Автор: Денис Аветисян
Новая модель EditThinker позволяет значительно улучшить качество редактирования изображений, позволяя нейросети критически оценивать и уточнять ваши инструкции.

Представлен фреймворк ‘Think-while-Edit’, использующий мультимодальную большую языковую модель и обучение с подкреплением для итеративного улучшения результатов редактирования изображений.
Несмотря на значительный прогресс в области редактирования изображений по текстовым запросам, существующие подходы часто сталкиваются с ограничениями в точности и последовательности выполнения сложных инструкций. В данной работе, представленной под названием ‘EditThinker: Unlocking Iterative Reasoning for Any Image Editor’, предлагается новый подход, имитирующий когнитивный цикл человека, посредством итеративного процесса «думай, пока редактируешь». Ключевым элементом является модель EditThinker — многомодальная большая языковая модель, обученная критически оценивать результаты редактирования и уточнять инструкции для достижения наилучшего качества. Может ли подобная имитация человеческого мышления открыть новые горизонты в автоматизированном редактировании изображений и повысить уровень понимания инструкций моделями искусственного интеллекта?
За гранью однократного редактирования: Необходимость рассуждения
Традиционные методы редактирования изображений, как правило, основываются на однократном применении изменений, что существенно ограничивает их возможности при выполнении сложных инструкций. В отличие от процессов, требующих последовательного планирования и уточнения, существующие алгоритмы зачастую не способны к многоступенчатой обработке, необходимой для достижения желаемого результата. Например, при просьбе «заменить небо на закатное, добавить облака и слегка изменить цветовую гамму», однократное применение фильтров или масок редко приводит к реалистичному и гармоничному изображению. Неспособность к итеративному уточнению и учету контекста приводит к тому, что даже простые запросы могут потребовать значительных ручных корректировок, подчеркивая потребность в подходах, имитирующих человеческое рассуждение и планирование в процессе редактирования.
Простое увеличение масштаба мультимодальных моделей не позволяет добиться истинного понимания изображений, поскольку этот процесс требует итеративной доработки и планирования. Исследования показывают, что для выполнения сложных задач редактирования недостаточно однократной обработки данных; необходимо последовательное уточнение и корректировка изменений, основанное на промежуточных результатах. Такой подход позволяет модели не только учитывать сложные инструкции, но и поддерживать семантическую согласованность изображения, избегая нежелательных артефактов или искажений. Итеративное планирование позволяет модели декомпозировать сложные запросы на более простые шаги, что повышает точность и надежность редактирования, приближая результат к намерениям пользователя и обеспечивая более естественное и правдоподобное изображение.
Современные методы редактирования изображений зачастую сталкиваются с проблемой поддержания семантической согласованности и соответствия внесенных изменений намерениям пользователя. Несмотря на впечатляющий прогресс в области мультимодальных моделей, они нередко допускают логические нестыковки или игнорируют контекст изображения, приводя к нежелательным результатам. Например, при редактировании фотографии, содержащей несколько объектов, модель может изменить лишь часть из них, или внести изменения, противоречащие здравому смыслу. Это связано с тем, что существующие подходы оперируют в основном на уровне пикселей, не обладая способностью к глубокому пониманию смысла изображения и намерений, стоящих за запросом пользователя. В результате, даже небольшие изменения могут привести к существенным семантическим искажениям, снижая общее качество и полезность отредактированного изображения.
Думай-пока-редактируешь: Рамки итеративной доработки
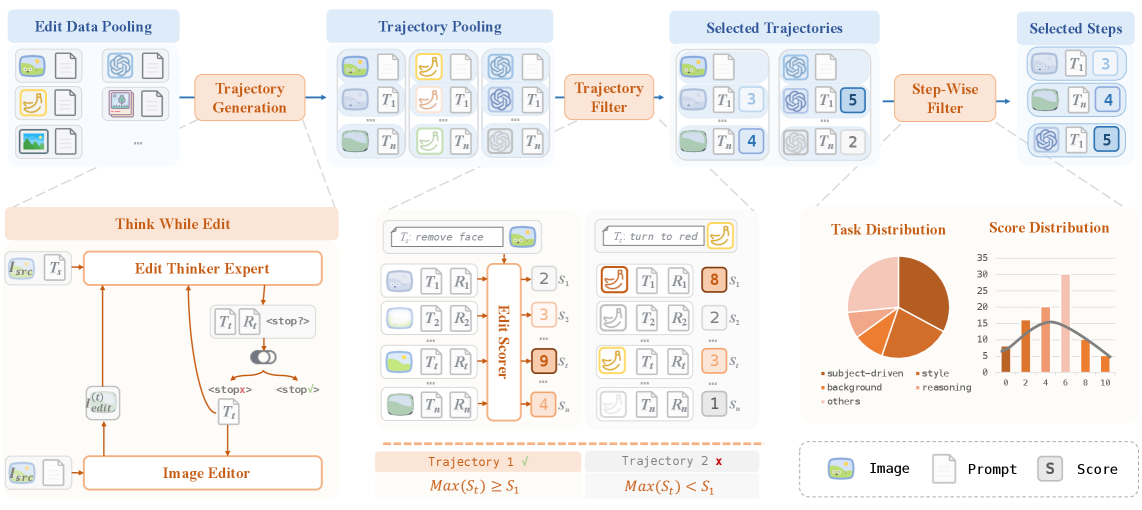
Предлагается фреймворк ‘Think-while-Edit’, предназначенный для итеративной доработки изображений. Данная система позволяет моделям редактирования изображений последовательно анализировать текущее состояние изображения, выявлять недостатки или области для улучшения, и на основе этого генерировать новые, уточненные версии. Итеративный процесс включает в себя критическую оценку, внесение изменений и повторение цикла до достижения желаемого результата, обеспечивая более точное соответствие изображения заданным инструкциям и требованиям.
В основе предлагаемого подхода лежит итеративный цикл “Критика-Уточнение-Повтор”, предназначенный для преодоления разрыва между общими инструкциями и детальными визуальными изменениями. Этот цикл обеспечивает последовательное улучшение изображения путем первоначальной оценки текущего состояния, выявления недостатков или несоответствий заданным требованиям, внесения конкретных изменений для их устранения и повторения процесса до достижения желаемого результата. Подобная итеративная схема позволяет модели постепенно приближаться к реализации сложных визуальных концепций, основываясь на постоянной обратной связи и корректировке действий.
В основе системы лежит ‘EditThinker’ — мультимодальная большая языковая модель (MLLM), предназначенная для организации и управления итеративным процессом редактирования изображений. EditThinker принимает на вход как текстовые инструкции, так и визуальную информацию об изображении, анализирует их и генерирует последовательность шагов для внесения изменений. Модель использует свои возможности понимания языка и анализа изображений для оценки текущего состояния изображения, выявления несоответствий инструкциям и планирования необходимых коррекций. Данная архитектура позволяет EditThinker последовательно улучшать изображение, пока не будет достигнут желаемый результат, за счет повторяющегося цикла критики, уточнения и повторной генерации.
![Визуализация траектории рассуждений EditThinker в связке с FLUX.1 Kontext [Dev] демонстрирует, как система оценивает текущий результат, выявляет недостатки и итеративно уточняет инструкцию для достижения улучшения.](https://arxiv.org/html/2512.05965v1/x5.png)
Обучение EditThinker: От данных к рассуждениям
Обучение EditThinker осуществляется посредством комбинации методов контролируемой тонкой настройки (Supervised Fine-Tuning, SFT) и обучения с подкреплением (Reinforcement Learning, RL). SFT предполагает использование размеченных данных для обучения модели следовать инструкциям и генерировать желаемый вывод. В свою очередь, RL позволяет модели совершенствовать свои навыки, получая обратную связь в виде вознаграждения или штрафа за каждое действие, что способствует оптимизации стратегии принятия решений и повышению качества генерируемого текста. Комбинированный подход позволяет эффективно использовать преимущества обоих методов, обеспечивая как точность следования инструкциям, так и способность к рассуждению и генерации осмысленного контента.
Набор данных ThinkEdit-140k, состоящий из 140 тысяч примеров, служит основой для обучения модели EditThinker. Этот масштабный датасет предоставляет необходимые сигналы для улучшения понимания инструкций и развития навыков логического мышления. Он содержит размеченные данные, позволяющие модели научиться сопоставлять входные запросы с ожидаемыми результатами, а также строить последовательность рассуждений для достижения этих результатов. Структура датасета позволяет эффективно обучать модель как на задачах, требующих прямого следования инструкциям, так и на более сложных задачах, требующих анализа и синтеза информации.
Для обучения модели EditThinker используется генерация высококачественных цепочек рассуждений с помощью GPT-4.1. Этот процесс позволяет создать обучающие данные, демонстрирующие логические шаги, необходимые для решения задач и следования инструкциям. GPT-4.1 генерирует не просто ответы, а детализированные объяснения, которые служат примером для EditThinker. Такой подход обеспечивает точность выполнения инструкций и способствует развитию способности модели к логическому мышлению, что критически важно для сложных задач и поддержания согласованности ответов.

Оценка и повышение качества редактирования
Для оценки эффективности EditThinker используются ключевые показатели, такие как ‘Семантическая Согласованность’ и ‘Оценка Следования Инструкциям’. Первый показатель измеряет, насколько внесенные изменения соответствуют содержанию изображения и сохраняют его общий смысл, предотвращая появление нелогичных или бессмысленных деталей. Второй показатель, ‘Оценка Следования Инструкциям’, оценивает, насколько точно модель интерпретирует и выполняет заданные пользователем команды для редактирования. Эти метрики позволяют количественно оценить качество редактирования и определить, насколько хорошо модель понимает намерения пользователя, что является важным шагом в разработке более интеллектуальных и удобных систем редактирования изображений. Высокие показатели по этим метрикам свидетельствуют о том, что модель способна генерировать правдоподобные и соответствующие запросам изменения, что положительно сказывается на пользовательском опыте.
Механизмы «Оценки Редактирования» и «Вознаграждения за Редактирование» представляют собой ключевой элемент, направленный на совершенствование процесса модификации изображений. Данные механизмы предоставляют обратную связь модели, позволяя ей не только создавать визуально привлекательные изменения, но и обеспечивать их семантическую точность — соответствие внесенных правок исходному запросу и общему смыслу изображения. По сути, система оценивает качество редактирования по множеству параметров, и на основе этой оценки формируется вознаграждение, стимулирующее модель к генерации более качественных и релевантных результатов. Такой подход позволяет модели обучаться на своих ошибках и постепенно улучшать свои навыки редактирования, добиваясь более реалистичных и точных изменений в изображениях.
Исследования показали, что данная платформа демонстрирует свою универсальность при работе с различными моделями редактирования изображений, включая ‘Qwen-Image-Edit’, ‘Flux-Kontext’ и ‘Omnigen2’. В частности, при использовании модели FLUX.1-Kontext удалось достичь общего результата в 3.98 балла на ImgEdit-Bench, что значительно превосходит базовый показатель в 3.44. Аналогичные улучшения наблюдаются и на GEdit-Bench-EN, где данный подход позволил получить 7.05 баллов, в то время как исходный результат составлял 6.18. Эти данные свидетельствуют о способности платформы эффективно адаптироваться и улучшать производительность различных моделей редактирования изображений, открывая новые возможности для создания визуально привлекательного и семантически точного контента.
В ходе оценки предложенной системы, модель FLUX.1-Kontext продемонстрировала выдающиеся результаты на эталонных наборах данных RISE-Bench и Kris-Bench, набрав 14.4 и 69.53 баллов соответственно. Примечательно, что положительный эффект от использования данной системы наблюдается не только в FLUX.1-Kontext, но и в других моделях редактирования изображений, в частности, OmniGen2, где зафиксировано увеличение показателей на 3.1-3.4 балла при тестировании на RISE-Bench. Это свидетельствует о высокой универсальности и эффективности предложенного подхода к оценке и улучшению качества редактирования изображений, способствуя созданию более точных и визуально привлекательных результатов.
В этой работе, где авторы пытаются научить нейросеть не просто выполнять команды по редактированию изображений, а ещё и думать над ними, прослеживается знакомый паттерн. Создаётся иллюзия прогресса, пока система не сталкивается с хоть сколько-нибудь сложной задачей. Как говорит Фэй-Фэй Ли: «Искусственный интеллект должен служить людям, а не заменять их». Идея «Think-while-Edit», подразумевающая итеративное улучшение инструкций, выглядит многообещающе, но всегда есть риск, что в погоне за автоматизацией упустят из виду базовые вещи. В конце концов, каждая «революционная» технология завтра станет техдолгом, и эта система не исключение. Начинаю подозревать, что они просто повторяют модные слова, чтобы получить финансирование, пока кто-то не заметит, что сложная система когда-то была простым bash-скриптом.
Что дальше?
Представленный подход, безусловно, элегантен. Идея итеративной доработки инструкций посредством большой мультимодальной модели — логичное развитие, учитывая текущую одержимость нейронных сетей всем и вся. Однако, за красивыми демо-роликами неизбежно скрывается тот факт, что каждое «улучшение» — это новая поверхность атаки для ошибок. Каждый шаг итерации требует вычислительных ресурсов, а значит, рано или поздно, энтузиазм столкнется с реальностью серверных счетов. Пока что это, скорее, демонстрация возможностей, чем реальный шаг к автоматизации редактирования изображений в продакшене.
Более фундаментальная проблема заключается в самой природе инструкций. Даже самые чёткие указания подвержены интерпретации. Нейронная сеть, как и любой инструмент, лишь усиливает намерения пользователя — как хорошие, так и плохие. Поэтому, стоит ожидать, что основная борьба перейдет в плоскость более точного определения желаемого результата, а не в улучшение алгоритмов редактирования как таковых. И, вероятно, вернется мода на простые, понятные интерфейсы, где пользователь сам контролирует процесс, а не надеется на гений нейронной сети.
Если код выглядит идеально — значит, его никто не запустил в реальном мире. Поэтому, в ближайшем будущем, скорее всего, увидим не революцию в области редактирования изображений, а эволюцию существующих инструментов, адаптированных к новым возможностям, с неизбежным появлением новых багов и сложностей, которые придётся решать обычным, человеческим трудом. Это не плохо, это просто реальность.
Оригинал статьи: https://arxiv.org/pdf/2512.05965.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-12-08 20:27