Автор: Денис Аветисян
Новое исследование показывает, что обучение моделей на более простых задачах и грамотная настройка системы вознаграждений позволяет значительно повысить эффективность их рассуждений и снизить вычислительные затраты.

В статье рассматриваются методы оптимизации больших языковых моделей с помощью обучения на данных различной сложности и формирования эффективных сигналов вознаграждения.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в цепях рассуждений (Chain-of-Thought), их вычислительная сложность остается серьезной проблемой. В данной работе, ‘The Art of Efficient Reasoning: Data, Reward, and Optimization’, систематически исследуются механизмы эффективного рассуждения, направленные на снижение этой сложности. Ключевым результатом является установление двухэтапного характера обучения — адаптации длины и уточнения рассуждений — при эффективном формировании вознаграждения и использовании данных различной сложности. Какие стратегии обучения и оптимизации позволят в полной мере реализовать потенциал LLM, обеспечивая как высокую точность, так и экономичность вычислений?
За гранью простого масштабирования: проблема эффективного рассуждения в больших языковых моделях
Несмотря на впечатляющие успехи больших языковых моделей (БЯМ), достижение действительно эффективного рассуждения остается серьезной проблемой, ограничивающей их масштабируемость и практическое применение. БЯМ часто демонстрируют способность генерировать текст, имитирующий разумные ответы, однако их способность к логическому выводу, решению проблем и адаптации к новым ситуациям остается несовершенной. Это связано с тем, что обучение таких моделей требует огромных вычислительных ресурсов и больших объемов данных, а также с тем, что существующие архитектуры не всегда оптимальны для сложных когнитивных задач. Ограниченная эффективность рассуждений приводит к увеличению времени обработки запросов, повышению стоимости вычислений и снижению надежности результатов, что препятствует широкому внедрению БЯМ в критически важные приложения, такие как научные исследования, медицинская диагностика и автономные системы.
Несмотря на впечатляющие успехи больших языковых моделей, традиционные методы масштабирования, такие как увеличение количества параметров и объема обучающих данных, демонстрируют тенденцию к уменьшению отдачи. Дальнейшее наращивание вычислительных ресурсов не обеспечивает пропорционального улучшения способности к логическому мышлению, что приводит к возрастающим затратам и замедлению работы. В связи с этим, все больше внимания уделяется разработке инновационных подходов к оптимизации процессов рассуждения, направленных на повышение эффективности и скорости обработки информации при сохранении или снижении вычислительных издержек. Исследования в этой области фокусируются на алгоритмических улучшениях, таких как более эффективные механизмы внимания и методы сжатия моделей, а также на разработке специализированных архитектур, способных выполнять сложные логические операции с минимальными ресурсами.
Современные языковые модели, несмотря на впечатляющие успехи в обработке естественного языка, часто демонстрируют ограниченную глубину рассуждений, особенно при решении сложных задач, требующих последовательного, многоступенчатого вывода. Эта проблема проявляется в неспособности модели поддерживать логическую цепочку на протяжении нескольких шагов, приводя к ошибкам в заключении и снижению общей точности. Исследования показывают, что модели склонны к упрощению сложных проблем или неспособности учесть все необходимые факторы при принятии решения. Ограниченная глубина рассуждений представляет собой серьезное препятствие для применения этих моделей в областях, требующих высокой степени надежности и обоснованности, таких как научные исследования, финансовый анализ и принятие критически важных решений.
Двухэтапный подход: разделяй и властвуй в логическом выводе
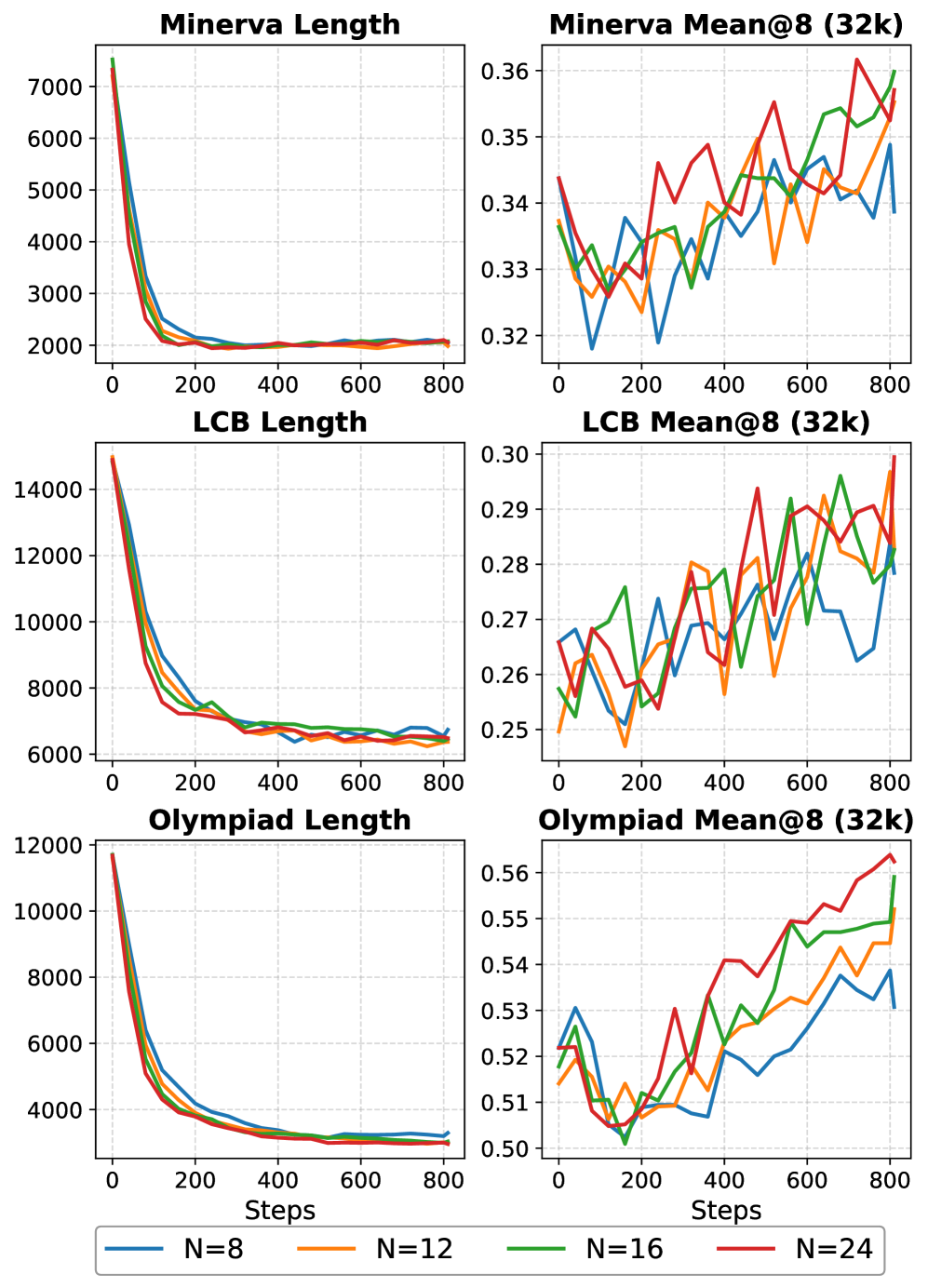
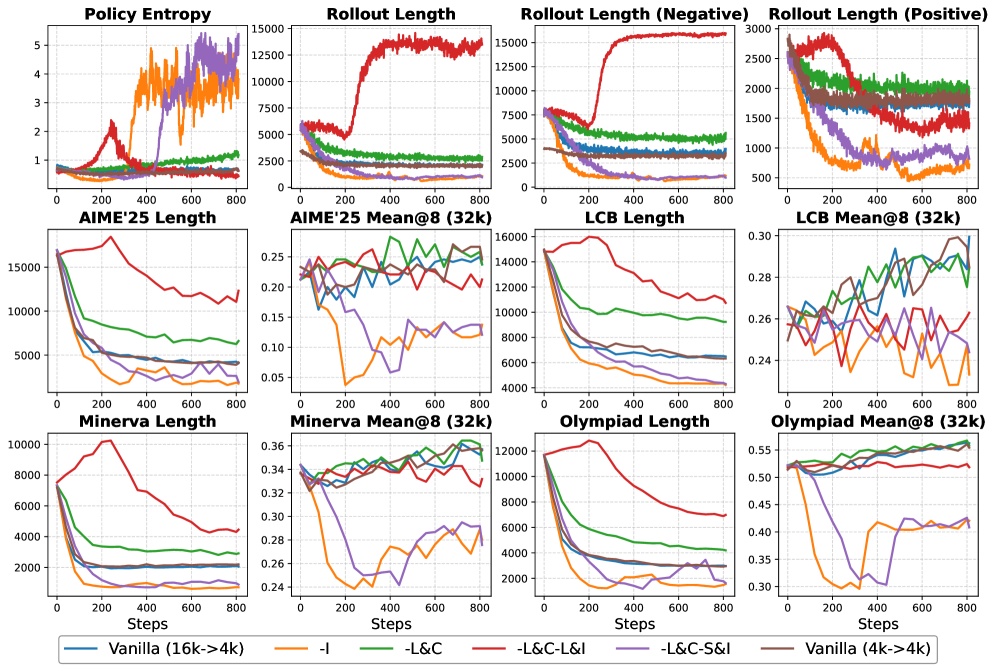
Недавние исследования выявили последовательную двухэтапную парадигму обучения для повышения эффективности рассуждений: первоначальная адаптация к требуемой длине ответа, за которой следует уточнение качества самих рассуждений. Этот подход предполагает раздельное обучение модели генерации текста определенной длины и, на втором этапе, оптимизацию логической связности и корректности представленных аргументов. Наблюдается, что предварительное обучение контролю длины позволяет стабилизировать процесс обучения и повысить общую производительность модели в задачах, требующих логического вывода и анализа.
Наблюдаемая двухэтапная парадигма обучения больших языковых моделей отражает естественный процесс освоения навыков: сначала модель учится контролировать длину генерируемых ответов, оптимизируя параметры для достижения желаемого объема текста. Только после стабилизации контроля над длиной происходит фокусировка на улучшении качества рассуждений и логической связности внутри этих ограничений. Этот подход позволяет модели последовательно развивать навыки, сначала осваивая базовый аспект — длину — а затем переходя к более сложной задаче — обеспечению содержательности и точности.
Разделение контроля над длиной генерируемого текста и качеством рассуждений позволяет добиться большей стабильности процесса обучения. Традиционно, модели обучаются одновременно оптимизировать оба параметра, что приводит к колебаниям и затрудняет сходимость. Изолируя контроль длины на первом этапе, можно добиться предсказуемой генерации текстов заданной длины, создавая более устойчивую основу для последующей оптимизации качества рассуждений. Такой подход позволяет целенаправленно улучшать каждый аспект модели, используя различные функции потерь и стратегии обучения, что в итоге повышает общую производительность и эффективность.
Подкрепление и вознаграждение: наведение модели на путь истинного рассуждения
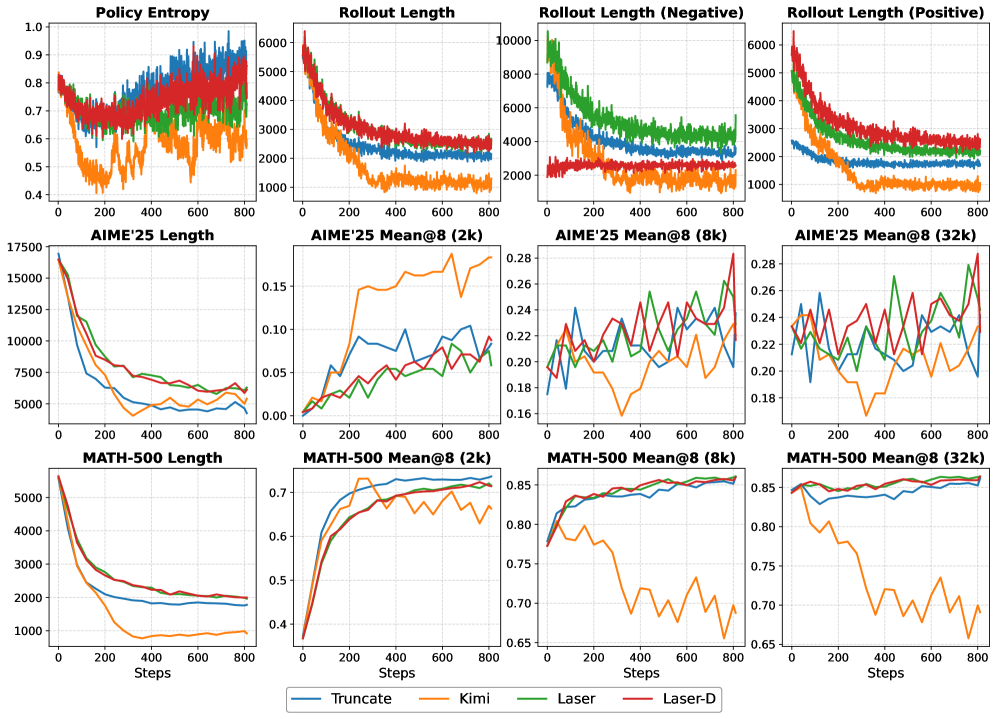
Обучение с подкреплением предоставляет эффективный механизм для стимулирования логического мышления посредством формирования вознаграждения, основанного на длине цепочки рассуждений и её корректности. Данный подход позволяет назначать более высокое вознаграждение за короткие и правильные решения, тем самым направляя модель к оптимальным стратегиям рассуждений. Оценка вознаграждения напрямую зависит от длины последовательности действий, предпринятых моделью для достижения цели, и от того, насколько точно эти действия соответствуют правильному ответу. Это позволяет модели оптимизировать процесс рассуждений, избегая излишне длинных или ошибочных цепочек и фокусируясь на наиболее эффективных путях решения задачи.
Эффективное формирование вознаграждения, включающее стратегии усечения (truncation), предусматривает применение штрафных санкций к длинным или неверным последовательностям рассуждений. Это стимулирует модель к поиску лаконичных и точных решений, минимизируя вычислительные затраты и повышая эффективность процесса обучения. Усечение позволяет ограничить длину генерируемых последовательностей, а штрафы за неверные ответы направляют модель к более надежным и корректным результатам. Таким образом, оптимизация вознаграждения способствует более быстрому схождению модели и улучшению ее производительности в задачах, требующих логического вывода и решения проблем.
Использование наборов данных, таких как DeepScaleR, и методов оптимизации вне политики (Off-Policy Optimization) значительно повышает эффективность исследования пространства наград и ускоряет процесс обучения в задачах обучения с подкреплением. DeepScaleR предоставляет обширный набор данных, позволяющий моделировать различные сценарии и оценивать эффективность стратегий. Оптимизация вне политики позволяет использовать данные, собранные в процессе обучения с использованием различных политик, что увеличивает эффективность использования данных и сокращает время, необходимое для достижения оптимальной производительности. Это особенно важно в задачах с разреженными наградами, где эффективное исследование пространства состояний является критически важным.
Бенчмаркинг и эффективность: проверка на прочность в реальных задачах
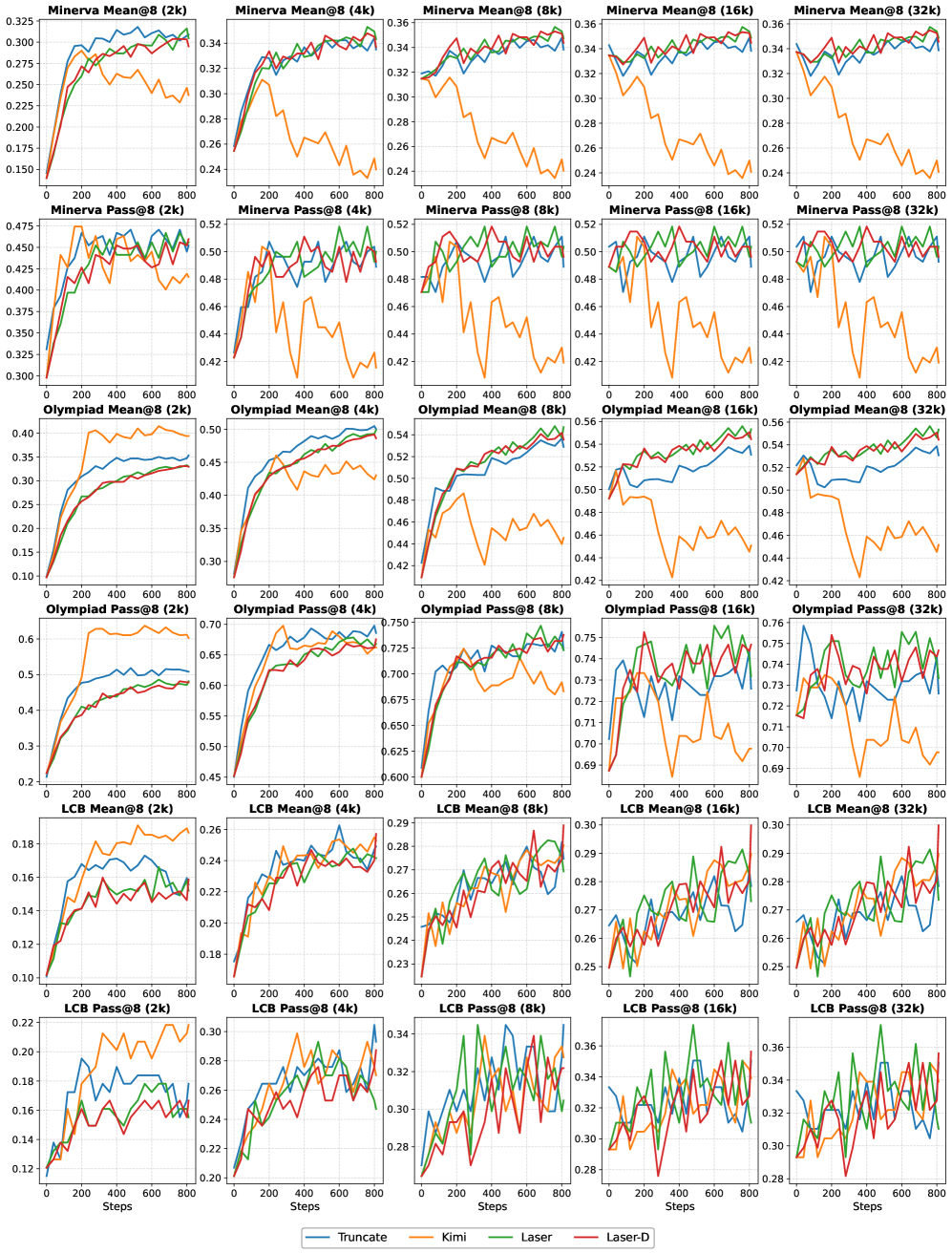
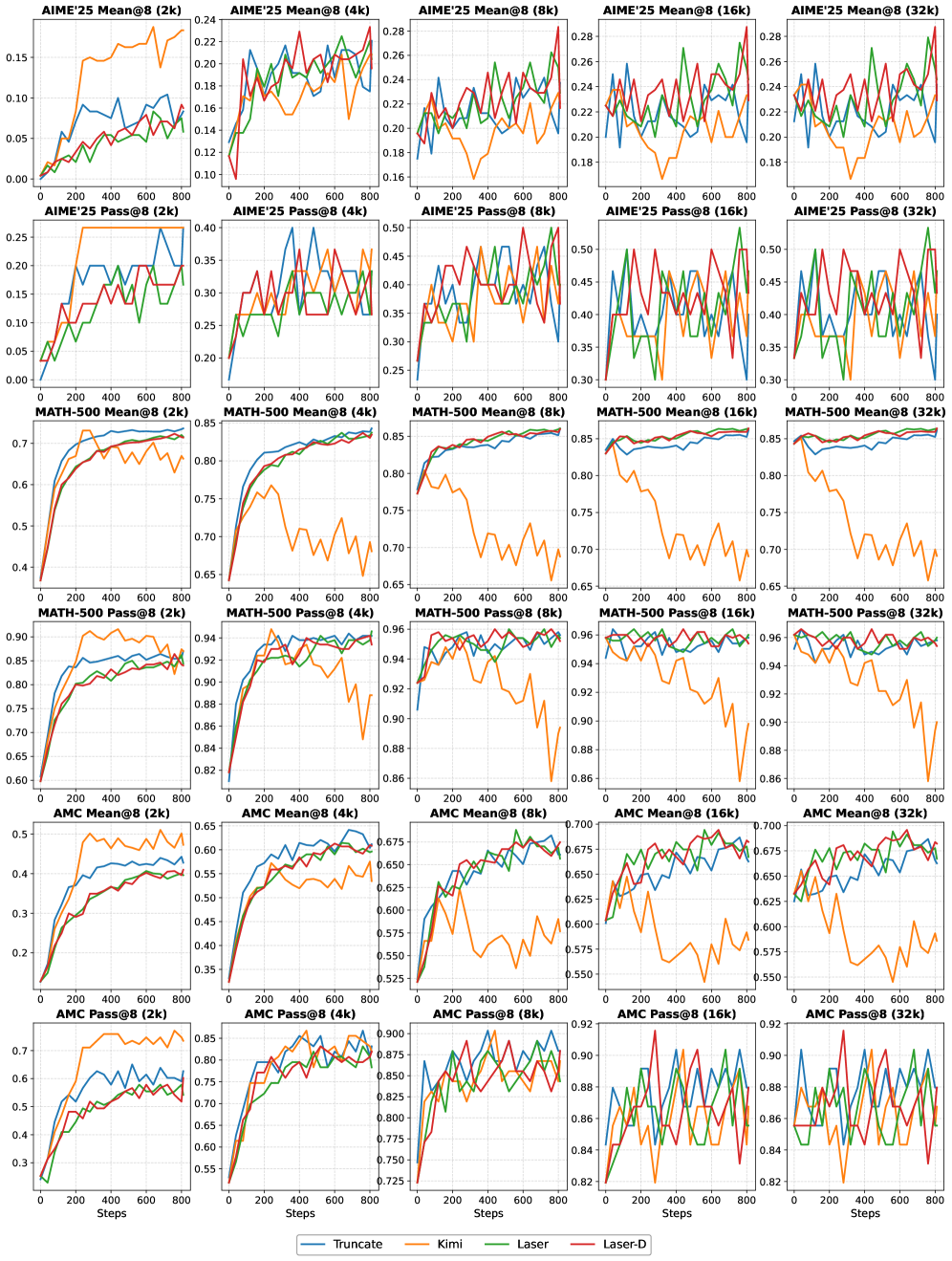
Оценка эффективности больших языковых моделей (LLM) с учетом ограничений по количеству токенов — критически важный аспект при проведении сравнительного анализа. Традиционные метрики производительности часто не учитывают стоимость генерации ответов, что может привести к нереалистичной оценке практической применимости моделей. Бюджетно-ориентированное тестирование позволяет оценить производительность LLM при различных ограничениях на длину ответа, моделируя сценарии, в которых ресурсы ограничены или стоимость генерации токенов высока. Такой подход позволяет более точно оценить эффективность модели, ее способность предоставлять качественные ответы в условиях ограниченного бюджета токенов, и определить оптимальный баланс между длиной ответа и его точностью.
Оценка производительности проводится на сложных бенчмарках, включающих MATH-500, AIME и LiveCodeBench. MATH-500 представляет собой набор из 500 математических задач, требующих многоступенчатых вычислений и логического мышления. AIME (American Invitational Mathematics Examination) — это конкурсный математический экзамен, проверяющий навыки решения сложных задач. LiveCodeBench предназначен для оценки возможностей генерации кода и решения задач программирования. Использование этих бенчмарков позволяет комплексно оценить способность языковых моделей к математическому рассуждению и генерации кода, охватывая широкий спектр сложностей и требующих различных подходов к решению.
В результате применения данной методики оценки производительности наблюдались значительные улучшения. В частности, модель Qwen3-0.6B продемонстрировала значение Mean@8, равное 24.58, что на 11.25 пункта выше базового показателя в 13.33. Одновременно с этим, средняя длина генерируемых ответов была сокращена с 14.9 тысяч токенов до 8.9 тысяч токенов, что свидетельствует о повышении эффективности модели при сохранении качества решения задач.
Модель Qwen3-4B-Instruct-2507 продемонстрировала значительные результаты в оценке эффективности, достигнув среднего значения Mean@8 в 46.67 и Pass@8 в 70.00. Эти показатели свидетельствуют о высокой точности и надежности модели в решении сложных задач. Важно отметить, что средняя длина ответа модели была сокращена до 4.8k токенов с 9.1k токенов, что указывает на повышение эффективности и снижение вычислительных затрат без ущерба для качества решения.
Взгляд в будущее: разворачивая мощь интеллекта на периферии
Оптимизация процессов логического вывода позволяет развертывать мощные языковые модели на устройствах с ограниченными ресурсами, что значительно расширяет их доступность и сферу применения. Ранее сложные вычисления, требовавшие мощных серверов, теперь могут выполняться непосредственно на смартфонах, ноутбуках и других портативных устройствах. Это открывает возможности для создания персональных ассистентов, способных решать сложные задачи в режиме реального времени, а также для внедрения интеллектуальных систем в области образования, здравоохранения и других отраслях, где доступ к вычислительным ресурсам может быть ограничен. Такой подход не только снижает затраты на инфраструктуру, но и повышает конфиденциальность данных, поскольку обработка информации происходит локально, без необходимости передачи её на удалённые серверы.
Двухэтапный подход в сочетании с методами обучения с подкреплением представляет собой перспективный путь к созданию более устойчивых и масштабируемых систем искусственного интеллекта. В данной парадигме, модель сначала генерирует предварительный ответ, а затем, на втором этапе, оценивает и улучшает его, используя обратную связь в виде вознаграждения. Такой подход позволяет значительно сократить вычислительные затраты по сравнению с прямым обучением, поскольку фокус смещается на оптимизацию процесса рассуждений, а не на перебор всех возможных вариантов. Использование обучения с подкреплением позволяет модели самостоятельно находить наиболее эффективные стратегии рассуждений, адаптируясь к различным задачам и условиям. В результате, создаются системы, которые не только способны решать сложные задачи, но и делают это более экономично и эффективно, открывая возможности для их развертывания на устройствах с ограниченными ресурсами и расширения сферы применения искусственного интеллекта.
Перспективные исследования в области эффективного рассуждения больших языковых моделей (LLM) должны быть сосредоточены на разработке инновационных стратегий формирования вознаграждений. Существующие методы часто оказываются недостаточно эффективными для стимулирования LLM к оптимальному пошаговому решению задач, что ограничивает их производительность и масштабируемость. Параллельно с этим, критически важна разработка более надежных оценочных критериев. Нынешние бенчмарки нередко не способны адекватно оценить сложность рассуждений и склонны к предвзятости, что затрудняет объективное сравнение различных подходов. Разработка комплексных и разнообразных тестов, охватывающих широкий спектр когнитивных задач, позволит более точно измерить прогресс в области эффективного рассуждения и выявить наиболее перспективные направления для дальнейших исследований, способствуя созданию действительно интеллектуальных и устойчивых систем искусственного интеллекта.
Исследование демонстрирует, что даже самые продвинутые языковые модели нуждаются в тонкой настройке, а не просто в увеличении масштаба. Авторы предлагают подход к формированию вознаграждений и упрощению обучающих данных, что позволяет добиться большей эффективности при меньших вычислительных затратах. В этом нет ничего удивительного. Как однажды заметил Винтон Серф: «Интернет — это просто способ обмениваться информацией, и люди всегда найдут способ это сделать, даже если это будет сложно и неудобно». Истина проста: элегантная теория быстро столкнется с реальностью, где данные — это всегда компромисс, а оптимизация — вечная борьба с энтропией. И если модель вдруг заработала — значит, просто ещё не встретила достаточно сложных запросов.
Что дальше?
Статья демонстрирует, что «эффективное рассуждение» в больших языковых моделях — это, по сути, умение обманывать метрики на более простых задачах. Не стоит обольщаться — рано или поздно, датасеты усложнятся, а «лёгкие» подсказки перестанут работать. И тогда, вся эта оптимизация вознаграждений окажется лишь очередным слоем техдолга, который придётся расхлёбывать. Разумеется, новые архитектуры, новые функции потерь — всё это, несомненно, появится. Но проблема останется: как заставить машину не просто генерировать правдоподобный текст, а действительно понимать, что она делает.
Особое внимание следует уделить длине токенов. Сейчас это, кажется, просто удобный способ сократить вычислительные затраты. Но что, если истинная причина улучшения производительности — не в оптимизации вознаграждений, а в том, что модели просто «забывают» контекст, когда он становится слишком длинным? Вполне вероятно, что будущие исследования покажут, что «эффективное рассуждение» — это просто короткая память, замаскированная под интеллект.
Иногда лучше монолит, чем сто микросервисов, каждый из которых врёт. И, возможно, иногда лучше более простая модель, которая честно признаёт свою некомпетентность, чем сложная, которая пытается казаться умнее, чем есть на самом деле. В конечном счёте, всё вернётся к фундаментальным ограничениям вычислительных ресурсов и к той простой истине, что идеальной модели не существует.
Оригинал статьи: https://arxiv.org/pdf/2602.20945.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
2026-02-25 19:57