Автор: Денис Аветисян
Исследователи представили EDIR — принципиально новый способ оценки систем поиска по изображениям, учитывающий сложность композитных сцен.
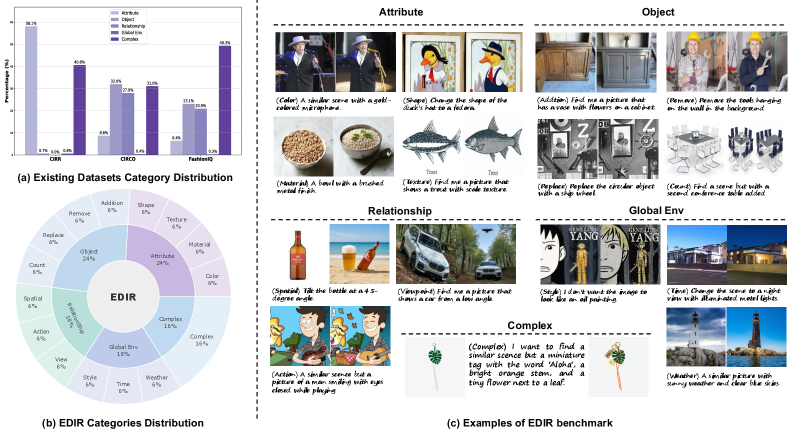
Предлагается эталонный набор данных EDIR, созданный с использованием технологий редактирования изображений для проведения детальной оценки поиска составных изображений.
Существующие подходы к оценке систем поиска по составным запросам часто не учитывают разнообразие реальных сценариев и гранулярность требований. В данной работе, ‘Rethinking Composed Image Retrieval Evaluation: A Fine-Grained Benchmark from Image Editing’, предложен новый, детализированный бенчмарк EDIR, созданный с использованием методов редактирования изображений для точного контроля над типами модификаций и содержанием запросов. Полученный набор данных, включающий 5000 высококачественных запросов, выявил значительные ограничения даже в передовых мультимодальных моделях, таких как RzenEmbed и GME, в части обеспечения стабильной производительности по всем подкатегориям. Какие архитектурные решения и стратегии обучения позволят преодолеть эти ограничения и создать более надежные и адаптивные системы понимания мультимодальных данных?
Сложность Композиционного Мышления в Мультимодальных Моделях
Современные мультимодальные модели, несмотря на значительные успехи в обработке изображений и текста, сталкиваются с трудностями при выполнении сложных инструкций, требующих одновременного учета нескольких ограничений. Эта проблема существенно ограничивает их применимость в реальных сценариях, где задачи часто предполагают комбинацию различных факторов и условий. Например, модель может успешно идентифицировать объект на изображении и понимать отдельные характеристики, но испытывает затруднения при выполнении запроса, требующего найти «красный мяч, лежащий справа от синей коробки». Неспособность эффективно объединять несколько критериев поиска или действий приводит к неточностям и ошибкам, делая такие модели недостаточно надежными для сложных приложений, как, например, автоматизированное управление роботами или интеллектуальный поиск информации.
Существующие оценочные наборы данных для мультимодальных моделей часто оказываются недостаточно детализированными, чтобы выявить истинные ограничения в способности к композиционному мышлению. Вместо проверки умения комбинировать несколько условий одновременно, большинство тестов ограничиваются простыми изменениями отдельных атрибутов объектов на изображениях. Например, модель может успешно находить «красное яблоко», но испытывает трудности, если требуется найти «красное яблоко слева от зеленого банана», что демонстрирует неспособность к комплексному анализу и интеграции нескольких визуальных и текстовых признаков. Такая упрощенная оценка создает иллюзию прогресса, скрывая реальные недостатки в понимании сложных инструкций и способности к обобщению знаний в новых, более сложных ситуациях.
Наблюдается тенденция, что современные мультимодальные модели демонстрируют выраженный перекос в сторону текстовой модальности, игнорируя или недооценивая визуальную информацию. Данное явление проявляется в ситуациях, когда модель, получив сложное указание, в большей степени опирается на интерпретацию текста, даже если визуальные данные содержат ключевую информацию для точного выполнения задачи. В результате, модель может совершать ошибки, основываясь на неполных или неверных интерпретациях, игнорируя очевидные визуальные подсказки. Этот перекос в сторону текста ограничивает способность моделей к полноценному пониманию сложных инструкций и снижает их надежность в реальных сценариях, где визуальная информация играет критически важную роль.
EDIR: Новый Бенчмарк для Оценки Композиционного Мышления
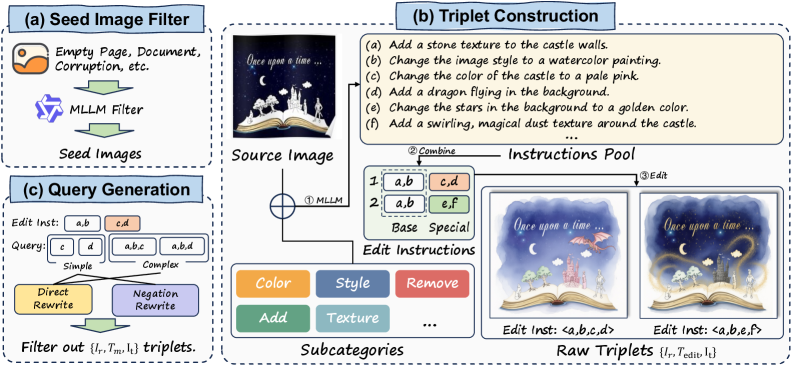
Бенчмарк EDIR создан посредством автоматизированного конвейера синтеза данных, использующего методы редактирования изображений для генерации сложных задач поиска по составным признакам. Данный подход позволяет создавать изображения и запросы, требующие от моделей понимания взаимосвязей между объектами и их атрибутами, а не просто сопоставления отдельных признаков. Конвейер автоматически комбинирует различные элементы и модификации изображений, что обеспечивает генерацию большого объема данных с контролируемым уровнем сложности и разнообразием композиций. Это позволяет оценить способность моделей к композиционному рассуждению в условиях, приближенных к реальным задачам компьютерного зрения.
Набор данных EDIR состоит из 5000 запросов и 178 645 изображений, что обеспечивает всестороннюю платформу для оценки композиционного рассуждения. Такой объем данных позволяет проводить статистически значимые тесты и надежно оценивать производительность моделей в задачах, требующих понимания и сопоставления сложных визуальных сцен. Большое количество изображений и запросов позволяет выявить слабые места в алгоритмах и оценить их способность к обобщению на новые, ранее не встречавшиеся комбинации объектов и атрибутов.
Подход, используемый в EDIR, обеспечивает систематический контроль над сложностью необходимого для решения задач рассуждения, что позволяет проводить детальную оценку возможностей моделей. Конкретно, варьируя количество и тип редактирований, применяемых к исходным изображениям для создания составных запросов, можно точно настроить уровень требуемого логического вывода. Это позволяет выделить слабые места моделей в различных аспектах композиционного рассуждения, например, в понимании отношений между объектами или в обработке сложных инструкций, и оценить их производительность на различных уровнях сложности. Такой контроль критически важен для объективного сравнения различных моделей и выявления направлений для их улучшения.
Оценка Мультимодальных Моделей с Использованием EDIR
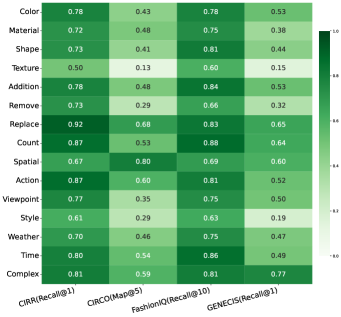
В качестве платформы для оценки современных мультимодальных моделей встраивания, включая модели, построенные на основе CLIP, используется датасет EDIR. EDIR предоставляет набор данных, предназначенный для тестирования способности моделей понимать и обрабатывать сложные, составные инструкции, выраженные в текстовой форме и сопоставлять их с соответствующими изображениями. Оценка проводится путем измерения способности модели генерировать векторные представления для текста и изображений, и последующего поиска изображений, наиболее соответствующих текстовому запросу. Использование EDIR позволяет стандартизировать процесс оценки и сравнивать производительность различных моделей в контролируемых условиях.
Оценка производительности моделей осуществляется с использованием метрики Recall@1, которая измеряет долю случаев, когда модель успешно извлекает изображение, точно соответствующее составному запросу. Recall@1 вычисляется как отношение количества правильно извлеченных изображений к общему числу запросов. При этом, запрос считается успешно выполненным, если извлеченное изображение наиболее полно и корректно отражает все элементы и отношения, заданные в сложном текстовом описании. Высокое значение Recall@1 указывает на способность модели к точному пониманию и интерпретации составных инструкций и сопоставлению их с соответствующим визуальным контентом.
При обучении на специализированном наборе данных (in-domain training), модели EDIR-MLLM демонстрируют показатель Recall@1, достигающий 59.9%. Данный результат подтверждает эффективность целенаправленного обучения для улучшения способности моделей к извлечению релевантных изображений, соответствующих составным инструкциям. Высокий показатель Recall@1 указывает на то, что модель способна успешно находить наиболее подходящее изображение из предложенного набора, когда запрос включает в себя несколько условий или атрибутов.
Среднее значение метрики Recall@1 для других моделей на основе MLLM составляет лишь 36.9%. Этот показатель свидетельствует о сохраняющихся трудностях в области композиционного рассуждения, то есть способности модели корректно интерпретировать и выполнять инструкции, состоящие из нескольких связанных элементов. Низкий показатель Recall@1 указывает на то, что модели часто не могут точно сопоставить текстовое описание с соответствующим изображением, особенно когда инструкция требует одновременного учета нескольких атрибутов или условий.
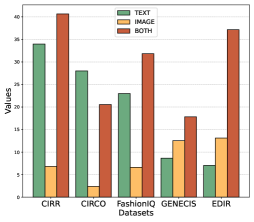
За пределами современных моделей: к надежному визуально-языковому рассуждению
Разработанный ресурс EDIR представляет собой ценный инструмент для научного сообщества, позволяющий проводить более строгую и всестороннюю оценку моделей, работающих с визуальной и текстовой информацией. Этот набор данных, специально созданный для оценки способности моделей к многоступенчатому рассуждению, позволяет выявлять слабые места существующих алгоритмов и стимулирует разработку более надежных и эффективных систем. Предоставляя стандартизированную платформу для тестирования, EDIR способствует ускорению прогресса в области мультимодального искусственного интеллекта и открывает новые возможности для создания систем, способных к сложному анализу и интерпретации визуальной информации в контексте текстовых запросов.
Анализ текущих моделей мультимодального искусственного интеллекта выявил, что существенное повышение надежности и устойчивости к ошибкам напрямую связано с улучшением способности к композиционному рассуждению. Данный тип рассуждений предполагает не просто распознавание отдельных элементов на изображении и в тексте, но и умение объединять их в сложные логические конструкции, учитывая множество взаимосвязанных ограничений. Неспособность к такому синтезу приводит к ошибкам даже в простых сценариях, когда модель сталкивается с незнакомыми комбинациями известных объектов или условий. Поэтому, разработка алгоритмов, способных эффективно анализировать и комбинировать информацию из различных источников, является ключевым фактором для создания действительно интеллектуальных систем, способных к надежному и гибкому взаимодействию с окружающим миром.
Перспективные исследования направлены на создание архитектур, способных эффективно решать сложные задачи, характеризующиеся множеством взаимосвязанных ограничений. Особое внимание уделяется использованию конструкций, основанных на принципах больших мультимодальных языковых моделей (MLLM), которые позволяют объединить возможности обработки визуальной информации и естественного языка. Такой подход может существенно повысить надежность и точность систем искусственного интеллекта, способных рассуждать на основе как изображений, так и текстовых данных, открывая новые горизонты в области мультимодального анализа и решения задач.

Представленное исследование, создающее новый бенчмарк EDIR для поиска составных изображений, закономерно сталкивается с неизбежной сложностью оценки. Авторы стремятся к детализированной оценке, используя pipeline синтеза данных на основе редактирования изображений. Однако, как показывает практика, любая, даже самая продуманная метрика, рано или поздно станет инструментом для манипуляций и оптимизаций, не отражающих реальную ценность системы. Как однажды заметил Дэвид Марр: «Любая модель слишком проста, чтобы быть точной, но достаточно точна, чтобы быть полезной.» Эта фраза особенно актуальна в контексте машинного обучения, где погоня за числовыми показателями часто затмевает здравый смысл и реальные потребности пользователей. Бенчмарк EDIR, несомненно, продвигает область multimodal learning, но важно помнить, что даже самые передовые методы рано или поздно превратятся в технический долг.
Что дальше?
Представленный бенчмарк EDIR, безусловно, усложняет задачу для систем поиска по составным изображениям. Однако, как известно, продакшен всегда найдет способ обмануть даже самые изощренные метрики. Ожидается, что появятся модели, заточенные конкредно под EDIR, демонстрирующие впечатляющие результаты на синтетических данных, но спотыкающиеся о реальные, «неудобные» изображения. Ведь, в конце концов, все новое — это старое, только с другим именем и теми же багами.
Более глубокий вопрос заключается в том, насколько вообще оправдана эта гонка за «идеальной» оценкой. Синтез данных, даже с использованием редактирования изображений, всегда будет упрощением реальности. Пока рано говорить о полноценном переходе к автоматизированной оценке качества поиска по составным запросам. Человеческая оценка, хоть и субъективная, по-прежнему остается эталоном, к которому следует стремиться — хотя бы для калибровки автоматических метрик.
Вероятно, следующее поколение исследований сосредоточится на создании более «живых» и непредсказуемых синтетических данных, способных имитировать разнообразие реального мира. Но не стоит забывать, что любая модель, даже самая сложная, — это лишь приближение к истине. И, как показывает опыт, каждое «революционное» решение завтра станет техдолгом.
Оригинал статьи: https://arxiv.org/pdf/2601.16125.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 17:18