Автор: Денис Аветисян
Новый инструмент позволяет наглядно понять, как большие языковые модели обрабатывают текст и генерируют ответы.
AnimatedLLM — это веб-приложение для интерактивной визуализации работы больших языковых моделей, включая процессы токенизации, генерации текста и предварительного обучения.
Несмотря на растущую популярность больших языковых моделей (LLM), понимание принципов их работы остается сложной задачей, особенно для непрофессионалов. В данной работе, ‘AnimatedLLM: Explaining LLMs with Interactive Visualizations’, представлена интерактивная веб-платформа, визуализирующая работу Transformer-моделей на примере пошагового анализа генерации текста и предварительного обучения. Приложение, работающее непосредственно в браузере, позволяет наглядно исследовать внутренние механизмы LLM, используя предварительно вычисленные трассировки. Способно ли такое визуальное представление стать эффективным инструментом обучения и расширить доступ к пониманию сложных алгоритмов искусственного интеллекта?
Раскрывая «Черный Ящик»: Сложность Больших Языковых Моделей
Современные большие языковые модели, такие как Llama 3, Qwen 3 и GPT-2, действительно совершили революцию в области обработки естественного языка, открыв новые горизонты для автоматического перевода, генерации текста и понимания речи. Однако, несмотря на впечатляющие результаты, принципы их работы остаются загадкой для большинства пользователей и даже для многих специалистов. Эти модели, основанные на сложных нейронных сетях, функционируют как своего рода “черный ящик”, где входные данные преобразуются в выходные посредством множества математических операций, скрытых от прямого наблюдения. Понимание этой непрозрачности критически важно для эффективного использования потенциала этих технологий и для развития более надежных и предсказуемых систем искусственного интеллекта.
Понимание сложной архитектуры трансформеров имеет первостепенное значение как для исследователей, стремящихся к дальнейшему развитию моделей обработки естественного языка, так и для специалистов, желающих эффективно применять их на практике. Трансформеры, в отличие от более ранних рекуррентных сетей, позволяют обрабатывать входные данные параллельно, что значительно повышает скорость обучения и вывода. Основой этой эффективности является механизм внимания, позволяющий модели фокусироваться на наиболее релевантных частях входной последовательности. Однако, для полноценного использования потенциала этих моделей необходимо глубокое понимание принципов работы слоев самовнимания, механизмов кодирования и декодирования, а также способов оптимизации и масштабирования. Без этого знания, применение больших языковых моделей может быть неоптимальным, приводя к неэффективному использованию ресурсов и снижению качества результатов. Поэтому, изучение архитектуры трансформеров является ключевым фактором для успешного развития и внедрения передовых технологий в области искусственного интеллекта.
Существующие объяснения принципов работы больших языковых моделей зачастую страдают от недостатка наглядности, что затрудняет понимание последовательной обработки информации и вероятностной природы генерируемых ими текстов. Традиционные подходы, сосредоточенные на математических формулах и схематических диаграммах, не позволяют в полной мере ощутить, как модель, слой за слоем, анализирует входные данные и формирует выходной текст, оценивая вероятность каждого следующего слова. Подобная абстрактность не способствует глубокому пониманию процесса, лишая исследователей и практиков возможности эффективно применять и совершенствовать эти мощные инструменты. Необходимость в визуализациях, демонстрирующих динамику работы модели и вероятностные распределения, становится всё более очевидной для преодоления этой информационной пропасти и раскрытия потенциала больших языковых моделей.
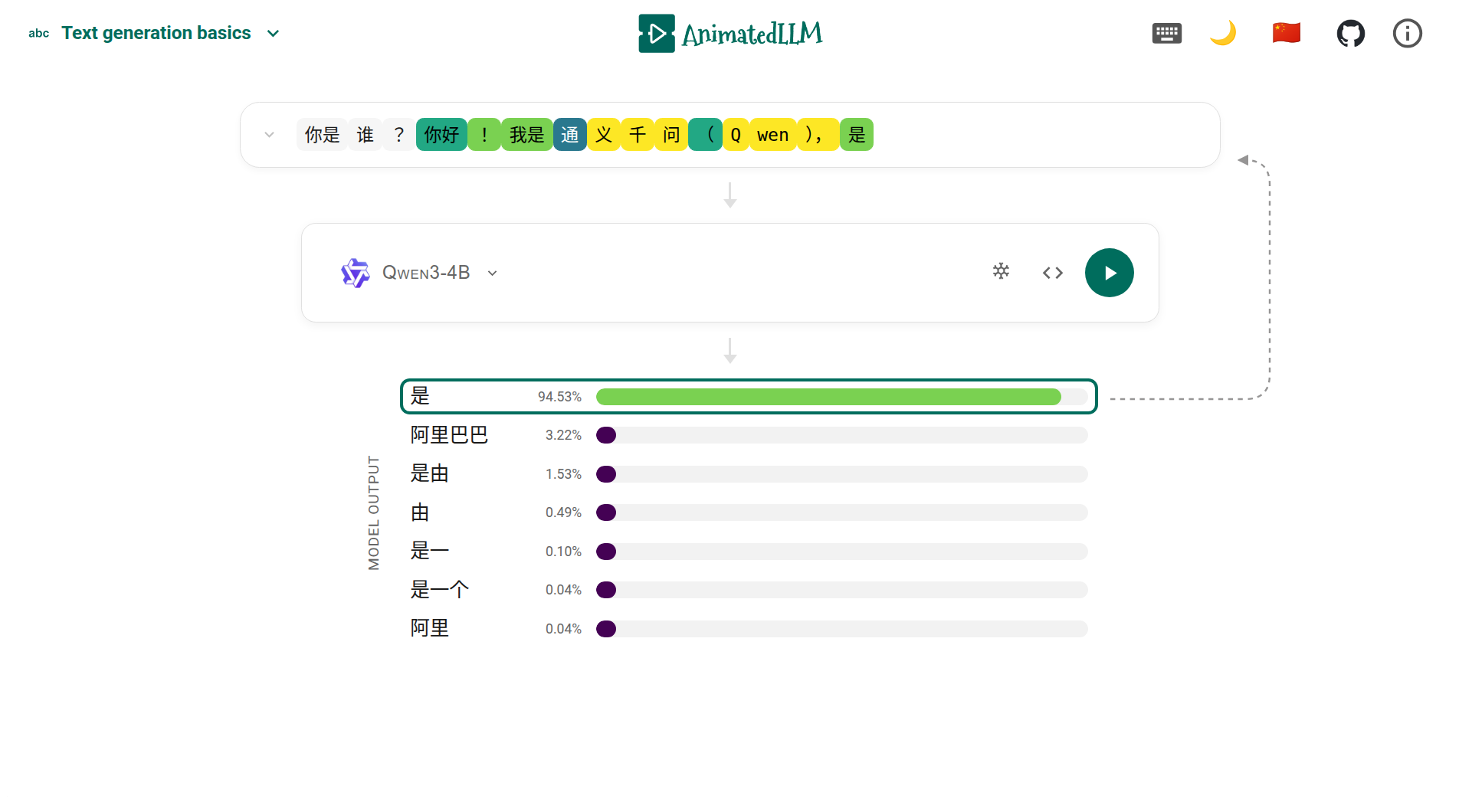
AnimatedLLM: Визуальный Подход к Объяснению LLM
AnimatedLLM представляет собой веб-приложение, реализованное на React, которое обеспечивает интерактивное визуальное представление процессов, происходящих внутри больших языковых моделей (LLM). Приложение работает непосредственно в браузере пользователя, что исключает необходимость серверной обработки для визуализации. Использование React позволяет создавать динамичный и отзывчивый интерфейс, облегчающий понимание сложных механизмов LLM. Основная цель разработки — предоставить пользователю возможность наглядно изучить, как LLM обрабатывают входные данные и генерируют текст, без необходимости глубокого знания принципов машинного обучения.
Приложение использует предварительно обученные модели, полученные из библиотеки Hugging Face Transformers, для генерации трассировок модели — полных выходных данных для заданных запросов. Процесс включает загрузку весов модели и конфигурации из репозитория Hugging Face Hub, что позволяет использовать широкий спектр моделей, включая BERT, GPT-2 и другие. Для каждого введенного запроса, модель генерирует последовательность токенов, а также соответствующие вероятности для каждого токена, которые и составляют трассировку. Эта трассировка включает в себя не только сгенерированный текст, но и промежуточные вычисления, необходимые для генерации, что позволяет детально проанализировать процесс работы языковой модели.
Трассировки, сериализованные в формате JSON, служат основой для визуализации в приложении AnimatedLLM. Это позволяет пользователям последовательно просматривать этапы обработки текста, начиная с токенизации — разбиения входного текста на отдельные единицы. Визуализация включает в себя отображение распределений вероятностей для каждого токена, что демонстрирует, какие варианты наиболее вероятны на каждом шаге. В конечном итоге, пользователь может наблюдать процесс генерации текста, от выбора наиболее вероятного токена до формирования итогового выходного результата. Данная пошаговая визуализация обеспечивает детальное понимание работы языковой модели.
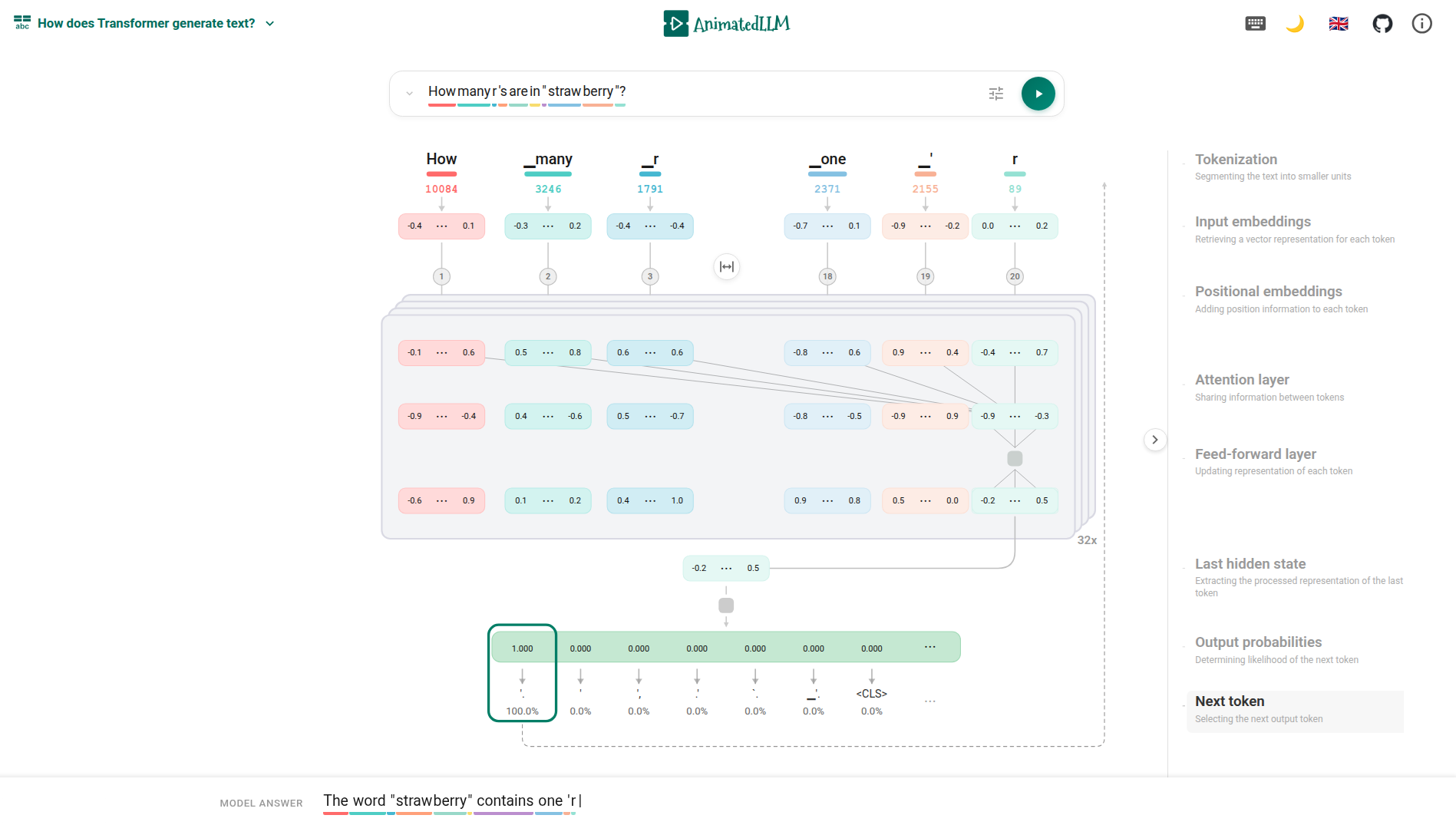
Инструмент AnimatedLLM предоставляет два режима визуализации для анализа работы больших языковых моделей. В режиме «Простой вид» акцент сделан на последовательной обработке токенов — пользователю демонстрируется процесс токенизации входного запроса и генерации ответа по одному токену за раз. Режим «Детальный вид» обеспечивает доступ к внутренним слоям архитектуры трансформера, позволяя изучить промежуточные результаты работы каждого слоя, веса и механизмы внимания, что необходимо для глубокого понимания процесса генерации текста моделью.
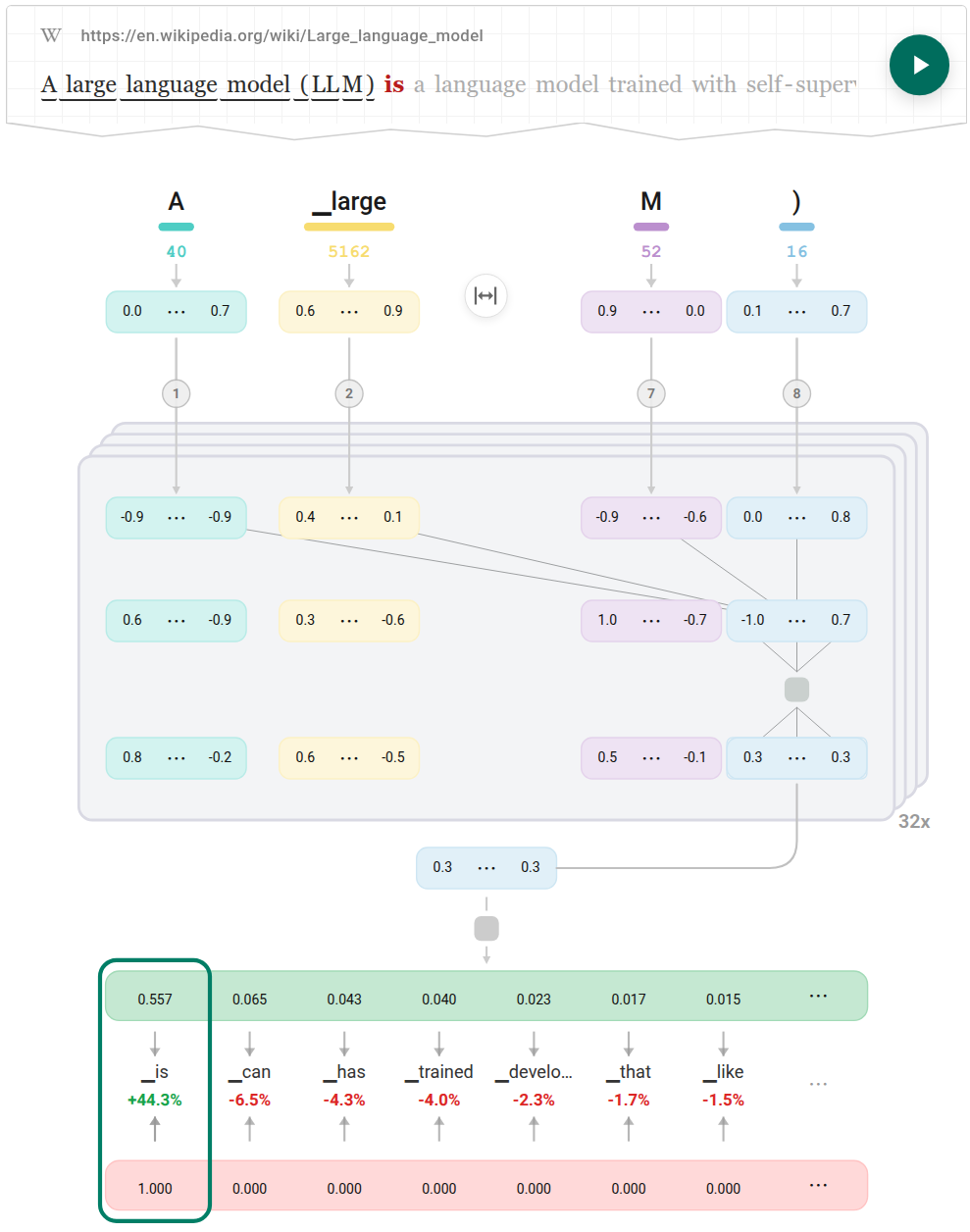
От Предварительного Обучения к Предсказанию: Визуализация Жизненного Цикла LLM
AnimatedLLM предоставляет специализированный вид для визуализации этапа предварительного обучения моделей (Model Pre-training). Этот вид демонстрирует процесс, в ходе которого большие языковые модели (LLM) обучаются на огромных объемах текстовых данных перед применением для решения конкретных задач. Визуализация позволяет наблюдать, как модель адаптирует свои параметры на основе статистических закономерностей, извлеченных из данных, формируя тем самым основу для последующей генерации текста или выполнения других лингвистических операций. Данный этап критически важен для понимания возможностей и ограничений модели, поскольку именно на нем формируется ее «знание» о языке и мире.
Визуализация процесса предварительного обучения позволяет пользователям получить более глубокое понимание предвзятостей и ограничений, присущих предварительно обученным моделям. Анализ данных, используемых для обучения, и промежуточных результатов позволяет выявить систематические ошибки и неточности, которые могут проявляться в выходных данных модели. Например, если модель обучалась на наборе данных, содержащем гендерные стереотипы, визуализация может показать, как эти стереотипы воспроизводятся в процессе генерации текста. Понимание этих ограничений критически важно для ответственного использования больших языковых моделей и разработки стратегий по смягчению их негативных последствий.
Представление генерации текста в AnimatedLLM демонстрирует последовательный характер выходных данных языковой модели, подчеркивая вероятностный выбор, осуществляемый на каждом шаге. Визуализация показывает, как модель оценивает различные варианты продолжения текста, назначая каждому из них вероятность, и затем выбирает наиболее вероятный токен для добавления к текущей последовательности. Этот процесс повторяется итеративно, формируя выходной текст, и позволяет пользователям наблюдать, как небольшие изменения во входном запросе или параметрах модели могут приводить к различным результатам. Отображение вероятностей для каждого токена на каждом шаге обеспечивает понимание неопределенности, присущей процессу генерации текста, и позволяет оценить уверенность модели в своих предсказаниях.
Визуализации, представленные в AnimatedLLM, наглядно демонстрируют взаимосвязь между параметрами языковой модели, входными запросами и генерируемым текстом. Отображение активаций нейронов и весов модели позволяет увидеть, как конкретные параметры влияют на вероятность выбора определенных токенов при генерации. Анализ влияния различных входных запросов на выходные данные подтверждает, что даже небольшие изменения во входных данных могут приводить к значительному изменению сгенерированного текста, что подчеркивает чувствительность модели к входным данным и сложность процесса генерации. Данные визуализации предоставляют эмпирическое подтверждение тому, что выходные данные LLM являются результатом вероятностного выбора, определяемого состоянием модели и входным контекстом.
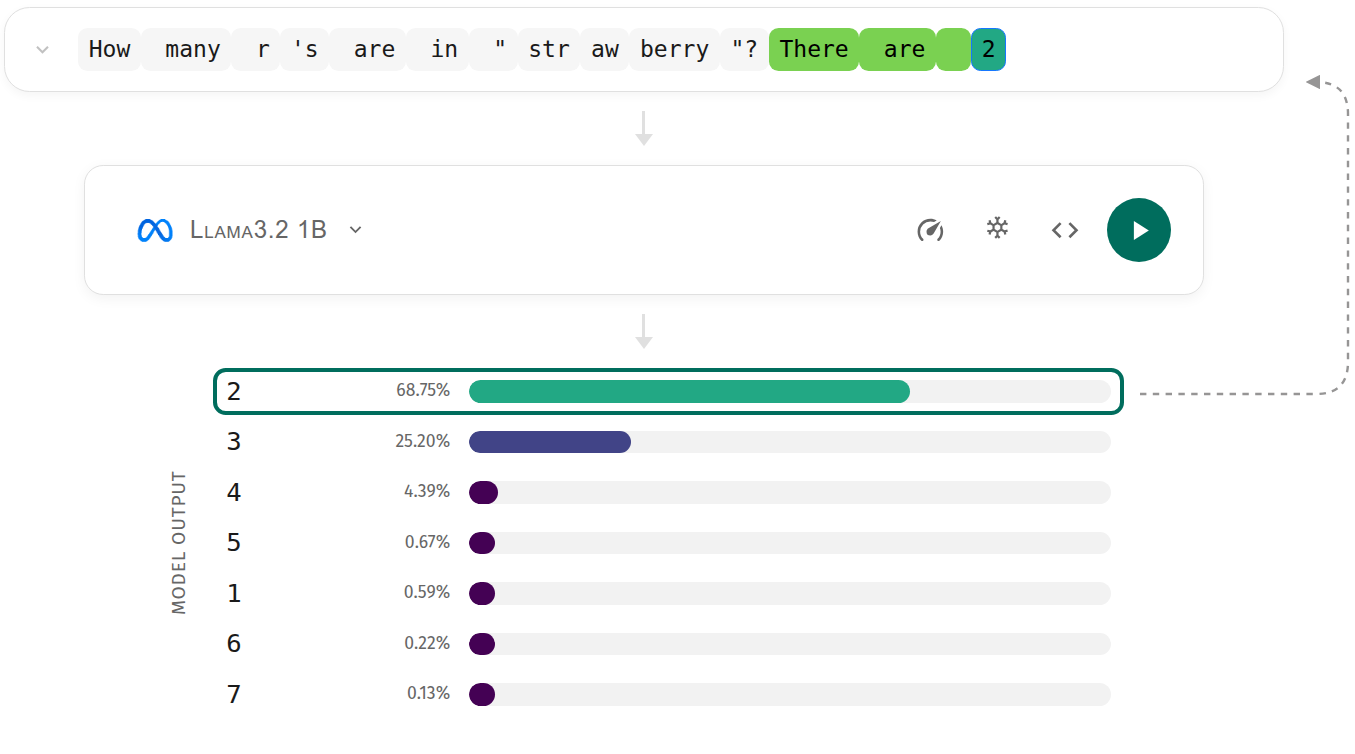
Расширяя Горизонты: Многоязычная Поддержка и Разнообразие Моделей
Интерфейс AnimatedLLM разработан с учетом принципов доступности, позволяя пользователям из разных стран изучать внутреннюю работу больших языковых моделей независимо от их родного языка. В настоящее время платформа поддерживает пять языков — английский, чешский, французский, украинский и китайский — что значительно расширяет аудиторию, заинтересованную в понимании и исследовании LLM. Такая многоязычность не только способствует глобальному распространению знаний в области искусственного интеллекта, но и позволяет учитывать лингвистические особенности при анализе поведения моделей, открывая новые возможности для совершенствования и адаптации технологий в различных культурных контекстах.
Приложение предоставляет возможность работы с разнообразным набором больших языковых моделей, включая Olmo 3 и Aya Expanse, что открывает перспективы для сравнительного анализа их архитектур и данных, использованных при обучении. В настоящее время поддерживаются пять моделей: Olmo 3, Aya Expanse, Llama 3.2, Qwen 3 и GPT-2. Эта функциональность позволяет исследователям и разработчикам оценить сильные и слабые стороны каждой модели в различных задачах, выявить особенности их поведения и выбрать наиболее подходящую для конкретного применения. Такой подход способствует более глубокому пониманию принципов работы больших языковых моделей и стимулирует развитие новых, более эффективных и надежных алгоритмов.
Универсальность AnimatedLLM проявляется в его способности служить эффективным инструментом как для образовательных целей, так и для проведения передовых научных исследований. Благодаря поддержке различных языковых моделей, включая Olmo 3 и Aya Expanse, платформа позволяет сравнивать архитектуры и данные обучения, предоставляя уникальную возможность для глубокого анализа. Такая широкая совместимость делает AnimatedLLM ценным ресурсом для студентов, преподавателей и исследователей, стремящихся к пониманию принципов работы больших языковых моделей и их потенциальных возможностей. Возможность экспериментировать с разными моделями и визуализировать их поведение способствует более глубокому освоению материала и стимулирует инновационные подходы в области искусственного интеллекта.
Расширяя доступ к пониманию больших языковых моделей (LLM), AnimatedLLM предоставляет разработчикам и исследователям инструменты для создания более надежных и этичных приложений искусственного интеллекта. Обеспечивая наглядную визуализацию внутренней работы этих сложных систем, платформа позволяет не только изучать принципы их функционирования, но и выявлять потенциальные уязвимости и предвзятости. Это, в свою очередь, способствует разработке алгоритмов, свободных от нежелательных искажений, и повышает доверие к результатам, генерируемым искусственным интеллектом. Таким образом, AnimatedLLM способствует не просто использованию LLM, а осознанному и ответственному развитию технологий искусственного интеллекта, ориентированному на создание справедливых и полезных решений для общества.
Изучение архитектуры больших языковых моделей, как это реализовано в AnimatedLLM, неизбежно приводит к вопросам о фундаментальной устойчивости алгоритмов. Пусть N стремится к бесконечности — что останется устойчивым? Этот вопрос перекликается с высказыванием Давида Гильберта: «Мы должны знать. Мы будем знать.» (Мы должны знать. Будем знать.). AnimatedLLM наглядно демонстрирует сложные процессы, такие как токенизация и генерация текста, позволяя увидеть, как даже в условиях огромного количества данных и параметров, определенные принципы остаются неизменными. Визуализация внутренних механизмов модели не просто объясняет их, но и подтверждает необходимость математической строгости в основе любого алгоритма, ведь только так можно гарантировать его корректность и предсказуемость.
Куда дальше?
Представленная работа, хоть и демонстрирует элегантный подход к визуализации сложных процессов в больших языковых моделях, лишь слегка приоткрывает завесу над истинной сложностью проблемы. Интерактивные инструменты, безусловно, полезны для обучения, однако они не решают фундаментальной задачи — обеспечения доказуемой корректности и предсказуемости этих систем. Визуализация — это иллюстрация, а не доказательство. Алгоритм, работающий на тестовых данных, может обернуться катастрофой в реальной среде, если его логика не поддается строгой математической формализации.
Будущие исследования должны быть направлены не только на создание более интуитивно понятных интерфейсов, но и на разработку методов формальной верификации и анализа LLM. Необходимо стремиться к созданию моделей, поведение которых можно предсказать и обосновать математически. В противном случае, мы обречены на бесконечную борьбу с эмпирическими ошибками и случайными артефактами, а иллюзия понимания, создаваемая визуализациями, лишь усугубит проблему.
В хаосе данных спасает только математическая дисциплина. Успех в этой области потребует не просто умения строить сложные алгоритмы, но и способности доказывать их корректность. Иначе, все наши усилия по визуализации и объяснению LLM превратятся в красивую, но бессмысленную игру теней.
Оригинал статьи: https://arxiv.org/pdf/2601.04213.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-11 20:46