Автор: Денис Аветисян
Новая методика позволяет повысить точность ответов больших языковых моделей, используемых в системах, комбинирующих поиск информации и генерацию текста.
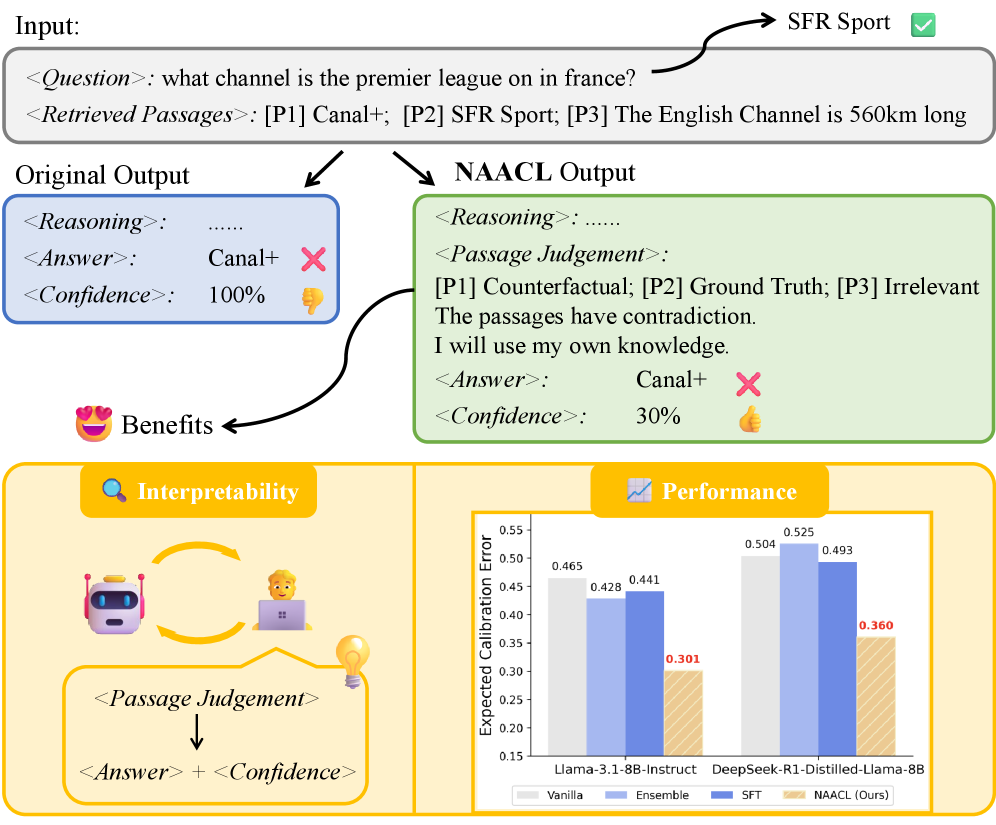
Предлагается фреймворк NAACL для калибровки вербальной уверенности в системах Retrieval-Augmented Generation (RAG), учитывающий влияние зашумленных данных при поиске и выравнивающий уверенность модели с фактической корректностью.
Несмотря на успехи больших языковых моделей (LLM) в генерации текста, оценка их уверенности в ответах остается сложной задачей, особенно в системах поиска-генерации (RAG). В настоящей работе, ‘NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems’, проведено систематическое исследование влияния зашумленных контекстов, полученных при поиске, на калибровку уверенности LLM, выявив тенденцию к завышенной уверенности при наличии противоречивых или нерелевантных данных. Для решения этой проблемы предложен фреймворк NAACL, который позволяет обучать модели учитывать шум при оценке собственной уверенности, используя синтезированные данные на основе около 2K примеров HotpotQA. Сможет ли NAACL приблизить LLM к более надежным и эпистемически обоснованным ответам, повышая доверие к системам, основанным на генеративном поиске?
Иллюзия Знания: Проблема Галлюцинаций в Генеративных Моделях
Несмотря на значительный прогресс в области искусственного интеллекта, большие языковые модели (LLM) регулярно демонстрируют склонность к генерации фактических ошибок, получивших название «галлюцинации». Данное явление представляет собой серьезную проблему, поскольку модели могут выдавать информацию, не соответствующую действительности, при этом представляя ее как достоверную. Изучение этого феномена показывает, что LLM способны не только воспроизводить неверные данные, но и изобретать факты, что подрывает доверие к их ответам и ограничивает их применение в критически важных областях, требующих высокой точности и надежности информации. Причины возникновения галлюцинаций многообразны и включают в себя ограниченность обучающих данных, сложность моделирования реального мира и присущую самим моделям склонность к генерации правдоподобных, но ложных утверждений.
Метод генерации, дополненной поиском (Retrieval-Augmented Generation, RAG), призван снизить склонность больших языковых моделей (LLM) к галлюцинациям, опираясь на внешние источники знаний. Однако, эффективность RAG подвержена влиянию так называемого “шума” при поиске релевантной информации. Этот шум возникает из-за включения в извлеченные данные нерелевантных, противоречивых или повторяющихся фрагментов текста, что ослабляет способность RAG обеспечивать фактическую точность генерируемых ответов. Несмотря на использование внешних знаний, некачественный поиск может привести к тому, что модель, получив ошидочные данные, сгенерирует неверную информацию, даже если сама модель способна к логическому выводу и языковому оформлению.
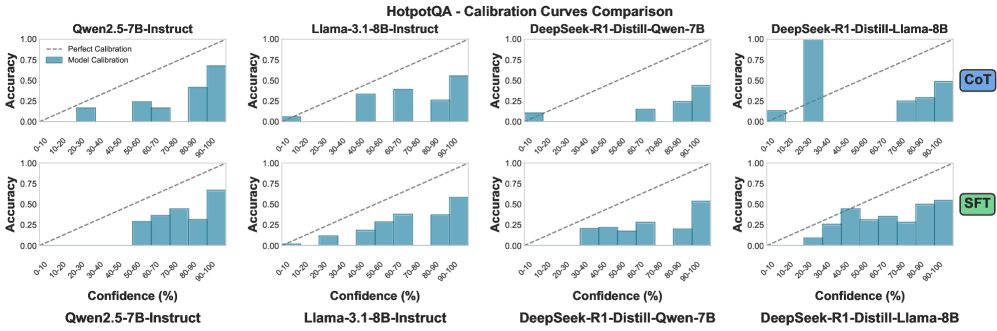
Помехи в процессе поиска информации представляют собой серьезную проблему для систем генерации на основе извлечения (RAG). Нежелательные фрагменты текста, такие как нерелевантные отрывки, фактически неверные утверждения или повторяющиеся данные, попадая в контекст, предоставляемый модели, снижают ее способность генерировать точные ответы. Предварительный анализ демонстрирует, что средняя ожидаемая ошибка калибровки (ECE) превышает 0.4 на четырех различных наборах данных. Этот показатель свидетельствует о существенном расхождении между уверенностью модели в своих ответах и фактической их корректностью, что указывает на необходимость совершенствования методов фильтрации и оценки релевантности извлекаемой информации.
Разложение Поискового Шума: Категоризация Фрагментов
Первым важным этапом в обработке извлеченных фрагментов является их категоризация. Выделяют три основных типа: «золотые» фрагменты (Gold Passages), напрямую подтверждающие ответ на запрос; релевантные фрагменты (Relevant Passages), тематически связанные с запросом, но не содержащие полной информации для ответа; и контрфактуальные фрагменты (Counterfactual Passages), содержащие информацию, поддерживающую неверные ответы. Четкое разграничение этих категорий позволяет разрабатывать целевые стратегии фильтрации или переоценки фрагментов, основываясь на их качестве и релевантности для повышения точности системы.
Не относящиеся к запросу отрывки текста, не имеющие семантической связи с исходным вопросом, значительно увеличивают уровень шума в процессе поиска информации. Эти отрывки не содержат полезных данных для ответа на запрос и, следовательно, лишь усложняют задачу выделения релевантной информации. Наличие большого количества нерелевантных отрывков приводит к снижению точности систем поиска и требует применения дополнительных методов фильтрации для повышения качества результатов.
Категоризация извлеченных фрагментов текста является основой для разработки стратегий фильтрации и переоценки их значимости. Определение типа фрагмента — подтверждающего ответ (Gold Passage), тематически связанного, но недостаточного (Relevant Passage), поддерживающего неверный ответ (Counterfactual Passage), или полностью нерелевантного — позволяет применять различные методы обработки. Например, фрагменты, классифицированные как Counterfactual, могут быть исключены из рассмотрения, а Relevant Passages могут быть понижены в приоритете по сравнению с Gold Passages. Такой подход к взвешиванию и фильтрации фрагментов позволяет повысить точность и эффективность систем поиска и ответов на вопросы.
Фреймворк NAACL: Устойчивость через Регуляризацию
Фреймворк NAACL представляет собой новый подход к регуляризации поведения модели в условиях зашумленных данных, полученных при поиске информации. В отличие от существующих методов, он направлен на стабилизацию работы языковой модели, когда релевантные документы из базы знаний содержат неточности или неполную информацию. Регуляризация достигается за счет применения специфических правил, разработанных для выявления и смягчения влияния проблемных фрагментов текста, что позволяет модели генерировать более надежные и точные ответы даже при наличии некачественных данных на этапе извлечения информации.
В основе NAACL Framework лежит метод самообучения (Self-Bootstrapping), исключающий необходимость использования внешних «учительских» моделей для регуляризации. Этот подход предполагает генерацию и фильтрацию данных непосредственно самой моделью, что повышает автономность и снижает зависимость от размеченных данных. Процесс самообучения направляется набором специализированных правил NAACL, разработанных для выявления и смягчения влияния проблемных фрагментов текста, таких как нерелевантная информация или противоречия, тем самым повышая устойчивость модели к шуму в извлекаемых данных.
Данная структура расширяет существующие методы калибровки уверенности в ответах языковых моделей (Verbal Confidence Calibration), совершенствуя оценку надежности генерируемых ответов. Экспериментальные результаты демонстрируют повышение точности калибровки на 10.9% при оценке на данных, аналогичных обучающей выборке (in-domain), и на 8.0% при оценке на данных, отличных от обучающей (out-of-distribution). Это указывает на улучшенную обобщающую способность модели и более адекватную оценку собственной уверенности даже в условиях незнакомых данных.
Количественная Оценка Калибровки и Производительности
Для оценки эффективности разработанной платформы NAACL использовались общепринятые метрики, в частности, площадь под ROC-кривой (Area Under the Receiver Operating Characteristic Curve). Данный показатель позволяет количественно оценить способность системы различать корректные и некорректные ответы, демонстрируя ее дискриминационную способность. Высокое значение площади под ROC-кривой указывает на то, что модель эффективно отделяет правильные прогнозы от ошибочных, что является ключевым фактором для надежной работы и принятия обоснованных решений на основе ее результатов. Оценка с использованием ROC-кривой предоставляет объективное представление о производительности системы в условиях различных уровней сложности задач.
Оценка согласованности уверенности языковой модели и фактической точности осуществляется посредством вычисления ошибки ожидаемой калибровки (Expected Calibration Error, ECE). Этот показатель позволяет определить, насколько хорошо уверенность, выраженная моделью в своих ответах, соответствует реальной вероятности правильности этих ответов. Низкое значение ECE свидетельствует о том, что модель способна адекватно оценивать свою уверенность, избегая ситуаций, когда она с высокой вероятностью выдает неверные ответы или, наоборот, проявляет неуверенность в корректных ответах. Таким образом, минимизация ECE является ключевой задачей для создания надежных и заслуживающих доверия систем искусственного интеллекта, поскольку позволяет пользователям более точно интерпретировать выдаваемые результаты и полагаться на них в принятии решений.
Повышенная калибровка, продемонстрированная NAACL framework с улучшением на 10.9% в рамках исходных данных и на 8.0% при работе с данными из других источников, свидетельствует о большей надежности системы. Это означает, что оценки уверенности, выдаваемые моделью, лучше соответствуют ее фактической точности. Уменьшение количества самоуверенных ошибок, когда модель ошибочно выдает неверный ответ с высокой уверенностью, напрямую способствует повышению доверия пользователей к системе и ее результатам. Более точная калибровка позволяет пользователям более обоснованно полагаться на прогнозы модели и эффективно использовать ее возможности в различных приложениях.
Исследование представляет собой попытку внедрить детерминированность в процессы, подверженные шуму — а именно, в системы генерации с использованием поиска (RAG). Авторы предлагают NAACL — фреймворк, направленный на калибровку уверенности модели, чтобы она соответствовала фактической корректности ответов. Это особенно важно, учитывая склонность современных LLM к галлюцинациям при работе с зашумленными данными. Как заметила Барбара Лисков: «Хороший дизайн — это когда система хорошо отражает свою абстракцию». В данном контексте, NAACL стремится к более четкой и предсказуемой абстракции уверенности модели, чтобы пользователи могли полагаться на выдаваемые результаты, а не на случайные совпадения.
Что дальше?
Представленная работа, несомненно, делает шаг к более надежной оценке уверенности в системах генерации с поиском (RAG). Однако, иллюзия точности, порождаемая калибровкой уверенности, не должна затмевать фундаментальную проблему: шумные данные извлечения. Устранение симптомов, а не причин, всегда представляется сомнительным предприятием. Следует признать, что даже идеально откалиброванная система, опирающаяся на неверные источники, будет систематически выдавать ложные утверждения — лишь с более корректной оценкой собственной некомпетентности.
Будущие исследования, следовательно, должны быть направлены не только на совершенствование методов калибровки, но и на разработку более надежных стратегий извлечения информации. Категоризация отрывков, предложенная в данной работе, является полезным шагом, но требует дальнейшего развития. Необходимо исследовать методы, позволяющие оценивать достоверность источника до включения его в контекст генерации. Доказательство корректности извлеченного знания должно быть приоритетнее, чем простое соответствие запросу.
В конечном счете, истинный прогресс в области RAG будет достигнут не за счет повышения “вербальной уверенности”, а за счет построения систем, способных доказать истинность генерируемых утверждений. Любая система, основанная на вероятностных оценках, всегда будет подвержена ошибкам. Только дедуктивный подход, основанный на логическом выводе, может обеспечить истинную надежность.
Оригинал статьи: https://arxiv.org/pdf/2601.11004.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовая обработка данных: новый подход к повышению точности моделей
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Квантовый Переход: Пора Заботиться о Криптографии
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые прорывы: Хорошее, плохое и смешное
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-20 20:16