Автор: Денис Аветисян
Исследователи представили QTabGAN — гибридную квантово-классическую модель, способную генерировать синтетические данные, превосходящие существующие методы по качеству и реалистичности.
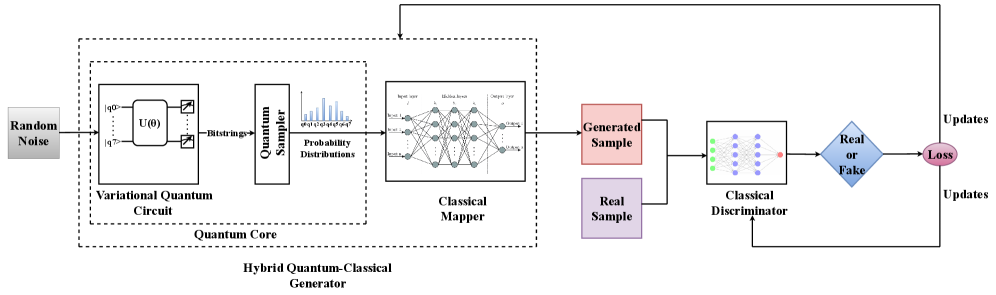
QTabGAN — это новый генеративный состязательный алгоритм, использующий вариационные квантовые схемы для улучшения конфиденциальности и полезности табличных данных.
Синтез реалистичных табличных данных представляет собой сложную задачу из-за разнородности типов признаков и высокой размерности. В настоящей работе представлена модель QTabGAN: гибридная квантово-классическая генеративно-состязательная сеть, специально разработанная для синтеза табличных данных в условиях ограниченного объема реальных данных или строгих требований к конфиденциальности. Эксперименты демонстрируют, что QTabGAN превосходит современные генеративные модели, достигая улучшения до 54.07% на различных классификационных датасетах, и подтверждает перспективность использования квантовых вычислений для повышения качества и конфиденциальности синтетических данных. Сможет ли данный подход стать основой для создания масштабируемых решений в области конфиденциального анализа данных и машинного обучения?
Разоблачение парадокса данных: вызов системе
Растущий спрос на данные в машинном обучении сталкивается со значительными препятствиями, обусловленными проблемами конфиденциальности и ограниченным доступом к реальным наборам данных. Многие организации располагают ценной информацией, необходимой для обучения сложных моделей, однако боятся её раскрытия из-за строгих правил защиты персональных данных и опасений, связанных с возможными утечками. Это создает парадокс: для достижения прогресса в области искусственного интеллекта требуются большие объемы данных, но получение доступа к этим данным часто ограничено или невозможно. В результате, разработчики сталкиваются с трудностями при создании и обучении эффективных моделей, что замедляет развитие технологий и ограничивает их потенциальное применение в различных сферах, от медицины до финансов.
Традиционные методы увеличения объема данных, такие как незначительные модификации существующих образцов, зачастую оказываются неэффективными при обучении сложных моделей машинного обучения. Простые преобразования, вроде поворотов изображений или добавления шума, могут не отражать реальное разнообразие данных, необходимое для достижения высокой точности и обобщающей способности. Более того, возникает вопрос о полезности таких искусственно созданных данных: действительно ли они способствуют улучшению модели или лишь вводят в заблуждение, приводя к переобучению и снижению надежности прогнозов. Особенно остро эта проблема проявляется в задачах, требующих высокой детализации и учета сложных взаимосвязей между признаками, где поверхностные изменения данных оказываются недостаточными для формирования адекватного представления о реальности.
В условиях растущего спроса на данные для обучения моделей машинного обучения, проблема конфиденциальности и ограниченный доступ к реальным наборам данных становятся все более актуальными. Хотя традиционные методы аугментации данных могут оказаться недостаточными для сложных моделей, а также вызывают вопросы относительно полезности генерируемых данных, синтетические данные представляют собой перспективное решение. Однако, для эффективного использования синтетических данных, необходимо разрабатывать методы, способные сохранять как точность, так и статистические свойства исходных данных. Существующие подходы часто не справляются с этой задачей, оставляя значительный пробел в возможностях генерации высококачественных синтетических наборов, который и призван восполнить QTabGAN.
Квантовый прорыв: новая парадигма генерации данных
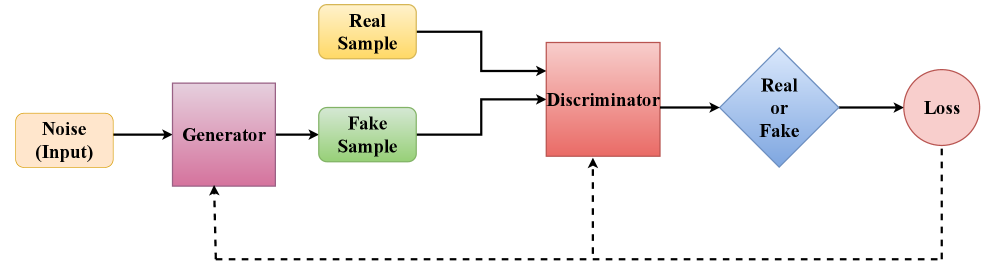
Генеративно-состязательные сети (GAN) представляют собой мощный фреймворк для изучения распределений данных и генерации синтетических образцов. В основе GAN лежит состязательный процесс между двумя нейронными сетями: генератором и дискриминатором. Генератор стремится создавать данные, неотличимые от реальных, в то время как дискриминатор пытается отличить сгенерированные данные от реальных. Этот процесс обучения, основанный на теории игр, позволяет GAN моделировать сложные распределения данных и генерировать новые образцы, которые сохраняют статистические свойства исходных данных. GAN находят применение в различных областях, включая генерацию изображений, видео, текста и других типов данных, а также для задач аугментации данных и обучения без учителя.
Квантовые генеративно-состязательные сети (GAN) используют принципы квантовой суперпозиции и запутанности для потенциального преодоления ограничений классических GAN в моделировании сложных данных. Суперпозиция позволяет квантовым битам (кубитам) представлять несколько состояний одновременно, что теоретически расширяет пространство поиска и позволяет более эффективно захватывать сложные зависимости в данных. Запутанность, в свою очередь, создает корреляции между кубитами, которые могут быть использованы для моделирования взаимосвязей между различными признаками в данных. В отличие от классических GAN, где генератор и дискриминатор представлены классическими нейронными сетями, квантовые GAN используют квантовые схемы для реализации этих функций, что позволяет им потенциально моделировать более сложные распределения данных и генерировать более реалистичные синтетические образцы. |\psi\rangle = \alpha|0\rangle + \beta|1\rangle — пример описания состояния кубита в суперпозиции.
Квантовые генеративно-состязательные сети (QGAN) демонстрируют потенциал для повышения эффективности и точности генерации синтетических данных, особенно в отношении табличных данных. Реализация QTabGAN, в частности, показала превосходство над классическими и другими квантовыми моделями в задачах генерации, что подтверждается результатами сравнительного анализа метрик качества синтезированных данных. Данные результаты указывают на возможность более эффективного моделирования сложных распределений данных с использованием квантовых преимуществ, таких как суперпозиция и запутанность, в сравнении с классическими подходами.
Гибридные и полностью квантовые подходы к синтезу табличных данных
QTabGAN использует гибридную квантово-классическую архитектуру для эффективной генерации синтетических данных. В ее основе лежит комбинация вариационных квантовых схем и классических нейронных сетей. Квантовые схемы отвечают за извлечение и моделирование сложных нелинейных зависимостей в данных, в то время как классические нейронные сети обеспечивают масштабируемость и оптимизацию процесса генерации. Такой подход позволяет QTabGAN эффективно работать с табличными данными, сохраняя при этом преимущества квантовых вычислений в представлении сложных взаимосвязей.
TabularQGAN представляет собой подход к синтезу табличных данных, использующий полностью квантовый генератор. Целью разработки является максимальное использование преимуществ квантовых вычислений для создания синтетических данных, имитирующих распределение исходного набора. В отличие от гибридных моделей, TabularQGAN стремится реализовать все этапы генерации данных с использованием квантовых алгоритмов, что потенциально позволяет достичь более высокой эффективности и точности моделирования сложных зависимостей в данных. Исследования в данной области направлены на оптимизацию квантовых схем и алгоритмов для решения задачи генерации табличных данных и демонстрацию превосходства над классическими и гибридными подходами.
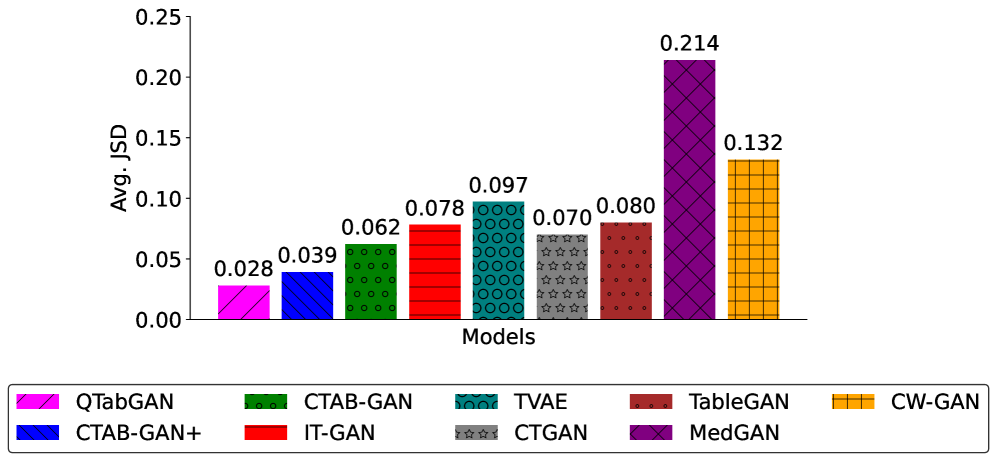
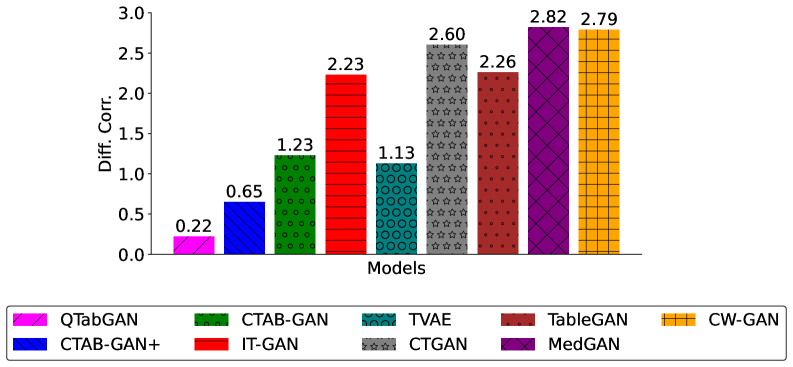
Оба метода, QTabGAN и TabularQGAN, демонстрируют способность к генерации синтетических данных высокого качества, что подтверждается использованием метрик, таких как Расхождение Дженсена-Шеннона (JSD) и Разница Корреляции. В частности, QTabGAN достигает значения JSD равного 0.028, что обеспечивает снижение расхождения на 54.84% по сравнению с классическим алгоритмом CTAB-GAN. Данный показатель свидетельствует о значительном улучшении точности и достоверности генерируемых синтетических данных, приближая их характеристики к реальным данным.
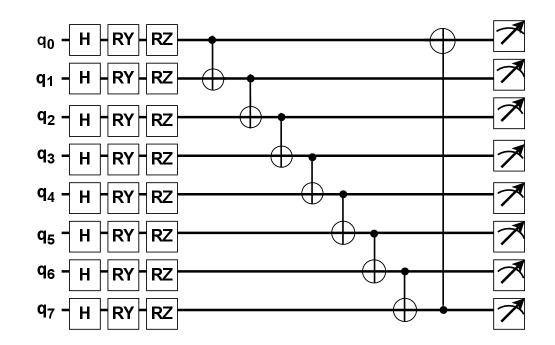
Практические аспекты и горизонты будущего
Архитектура QTabGAN спроектирована с учетом ограничений и возможностей квантовых устройств промежуточного масштаба (NISQ), что делает её особенно привлекательной для практической реализации в ближайшем будущем. В отличие от многих других генеративных моделей, требующих ресурсов, недоступных на текущих квантовых компьютерах, QTabGAN использует относительно простые квантовые схемы и операции. Такой подход позволяет использовать преимущества квантовых вычислений для синтеза данных, даже в условиях ограниченной квантовой мощности и высокого уровня шума, характерных для NISQ-устройств. Это открывает возможности для применения QTabGAN в различных областях, где требуется генерация синтетических данных для обучения моделей машинного обучения, и делает её перспективным решением для задач, требующих конфиденциальности и защиты данных.
Оценка качества сгенерированных синтетических данных, выполненная с использованием метрик точности (Accuracy) и F1-меры, демонстрирует их высокую применимость для задач машинного обучения. В ходе экспериментов QTabGAN показал незначительное отклонение в точности — всего 2.16% — по сравнению с исходными данными, что значительно превосходит показатели CTAB-GAN+, уступающего QTabGAN на 58.7%. Аналогично, разница в значениях F1-меры составила 0.048, что на 46.7% выше, чем у CTAB-GAN+. Эти результаты указывают на то, что QTabGAN способен генерировать синтетические данные, практически неотличимые от реальных, обеспечивая высокую эффективность в задачах машинного обучения и открывая новые возможности для работы с конфиденциальной информацией.
Перспективные исследования в области квантового синтеза данных должны быть направлены на повышение масштабируемости и устойчивости разработанных методов. Особое внимание следует уделить разработке новых квантовых алгоритмов, способных эффективно генерировать синтетические данные для табличных данных, преодолевая ограничения существующих подходов. Улучшение масштабируемости позволит применять эти методы к более крупным и сложным наборам данных, в то время как повышение устойчивости обеспечит надежность генерируемых данных даже при наличии шумов и ошибок, характерных для современных квантовых устройств. Дальнейшее исследование возможностей квантовых алгоритмов может привести к созданию принципиально новых подходов к синтезу данных, открывая новые горизонты для применения в различных областях, включая машинное обучение и анализ данных.
Исследование, представленное в данной работе, демонстрирует смелый подход к синтезу табличных данных, сочетающий классические алгоритмы генеративных состязательных сетей (GAN) с возможностями квантовых вычислений. Авторы не просто следуют установленным протоколам, но и подвергают их проверке, стремясь понять, как квантовые схемы могут улучшить качество генерируемых данных и обеспечить повышенную конфиденциальность. Как однажды заметил Линус Торвальдс: «Если у вас нет времени на автоматизацию, у вас найдется время на отладку.» Этот принцип применим и здесь: сложность квантово-классического подхода оправдывается потенциальным улучшением результатов и снижением рисков, связанных с приватностью данных. Разработка QTabGAN подтверждает, что понимание системы — в данном случае, взаимодействия квантовых и классических компонентов — является ключом к созданию более эффективных и надежных решений в области машинного обучения.
Что дальше?
Представленная работа, хотя и демонстрирует перспективность гибридных квантово-классических генеративных моделей для синтеза табличных данных, лишь приоткрывает дверь в сложный мир. Вопрос не в том, насколько хорошо QTabGAN превосходит существующие алгоритмы — правила существуют, чтобы их проверять. Настоящая задача заключается в понимании фундаментальных ограничений, накладываемых как квантовой, так и классической составляющими системы. Недостаточно просто генерировать данные, похожие на исходные; необходимо понять, что именно в этих данных несет в себе информацию, а что — лишь шум, и как квантовые алгоритмы могут помочь отделить одно от другого.
Очевидным направлением для дальнейших исследований является расширение масштабируемости и устойчивости QTabGAN к различным типам табличных данных. Однако, более глубокий вопрос — это разработка теоретической базы, позволяющей предсказывать, когда и при каких условиях квантовые генеративные модели действительно могут превзойти классические. Понимание этого требует не только усовершенствования алгоритмов, но и ревизии самого подхода к синтезу данных, переосмысления понятия «правдоподобия» в контексте квантовых вычислений.
В конечном счете, успех подобных моделей будет определяться не только их техническими характеристиками, но и способностью обеспечить реальную приватность данных. Истинная безопасность — это прозрачность, а не обфускация. Необходимо разработать строгие метрики и методы верификации, гарантирующие, что синтетические данные не раскрывают конфиденциальную информацию об исходных данных. Задача не в том, чтобы скрыть, а в том, чтобы понять, что именно скрывается.
Оригинал статьи: https://arxiv.org/pdf/2602.12704.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовая телепортация в новых измерениях: топологические изоляторы
- Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Цифровые улики под присмотром ИИ: новая эра криминалистики?
- Стратегия подцелей: Как научить ИИ долгосрочному планированию
2026-02-16 07:09