Автор: Денис Аветисян
Исследование демонстрирует, что небольшие языковые модели, в сочетании с машинным переводом, способны эффективно извлекать структурированные клинические данные из персидских транскриптов паллиативной помощи без необходимости тонкой настройки.

Открытые компактные языковые модели и машинный перевод для извлечения клинической информации в условиях ограниченности лингвистических ресурсов.
Извлечение клинической информации из медицинских транскриптов на языках с ограниченными ресурсами представляет собой сложную задачу в области обработки естественного языка. В работе, озаглавленной ‘Small Language Models for Privacy-Preserving Clinical Information Extraction in Low-Resource Languages’, исследуется двухэтапный подход, сочетающий модель машинного перевода Aya-expanse-8B и пять небольших языковых моделей с открытым исходным кодом для извлечения 13 клинических признаков из персидских транскриптов. Полученные результаты демонстрируют, что использование небольших языковых моделей в сочетании с машинным переводом позволяет эффективно извлекать структурированную клиническую информацию без необходимости тонкой настройки, предлагая жизнеспособное решение для языков с ограниченными ресурсами. Какие стратегии оптимизации масштаба модели и стратегии обработки входных данных могут еще больше повысить эффективность и надежность подобных систем в чувствительных медицинских приложениях?
Прогнозирование сбоев: Автоматизация анализа взаимодействия с пациентами
В паллиативной онкологии эффективное общение с пациентом играет ключевую роль в обеспечении качества жизни и принятии информированных решений. Однако, традиционная ручная оценка взаимодействия с пациентами — анализ текстовых записей, аудио- или видеоматериалов — отнимает значительное время у медицинского персонала и неизбежно подвержена человеческому фактору, что может приводить к упущениям важной информации. Данный процесс не позволяет комплексно оценить потребности пациента, его опасения и предпочтения, что в свою очередь затрудняет разработку индивидуального плана лечения и поддержки. В связи с этим, существует острая необходимость в разработке и внедрении автоматизированных систем анализа коммуникаций, способных эффективно извлекать и структурировать ключевые аспекты взаимодействия между врачом и пациентом.
Существующие методы извлечения ключевой клинической информации из неструктурированных текстов, таких как медицинские записи и истории болезни, сталкиваются со значительными ограничениями в масштабируемости и точности. Традиционные подходы, основанные на ручном анализе или простых алгоритмах обработки естественного языка, часто не способны уловить тонкие нюансы потребностей пациента, проявляющиеся в его речи и описаниях симптомов. Это приводит к неполному пониманию состояния больного и, как следствие, к неоптимальным решениям в области паллиативной помощи. Сложность заключается в том, что пациенты выражают свои потребности по-разному, используя метафоры, неявные просьбы и эмоционально окрашенные высказывания, которые трудно интерпретировать с помощью стандартных инструментов анализа текста. Неспособность адекватно отразить эти нюансы может привести к упущению важных аспектов качества жизни пациента и, в конечном итоге, к снижению эффективности паллиативного лечения.
Экосистемы поддержки: Автоматизированное извлечение информации
Исследование было направлено на изучение возможности автоматизированной экстракции информации для снижения нагрузки на врачей и улучшения поддержки в условиях паллиативной помощи. В рамках работы предполагается, что автоматизация рутинных задач, связанных с обработкой медицинских записей и извлечением ключевых данных о пациентах, позволит медицинскому персоналу высвободить время для непосредственной работы с пациентами и принятия клинических решений. Основной акцент делается на повышении эффективности работы врачей, уменьшении вероятности ошибок, связанных с ручной обработкой данных, и обеспечении более качественной и своевременной поддержки пациентов, находящихся на паллиативной помощи.
В данном исследовании для автоматической обработки данных используется подход, основанный на применении малых языковых моделей (SLM) в качестве вычислительно эффективной альтернативы большим языковым моделям (LLM). Использование SLM обусловлено не только их меньшими требованиями к ресурсам, но и снижением рисков, связанных с безопасностью данных, которые актуальны при работе с LLM. Большие языковые модели, несмотря на свою высокую производительность, потенциально могут привести к утечке конфиденциальной информации, что делает SLM более предпочтительным решением для обработки чувствительных данных в медицинских учреждениях.
Для обеспечения возможности обработки персидских транскриптов моделями автоматического извлечения информации, необходим их перевод на английский язык. В процессе перевода возникает риск появления артефактов, искажающих исходный смысл и точность извлеченных данных. Эти артефакты могут быть вызваны неоднозначностью персидской лексики, грамматическими различиями между языками, а также особенностями работы алгоритмов машинного перевода. Для минимизации влияния артефактов требуется тщательный анализ качества перевода, возможно, с привлечением лингвистов-экспертов и использование специализированных инструментов для оценки точности и согласованности переведенного текста.

Оценка и балансировка: Производительность малых языковых моделей
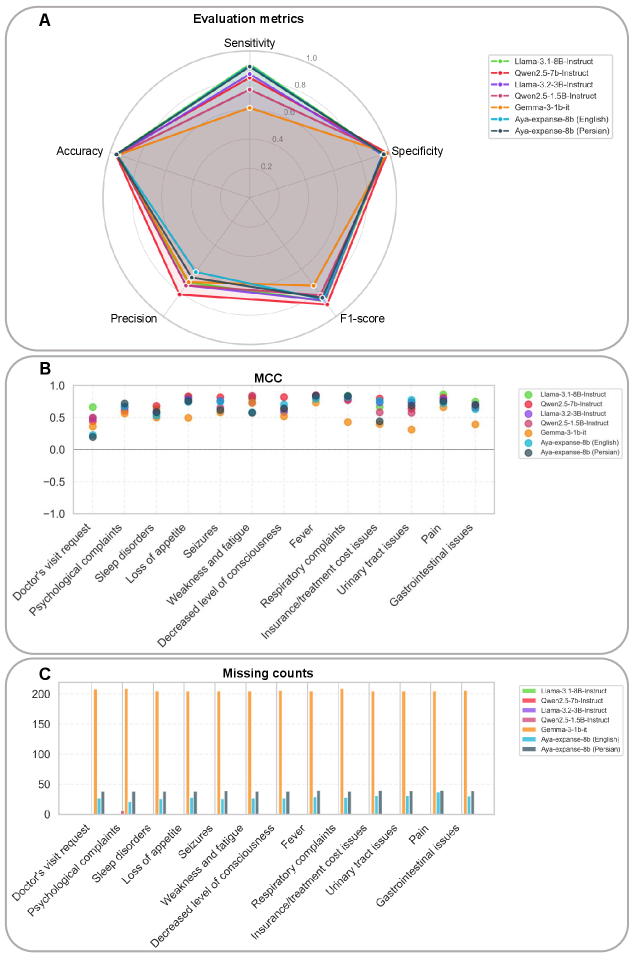
Для оценки эффективности различных небольших языковых моделей (SLM) был проведен сравнительный анализ, в ходе которого модели Aya-expanse-8B, Llama-3.2-3B-Instruct, Qwen2.5-7B-Instruct и Gemma-3-1B-it были протестированы на задаче извлечения 13 бинарных клинических признаков. Каждая модель была обучена определять наличие или отсутствие каждого признака на основе входных данных, что позволило количественно оценить их способность к пониманию и обработке клинической информации. Результаты этого анализа легли в основу дальнейшей оценки и сравнения производительности каждой модели.
Для управления большими языковыми моделями (SLM) в процессе извлечения 13 бинарных клинических признаков использовался метод Few-Shot Prompting, заключающийся в предоставлении моделям небольшого набора примеров для формирования ответа. Оценка производительности осуществлялась с использованием метрик: чувствительность (Sensitivity), определяющая долю правильно идентифицированных положительных случаев; специфичность (Specificity), отражающая долю правильно идентифицированных отрицательных случаев; и Macro-Averaged F1-Score, представляющая собой среднее гармоническое между точностью и полнотой по всем классам. Комбинация этих метрик позволила комплексно оценить способность моделей к точному извлечению и классификации клинических данных.
При оценке производительности моделей из-за дисбаланса классов в наборе данных, традиционные метрики, такие как точность и полнота, могут давать искаженные результаты. Для обеспечения более надежной оценки, наряду с чувствительностью, специфичностью и усредненной F1-метрикой, был использован коэффициент корреляции Мэтьюса (MCC). MCC учитывает соотношение истинно положительных, истинно отрицательных, ложноположительных и ложноотрицательных результатов, обеспечивая сбалансированную оценку, менее подверженную влиянию дисбаланса классов. Высокое значение MCC указывает на надежную корреляцию между предсказанными и фактическими клиническими признаками, что особенно важно при анализе медицинских данных, где даже небольшое количество ложноположительных или ложноотрицательных результатов может иметь значительные последствия.
Результаты оценки производительности моделей показали, что Qwen2.5-7B-Instruct достигла наивысшего медианного значения Macro-Averaged F1-score, составившего 0.899, и медианной специфичности в 0.987. Данные показатели свидетельствуют о высокой эффективности данной модели в задаче извлечения и идентификации релевантной клинической информации из представленного набора данных. Высокий F1-score указывает на сбалансированную точность и полноту извлечения, а высокая специфичность — на низкий уровень ложноположительных результатов.
Модель Qwen2.5-7B-Instruct продемонстрировала наивысший коэффициент корреляции Мэтьюса (MCC) — 0.797. Этот показатель подтверждает высокую степень надежности взаимосвязи между предсказанными моделью и фактическими клиническими признаками. Коэффициент MCC особенно важен при работе с несбалансированными данными, поскольку он учитывает как истинно положительные и отрицательные результаты, так и ложноположительные и ложноотрицательные, обеспечивая более объективную оценку производительности по сравнению с простой точностью.
Оптимизация и адаптация: Языковые особенности и поддержка врачей
Исследование продемонстрировало принципиальную возможность применения небольших языковых моделей (SLM) для анализа взаимодействий с пациентами даже в условиях ограниченных вычислительных ресурсов. В рамках работы была показана эффективность SLM в извлечении ключевой информации из текстовых данных, что открывает перспективы для их внедрения в реальную клиническую практику, особенно в медицинских учреждениях с ограниченным бюджетом или недостаточной инфраструктурой. Этот подход позволяет автоматизировать рутинные задачи, такие как поиск симптомов или обобщение истории болезни, тем самым снижая нагрузку на врачей и повышая качество обслуживания пациентов. Полученные результаты указывают на то, что SLM могут стать доступным и эффективным инструментом для поддержки принятия клинических решений.
Исследования показали, что применение специализированных запросов, адаптированных под конкретный язык, значительно повышает эффективность языковых моделей, особенно при работе с многоязычными данными. Вместо универсальных подходов, фокусировка на лингвистических особенностях каждого языка позволяет модели более точно интерпретировать и анализировать информацию. Такой подход учитывает синтаксические и семантические нюансы, что приводит к улучшению результатов в задачах, связанных с обработкой естественного языка, включая извлечение информации, классификацию текста и машинный перевод. Оптимизация запросов для каждого языка позволяет добиться более высокой производительности и точности, что особенно важно в контексте глобальных данных и многоязычного взаимодействия.
Исследования показали, что специализированные языковые модели (SLM) способны эффективно поддерживать врачей в выявлении ключевой информации из клинических данных. Такая поддержка позволяет автоматизировать рутинные задачи, связанные с анализом большого объема текстовой информации, например, из историй болезни или результатов обследований. В результате, врачи получают возможность уделять больше времени непосредственно пациентам и принятию важных клинических решений, что потенциально улучшает качество медицинской помощи. Кроме того, снижение нагрузки, связанной с обработкой информации, может существенно уменьшить профессиональное выгорание среди медицинских работников, способствуя более устойчивой и эффективной работе системы здравоохранения.
Исследование продемонстрировало высокую эффективность разработанного конвейера перевода для анализа медицинских взаимодействий. Модель Aya-expanse-8B, использующая перевод на английский язык, достигла показателя Macro-Averaged F1-score в 0.855 и коэффициента корреляции Мэтьюса в 0.724. Эти результаты свидетельствуют о значительной способности системы точно идентифицировать ключевую информацию в данных пациентов, что открывает перспективы для поддержки врачей в принятии решений и снижения профессионального выгорания. Достигнутая точность указывает на потенциал использования подобных систем в условиях ограниченных ресурсов, где оперативный и надежный анализ информации имеет решающее значение.
Исследование показывает, что даже небольшие языковые модели, при грамотном использовании машинного перевода, способны извлекать структурированную клиническую информацию из текстов на языках с ограниченными ресурсами. Это подчеркивает важность адаптации существующих инструментов, а не слепого следования за модой на огромные модели. Как заметил Брайан Керниган: «Простота — это высшая степень совершенства». В данном случае, простота подхода — использование небольших моделей и машинного перевода — позволяет решить сложную задачу извлечения данных в условиях ограниченных ресурсов, предлагая практичное и эффективное решение для улучшения паллиативной помощи и медицинского обслуживания в целом. Это не просто техническое достижение, а демонстрация того, что устойчивые системы строятся на основе осознанного выбора инструментов и адаптации к конкретным условиям.
Что Дальше?
Представленная работа демонстрирует не столько триумф технологии, сколько её вынужденную адаптацию к реальности. Малые языковые модели, действующие в связке с машинным переводом, позволяют извлекать структурированную информацию из клинических транскриптов на языках с ограниченными ресурсами. Однако, следует помнить: архитектура — это лишь способ откладывать хаос. Успех данной методики — это не отсутствие проблем, а лишь их временное откладывание. Вопросы баланса данных, качество машинного перевода, и, что наиболее важно, интерпретация извлеченной информации — остаются открытыми. Не существует лучших практик, есть лишь выжившие, и данное решение — лишь один из возможных путей.
Будущие исследования, вероятно, будут сосредоточены не на улучшении точности извлечения, а на оценке и смягчении последствий ошибок. Порядок — это кеш между двумя сбоями, и клинические данные, полученные с помощью автоматизированных систем, не являются исключением. Важнее не найти идеальную модель, а создать системы, способные обнаруживать и корректировать неточности, а также учитывать контекст и неопределенность. Необходимо перейти от поиска «истины» в данных к управлению риском, связанным с их интерпретацией.
В конечном итоге, задача состоит не в создании «умных» систем, а в разработке инструментов, которые расширят возможности врачей и позволят им принимать более обоснованные решения. Малые языковые модели — это лишь кирпичики, а не готовое решение. Экосистему необходимо выращивать, а не строить. Истинный прогресс заключается не в автоматизации, а в усилении человеческого интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.21374.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-27 03:38