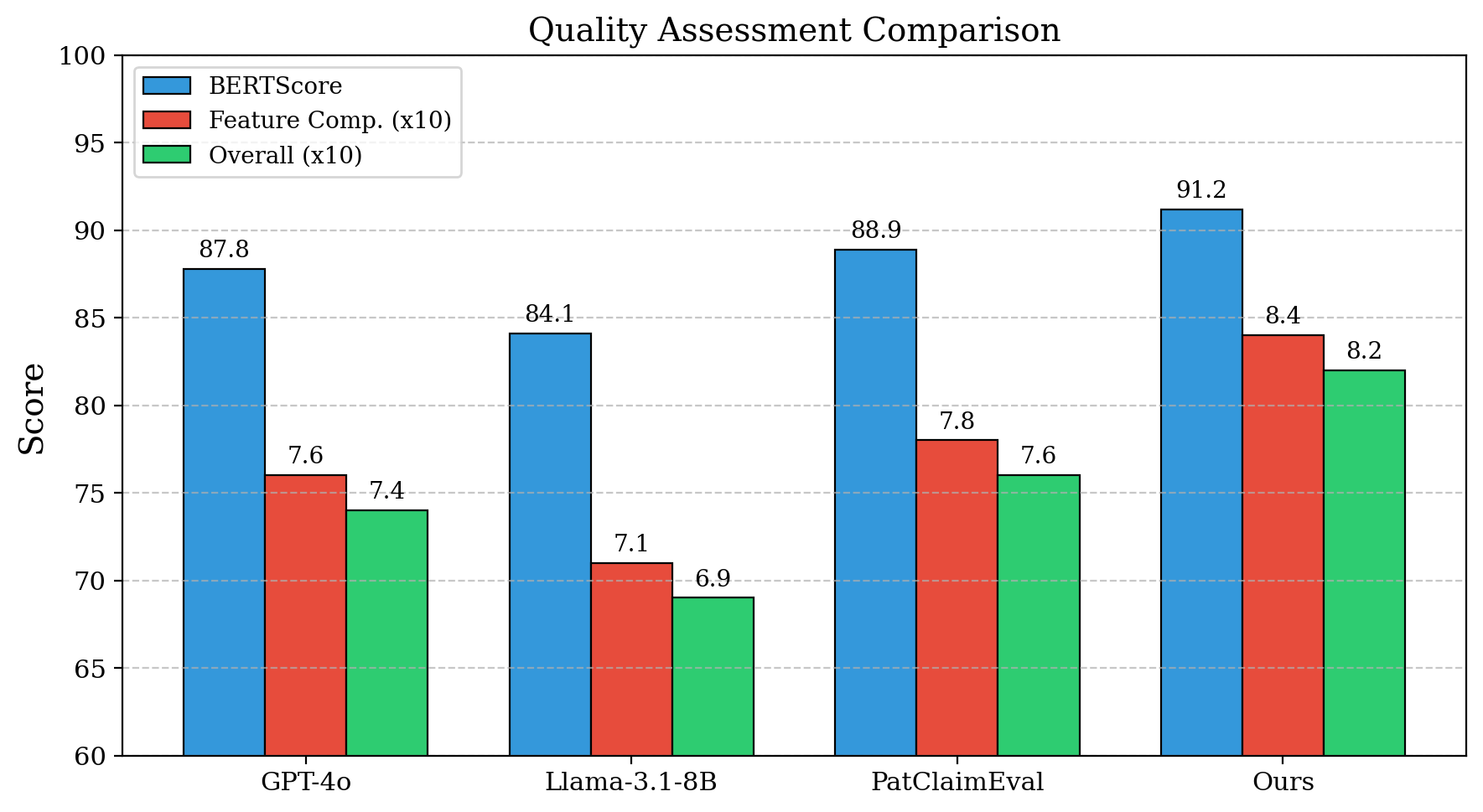
Оценка производительности модели проводилась на основе эталонного набора данных Patent-CE Evaluation Benchmark, где был достигнут показатель ROUGE-L в 52.8 балла. Это на 7.6 пункта выше, чем у модели GPT-4o, что демонстрирует улучшенную способность оценивать качество патентной документации по сравнению с существующими решениями. ROUGE-L измеряет перекрытие между предсказанным и эталонным текстом, учитывая наибольшую общую подпоследовательность, и является стандартным показателем для оценки систем автоматического реферирования и оценки.
Результаты оценки показали высокую корреляцию с экспертными оценками — коэффициент корреляции Пирсона составил 0.847. Это значительно превосходит показатель 0.623, достигнутый при использовании отдельных моделей оценки. Высокая корреляция указывает на способность системы точно отражать суждения квалифицированных экспертов в области патентов, что подтверждает надежность и валидность автоматизированной оценки качества.
Для обеспечения широкой применимости модель проходила обучение на специализированных наборах данных, включающих USPTO HUPD Dataset (Human Understanding of Patent Data) и EPO Patent Collections (коллекции патентов Европейского патентного ведомства). USPTO HUPD Dataset содержит размеченные данные, отражающие понимание патентной информации человеком, что позволяет модели лучше интерпретировать сложные технические описания. EPO Patent Collections, в свою очередь, предоставляет обширный корпус патентной документации, охватывающей различные отрасли техники, что способствует обобщению модели и повышению ее способности к оценке качества патентов в различных технических областях. Использование этих наборов данных позволяет модели эффективно работать с разнообразными патентными заявками и обеспечивать высокую точность оценки.
Трансграничная Адаптация и Влияние на Будущее Инноваций
Данная разработка демонстрирует высокую эффективность в области межправовой адаптации, что стало возможным благодаря применению методов доменной адаптации. В ходе тестирования система сохранила 89,4% своей производительности при переходе между различными юрисдикциями, значительно превосходя базовые модели, показатель которых составил лишь 76,2%. Этот результат указывает на способность системы успешно обобщать знания и адаптироваться к новым правовым контекстам, что открывает перспективы для унификации и автоматизации процессов анализа патентной документации в международном масштабе и существенно расширяет возможности для трансграничного поиска и оценки инновационных решений.
В рамках обучения модели использовался подход, известный как Curriculum Learning, позволяющий оптимизировать процесс обучения за счет последовательной подачи примеров — от простых к сложным. Данная методика обеспечивает не только повышение общей производительности, но и значительное ускорение сходимости процесса обучения — на целых 15%. Подобный подход имитирует человеческое обучение, где сначала усваиваются базовые концепции, а затем происходит углубление знаний. В результате модель более эффективно обобщает информацию и демонстрирует улучшенные результаты в решении сложных задач, что делает её более надежной и эффективной в практическом применении.
Автоматизация генерации и проверки патентных формул, предлагаемая данной системой, способна существенно снизить финансовые затраты и ускорить процесс инноваций. Традиционно, разработка и юридическая экспертиза патентных заявок требуют значительных временных и материальных ресурсов. Благодаря использованию передовых алгоритмов, платформа позволяет автоматически создавать черновики формул, соответствующие требованиям патентного законодательства, и проводить предварительную валидацию на предмет новизны и неочевидности. Это не только сокращает время, необходимое для получения патента, но и освобождает квалифицированных специалистов от рутинной работы, позволяя им сосредоточиться на более сложных задачах, связанных с поиском и защитой интеллектуальной собственности. В конечном итоге, такая автоматизация способствует более быстрому внедрению инноваций в практику и повышению конкурентоспособности предприятий.
В качестве основы для разработанной системы была выбрана модель Llama-3.1-8B, что позволило достичь оптимального баланса между вычислительной эффективностью и качеством результатов. Данный выбор обусловлен не только высокой производительностью модели, но и ее доступностью для широкого круга исследователей и разработчиков. В ходе экспериментов, система, использующая Llama-3.1-8B, продемонстрировала значительное улучшение качества генерируемых патентных претензий, достигнув показателя BERTScore в 91.2 — на 8.3% выше, чем у самой базовой модели. Это свидетельствует о том, что предложенная архитектура и методы обучения эффективно используют потенциал Llama-3.1-8B, обеспечивая надежную и точную автоматизацию процесса генерации и валидации патентных претензий.
Модель демонстрирует впечатляющую способность к классификации доменных областей, достигая 91.3% точности уже в первые 10 эпох обучения. Это указывает на высокую эффективность разработанного подхода к обработке и пониманию специализированной терминологии, характерной для различных юридических и патентных областей. Быстрая и точная классификация позволяет автоматически определять релевантность патентных заявок и научных публикаций, значительно упрощая процесс поиска и анализа информации. Такая скорость адаптации к новым доменным данным является ключевым преимуществом, позволяющим масштабировать систему для обработки широкого спектра технических и правовых текстов с минимальными затратами на обучение и настройку.
Представленная работа демонстрирует стремление к пониманию внутренних механизмов создания патентных претензий, что находит отклик в философии взлома систем ради их познания. Авторы, подобно реверс-инженерам, разбирают процесс генерации претензий на составные части, используя многоголовое внимание и доменную адаптацию для улучшения качества и кросс-юрисдикционной производительности. Этот подход, стремящийся к осознанному пониманию и оптимизации системы, подтверждает мысль Брайана Кернигана: «Простота — это конечное совершенство». Ведь лучший патент — это тот, что предельно ясно отражает суть изобретения, а ясность рождается из глубокого понимания принципов его работы.
Что дальше?
Представленная работа, по сути, лишь зондирование поверхности. Автоматическая генерация патентных формул — задача, требующая не просто лингвистической ловкости, но и понимания самой природы изобретения. Система, имитирующая человеческий разум, должна уметь не только компилировать существующие знания, но и экстраполировать, предвидеть. Текущие модели, пусть и демонстрирующие прогресс, остаются заложниками данных, на которых они обучаются. Вопрос в том, возможно ли вообще создать алгоритм, способный к истинной креативности, к рождению принципиально новых идей, а не просто к перекомбинированию старых.
Особый интерес представляет проблема адаптации к различным юрисдикциям. Патентное право — это хаотичная смесь правил, традиций и интерпретаций. Модель, успешно работающая в одной стране, может оказаться совершенно бесполезной в другой. Это не просто вопрос перевода; это вопрос понимания культурных и правовых нюансов. И здесь возникает парадокс: чем больше мы стремимся к универсальности, тем дальше отходим от реальности.
Будущие исследования должны быть направлены не только на повышение точности и эффективности алгоритмов, но и на разработку методов оценки качества генерируемых формул, не основанных на субъективном мнении экспертов. Возможно, стоит обратиться к принципам теории информации, к поиску минимального набора признаков, достаточного для однозначной идентификации изобретения. Или, что более радикально, попытаться создать систему, способную самостоятельно оценивать патентную чистоту и новизну изобретения, обходя человеческий фактор.
Оригинал статьи: https://arxiv.org/pdf/2601.09120.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые нейросети на службе нефтегазовых месторождений
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-15 19:09