Автор: Денис Аветисян
Исследователи разработали усовершенствованный метод, позволяющий эффективно обходить системы искусственного интеллекта, объединяющие обработку изображений и естественного языка, даже без доступа к внутренним механизмам.

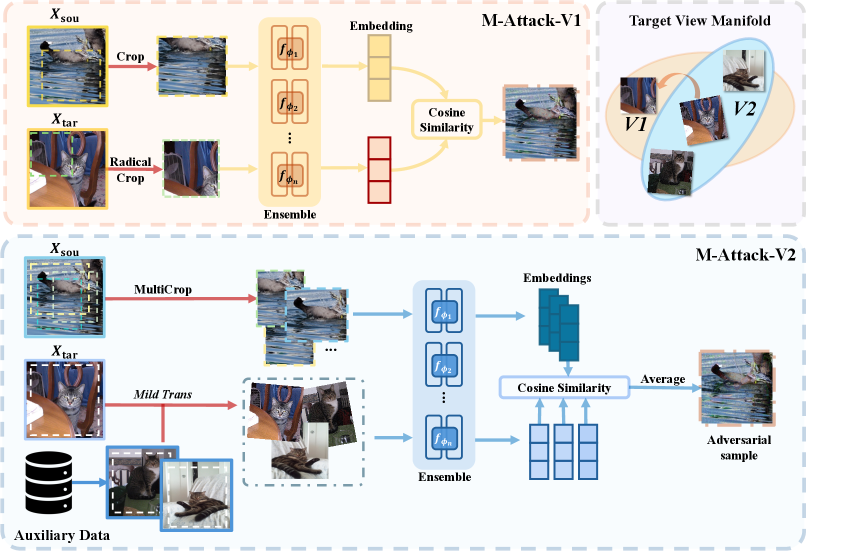
В статье представлена M-Attack-V2 — надежная система подавления шума градиента, значительно превосходящая существующие методы атак на большие визуально-языковые модели за счет повышения стабильности сопоставления на локальном уровне с использованием многократной обрезки, дополнительной целевой ориентации и импульса патчей.
Несмотря на успехи в области больших визуально-языковых моделей (LVLM), их устойчивость к состязательным атакам остаётся сложной задачей из-за отсутствия градиентов и сложной мультимодальной природы. В работе ‘Pushing the Frontier of Black-Box LVLM Attacks via Fine-Grained Detail Targeting’ предложен новый подход, M-Attack-V2, который значительно повышает эффективность атак на основе переноса, решая проблему нестабильности локального сопоставления деталей. Достигнуто это за счёт усреднения градиентов по множеству локальных видов (Multi-Crop Alignment), использования вспомогательного набора целевых данных (Auxiliary Target Alignment) и переосмысления момента как сохранения градиентов по патчам (Patch Momentum). Способен ли M-Attack-V2 стать стандартом для оценки безопасности и надёжности передовых LVLM, таких как Claude-4.0, Gemini-2.5-Pro и GPT-5?
Хрупкость зрения: уязвимости современных мультимодальных моделей
Современные мультимодальные модели, такие как Gemini-2.5-Pro, GPT-4o и Claude-3.7, всё активнее внедряются в критически важные области — от автономного вождения и медицинской диагностики до систем безопасности и анализа данных. Однако, несмотря на впечатляющие возможности, эти мощные системы оказываются уязвимыми к так называемым «атакам с подменой», когда незначительные, незаметные для человека изменения входных данных приводят к ошибочным результатам. Данная уязвимость представляет серьезную угрозу, поскольку может привести к непредсказуемым и потенциально опасным последствиям в реальных приложениях, требуя разработки надежных методов защиты и повышения устойчивости этих моделей к внешним воздействиям.
Традиционные методы генерации атак на системы, объединяющие зрение и язык, зачастую демонстрируют нестабильность, что серьезно ограничивает их практическую применимость. Незначительные изменения в параметрах атаки или даже в самой модели могут привести к полному провалу, когда ранее успешное возмущение перестает оказывать желаемого эффекта. Это связано с высокой чувствительностью современных больших моделей к входным данным и сложностью поддержания стабильности возмущений в многомерном пространстве признаков. Непредсказуемость результатов делает такие атаки ненадежными для систематического тестирования безопасности и требует разработки более устойчивых и контролируемых методов, способных гарантированно вводить модели в заблуждение.
Основная сложность в обеспечении надёжности систем, основанных на крупных визуально-языковых моделях, заключается в разработке эффективных и незаметных модификаций входных данных, способных последовательно вводить эти мощные системы в заблуждение. Несмотря на впечатляющую производительность, эти модели остаются уязвимыми к тщательно сконструированным искажениям, которые могут быть едва различимы для человеческого глаза, но оказывают существенное влияние на процесс принятия решений моделью. Создание таких «адверсарных примеров» требует поиска оптимального баланса между степенью искажения и эффективностью обмана, что представляет собой непростую задачу оптимизации. Успешное решение этой задачи позволит не только выявить слабые места в архитектуре моделей, но и разработать более устойчивые и безопасные системы искусственного интеллекта.

Локализованное вмешательство: M-Attack как новый подход
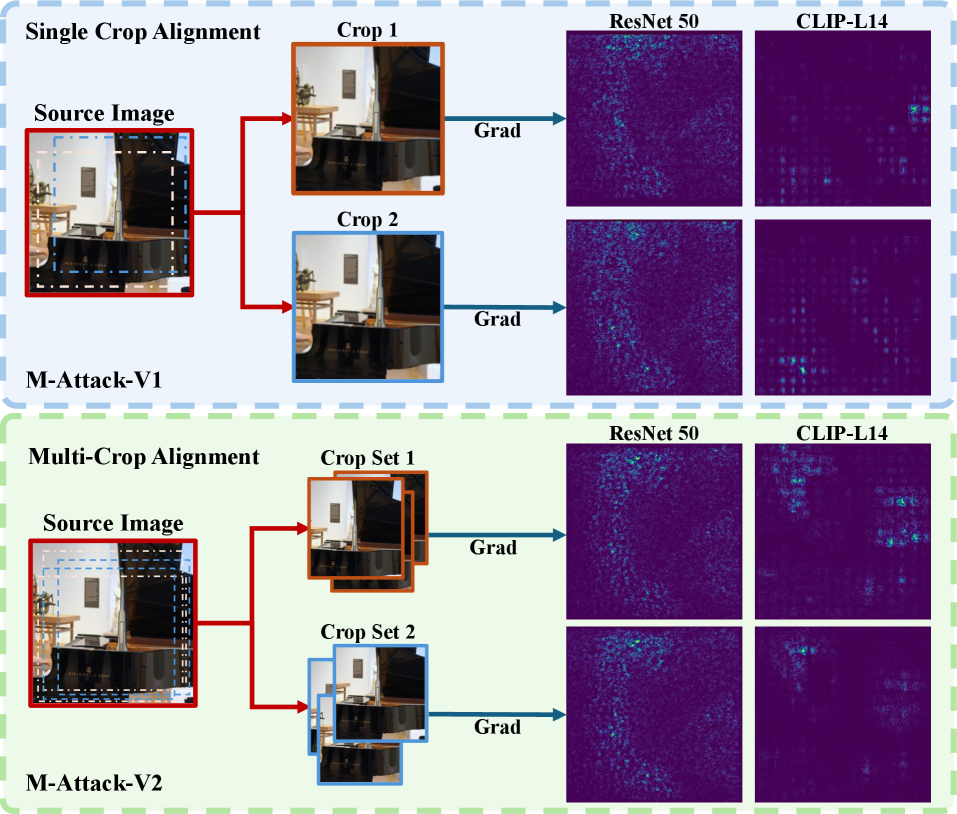
Метод M-Attack использует сопоставление на уровне локальных областей изображения для определения критически важных регионов, требующих возмущения. Вместо применения глобальных изменений ко всему изображению, M-Attack концентрирует усилия на небольших, но значимых участках, что позволяет добиться более эффективной атаки при меньших вычислительных затратах. Этот подход основан на идентификации регионов, оказывающих наибольшее влияние на предсказания целевой модели, и целенаправленном внесении в них изменений для обхода механизмов защиты. Локализованное возмущение значительно снижает общую «заметность» атаки и повышает вероятность успешного обмана целевой системы.
Метод M-Attack обходит необходимость прямого доступа к градиентам целевой модели, используя в качестве альтернативы суррогатные модели — CLIP, BLIP-2 и DinoV2. Эти модели, предварительно обученные на больших объемах данных, позволяют оценивать признаки изображения и определять области, наиболее чувствительные к возмущениям, без информации о внутренней структуре и параметрах целевой модели. Использование суррогатных моделей значительно упрощает процесс генерации атак, поскольку не требует вычисления градиентов, что особенно актуально для закрытых или недоступных моделей машинного зрения.
Использование локализованного подхода в M-Attack значительно повышает эффективность атак и снижает вычислительные затраты на генерацию антагонистических примеров. Традиционные методы часто требуют вычислений по всей площади изображения, что является ресурсоемким. M-Attack, напротив, концентрирует усилия на ключевых областях, определенных локальным сопоставлением, что позволяет сократить количество необходимых вычислений и, следовательно, время генерации антагонистических примеров. Сокращение вычислительной нагрузки особенно важно при работе с большими изображениями или при необходимости проведения атак в реальном времени.
Стабилизация атаки: M-Attack-V2 и патч-ансамбль
M-Attack-V2 решает проблему нестабильности градиентов, характерную для предыдущей версии алгоритма, что обеспечивает более надежную и воспроизводимую эффективность атак. Нестабильность градиентов в оригинальном M-Attack приводила к непредсказуемым результатам и снижению вероятности успешной атаки. В M-Attack-V2 реализованы улучшения, направленные на сглаживание градиентов и повышение устойчивости процесса оптимизации, что позволяет добиться более консистентных результатов при различных параметрах и входных данных. Это достигается за счет оптимизации алгоритма вычисления градиентов и применения методов регуляризации, направленных на предотвращение резких изменений в процессе обучения.
Стратегия Patch Ensemble+ представляет собой усовершенствованный подход к выбору набора разнородных размеров патчей в рамках суррогатной ансамблевой модели. В отличие от предыдущих методов, Patch Ensemble+ динамически определяет оптимальные размеры патчей, учитывая специфику целевой модели и входных данных. Это достигается за счет использования алгоритма, который максимизирует разнообразие патчей, при этом сохраняя их эффективность в процессе атаки. Использование разнородных патчей позволяет более эффективно обходить механизмы защиты, основанные на обнаружении однотипных атак, и повышает устойчивость к различным параметрам модели, что приводит к более надежным результатам.
Оценка M-Attack-V2 на наборе данных NIPS 2017 показала значительное повышение коэффициентов успешности атак (Attack Success Rate, ASR). В частности, ASR был увеличен с 98% до 100% для GPT-5, с 8% до 30% для Claude-4 и с 83% до 97% для Gemini-2.5-Pro. Эти результаты демонстрируют существенное улучшение надежности и эффективности атаки по сравнению с предыдущими версиями, особенно в отношении моделей Claude-4, где наблюдается наиболее значительный прирост ASR.
Эхо хрупкости: последствия для надёжности и направления будущих исследований
Несмотря на впечатляющие достижения в области обработки естественного языка, современные большие языковые модели (LVLMs) остаются уязвимыми даже к незначительным, едва заметным изменениям во входных данных. Успех M-Attack-V2 демонстрирует, что даже минимальные, тщательно подобранные возмущения способны существенно повлиять на работу этих моделей, приводя к неверным ответам или неожиданному поведению. Этот факт подчеркивает необходимость дальнейших исследований в области надежности и безопасности LVLMs, а также разработки эффективных механизмов защиты от целенаправленных атак, направленных на искажение их работы. Подобные уязвимости указывают на то, что модели, несмотря на кажущуюся «интеллектуальность», опираются на хрупкие закономерности в данных и могут быть легко обмануты при незначительных отклонениях от ожидаемого.
Ограничение возмущений, вводимых в модели, с использованием норм, таких как ℓ∞ норма, остается критически важным аспектом оценки эффективности атак и построения реалистичных моделей угроз. Данный подход позволяет контролировать максимальную величину изменений, вносимых в исходные данные, и, следовательно, оценивать устойчивость больших языковых моделей (LVLM) к незначительным, но целенаправленным искажениям. Использование ℓ∞ нормы гарантирует, что каждое отдельное изменение в данных не превышает определенного порога, что отражает сценарии реальных атак, где злоумышленник ограничен в возможностях внесения масштабных модификаций. Таким образом, оценка устойчивости LVLM при таких ограничениях предоставляет более достоверную картину их надежности и помогает в разработке эффективных методов защиты от враждебных воздействий.
Перспективные исследования должны быть направлены на создание более устойчивых механизмов защиты для больших языковых моделей (LLM). Особое внимание следует уделить разработке методов, позволяющих сертифицировать устойчивость LLM к враждебным атакам. Это предполагает не просто обнаружение атак, но и предоставление формальных гарантий того, что модель сохранит свою производительность даже при незначительных, намеренных изменениях входных данных. Разработка таких методов сертификации потребует новых подходов к анализу уязвимостей и оценке надежности LLM, что, в свою очередь, откроет возможности для создания более безопасных и предсказуемых систем искусственного интеллекта.

Исследование, представленное в данной работе, демонстрирует, что попытки создания абсолютно устойчивых систем, пусть даже и в рамках таких сложных моделей, как Large Vision-Language Models, обречены на провал. Авторы предлагают M-Attack-V2, как способ усилить существующие атаки, подчеркивая нестабильность даже самых передовых методов локального сопоставления. Это напоминает о глубокой мысли Давида Гильберта: «Вся математика — это борьба с неопределенностью». Ведь и в данном случае, совершенствование одной части системы неизбежно порождает новые уязвимости в другой. Попытки оптимизировать производительность и устойчивость, как показывает практика, лишь откладывают неизбежное — появление новых, более изощренных атак, требующих постоянной адаптации и переосмысления архитектуры.
Что Дальше?
Представленная работа, фокусируясь на тонкостях атак на большие визуально-языковые модели, лишь обнажает глубину скрытых взаимосвязей внутри этих сложных систем. Успех M-Attack-V2, достигаемый за счет выравнивания и локального сопоставления, — не триумф атаки, а скорее диагностика уязвимости, заложенной в самой архитектуре. Долгосрочная стабильность модели, ее кажущаяся устойчивость к возмущениям, — это иллюзия, маскирующая неизбежное накопление внутренних напряжений. Каждое уточнение градиента, каждое выравнивание патчей — это пророчество о будущей точке бифуркации.
Не стоит обольщаться улучшением показателей переноса атак. Это не укрепление защиты, а лишь смещение фронта. Истинная проблема заключается не в преодолении конкретных методов атаки, а в фундаментальной неспособности этих моделей к самовосстановлению. Система не «защищается» — она эволюционирует в неожиданные формы, подстраиваясь под новые угрозы, но при этом неизбежно теряя часть своей изначальной функциональности.
Будущие исследования, вероятно, будут направлены на создание более устойчивых архитектур, но это — путь иллюзий. Более продуктивным представляется изучение механизмов контролируемой деградации, способов предсказания и смягчения последствий неизбежных сбоев. Истинная цель — не построить идеальную систему, а научиться сосуществовать с ее несовершенством, признавая ее как живой, эволюционирующий организм.
Оригинал статьи: https://arxiv.org/pdf/2602.17645.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок: от лаборатории к рынку
2026-02-23 03:44