Автор: Денис Аветисян
Новая система объединяет возможности больших языковых моделей с принципами физики для автоматического выявления интерпретируемых уравнений из научных данных.
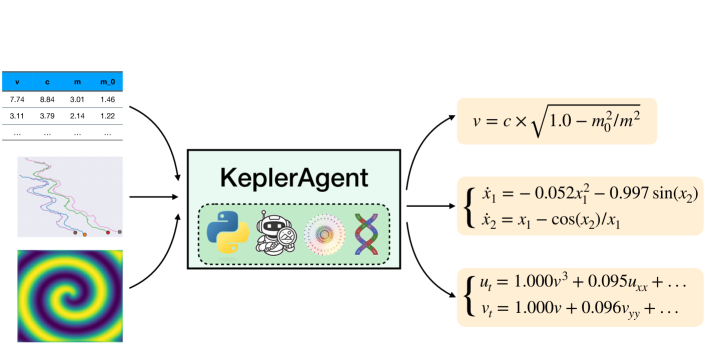
Представлен KeplerAgent — фреймворк, использующий LLM-агентов и методы физически обоснованного машинного обучения для автоматического обнаружения уравнений, превосходящий традиционную символьную регрессию и существующие LLM-подходы.
Поиск интерпретируемых формул для объяснения наблюдаемых явлений остаётся фундаментальной задачей науки, но существующие подходы часто упускают из виду многоступенчатый процесс, свойственный научному мышлению. В статье ‘Think like a Scientist: Physics-guided LLM Agent for Equation Discovery’ представлен KeplerAgent — агентский фреймворк, который эмулирует этот процесс, используя физически обоснованные инструменты для выявления промежуточных структур и последующей настройки алгоритмов символьной регрессии, таких как PySINDy и PySR. Полученные результаты демонстрируют, что KeplerAgent превосходит как традиционные методы, так и другие LLM-системы по точности и устойчивости к шуму. Способен ли этот подход автоматизировать научные открытия и значительно ускорить прогресс в различных областях физики и не только?
Постановка задачи: Открывая уравнения из данных
Традиционно, процесс вывода уравнений из данных опирается на глубокие экспертные знания и трудоемкую ручную разработку признаков, что представляет собой медленный и подверженный ошибкам подход. Ученым приходилось вручную отбирать релевантные переменные и комбинировать их, чтобы получить математическую модель, описывающую наблюдаемые явления. Такой метод требовал значительных временных затрат и зависел от субъективной оценки исследователя, что могло приводить к упущению важных закономерностей или включению ложных корреляций. Например, при моделировании сложных физических процессов, определение подходящих параметров и функциональных зависимостей требовало не только теоретических знаний, но и интуиции, основанной на многолетнем опыте. В результате, скорость научных открытий и проверки гипотез существенно ограничивалась, а возможность анализа больших объемов данных оставалась недоступной. E = mc^2 — даже такая фундаментальная формула была получена благодаря глубокому пониманию физических принципов и не могла быть найдена чисто автоматизированным способом в условиях ограниченных данных.
Стремительный рост объемов научных данных создает острую потребность в автоматизированных методах анализа, однако существующие техники символьной регрессии сталкиваются с серьезными ограничениями при работе со сложными системами и большими масштабами данных. Традиционные алгоритмы, хотя и способны находить простые зависимости, часто оказываются неэффективными при моделировании нелинейных явлений или систем, описываемых множеством переменных. Это связано с экспоненциальным ростом вычислительной сложности по мере увеличения числа возможных уравнений, что делает поиск оптимальной модели крайне затратным по времени и ресурсам. В результате, несмотря на значительные успехи в области машинного обучения, задача автоматического вывода уравнений из данных остается сложной и требует разработки новых, более эффективных подходов, способных справляться с возрастающей сложностью современных научных исследований и извлекать ценные знания из огромных массивов информации.
Ограничения существующих методов автоматического вывода уравнений существенно замедляют прогресс в различных научных областях. Невозможность быстро и эффективно моделировать сложные системы, такие как климатические изменения, динамика популяций или процессы в материаловедении, препятствует глубокому пониманию лежащих в основе механизмов и разработке эффективных решений. Отсутствие инструментов, способных оперативно анализировать огромные объемы данных и выявлять ключевые закономерности, создает узкие места в исследованиях, требующих быстрого прототипирования и валидации гипотез. В результате, ученые сталкиваются с трудностями в прогнозировании, оптимизации и контроле сложных процессов, что замедляет темпы научных открытий и инноваций, а также ограничивает возможности применения научных знаний на практике. Поиск новых подходов к автоматическому выводу уравнений представляется критически важной задачей для ускорения научного прогресса и решения глобальных вызовов современности.
KeplerAgent: Гармонизация физических знаний и символьной регрессии
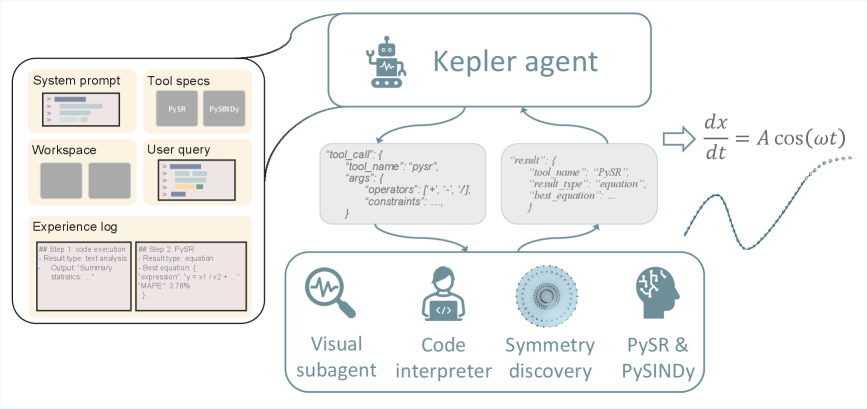
KeplerAgent представляет собой новую архитектуру, объединяющую инструменты, основанные на физическом моделировании, и методы символьной регрессии под управлением большой языковой модели (LLM). Данная архитектура обеспечивает оркестровку взаимодействия между различными инструментами, позволяя LLM выступать в роли координатора, определяющего последовательность и параметры работы этих инструментов. В рамках KeplerAgent, LLM анализирует задачу и, основываясь на своих рассуждениях, выбирает наиболее подходящие физические модели и алгоритмы символьной регрессии для поиска и формулировки уравнений, описывающих наблюдаемые явления. Это позволяет автоматизировать процесс открытия уравнений и снизить необходимость ручной настройки и вмешательства.
В основе KeplerAgent лежит подход, управляемый большой языковой моделью (LLM), который автоматически выбирает и настраивает необходимые инструменты и методы, включая физические симуляторы и символьную регрессию. LLM анализирует задачу и данные, определяя оптимальную последовательность операций для обнаружения уравнений. Этот процесс включает в себя выбор подходящих параметров для каждого инструмента, а также координацию их работы. В результате, ручное вмешательство в процесс обнаружения уравнений значительно сокращается, что повышает скорость и эффективность решения задачи, а также снижает вероятность ошибок, связанных с человеческим фактором.
В основе повышения точности и эффективности поиска уравнений в KeplerAgent лежит использование априорных физических знаний для сужения области поиска. Вместо перебора всех возможных математических выражений, система использует известные физические принципы и ограничения для фильтрации нерелевантных решений. Это достигается путем включения физических единиц измерения, констант и известных соотношений в процесс символьной регрессии. Например, при поиске уравнения для кинетической энергии система автоматически учитывает, что энергия должна быть выражена в единицах J (Джоулях), а масса в kg (килограммах) и скорость в m/s (метрах в секунду), что значительно сокращает количество рассматриваемых кандидатов и повышает вероятность нахождения корректного решения.
Использование симметрии для эффективного поиска
В рамках системы реализован модуль обнаружения симметрий, предназначенный для выявления и использования симметричных свойств, присущих анализируемым данным. Этот модуль автоматически определяет симметрии в данных, что позволяет значительно сократить количество потенциальных уравнений, подлежащих оценке. Обнаруженные симметрии используются в качестве ограничений при поиске, исключая из рассмотрения уравнения, не удовлетворяющие этим условиям. Такой подход существенно повышает эффективность процесса обнаружения уравнений, особенно в задачах с большим количеством переменных и сложными зависимостями, поскольку позволяет сфокусироваться на более узком и релевантном подмножестве возможных решений. Например, если данные демонстрируют симметрию относительно определенной переменной x, то уравнения, содержащие несимметричные члены относительно x, будут исключены из дальнейшего анализа.
Применение ограничений симметрии позволяет значительно сократить пространство поиска уравнений, что напрямую влияет на скорость и точность процесса обнаружения уравнений. Сокращение пространства поиска достигается путем исключения эквивалентных решений, возникающих в результате симметричных преобразований. Это особенно эффективно в задачах, где количество возможных уравнений экспоненциально растет с увеличением числа переменных и членов. Уменьшение числа оцениваемых уравнений приводит к снижению вычислительных затрат и повышает вероятность нахождения оптимального решения в разумные сроки. В результате, алгоритм с использованием ограничений симметрии демонстрирует повышенную эффективность по сравнению с методами, не учитывающими симметрии данных.
В рамках фреймворка реализована интеграция инструментов PySINDy и PySR, обеспечивающих применение методов разреженного регрессионного анализа (Sparse Regression) и генетического программирования (Genetic Programming) для эффективного исследования сокращенного пространства поиска уравнений. PySINDy использует разрешенный регрессион, чтобы идентифицировать наиболее значимые члены в уравнении, отбрасывая незначительные, что позволяет получить лаконичную и интерпретируемую модель. PySR, в свою очередь, использует генетические алгоритмы для эволюционного поиска оптимальных уравнений, комбинируя различные функции и параметры. Оба инструмента оптимизированы для работы с пространствами поиска, уменьшенными за счет применения ограничений симметрии, что значительно повышает скорость и точность поиска подходящих уравнений.
Обеспечение точности и широкое влияние
Для обеспечения достоверности полученных моделей, идентифицированные уравнения подвергаются строгой проверке с использованием метрик численной точности. Данный подход позволяет убедиться, что математические выражения адекватно отражают лежащие в основе физические процессы. Оценка точности проводится путем сравнения результатов, полученных с помощью разработанных уравнений, с известными или экспериментально полученными данными. В ходе валидации учитываются различные аспекты, такие как погрешность вычислений и стабильность решения, что гарантирует надежность и применимость моделей для прогнозирования и анализа сложных систем. Особое внимание уделяется проверке на чувствительность к изменениям начальных условий и параметров, что позволяет оценить устойчивость модели к погрешностям в исходных данных и обеспечить ее предсказуемость в различных сценариях.
Исследование демонстрирует, что KeplerAgent достигает символьной точности в 45% при работе с наборами данных DiffEq, что превосходит результаты, показанные другими базовыми методами в рамках бенчмарка DiffEq. Этот показатель свидетельствует о значительно улучшенной способности KeplerAgent находить точные символические представления дифференциальных уравнений по сравнению с существующими подходами. Достигнутая точность позволяет надежно моделировать сложные динамические системы, открывая возможности для более точного прогнозирования и анализа в различных областях науки и техники. Успех KeplerAgent в данном бенчмарке подтверждает его эффективность как инструмента для решения задач символической регрессии и автоматического открытия уравнений.
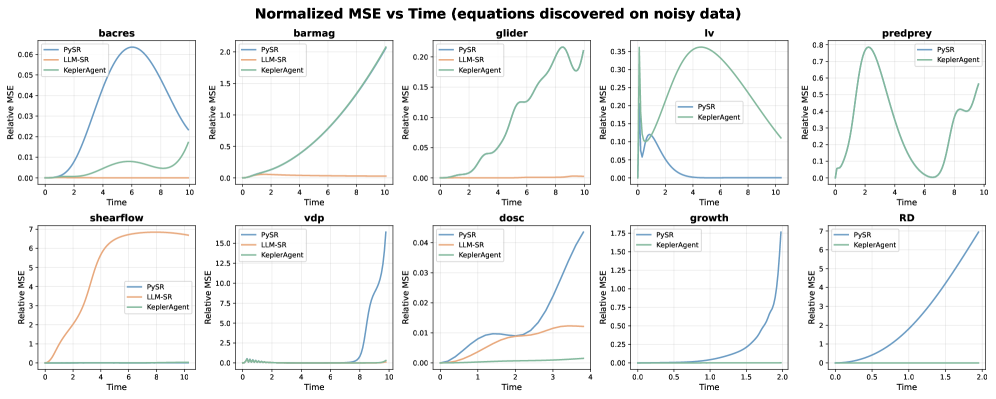
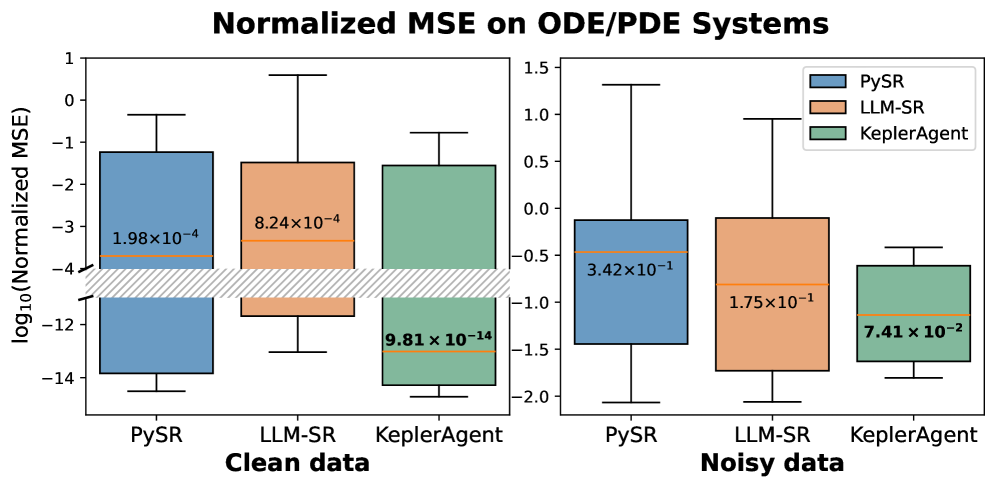
Исследования показали, что KeplerAgent демонстрирует высокую устойчивость к зашумленным данным, достигая наилучших или близких к лучшим результатам в 6 из 10 протестированных систем. Данный факт указывает на способность модели эффективно извлекать закономерности и строить точные прогнозы даже при наличии значительного шума в исходных данных. Такая робастность особенно важна при работе с реальными физическими системами, где данные часто содержат погрешности измерений и другие виды шума, что делает KeplerAgent перспективным инструментом для решения сложных задач моделирования и анализа.
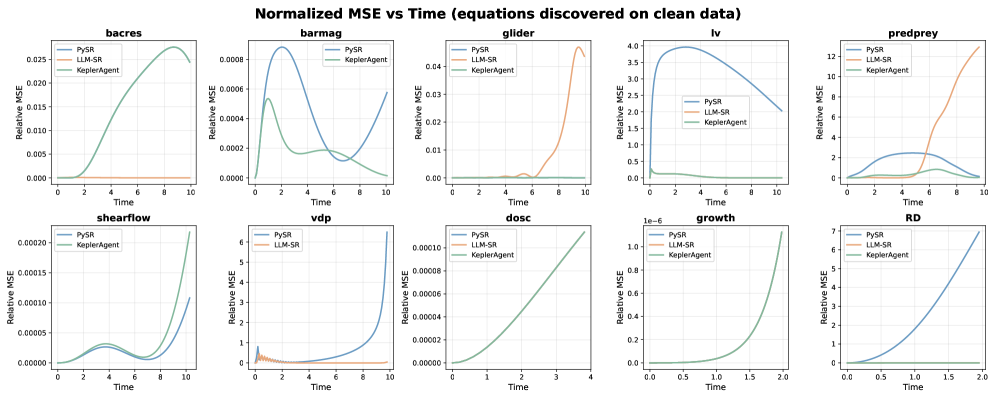
Исследования показали, что KeplerAgent демонстрирует повышенную точность по сравнению с такими подходами, как PySR и LLM-SR, при работе с чистыми данными. Это подтверждается более низкой нормализованной среднеквадратичной ошибкой (MSE) — метрикой, оценивающей разницу между предсказанными и фактическими значениями. По сути, KeplerAgent способен с большей прецизионностью выявлять и моделировать закономерности в данных, что свидетельствует о его потенциале в задачах, требующих высокой степени точности прогнозирования и анализа. Данный результат указывает на эффективность KeplerAgent в сценариях, где качество данных не является проблемой, и подчеркивает его преимущества в обеспечении надежных и точных результатов.
В представленной работе KeplerAgent демонстрирует подход к обнаружению уравнений, опираясь на принципы, близкие к математической строгости. Система не просто находит решения, но и стремится к их доказательной базе, используя физические принципы в качестве ограничивающих условий. Как однажды заметил Давид Гильберт: «Вся математика должна быть сведена к логике». Этот принцип находит отражение в KeplerAgent, где логическая непротиворечивость и доказуемость являются ключевыми аспектами при поиске и валидации уравнений, превосходя традиционные методы символьной регрессии и современные LLM-подходы. Подход к симметрии, используемый в работе, также подчеркивает стремление к элегантным и универсальным решениям.
Куда же это всё ведёт?
Представленный подход, хотя и демонстрирует прогресс в автоматическом обнаружении уравнений, не является панацеей. Если кажущаяся «магия» LLM-агента скрывает недостаток формальной доказательности — значит, инварианты, определяющие истинное решение, остались невыявленными. Проблема симметрий, являющаяся краеугольным камнем физики, требует более глубокой интеграции в процесс поиска, а не простого обнаружения после факта. Необходимо разрабатывать методы, позволяющие агенту активно исследовать пространство симметрий и использовать их в качестве ограничений для поиска.
Особое внимание следует уделить вопросу верификации полученных уравнений. Прохождение тестов, безусловно, необходимо, но недостаточно. Алгоритм должен быть доказуемо корректным, а не просто «работать» на предоставленных данных. Необходимо разрабатывать формальные методы проверки, гарантирующие, что найденное уравнение действительно отражает лежащие в основе физические принципы, а не является лишь статистической аномалией.
Будущие исследования должны сосредоточиться на расширении области применения KeplerAgent за пределы классической физики. Применимость к более сложным системам, таким как турбулентные потоки или квантовые явления, потребует разработки новых инструментов и алгоритмов, способных обрабатывать более сложные данные и учитывать нелинейные эффекты. И, конечно, необходимо помнить, что истинная элегантность кода проявляется в его математической чистоте.
Оригинал статьи: https://arxiv.org/pdf/2602.12259.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование кровотока мозга: новый взгляд на скорость и точность
- Квантовый скачок и финансовая бездна
- Звук в коде: новая эра токенизации аудио
- Видеомонтаж без следов: Новый подход к удалению и вставке объектов
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
- Рассуждения на графах: как большие языковые модели учатся видеть мир
- Квантовая телепортация в новых измерениях: топологические изоляторы
- Быстрый поиск по геному: Новые алгоритмы для spaced k-mers
- Преображение лиц: от тепла к реализму с помощью ИИ
2026-02-13 08:29