Автор: Денис Аветисян
Исследователи разработали подход, позволяющий агентам на основе больших языковых моделей эффективно управлять своими мыслями и наблюдениями, повышая производительность без потери точности.
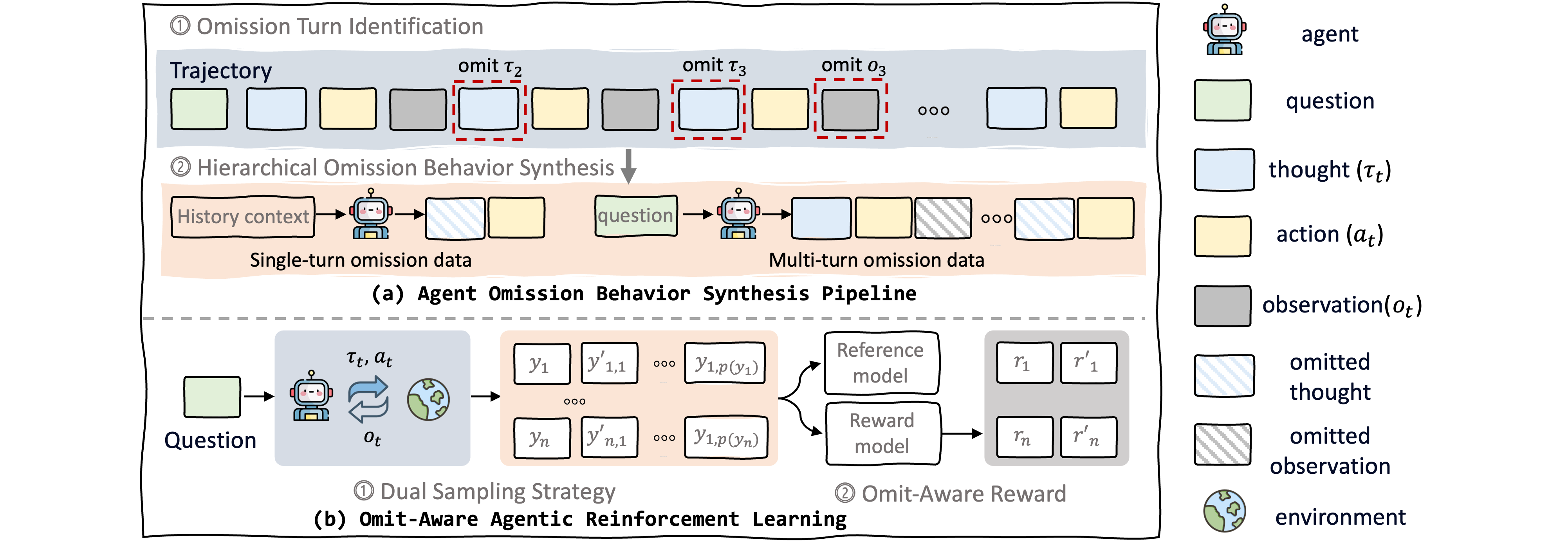
Представлен фреймворк Agent-Omit, использующий обучение с подкреплением для адаптивного отсеивания избыточных мыслей и наблюдений, оптимизируя контекст и повышая эффективность агентов.
Эффективное управление когнитивными процессами и выбором релевантной информации в многошаговом взаимодействии агента с окружающей средой остается сложной задачей. В данной работе, посвященной ‘Agent-Omit: Training Efficient LLM Agents for Adaptive Thought and Observation Omission via Agentic Reinforcement Learning’, предложен фреймворк, позволяющий LLM-агентам адаптивно отбрасывать избыточные мысли и наблюдения, оптимизируя их производительность. Разработанный подход демонстрирует сопоставимые результаты с передовыми LLM-агентами, при этом достигая лучшего баланса между эффективностью и точностью. Сможет ли подобная адаптивная политика значительно расширить возможности LLM-агентов в решении более сложных задач и в условиях ограниченных ресурсов?
Пределы Многословия: Узкие Места Эффективности LLM
Современные большие языковые модели демонстрируют впечатляющие возможности в решении широкого спектра задач, однако их эффективность резко снижается при обработке сложных, многоступенчатых рассуждений. Эта проблема обусловлена принципом квадратичного масштабирования механизма внимания — ключевого компонента, позволяющего модели устанавливать связи между различными частями входного текста. По мере увеличения длины последовательности, количество необходимых вычислений для оценки взаимосвязей между всеми элементами растет пропорционально квадрату длины, что приводит к экспоненциальному увеличению вычислительных затрат и замедлению обработки. Таким образом, способность модели к эффективному решению задач, требующих глубокого анализа и длительных цепочек умозаключений, ограничена её архитектурными особенностями и вычислительными ресурсами.
Несмотря на впечатляющие возможности, большие языковые модели (LLM) сталкиваются с существенными ограничениями в задачах, требующих длительных цепочек рассуждений. Эта внутренняя неэффективность проявляется в высоких вычислительных затратах, обусловленных экспоненциальным ростом ресурсов, необходимых для обработки длинных последовательностей текста. В результате, применение LLM в сложных, динамичных средах, таких как автономные системы или анализ больших объемов данных в реальном времени, становится затруднительным и дорогостоящим. Ограничения в скорости и потреблении энергии препятствуют развертыванию моделей на мобильных устройствах или в условиях ограниченных ресурсов, что сужает сферу их практического применения и требует разработки новых подходов к оптимизации архитектуры и алгоритмов обработки информации.
Существенная проблема, с которой сталкиваются большие языковые модели, заключается в их склонности сохранять и обрабатывать избыточную информацию, что препятствует эффективному мышлению. В отличие от человеческого мозга, способного к фильтрации несущественных деталей, LLM часто удерживают в памяти весь контекст, даже если он не имеет отношения к текущей задаче. Это приводит к экспоненциальному росту вычислительных затрат, особенно при работе с длинными текстами или сложными логическими цепочками. Данная особенность проявляется в виде замедления обработки, увеличения потребления памяти и, как следствие, ограничения применимости моделей в задачах, требующих оперативного и ресурсоэффективного анализа больших объемов данных. Исследования показывают, что оптимизация механизмов внимания и разработка методов сжатия информации являются ключевыми направлениями для преодоления этой проблемы и повышения производительности LLM.

Agent-Omit: Адаптивная Обрезка для Эффективных Рассуждений
Фреймворк Agent-Omit предназначен для обучения LLM-агентов, способных проактивно исключать из рассмотрения избыточные мысли и наблюдения. В процессе обучения агент выявляет и отбрасывает информацию, не вносящую существенного вклада в процесс принятия решений или достижения поставленной цели. Это достигается путем анализа внутренней цепочки рассуждений и внешних наблюдений с целью определения их релевантности и уникальности. Исключение избыточной информации позволяет снизить вычислительные затраты, повысить скорость работы агента и улучшить качество принимаемых решений за счет фокусировки на наиболее значимых данных.
Архитектура Agent-Omit расширяет существующие подходы к управлению ходом мыслей (Thought Management) и обработке наблюдений (Observation Management) посредством унифицированной стратегии обработки информации. Вместо рассмотрения этих процессов как отдельных, Agent-Omit интегрирует их в единый механизм, позволяющий агенту динамически оценивать релевантность внутренних рассуждений и внешних данных. Это достигается путем совместной оптимизации как внутренних (мысли), так и внешних (наблюдения) потоков информации, что повышает эффективность агента и снижает вычислительные затраты за счет исключения из рассмотрения избыточных или нерелевантных данных.
В основе Agent-Omit лежит стратегия управления мыслями и наблюдениями (Thought&Observation Management, TOM), направленная на оптимизацию как внутренней логической обработки информации, так и внешнего восприятия окружения. TOM предполагает динамическую оценку релевантности каждой мысли и каждого наблюдения для текущей задачи. Несущественные элементы отбрасываются, что позволяет снизить вычислительную нагрузку и повысить эффективность работы агента. Оптимизация проводится за счет совместного управления внутренним процессом рассуждений и внешним сбором информации, обеспечивая более рациональное использование ресурсов и ускорение принятия решений.
Обучение Agent-Omit: От Синтеза к Подкреплению
На начальном этапе, Синтез Поведения с Исключением, формируется датасет, необходимый для обучения агента идентификации и исключению нерелевантной информации. Этот процесс заключается в создании размеченных данных, где указывается, какие части входной последовательности следует опускать для повышения эффективности и фокусировки на существенных элементах. Датасет генерируется с использованием заранее определенных правил или эвристик, определяющих релевантность информации, и служит отправной точкой для последующего обучения с подкреплением. Объем и качество сгенерированного датасета напрямую влияют на способность агента к эффективному исключению ненужной информации на последующих этапах обучения.
После этапа синтеза поведения упущения, происходит тонкая настройка политики упущения с использованием обучения с подкреплением (Reinforcement Learning), известного как Omit-Aware Agentic RL. В рамках этого этапа агент обучается определять и исключать несущественную информацию на основе получаемого вознаграждения. Процесс обучения направлен на оптимизацию стратегии упущения, позволяя агенту эффективно сокращать длину траекторий и фокусироваться на релевантных данных. В результате, агент адаптирует свою политику упущения для повышения эффективности и производительности в задачах, требующих фильтрации информации.
В рамках этапа обучения с подкреплением ключевым элементом является стратегия двойной выборки (Dual Sampling Strategy), направленная на эффективное исследование как полных, так и частичных траекторий. Данный подход предполагает одновременный сбор данных, полученных при прохождении агентом всей последовательности действий, и данных, полученных при намеренном исключении определенных шагов. Это позволяет агенту оценивать влияние каждого действия на конечный результат и оптимизировать политику отсеивания несущественной информации. Использование как полных, так и частичных траекторий обеспечивает более широкое покрытие пространства состояний и ускоряет процесс обучения, повышая эффективность алгоритма.
Для стимулирования эффективного отсева нерелевантной информации в процессе обучения агента используется функция вознаграждения за отсев (Omission Reward). Эта функция формирует сигнал, направленный на максимизацию полезности траектории при минимальной её длине. В ходе обучения наблюдается устойчивая тенденция к уменьшению длины траектории (Trajectory Length Reduction), что подтверждает эффективность предложенного подхода и способность агента оптимизировать процесс отсева для улучшения производительности. Значение функции вознаграждения напрямую связано с количеством опущенных шагов, при этом учитывается влияние этих отсечений на достижение конечной цели.

Эмпирическая Валидация: Эффективность в Различных Средах
Агент-Omit продемонстрировал свою эффективность в решении сложных задач в разнообразных средах, включая платформы, имитирующие онлайн-шопинг (WebShop), глубокий поиск информации (DeepSearch), креативное написание текстов (TextCraft), обучение младенцев (BabyAI) и научные исследования (SciWorld). Исследования показали, что агент способен успешно функционировать в этих требовательных условиях, требующих адаптации к различным типам данных и задачам. Данная универсальность подчеркивает потенциал Agent-Omit как надежного инструмента для автоматизации сложных процессов и расширения возможностей искусственного интеллекта в различных областях применения. Успешная работа в столь отличающихся средах является свидетельством его способности к обобщению и применению знаний в новых ситуациях.
Исследования показали значительное сокращение длины траектории, необходимой для выполнения задач в различных сложных средах. Это означает, что Agent-Omit достигает целей быстрее, требуя меньше шагов и, следовательно, снижая общие вычислительные затраты. Уменьшение количества действий, необходимых для успешного завершения задачи, не только повышает эффективность, но и позволяет существенно экономить ресурсы, что особенно важно при работе с большими языковыми моделями и в условиях ограниченной вычислительной мощности. Такое сокращение траектории демонстрирует способность Agent-Omit оптимизировать процесс принятия решений и фокусироваться на наиболее релевантных действиях, обеспечивая более быстрый и экономичный подход к решению задач.
Исследования демонстрируют, что Agent-Omit значительно сокращает количество необходимых раундов взаимодействия для решения задач в различных средах. Это указывает на повышенную эффективность использования данных и более лаконичное, целенаправленное рассуждение. Вместо многократных попыток и уточнений, Agent-Omit способен достигать поставленных целей, используя меньше итераций, что свидетельствует о его способности быстро усваивать информацию и эффективно применять ее для достижения результата. Такое снижение количества раундов не только оптимизирует процесс решения задач, но и существенно снижает вычислительные затраты, делая Agent-Omit более экономичным и масштабируемым решением.
Исследования показали, что Agent-Omit демонстрирует сопоставимую с семью передовыми большими языковыми моделями (LLM) точность, оцениваемую показателем Pass@1, в сложных средах, таких как WebShop, TextCraft, BabyAI и SciWorld. При этом, Agent-Omit существенно снижает затраты на использование токенов, что делает его более эффективным решением для задач, требующих обработки больших объемов информации. Данное сочетание высокой точности и экономичности делает Agent-Omit привлекательным инструментом для широкого спектра приложений, где важна как надежность результатов, так и оптимизация вычислительных ресурсов.
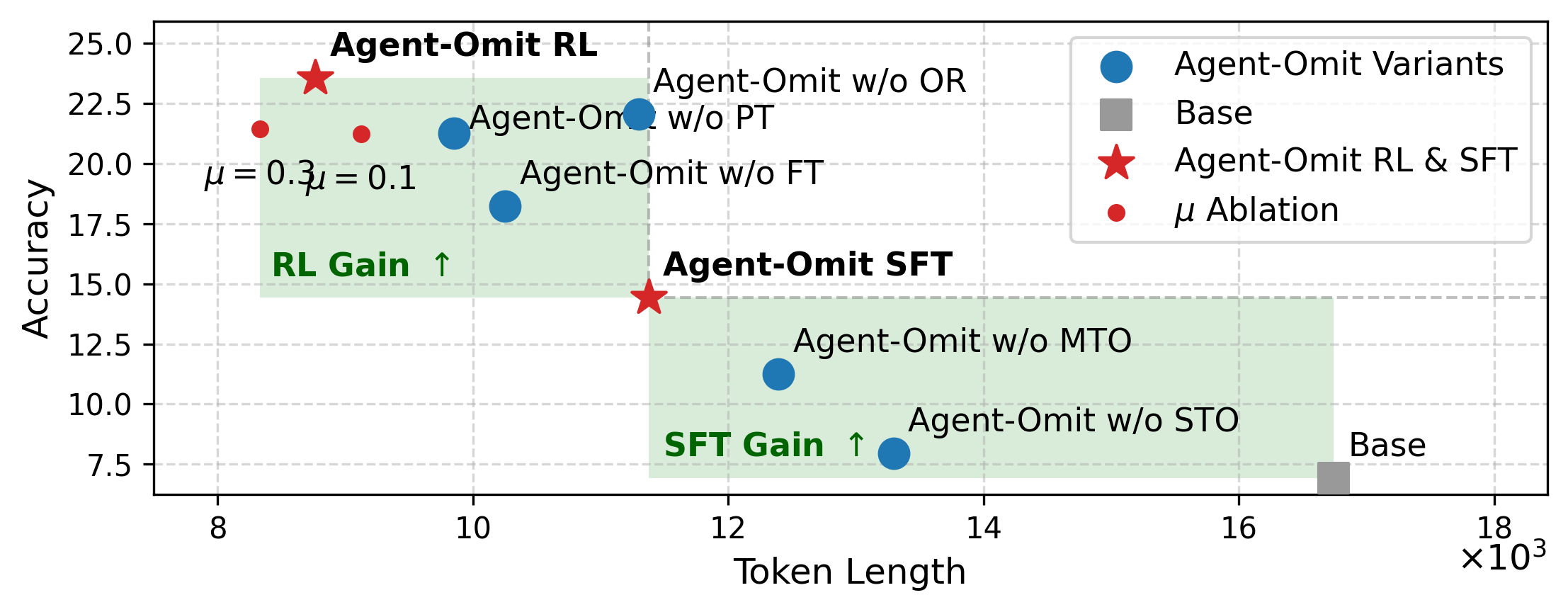
За Пределами Эффективности: К Надежному и Адаптируемому ИИ
Принципы, лежащие в основе подхода Agent-Omit, открывают перспективный путь к созданию искусственных интеллектов, которые отличаются не только высокой производительностью, но и устойчивостью к нештатным ситуациям и способностью к адаптации. В отличие от традиционных систем, стремящихся к максимальной эффективности при заданных условиях, Agent-Omit акцентирует внимание на обучении агентов определять и приоритизировать наиболее релевантную информацию. Это позволяет им эффективно функционировать даже в условиях зашумленных или неполных данных, а также быстро приспосабливаться к изменениям окружающей среды. Такой подход, основанный на избирательном внимании и гибкости обработки информации, создает основу для разработки интеллектуальных систем нового поколения, способных к самообучению и эффективному решению сложных задач в динамично меняющемся мире.
Исследования показывают, что способность искусственных агентов выделять и приоритизировать релевантную информацию значительно повышает их устойчивость к шуму и неполноте данных. Вместо обработки всего входящего потока, эти агенты обучаются фокусироваться на наиболее значимых элементах, что позволяет им принимать более надежные решения даже в сложных и неопределенных ситуациях. Такой подход имитирует когнитивные процессы, наблюдаемые у живых организмов, где внимание избирательно направляется на критически важные стимулы. В результате, агенты, использующие принципы приоритезации, демонстрируют повышенную эффективность в условиях, когда традиционные системы искусственного интеллекта сталкиваются с трудностями, открывая новые возможности для применения в различных областях, требующих надежной работы с неполными или зашумленными данными.
Предстоящие исследования сосредоточены на расширении области применения Agent-Omit, с целью проверки его эффективности в решении задач, значительно превосходящих текущий уровень сложности. Планируется протестировать систему в динамичных и непредсказуемых средах, моделирующих реальные условия, такие как автономная навигация в сложных городских ландшафтах или управление сложными производственными процессами. Особое внимание будет уделено адаптации Agent-Omit к задачам, требующим не только обработки данных, но и принятия решений в условиях неопределенности и неполной информации. Успешная реализация этих исследований может открыть новые возможности для создания интеллектуальных систем, способных эффективно функционировать в самых разнообразных и требовательных условиях.
Открывающиеся возможности, предоставляемые данным подходом, простираются далеко за пределы простой оптимизации. В сфере научных открытий, интеллектуальные агенты, способные к адаптивному отбору информации, могут ускорить анализ огромных массивов данных, выявляя закономерности и выдвигая гипотезы, которые могли бы остаться незамеченными. Автоматизированное рассуждение, освобожденное от необходимости обработки избыточной информации, станет более эффективным и надежным. И, наконец, перспективы человеко-машинного взаимодействия претерпят значительные изменения: агенты, способные понимать контекст и приоритеты, смогут стать полноценными партнерами в решении сложных задач, обеспечивая более интуитивное и продуктивное сотрудничество. Подобные системы не просто автоматизируют процессы, но и расширяют возможности человека в самых разнообразных областях деятельности.
В статье описывается Agent-Omit, система, стремящаяся к оптимизации работы языковых агентов путём отсеивания избыточной информации. Это вызывает лишь усталую иронию. Как говорил Брайан Керниган: «Простота — это главное. Если что-то сложное, значит, мы что-то упустили». По сути, авторы пытаются элегантно решить проблему, с которой разработчики сталкиваются постоянно: любой, даже самый продуманный механизм, рано или поздно обрастает ненужными деталями. Стремление к эффективному управлению «мыслями» агента — это лишь способ отсрочить неизбежное усложнение. История показывает, что каждая оптимизация порождает новые точки отказа, и рано или поздно система вернется к исходной точке — когда «всё работало, пока не пришёл agile».
Куда же это всё катится?
Представленный фреймворк, Agent-Omit, безусловно, демонстрирует, как можно заставить языковую модель забывать лишнее. Что, впрочем, не ново — вся жизнь состоит из умения игнорировать подавляющее большинство входящих сигналов. Однако, оптимизация «эффективности» агента посредством выборочного «забывания» — это, скорее, временное решение. Продакшен, как всегда, найдёт способ завалить систему настолько сложными запросами, что даже самый избирательный «опуск» мыслей окажется недостаточным. Если система стабильно падает, значит, она хотя бы последовательна.
Следующим шагом, вероятно, станет попытка автоматизировать процесс определения «ненужного». Но кто решит, что именно считать «ненужным»? Разработчик, конечно. Именно он, в конечном итоге, будет кодировать свои представления о «важности», превращая «адаптивное» поведение в просто набор предустановленных правил. Мы не пишем код — мы просто оставляем комментарии будущим археологам, которые будут гадать, что мы имели в виду.
В конечном счёте, все эти «cloud-native» решения и «агентные» фреймворки — это лишь попытки замаскировать фундаментальную проблему: неспособность существующих архитектур справляться с возрастающей сложностью задач. И пока мы гоняемся за «эффективностью», реальная проблема — в постоянном накоплении технического долга. Возможно, через десять лет мы будем изобретать заново принципы простоты и надёжности, забыв о всех этих модных словах.
Оригинал статьи: https://arxiv.org/pdf/2602.04284.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Визуальное мышление машин: проверка на прочность
2026-02-05 20:04