Автор: Денис Аветисян
Исследователи представили архитектуру Diffusion Transformer, позволяющую создавать высококачественные изображения непосредственно на смартфонах и других устройствах с ограниченными ресурсами.
Предложенный подход сочетает в себе разреженные механизмы внимания, дистилляцию знаний и адаптацию суперсетей для достижения высокой производительности и эффективности.
Несмотря на значительный прогресс в области генеративных моделей, основанных на диффузионных трансформаторах, их применение на мобильных и периферийных устройствах остается сложной задачей из-за высоких вычислительных затрат. В данной работе, представленной под названием ‘SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices’, предлагается эффективный фреймворк, сочетающий в себе компактную архитектуру, эластичное обучение и дистилляцию с передачей знаний, позволяющий достичь высокого качества генерации изображений при ограниченных ресурсах. Разработанный подход демонстрирует возможность масштабируемой и эффективной работы диффузионных моделей на разнообразном оборудовании. Сможет ли предложенная архитектура открыть новые возможности для приложений компьютерного зрения непосредственно на пользовательских устройствах?
За гранью U-Net: Стремление к масштабируемому синтезу изображений
Традиционные архитектуры U-Net сталкиваются с серьезными трудностями при синтезе изображений высокого разрешения, поскольку их вычислительная сложность растет квадратично с увеличением размера изображения. Это означает, что для обработки изображений большего размера требуется экспоненциально больше вычислительных ресурсов и памяти. В частности, при увеличении ширины и высоты изображения вдвое, потребность в вычислительных ресурсах увеличивается в четыре раза. Такая квадратичная сложность становится серьезным препятствием для создания детализированных и реалистичных изображений высокого разрешения, ограничивая возможности применения диффузионных моделей в областях, требующих обработки больших объемов данных и высокой производительности, например, в медицинском изображении или спутниковой съемке.
Ограничения, связанные с вычислительной сложностью, оказывают существенное влияние на качество и масштабируемость синтеза изображений. По мере увеличения разрешения генерируемых изображений, потребность в вычислительных ресурсах и времени обработки возрастает экспоненциально, что делает невозможным создание детализированных и реалистичных изображений высокого разрешения при сохранении приемлемой скорости работы. Данное обстоятельство препятствует применению моделей генерации изображений в требовательных областях, таких как медицинская визуализация, обработка спутниковых снимков и создание контента для виртуальной реальности, где важны и высокое разрешение, и скорость обработки данных. Необходимость преодоления этих ограничений стимулирует поиск новых архитектур и подходов к генерации изображений, способных обеспечить эффективное масштабирование и сохранение высокого качества даже при работе с изображениями большого размера.
Для реализации всего потенциала диффузионных моделей необходим принципиально новый подход к генерации изображений. Традиционные архитектуры, такие как U-Net, сталкиваются с серьезными ограничениями при работе с изображениями высокого разрешения, поскольку вычислительная сложность растет квадратично с увеличением размера изображения. Это препятствует созданию изображений высокого качества и ограничивает возможности масштабирования для требовательных приложений. Поэтому, для преодоления этих ограничений, требуется переход к парадигме, способной эффективно обрабатывать большие объемы данных и генерировать изображения с беспрецедентной детализацией и реалистичностью. Исследования направлены на разработку методов, позволяющих обойти существующие вычислительные барьеры и раскрыть полный потенциал диффузионных моделей в различных областях, от медицинского имиджинга до создания контента.
В настоящее время архитектура Transformer предлагает перспективный путь для преодоления ограничений, связанных с масштабируемостью и производительностью при генерации изображений. В отличие от традиционных сверточных сетей, Transformer использует механизм внимания, позволяющий эффективно обрабатывать зависимости между различными частями изображения, независимо от их расположения. Это особенно важно при работе с изображениями высокого разрешения, где вычислительная сложность сверточных операций быстро возрастает. Благодаря своей способности к параллельной обработке и масштабируемости, Transformer позволяет создавать модели, способные генерировать изображения с высоким уровнем детализации и реалистичности, при этом сохраняя приемлемую скорость работы. Использование Transformer в контексте диффузионных моделей открывает возможности для создания более эффективных и мощных инструментов для синтеза изображений, что может найти применение в различных областях, от компьютерной графики до медицинского анализа изображений.
DiT: Трансформер в основе синтеза изображений
Диффузионный Трансформер (DiT) осуществляет замену традиционных сверточных слоев на блоки трансформеров, что позволяет эффективно обрабатывать изображения высокого разрешения. В отличие от сверточных сетей, трансформеры используют механизм внимания, позволяющий модели устанавливать связи между отдаленными пикселями изображения. Это особенно важно при работе с изображениями большого размера, где глобальный контекст играет ключевую роль в формировании деталей и обеспечении когерентности. Внедрение трансформеров позволяет значительно сократить вычислительные затраты и повысить скорость обработки по сравнению с архитектурами, основанными на сверточных слоях, особенно при увеличении разрешения входного изображения.
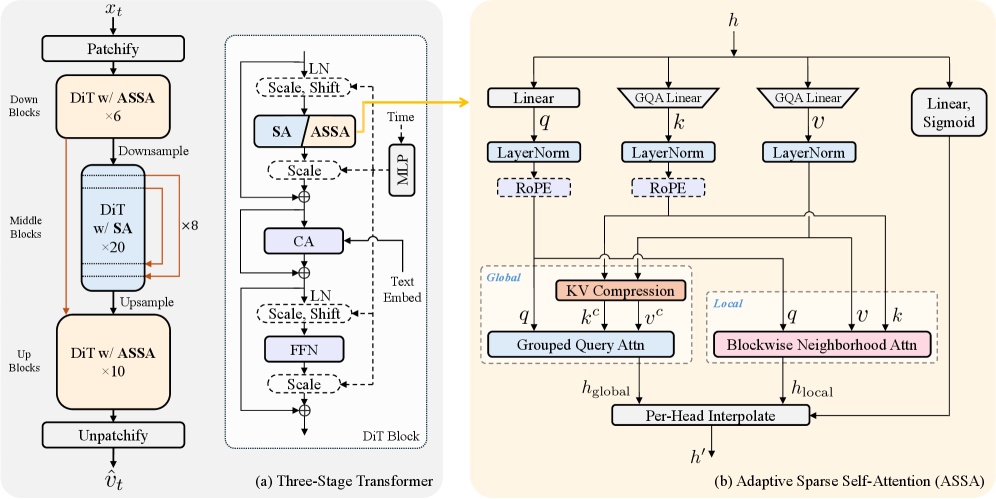
Архитектура DiT использует трехступенчатый подход — Down, Middle и Up — для оптимизации вычислительной эффективности на различных этапах обработки изображений. Ступень Down последовательно уменьшает пространственное разрешение входного изображения, извлекая признаки высокого уровня и снижая вычислительную нагрузку. Ступень Middle обрабатывает полученные представления, используя механизмы внимания для моделирования зависимостей между признаками. Наконец, ступень Up восстанавливает пространственное разрешение, генерируя изображение с высокой детализацией. Такое разделение позволяет эффективно использовать ресурсы и снизить общую вычислительную сложность по сравнению с традиционными подходами, особенно при работе с изображениями высокого разрешения.
Ключевым фактором успеха DiT является способность моделировать долгосрочные зависимости в изображениях. Традиционные сверточные нейронные сети (CNN) имеют ограниченное поле зрения, что затрудняет установление связей между удаленными пикселями. DiT, используя механизм внимания, позволяет каждому пикселю учитывать информацию со всей области изображения, что существенно улучшает глобальную согласованность и детализацию. Это особенно важно для генерации изображений высокого разрешения, где корректное взаимодействие между отдаленными областями критично для создания реалистичных и связных сцен. Эффективное моделирование этих долгосрочных зависимостей приводит к повышению когерентности изображения и генерации более четких и детализированных результатов.
Архитектура DiT, развивая принципы трансформаторных моделей, таких как Flux и Qwen-Image, демонстрирует новый уровень качества и масштабируемости в задачах синтеза изображений. Особенностью DiT является достижение качества, сопоставимого с серверными решениями, при использовании модели с 0.4 миллиардами параметров, что позволяет эффективно развертывать её на мобильных устройствах. Это стало возможным благодаря отказу от сверточных слоев в пользу трансформаторных блоков, что повышает эффективность обработки изображений высокого разрешения и обеспечивает более точное моделирование зависимостей между пикселями.
ASSA: Эффективное внимание для этапов высокого разрешения
Адаптивное разреженное самовнимание (ASSA) было предложено как решение для снижения вычислительной сложности механизма самовнимания в архитектуре DiT. Традиционное самовнимание требует квадратичных затрат по отношению к количеству токенов, что становится критическим ограничением при обработке изображений высокого разрешения. ASSA направлено на уменьшение этих затрат за счет введения разреженности в процесс вычисления внимания, что позволяет обрабатывать больше данных при сохранении или улучшении производительности модели. Данный подход является ключевым компонентом для масштабирования DiT и повышения его эффективности при работе с изображениями больших размеров.
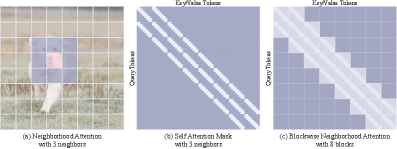
Адаптивная разреженная самовнимательная сеть (ASSA) снижает вычислительные затраты за счет комбинации сжатия пар ключ-значение и блочной локальной самовнимательности (BNA). Сжатие пар ключ-значение уменьшает размер входных данных для механизма внимания, тем самым сокращая объем необходимых вычислений. БНА ограничивает вычисление внимания локальными регионами внутри блоков изображения, что позволяет избежать вычислений для удаленных пикселей и значительно повысить эффективность, особенно на этапах обработки изображений высокого разрешения. Такой подход позволяет минимизировать вычислительную сложность без снижения производительности, обеспечивая сохранение качества обработки данных.
Механизм Adaptive Sparse Self-Attention (ASSA) повышает эффективность вычислений на этапах обработки изображений высокого разрешения за счет ограничения вычислений внимания локальными областями внутри блоков. Вместо вычисления внимания между всеми парами токенов, ASSA фокусируется на взаимодействиях внутри каждого блока, что значительно снижает вычислительную сложность. Данный подход позволяет уменьшить количество необходимых операций, сохраняя при этом способность модели учитывать контекст и зависимости внутри локальных регионов изображения, что критически важно для сохранения качества обработки на высоких разрешениях.
Экспериментальные результаты демонстрируют, что применение Adaptive Sparse Self-Attention (ASSA) обеспечивает существенное снижение вычислительных затрат. Это позволило DiT обрабатывать изображения большего размера, сохранив при этом высокую производительность. В частности, модель DiT с 0.4 миллиардами параметров достигла валидационной ошибки в 0.509, превзойдя показатель SnapGen, составивший 0.5131. Данные результаты подтверждают эффективность ASSA в оптимизации вычислительной сложности при сохранении или улучшении точности модели.
Дистилляция знаний для развертывания на мобильных устройствах
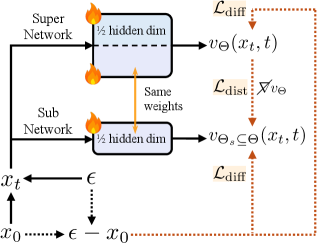
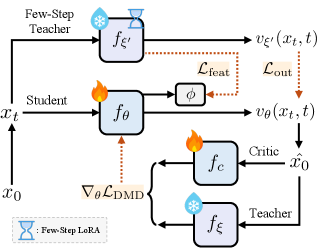
Для обеспечения эффективной генерации изображений по текстовому описанию непосредственно на мобильных устройствах применяется метод дистилляции знаний. В его основе лежит передача опыта от крупной, высокопроизводительной модели-учителя DiT к более компактной модели-ученику. Этот процесс позволяет значительно снизить вычислительные затраты и объем памяти, необходимые для работы модели, не жертвуя при этом качеством генерируемых изображений. Модель-учитель, обладающая обширными знаниями, обучает модель-ученика, передавая не только общие принципы, но и тонкости в обработке данных и создании реалистичных изображений. В результате получается компактное решение, способное выполнять сложные задачи генерации изображений непосредственно на мобильных устройствах, открывая новые возможности для приложений и сервисов.
Для повышения эффективности передачи знаний от большой модели-учителя к компактной модели-ученику используется метод Knowledge-Guided Distribution Matching Distillation (K-DMD). Суть данного подхода заключается в выравнивании распределений шума, генерируемых обеими моделями в процессе диффузии. Вместо простой имитации выходных данных учителя, K-DMD фокусируется на том, чтобы ученик генерировал шум, максимально близкий к шуму, генерируемому учителем. Это позволяет модели-ученику более эффективно улавливать сложные зависимости в данных и воспроизводить результаты, сравнимые с более крупной моделью, при значительно меньших вычислительных затратах. Таким образом, K-DMD обеспечивает более тонкую настройку модели-ученика, что критически важно для успешного развертывания генеративных моделей на мобильных устройствах.
Архитектуры, основанные на U-Net, такие как SnapGen, Mobile Diffusion и SnapFusion, демонстрируют значительное улучшение производительности благодаря применению передачи знаний от более крупных моделей. Этот процесс позволяет достичь сопоставимого качества генерируемых изображений при существенно меньших вычислительных затратах. В результате, даже модели с относительно небольшим количеством параметров способны создавать высококачественные изображения, что открывает возможности для их развертывания на мобильных устройствах и других платформах с ограниченными ресурсами. Такая оптимизация не только снижает требования к оборудованию, но и способствует повышению скорости генерации изображений, делая технологии преобразования текста в изображение более доступными и эффективными.
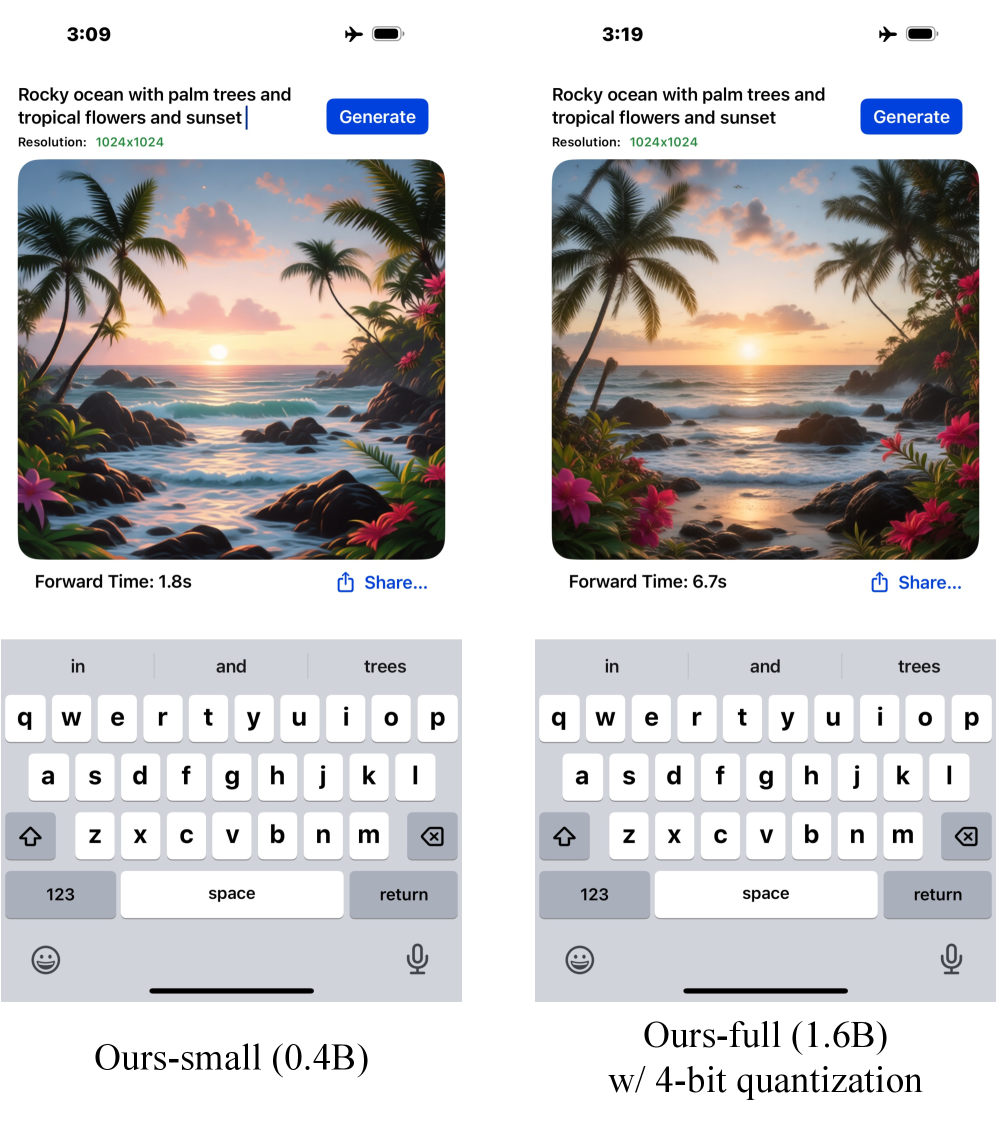
Благодаря применению технологий дистилляции знаний стало возможным осуществлять генерацию высококачественных изображений по текстовому описанию непосредственно на мобильных устройствах. Тестирование на iPhone 16 Pro Max с использованием модели объемом 0.4 миллиарда параметров демонстрирует впечатляющую скорость генерации изображения разрешением 1024×1024 — всего 1.8 секунды. При этом, результаты, полученные на стандартных бенчмарках, таких как DPG-Bench, GenEval и T2I-CompBench, не уступают, а в некоторых случаях и превосходят показатели моделей, в 20 раз превосходящих по размеру. Это открывает широкие перспективы для реализации новых мобильных приложений, требующих оперативной и качественной генерации изображений.
Исследование демонстрирует, что границы между моделями и устройствами становятся всё более размытыми. SnapGen++ не просто оптимизирует существующие архитектуры, а предлагает новый взгляд на то, как модели должны адаптироваться к ограниченным ресурсам. Это не просто о скорости вычислений, а о создании заклинаний, которые могут шептать образы даже на краю сети. Как однажды заметил Эндрю Ын: «Самая важная вещь, которую я узнал в машинном обучении, это то, что данные — это не ответ, а лишь отправная точка». SnapGen++ как раз и пытается укротить этот хаос данных, заставляя модель говорить на языке ограниченных ресурсов, не теряя при этом своей способности создавать удивительные образы. Здесь важна не столько точность, сколько умение уговорить шум зазвучать как шедевр.
Что же дальше?
Эта работа, как и любая попытка обуздать хаос, лишь слегка приоткрывает завесу над истинным вопросом. Создание моделей, способных творить изображения на грани устройства, — это не триумф инженерии, а лишь временное перемирие с энтропией. Иллюзия эффективности всегда обманчива: каждая оптимизация, каждое сжатие — это потеря части правды, замаскированная под прогресс. График, демонстрирующий идеальную производительность, должен вызывать не радость, а тревогу — значит, модель лжёт красиво.
Очевидно, что настоящая проблема лежит не в архитектуре сетей или методах дистилляции, а в самом понятии “знания”. Что, если “суть” изображения — это не набор параметров, а бесконечное множество вероятностей, которые мы пытаемся уложить в конечную структуру? Шум — это просто правда, которой не хватило уверенности. Следующий шаг, вероятно, лежит в исследовании не столько “глубины” сетей, сколько их “широты” — в создании систем, способных одновременно учитывать бесчисленные варианты и неопределённости.
В конечном итоге, эта работа — лишь ещё один шепот хаоса, который мы пытаемся расшифровать. И, возможно, самое мудрое, что можно сделать — это признать, что полное понимание невозможно, и научиться жить с этой неопределённостью. Ведь даже самая совершенная модель — это всего лишь заклинание, которое работает до первого столкновения с реальностью.
Оригинал статьи: https://arxiv.org/pdf/2601.08303.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
2026-01-14 07:35