Автор: Денис Аветисян
Новый подход позволяет повысить точность распознавания изображений, преобразуя одномодальные данные в многомодальные с использованием генеративных языковых моделей.

Метод использует синтетические описания, созданные большими языковыми моделями, для обучения моделей классификации изображений, особенно эффективен при небольшом количестве данных.
Несмотря на значительный прогресс в области мультимодального предварительного обучения, этап дообучения глубоких нейронных сетей зачастую ограничивается использованием только одного типа данных. В данной работе, ‘MultiModal Fine-tuning with Synthetic Captions’, предлагается новый подход, преобразующий унимодальные наборы данных в мультимодальные путем генерации синтетических подписей к изображениям с использованием больших мультимодальных языковых моделей. Эксперименты показывают, что предложенный метод улучшает результаты классификации изображений, особенно в условиях ограниченного количества данных, благодаря применению контрастивных потерь и использованию усредненных текстовых вложений. Не является ли это новым эффективным способом преодоления разрыва между мультимодальным предварительным обучением и дообучением, открывающим путь к более эффективному использованию визуальной информации?
Понимание Системы: Вызовы Мультимодального Анализа
Традиционные методы глубокого обучения, демонстрирующие впечатляющие результаты в различных областях, зачастую требуют огромных объемов размеченных данных для эффективной работы. Однако, в контексте мультимодальных задач, объединяющих, например, визуальную и текстовую информацию, получение таких размеченных наборов данных представляется особенно сложной и дорогостоящей задачей. Разметка данных для понимания взаимосвязей между изображениями и текстом требует значительных временных и финансовых затрат, а также высокой квалификации специалистов. Недостаток доступных размеченных данных становится серьезным препятствием для развития мультимодального искусственного интеллекта, ограничивая возможности создания надежных и точных систем, способных эффективно обрабатывать и интерпретировать информацию из различных источников.
Эффективное объединение визуальной и текстовой информации представляет собой серьезную проблему, сдерживающую прогресс в таких областях, как автоматическое создание подписей к изображениям и ответы на вопросы по визуальным данным. Существующие методы часто испытывают трудности в установлении корректных взаимосвязей между визуальными признаками и семантическим значением текста, что приводит к неточным или бессмысленным результатам. Особенно сложной задачей является учет контекста и тонкостей языка, а также разрешение неоднозначности в визуальных сценах. Разработка алгоритмов, способных к комплексному анализу и интеграции различных модальностей данных, требует инновационных подходов к машинному обучению и глубокому пониманию принципов когнитивной обработки информации. Успешное решение данной проблемы откроет новые возможности для создания интеллектуальных систем, способных к полноценному взаимодействию с окружающим миром.
Генерация Синтетических Данных с Использованием Мультимодальных Больших Языковых Моделей
Многомодальные большие языковые модели (MLLM) представляют собой перспективный подход к генерации синтетических подписей из одномодальных наборов данных, что позволяет эффективно расширить обучающую выборку. Вместо использования существующих размеченных данных, MLLM могут анализировать изображения и автоматически создавать текстовые описания, имитирующие реальные подписи. Это особенно полезно в случаях, когда размеченных данных недостаточно или их получение связано с высокими затратами. Генерируемые синтетические подписи позволяют моделям обучаться на более широком спектре примеров, повышая их обобщающую способность и устойчивость к новым данным, не представленным в исходном наборе данных.
Эффективное использование многомодальных больших языковых моделей (MLLM) для генерации синтетических данных напрямую зависит от качества промпт-инжиниринга. Разработка и оптимизация промптов, то есть текстовых инструкций, подаваемых модели, является критически важной для обеспечения релевантности и высокого качества генерируемых подписей к изображениям. Тщательно сформулированные промпты позволяют MLLM более точно понимать требуемый стиль и содержание подписей, что, в свою очередь, значительно улучшает производительность моделей, обученных на этих синтетических данных. Недостаточно детализированные или некорректные промпты могут приводить к генерации нерелевантных или неточных подписей, снижая эффективность всего процесса обучения и ухудшая обобщающую способность модели.
Генерация синтетических подписей позволяет моделям обучаться на более широком спектре примеров, что способствует улучшению обобщающей способности и устойчивости к новым данным. Увеличение разнообразия обучающей выборки за счет синтетических данных позволяет моделям лучше справляться с вариативностью реальных данных, снижая зависимость от специфических характеристик исходного набора. Это особенно важно для сценариев, где доступ к размеченным данным ограничен, или требуется улучшить производительность модели в условиях, отличающихся от тех, на которых она была обучена. Расширение обучающей выборки синтетическими данными позволяет модели лучше адаптироваться к новым условиям и демонстрировать более стабильные результаты в различных сценариях применения.
Оценка CLIP, равная 0.3139, демонстрирует высокую семантическую согласованность между изображениями и сгенерированными синтетическими подписями. Данный показатель, полученный в ходе оценки соответствия визуального и текстового контента, подтверждает, что сгенерированные подписи релевантны изображениям и отражают их содержание. Значение CLIP измеряет косинусное сходство между векторами признаков изображения и текста, полученными с помощью модели CLIP, где более высокие значения указывают на более тесную семантическую связь. Полученный результат свидетельствует об эффективности подхода к генерации синтетических данных и потенциальном улучшении производительности моделей, обученных на расширенном наборе данных.

Оптимизация Обучения с Использованием Контрастного Обучения
Контрастное обучение, особенно в сочетании с моделями, такими как CLIP, предоставляет эффективный механизм для выравнивания визуальных и текстовых представлений. CLIP (Contrastive Language-Image Pre-training) обучается сопоставлять изображения и текст, формируя общее векторное пространство, где семантически близкие изображения и текстовые описания располагаются рядом. Это достигается путем максимизации сходства между соответствующими парами изображение-текст и минимизации сходства между несвязанными парами. В результате, модель приобретает способность понимать взаимосвязь между визуальным контентом и его текстовым описанием, что позволяет использовать полученные представления для различных задач, включая классификацию изображений, поиск изображений по тексту и генерацию описаний изображений.
Супервизированный контрастивный подход к обучению (Supervised Contrastive Loss) усиливает выравнивание визуальных и текстовых представлений за счет включения информации о классах. В отличие от стандартного контрастивного обучения, которое фокусируется на различии между примерами, данный метод использует метки классов для обеспечения группировки схожих изображений и подписей в векторном пространстве. Это достигается путем минимизации расстояния между представлениями изображений и подписей, принадлежащих к одному классу, и максимизации расстояния между представлениями примеров из разных классов. Такой подход позволяет модели более эффективно обобщать знания и повышать точность классификации.
Использование метода усреднения текстовых эмбеддингов по классам (Class-Averaged Text Embedding) позволяет повысить устойчивость представлений текстовых описаний. Данный подход заключается в вычислении среднего вектора эмбеддингов для всех текстовых описаний, относящихся к одному и тому же классу. Это снижает влияние шума и вариативности в отдельных описаниях, формируя более обобщенное и надежное представление класса. В результате, улучшается способность модели различать и сопоставлять изображения и текстовые описания, что положительно сказывается на общей производительности системы.
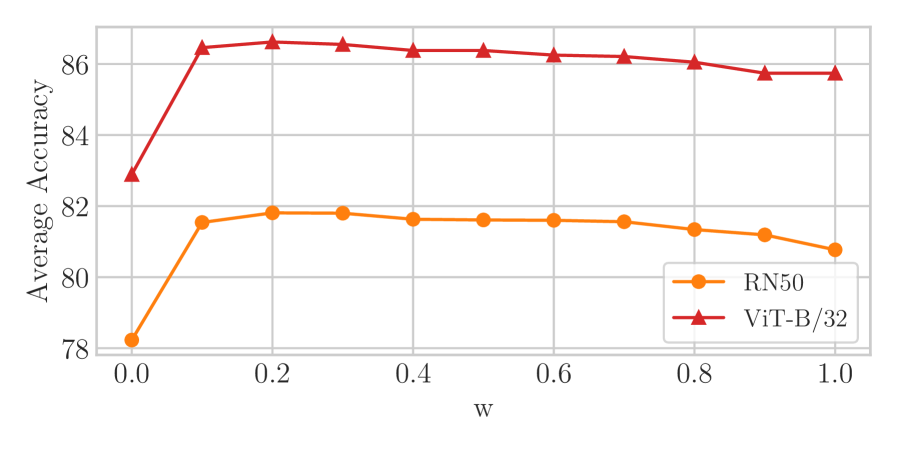
При использовании стандартной тонкой настройки (fine-tuning) предложенный подход демонстрирует точность в 82.08%. Это представляет собой улучшение на 4.69 процентных пункта по сравнению с результатами, полученными при использовании стандартной тонкой настройки (FT) без применения контрастивного обучения. Данный прирост точности подтверждает эффективность использования контрастивного обучения для улучшения производительности моделей в задачах, требующих выравнивания визуальных и текстовых представлений.
При использовании архитектуры ViT в качестве основы и стандартной тонкой настройки (fine-tuning), предложенный подход демонстрирует точность в 86.81%. Этот показатель на 2.43 процентных пункта выше, чем точность, достигаемая при использовании стандартной тонкой настройки без применения предложенных методов (FT). Данное улучшение подтверждает эффективность использования архитектуры ViT в сочетании с предложенными методами для повышения точности классификации изображений.
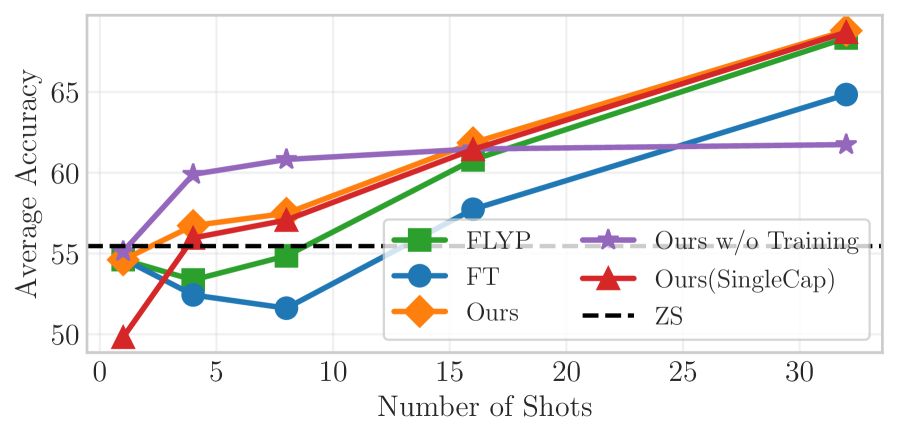
Усиление Производительности при Ограниченном Объеме Данных
Сочетание синтетических подписей с методами увеличения данных позволяет значительно повысить эффективность моделей в условиях малого количества обучающих примеров, известных как Few-Shot Learning. Этот подход, генерируя дополнительные описания к изображениям, фактически расширяет обучающую выборку, позволяя модели лучше обобщать и распознавать новые объекты, даже при ограниченном количестве размеченных данных. Такой способ обогащения данных особенно ценен в ситуациях, когда сбор и аннотация больших объемов информации являются дорогостоящими или трудоемкими, открывая путь к созданию высокопроизводительных мультимодальных систем с минимальными затратами и ускорением исследований.
В условиях обучения с небольшим объемом данных, предложенный подход демонстрирует значительные результаты в задаче 8-шагового обучения. Достигнутая точность составляет 60.82%, что превосходит показатели моделей, подвергшихся тонкой настройке, на 3.33 процентных пункта. Такое улучшение указывает на эффективность использования синтетических подписей в сочетании с методами аугментации данных, позволяя модели эффективно обобщать знания даже при ограниченном количестве обучающих примеров. Это позволяет значительно повысить производительность мультимодальных моделей, не прибегая к дорогостоящей и трудоемкой разметке больших объемов данных.
Исследование демонстрирует значительное превосходство разработанного подхода над базовым методом FLYP в условиях обучения с четырьмя примерами (4-shot learning). Достигнутая точность в 55.98% превышает показатели FLYP на 3.41 процентных пункта, что свидетельствует о более эффективном использовании ограниченного набора данных. Этот результат подчеркивает потенциал предложенной методики для повышения производительности мультимодальных моделей даже при крайне небольшом количестве размеченных данных, открывая возможности для экономии ресурсов и ускорения исследовательских проектов в области машинного обучения.
Предложенный подход открывает новые возможности для обучения высокоэффективных мультимодальных моделей, требуя при этом минимального объема размеченных данных. Это позволяет значительно снизить затраты на создание и обучение таких моделей, что особенно важно для проектов с ограниченным бюджетом или при работе с редкими типами данных. Уменьшение потребности в больших размеченных наборах данных также ускоряет процесс исследований, позволяя ученым и разработчикам быстрее прототипировать и тестировать новые идеи в области искусственного интеллекта и машинного обучения. Подобная экономия ресурсов способствует более широкому внедрению мультимодальных систем в различных областях, от компьютерного зрения и обработки естественного языка до робототехники и анализа медицинских изображений.
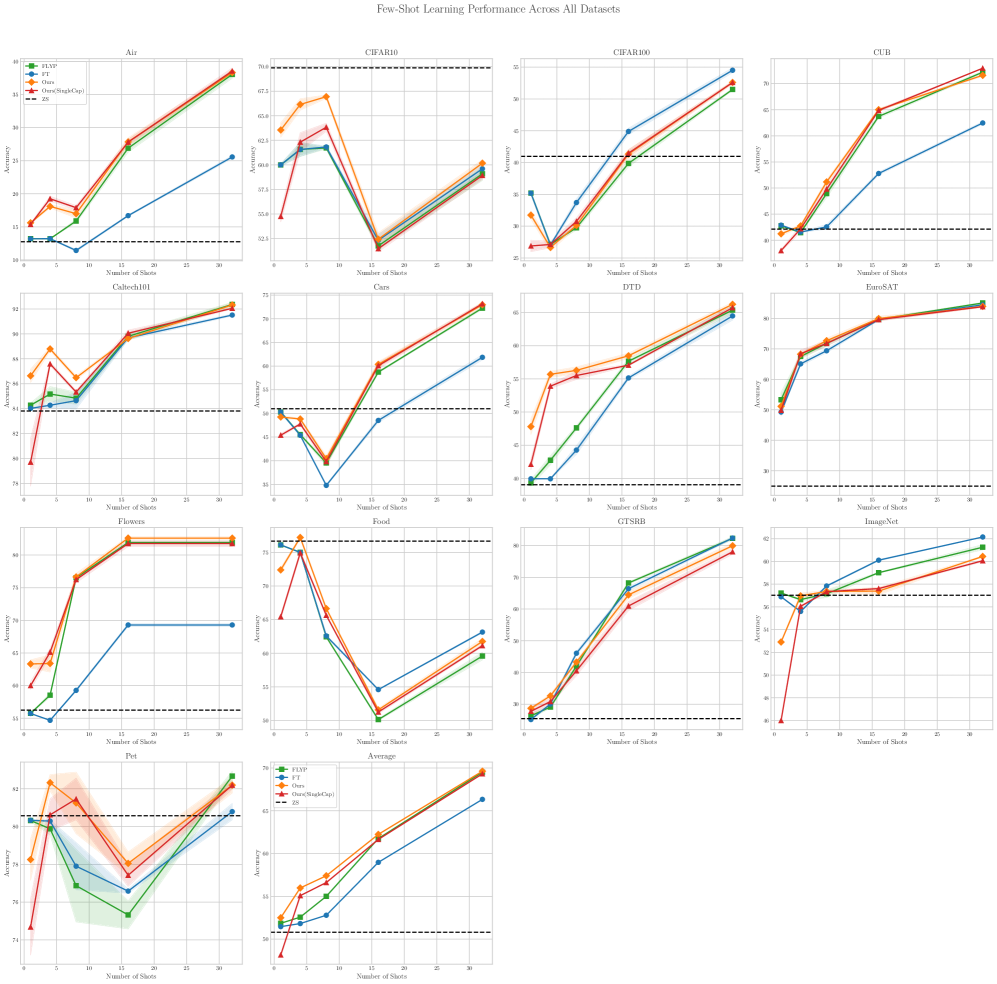
Исследование демонстрирует, что преобразование унимодальных данных в мультимодальные с использованием больших языковых моделей открывает новые возможности для улучшения классификации изображений. Этот подход, основанный на генерации синтетических подписей, позволяет модели учиться более эффективно, особенно в условиях ограниченного количества обучающих данных. Как однажды заметил Ян Лекун: «Машинное обучение — это искусство использования данных для прогнозирования будущего». Данная работа подтверждает эту мысль, показывая, как искусственно созданные данные могут значительно расширить возможности модели и повысить её точность, используя принципы контрастивного обучения и тонкой настройки для достижения лучших результатов.
Куда Ведут Эти Пути?
Представленная работа, демонстрируя возможности трансформации унимодальных данных посредством синтетических подписей, лишь приоткрывает завесу над более глубоким вопросом: насколько далеко можно зайти в искусственном расширении реальности? Каждое изображение, несомненно, скрывает структурные зависимости, которые необходимо выявить, но генерация описаний, даже с использованием мощных языковых моделей, является лишь прокси-решением. Истинная проблема заключается не в количестве данных, а в адекватности их репрезентации.
Перспективы, безусловно, связаны с поиском более элегантных способов извлечения семантической информации непосредственно из визуальных данных, минуя стадию текстового посредничества. Важно понимать, что интерпретация моделей важнее красивых результатов, и будущие исследования должны быть сосредоточены на разработке метрик, оценивающих не только точность классификации, но и семантическую согласованность представлений. Особенно актуальным представляется изучение устойчивости моделей к нерелевантным или вводящим в заблуждение синтетическим подписям.
Следующим логичным шагом видится переход к самообучению, где модель сама генерирует и оценивает свои собственные обучающие примеры. Такой подход потребует разработки новых алгоритмов, способных к критическому анализу и самокоррекции, но в конечном итоге может привести к созданию систем, способных к истинному пониманию визуального мира, а не просто к его имитации.
Оригинал статьи: https://arxiv.org/pdf/2601.21426.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Молекулярный конструктор: Искусственный интеллект на службе создания лекарств
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Диффузия против Квантов: Новый Взгляд на Факторизацию
2026-02-02 02:54