Автор: Денис Аветисян
Новое исследование показывает, что современные языковые модели склонны переоценивать соответствие документов запросам, даже когда реальная релевантность невелика.
Работа посвящена анализу систематической переоценки релевантности документов большими языковыми моделями при оценке информационного поиска, выявляя чувствительность к поверхностным признакам и ограниченное семантическое понимание.
Оценка релевантности информационного поиска традиционно требует значительных временных и когнитивных затрат. В работе ‘When LLM Judges Inflate Scores: Exploring Overrating in Relevance Assessment’ исследуется проблема систематической переоценки релевантности при использовании больших языковых моделей (LLM) в качестве замены экспертам-людям. Полученные результаты демонстрируют, что LLM склонны к завышению оценок релевантности документов, часто основываясь на поверхностных признаках, таких как длина текста и совпадение ключевых слов, что указывает на ограниченное семантическое понимание. Не ставит ли это под сомнение возможность использования LLM для автоматизированной оценки релевантности и не требует ли это разработки новых методов диагностической оценки их надежности?
Традиции и Пророчества: Оценка Релевантности в Информационном Потоке
Традиционно, оценка релевантности информации в системах поиска осуществлялась кропотливым ручным анализом, выполняемым экспертами-людьми. Этот процесс, хоть и являющийся основой для создания «золотых стандартов» оценки, таких как используемые в рамках TREC DL Track, требует значительных временных и финансовых затрат. Каждая единица информации должна быть тщательно просмотрена и оценена человеком, что становится особенно проблематичным при работе с огромными объемами данных, характерными для современного информационного пространства. Подобный подход, будучи необходимым для первоначальной калибровки и оценки автоматизированных систем, в перспективе ограничивает масштабируемость и эффективность поиска, создавая узкое место в развитии информационных технологий.
В основе оценки эффективности систем автоматического поиска информации лежат так называемые “золотые стандарты” релевантности, создаваемые экспертами. Примером таких стандартов служит работа в рамках трека TREC DL, где квалифицированные специалисты тщательно анализируют большие объемы данных, определяя, насколько полно и точно поисковые системы отвечают на поставленные запросы. Эти экспертные оценки служат эталоном, с которым сравниваются результаты работы автоматизированных алгоритмов, позволяя объективно измерить их производительность и выявить области для улучшения. Именно благодаря этим тщательно выверенным суждениям стало возможным количественно оценить прогресс в области информационного поиска и разработать более совершенные системы, способные эффективно обрабатывать и анализировать огромные потоки данных.
Традиционный подход к оценке релевантности информации, основанный на кропотливой ручной работе экспертов, сталкивается с принципиальными ограничениями. Во-первых, масштабируемость такого метода крайне низка: обработка больших объемов данных требует огромных временных и финансовых затрат. Во-вторых, субъективность человеческого восприятия неизбежно влияет на оценки, что приводит к расхождениям между экспертами и снижает надежность “золотого стандарта”. Даже при использовании четких инструкций, личный опыт и предпочтения каждого оценщика оказывают влияние, создавая погрешность и затрудняя объективное сравнение различных систем автоматического поиска информации. В результате, полагаясь исключительно на человеческие оценки, сложно достичь высокой степени достоверности и воспроизводимости результатов, что препятствует прогрессу в области информационного поиска.
Необходимость в более эффективных и объективных методах оценки релевантности представляется критически важной задачей в современном информационном поиске. Традиционные подходы, основанные на кропотливой ручной оценке экспертов, становятся узким местом при обработке растущих объемов данных и не позволяют оперативно тестировать новые алгоритмы. Существующие “золотые стандарты” зачастую отражают субъективные представления оценивающих, что вносит искажения в результаты и затрудняет сравнение различных систем. Разработка автоматизированных метрик, способных быстро и беспристрастно определять соответствие между запросом и документом, является ключевым шагом к созданию более интеллектуальных и адаптивных поисковых систем, способных удовлетворять постоянно меняющиеся потребности пользователей.
Языковые Модели как Судьи: Обещающее, но Несовершенное Решение
Использование больших языковых моделей (LLM) для автоматической оценки релевантности представляется перспективным решением для повышения эффективности обработки информации. Традиционно, оценка релевантности требует значительных трудозатрат, поскольку выполняется людьми-экспертами. LLM способны генерировать оценки релевантности автоматически, что позволяет существенно сократить время и ресурсы, необходимые для анализа больших объемов данных. Этот подход особенно актуален в задачах, связанных с поиском информации, фильтрацией контента и построением систем рекомендаций, где требуется быстрая и точная оценка соответствия документов запросам пользователей.
Фреймворки, такие как UMBRELA, предназначены для автоматизации процесса создания масштабных размеченных наборов данных, необходимых для обучения и оценки моделей оценки релевантности. Они предоставляют инструменты для генерации запросов, извлечения релевантных документов и последующей аннотации этих данных, позволяя значительно ускорить и удешевить процесс подготовки обучающих выборок. UMBRELA поддерживает различные методы аннотации, включая ручную разметку экспертами и автоматическую разметку с использованием предварительно обученных моделей, обеспечивая гибкость и масштабируемость в зависимости от требований конкретной задачи. Основной целью является создание больших объемов высококачественных данных, пригодных для обучения моделей, способных автоматически оценивать релевантность документов по отношению к заданным запросам.
Оценка релевантности с использованием больших языковых моделей (LLM) использует как точечный (pointwise), так и попарный (pairwise) подходы к оценке. Точечная оценка предполагает присвоение каждому документу отдельной оценки релевантности, независимо от других документов. Попарная оценка, напротив, предполагает сравнение двух документов и определение, какой из них более релевантен запросу. Комбинирование этих двух парадигм позволяет получить более точную и надежную оценку релевантности, учитывая как абсолютные характеристики документа, так и его относительное положение по отношению к другим документам в контексте конкретного запроса.
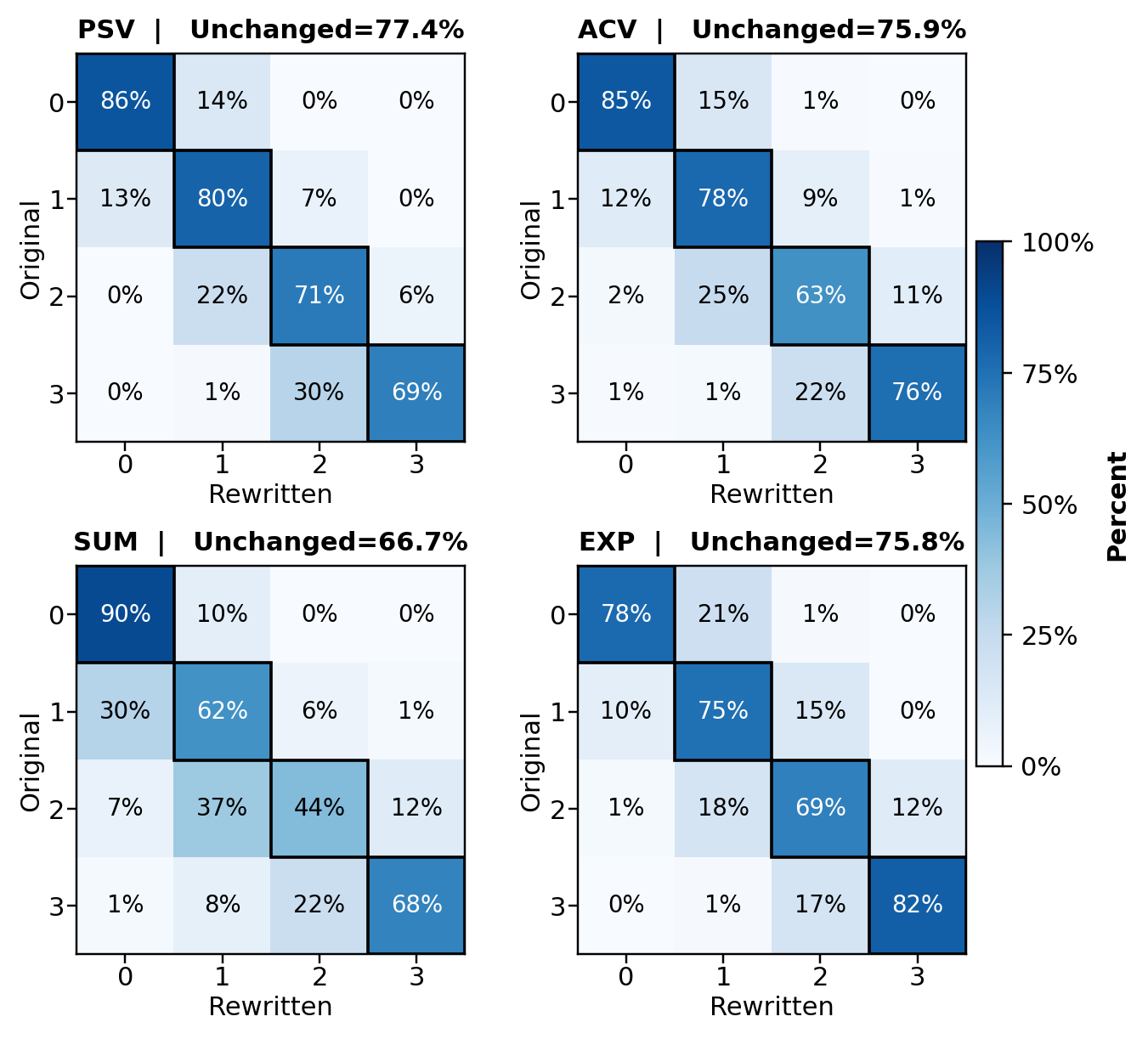
При использовании больших языковых моделей (LLM) для оценки релевантности наблюдается тенденция к завышению оценок по сравнению с оценками, выставляемыми людьми. Исследования показывают, что коэффициент завышения оценок (overrate ratio) варьируется от 18.57% до 51.11% в зависимости от конкретной используемой модели. Данное смещение требует проведения калибровки LLM для корректировки оценок и приведения их в соответствие с человеческими суждениями, что необходимо для обеспечения точности и надежности автоматизированной оценки релевантности.
Разбирая Суждения LLM: Отрывок, Голос и Уверенность
Эффективность больших языковых моделей (LLM) напрямую зависит от характеристик оцениваемых фрагментов текста, при этом длина фрагмента играет ключевую роль. Анализ показывает, что LLM демонстрируют снижение производительности при оценке более длинных текстов, что связано с увеличением вычислительной сложности и потенциальными ошибками при обработке больших объемов информации. Более короткие фрагменты, как правило, оцениваются более точно и последовательно, что указывает на то, что длина текста является важным фактором, который необходимо учитывать при разработке и применении LLM в задачах оценки и анализа текста.
Грамматическое построение текста, в частности использование активного или пассивного залога, оказывает влияние на суждения языковых моделей (LLM). Исследования показывают, что LLM демонстрируют различную производительность при оценке текстов, написанных в активном и пассивном залоге. Пассивный залог может приводить к снижению точности оценки, поскольку требует от модели более сложного анализа для определения субъекта и его действий. Различия в оценках, связанные с залогом, необходимо учитывать при разработке и применении LLM в задачах оценки текста, особенно когда требуется высокая степень объективности и согласованности.
Уровень уверенности модели, в частности, уверенность на уровне отдельных токенов (Token-Level Confidence), предоставляет ценную информацию о степени достоверности оценки, которую выдает языковая модель. Этот показатель позволяет оценить, насколько модель уверена в каждом конкретном элементе своего ответа или суждения. Анализ уверенности на уровне токенов может выявить области текста, в которых модель испытывает затруднения или неопределенность, что, в свою очередь, позволяет улучшить качество и надежность ее оценок. Высокая уверенность на уровне токенов обычно коррелирует с более точными и обоснованными суждениями, в то время как низкая уверенность может указывать на потенциальные ошибки или необходимость дополнительной проверки.
Оценка качества, выполненная большими языковыми моделями (LLM) в задачах с градациями (например, оценка по шкале) демонстрирует более низкие значения коэффициента Коэна κ по сравнению с бинарной оценкой (например, «да/нет»). В задачах попарного сравнения точности моделей наблюдается уровень ничьих (одинаковой оценки для обоих вариантов) от 24% до 45%. Однако, при исключении ничьих из анализа, точность моделей в попарном сравнении повышается до 85-93%, что указывает на способность моделей к различению вариантов, когда однозначного лидера нет.
Прощупывая Поведение LLM: Зависимая Вставка и Семантическая Верификация
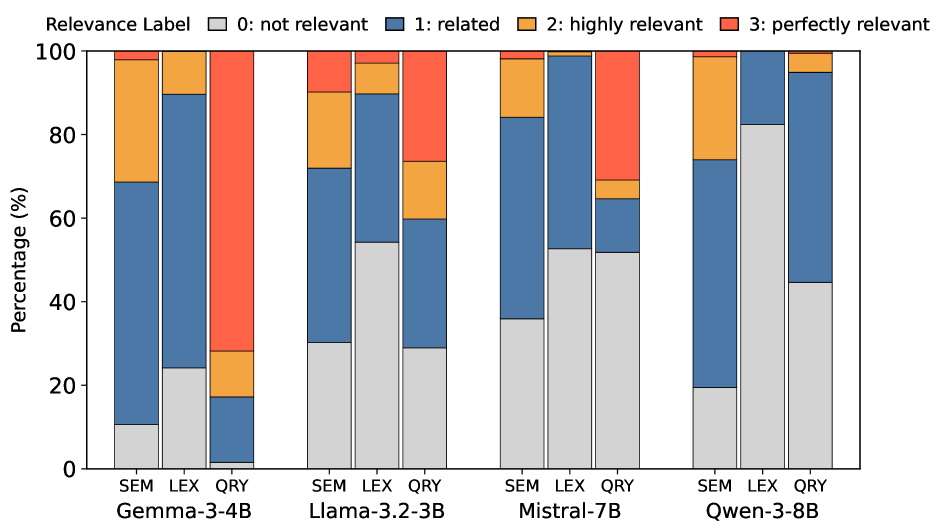
Метод зависимой вставки запросов позволяет проводить контролируемые эксперименты, добавляя предложения в тексты, не имеющие к ним отношения, чтобы проверить, насколько чувствительна большая языковая модель к контексту. Данный подход позволяет намеренно нарушать семантическую согласованность, что, в свою очередь, дает возможность оценить способность модели выявлять и реагировать на несоответствия. По сути, это контролируемое введение «шума» в текст, позволяющее исследователям определить, насколько надежно модель отделяет релевантную информацию от нерелевантной, и как это влияет на ее рассуждения и ответы. Такой подход способствует выявлению скрытых предубеждений и уязвимостей в процессе принятия решений языковой моделью, а также помогает оценить ее устойчивость к манипуляциям и искажению информации.
Применение метода контролируемой вставки предложений в нерелевантные отрывки текста позволяет выявить скрытые предубеждения и уязвимости в процессе рассуждений больших языковых моделей. Данный подход позволяет искусственно создавать ситуации, в которых модель должна оценить согласованность и релевантность информации, тем самым обнажая склонность к определенным шаблонам мышления или предвзятости. Анализ реакций модели на намеренно искаженные данные помогает понять, насколько критически она оценивает информацию и способна ли отличать правдоподобные, но не соответствующие контексту утверждения, от логически обоснованных заключений. Таким образом, данный метод является ценным инструментом для оценки надежности и объективности языковых моделей, а также для разработки стратегий по смягчению потенциальных рисков, связанных с их применением.
Для обеспечения достоверности экспериментов по исследованию поведения больших языковых моделей, используется Gemini-2.5-Flash для верификации семантической целостности текста. В процессе намеренного добавления предложений в нерелевантные отрывки, эта модель оценивает, насколько внесенные изменения влияют на исходный смысл. Gemini-2.5-Flash выступает в роли своеобразного «арбитра», подтверждая, что добавленные предложения не искажают первоначальную информацию и не вносят нежелательных смысловых сдвигов. Такой подход позволяет с высокой степенью уверенности изолировать влияние манипулированного текста на ответы языковой модели, выявляя потенциальные уязвимости и предвзятости в процессе рассуждений.
Модели Gemma продемонстрировали высокую степень уверенности в правильной оценке пар предложений, достигнув показателя 0.979 при верных суждениях против 0.964 при ошибочных. Данный результат позволяет предположить наличие у модели определенного уровня самооценки и способности к анализу собственной логики. Особенно примечательно, что уверенность модели превышает 0.95 в 75% случаев, когда оценки оказываются одинаковыми, что указывает на высокую степень убежденности даже в неоднозначных ситуациях и свидетельствует о способности модели к тонкому различению нюансов смысла.
Исследование показывает, что большие языковые модели склонны к завышению релевантности документов, ориентируясь на поверхностные признаки вроде длины отрывка и совпадения ключевых слов. Это явление напоминает о сложности истинного семантического понимания и необходимости критического подхода к оценке систем информационного поиска. Как однажды заметил Давид Гильберт: «В конечном счете, мы должны требовать от математики не только точности, но и истины». Подобно тому, как математика стремится к истине, так и оценка релевантности должна выходить за рамки поверхностных совпадений и учитывать глубинный смысл информации. Зависимости, которые строятся на неверных оценках, подобны обещаниям прошлого, которые не могут быть выполнены в будущем.
Что дальше?
Представленная работа выявляет не склонность к ошибкам, а закономерность в поведении больших языковых моделей при оценке релевантности. Иллюзия понимания, создаваемая кажущейся связностью текста, оказывается хрупкой, подверженной влиянию поверхностных признаков. Настоящая устойчивость системы оценки не в устранении этих эффектов, а в осознании их неизбежности. Мониторинг становится не средством предотвращения сбоев, а способом бояться осознанно.
Полагаться на LLM как на беспристрастных судей — значит игнорировать природу любой системы: каждая архитектурная особенность — это пророчество о будущем сбое. Вместо того, чтобы стремиться к идеальной метрике, следует признать, что оценка релевантности — это всегда интерпретация, всегда субъективная, даже если она замаскирована под объективность алгоритма. Ключевой вопрос не в том, как «исправить» LLM, а в том, как построить экосистему оценки, способную адаптироваться к этим предсказуемым отклонениям.
Будущие исследования должны сосредоточиться не на улучшении «понимания» LLM, а на разработке методов обнаружения и смягчения влияния поверхностных признаков. Необходимо переосмыслить саму концепцию релевантности, признав ее контекстуальность и изменчивость. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить.
Оригинал статьи: https://arxiv.org/pdf/2602.17170.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок: от лаборатории к рынку
2026-02-23 00:14