Автор: Денис Аветисян
В статье представлена формальная основа для систематического сравнения и улучшения методов оценки в различных научных областях.
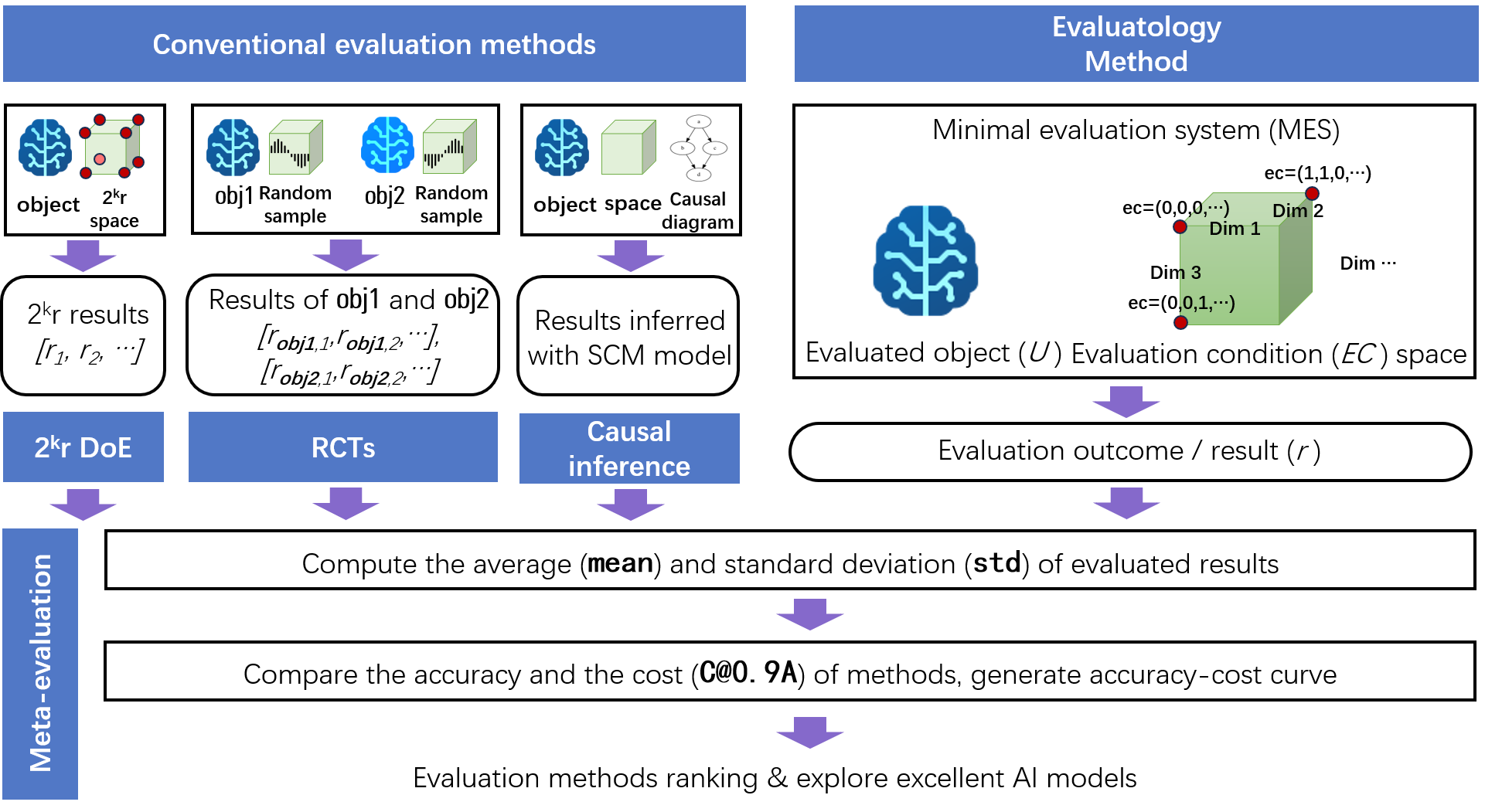
Предложен фреймворк мета-оценки, включающий бенчмарк AxiaBench, который демонстрирует превосходство нового подхода в области Evaluatology.
Оценка является основой эмпирической науки, однако систематическая оценка самих методов оценки — так называемая мета-оценка — остается слабоизученной областью. В работе ‘On Meta-Evaluation’ предложен формальный подход к мета-оценке, включающий в себя эталонный набор данных AxiaBench, для сравнительного анализа и улучшения методов оценки в различных научных областях. Полученные результаты демонстрируют, что ни один из существующих методов не обеспечивает одновременно высокую точность и эффективность во всех сценариях, а недавно предложенный метод стратифицированной выборки по всему пространству параметров стабильно превосходит традиционные подходы. Возможно ли, используя принципы мета-оценки, создать универсальную систему оценки, гарантирующую надежность и воспроизводимость научных результатов?
Оценка оценок: Зачем переоценивать то, что уже оценено?
Оценка производительности моделей машинного обучения представляется задачей не столь однозначной, как может показаться на первый взгляд. Стандартные наборы данных для тестирования, или бенчмарки, зачастую дают искажённую картину реальных возможностей алгоритмов. Это связано с тем, что данные в бенчмарках могут не отражать сложность и разнообразие задач, с которыми модель столкнётся в реальных условиях, а также могут содержать скрытые систематические ошибки или предвзятости. В результате, модель, демонстрирующая высокие результаты на бенчмарке, может оказаться неэффективной при решении практических задач, что подрывает доверие к технологиям искусственного интеллекта и замедляет их внедрение в различные сферы жизни. Более того, оптимизация моделей под конкретные бенчмарки может привести к переобучению и ухудшению обобщающей способности, что является серьёзной проблемой для создания надёжных и устойчивых систем.
Существенная проблема в оценке современных моделей машинного обучения заключается в отсутствии надежных мета-оценочных фреймворков, способных выявлять систематические искажения и неточности. В то время как отдельные модели подвергаются тестированию на стандартных наборах данных, мало кто анализирует сами методы оценки, что приводит к ситуации, когда ошибочные или предвзятые метрики могут незаметно влиять на представление о реальной производительности. Такие фреймворки должны позволять не только измерять точность, но и обнаруживать, например, чувствительность к специфическим особенностям данных, предвзятость в отношении определенных групп или тенденцию к переобучению. Без возможности критической оценки самих оценочных процедур, прогресс в машинном обучении рискует оказаться иллюзорным, а разработки — неэффективными в реальных условиях применения.
Существующие методы оценки производительности моделей машинного обучения сталкиваются с серьезной дилеммой: стремление к высокой статистической мощности часто требует неприемлемых вычислительных затрат. Для получения достоверных результатов необходимо анализировать большое количество данных и проводить множество экспериментов, что может быть непосильно даже для мощных вычислительных систем. В результате исследователи вынуждены идти на компромиссы, используя более простые, но менее надежные методы оценки. Это приводит к ситуации, когда результаты, опубликованные в научных статьях, могут быть невоспроизводимыми или не отражать реальную производительность модели в практических условиях. Таким образом, достижение баланса между точностью оценки и ее стоимостью остается одной из ключевых проблем, препятствующих дальнейшему прогрессу в области машинного обучения и ограничивающих возможности его применения.
Отсутствие точной и надежной оценки моделей машинного обучения ставит под вопрос саму основу прогресса в этой области. Недостаточно проверенные алгоритмы, успешно демонстрирующие результаты на ограниченных или предвзятых наборах данных, рискуют потерпеть неудачу при применении к реальным задачам. Это приводит к неэффективным решениям, финансовым потерям и, что особенно важно, к утрате доверия к технологиям искусственного интеллекта. Качество и надежность машинного обучения напрямую зависят от способности адекватно измерять и подтверждать эффективность разработанных моделей, а несовершенство существующих методов оценки значительно ограничивает их практическую ценность и потенциальное влияние на различные сферы жизни.
AxiaBench: Систематический взгляд на оценку оценок
AxiaBench представляет собой эталонный набор данных, разработанный для строгой оценки методов оценки, а не самих моделей машинного обучения. В отличие от традиционных бенчмарков, которые измеряют производительность моделей на заданных задачах, AxiaBench фокусируется на оценке надежности и эффективности различных методологий, используемых для измерения качества моделей. Это означает, что AxiaBench оценивает, насколько точно и последовательно различные методы оценки могут определять реальные улучшения в производительности моделей, а не просто измеряет сами результаты моделей. Целью является предоставление объективной основы для сравнения и выбора оптимальных методов оценки в различных областях применения.
AxiaBench использует методологию EvaluatologyMethod, представляющую собой фреймворк мета-оценки, для обеспечения всесторонней оценки методов оценки. Ключевым аспектом является использование стратифицированной выборки, позволяющей охватить широкий спектр сценариев и условий. Данный подход гарантирует, что оценка методов не будет смещена в сторону определенных типов задач или данных, а результаты будут репрезентативными для различных научных областей. Стратификация позволяет разделить совокупность задач на подгруппы на основе важных характеристик, что обеспечивает более точную и надежную оценку эффективности различных методов оценки.
В основе AxiaBench лежат рандомизированные контролируемые испытания (РКИ) и нерандомизированные контролируемые испытания (НРКИ) в качестве базовых методологий оценки. РКИ обеспечивают строгое сравнение, минимизируя систематические ошибки за счет случайного распределения участников по группам. НРКИ, в свою очередь, используются для оценки в условиях, когда рандомизация невозможна или непрактична, однако требуют более тщательного анализа для учета потенциальных смещений. Использование обеих категорий контролируемых испытаний позволяет AxiaBench проводить комплексную оценку других методов, сравнивая их эффективность и надежность с установленными стандартами в различных научных областях.
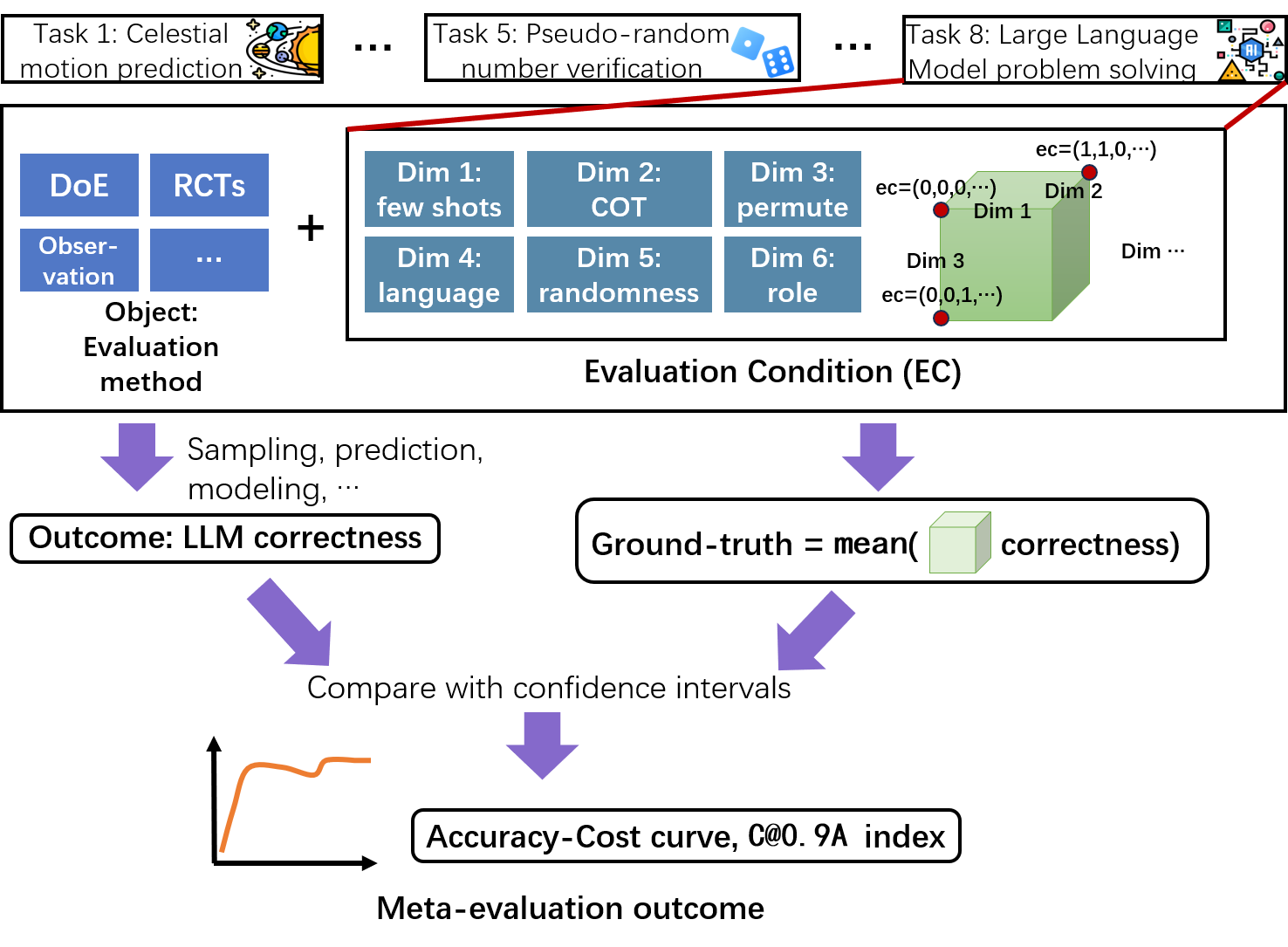
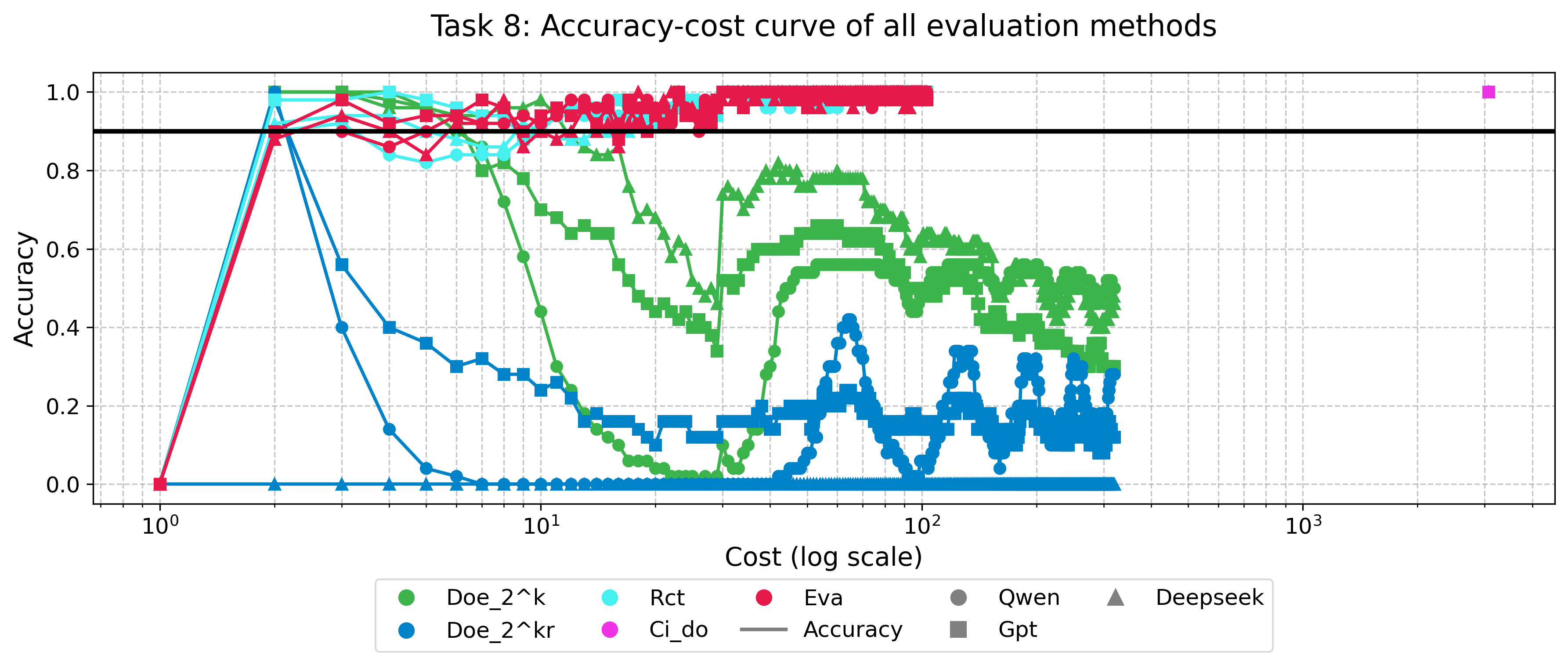
Методика InterventionStaggering позволяет оценивать методы оценки в различных условиях, что максимизирует получаемые знания. В рамках данной работы проведено систематическое, количественное сравнение 10 методов оценки в восьми научных областях. Этот подход подразумевает последовательное и контролируемое изменение условий проведения оценки, что позволяет выявить устойчивость и надежность каждого метода в разных сценариях. Результаты анализа, полученные с использованием InterventionStaggering, демонстрируют различия в производительности методов оценки в зависимости от специфики предметной области и условий тестирования.
За пределами простых сравнений: Сила экспериментального дизайна
В AxiaBench для эффективного исследования пространства конфигураций методов оценки используются факторные планы эксперимента, такие как DoE_2k и DoE_2kp. Эти планы позволяют систематически варьировать параметры методов оценки и анализировать их влияние на результаты, избегая полного перебора всех возможных комбинаций. DoE_2k исследует взаимодействие двух факторов на двух уровнях, в то время как DoE_2kp добавляет репликацию для повышения статистической значимости результатов. Использование факторных планов значительно сокращает количество необходимых экспериментов при сохранении высокой точности оценки эффективности различных стратегий.
Дизайн экспериментов DoE_2kr, включающий репликацию (повторение экспериментов), позволяет значительно повысить статистическую мощность и надежность получаемых результатов. Репликация подразумевает проведение одного и того же эксперимента несколько раз с независимыми выборками данных. Это позволяет уменьшить влияние случайных факторов и повысить точность оценки эффекта исследуемых параметров. Увеличение количества реплик напрямую коррелирует с уменьшением стандартной ошибки оценки и повышением доверительного интервала, что позволяет с большей уверенностью утверждать о статистической значимости наблюдаемых различий между различными методами оценки. В контексте AxiaBench, применение DoE_2kr способствует более надежной идентификации оптимальных конфигураций методов оценки и повышает доверие к выводам об их эффективности.
В сценариях, где факторы оценки имеют несколько уровней, методология DoE_lkl (L-k-l design) предоставляет гибкий и эффективный подход к проектированию экспериментов. В отличие от фиксированных дизайнов, DoE_lkl позволяет адаптировать количество экспериментов и уровни факторов к конкретным потребностям исследования. Это достигается путем систематического варьирования уровней каждого многоуровневого фактора в комбинации с другими факторами, что обеспечивает полное покрытие пространства конфигураций и позволяет выявить оптимальные стратегии оценки. Гибкость DoE_lkl особенно полезна при исследовании сложных систем, где взаимодействие между факторами может быть непредсказуемым, а количество возможных конфигураций велико.
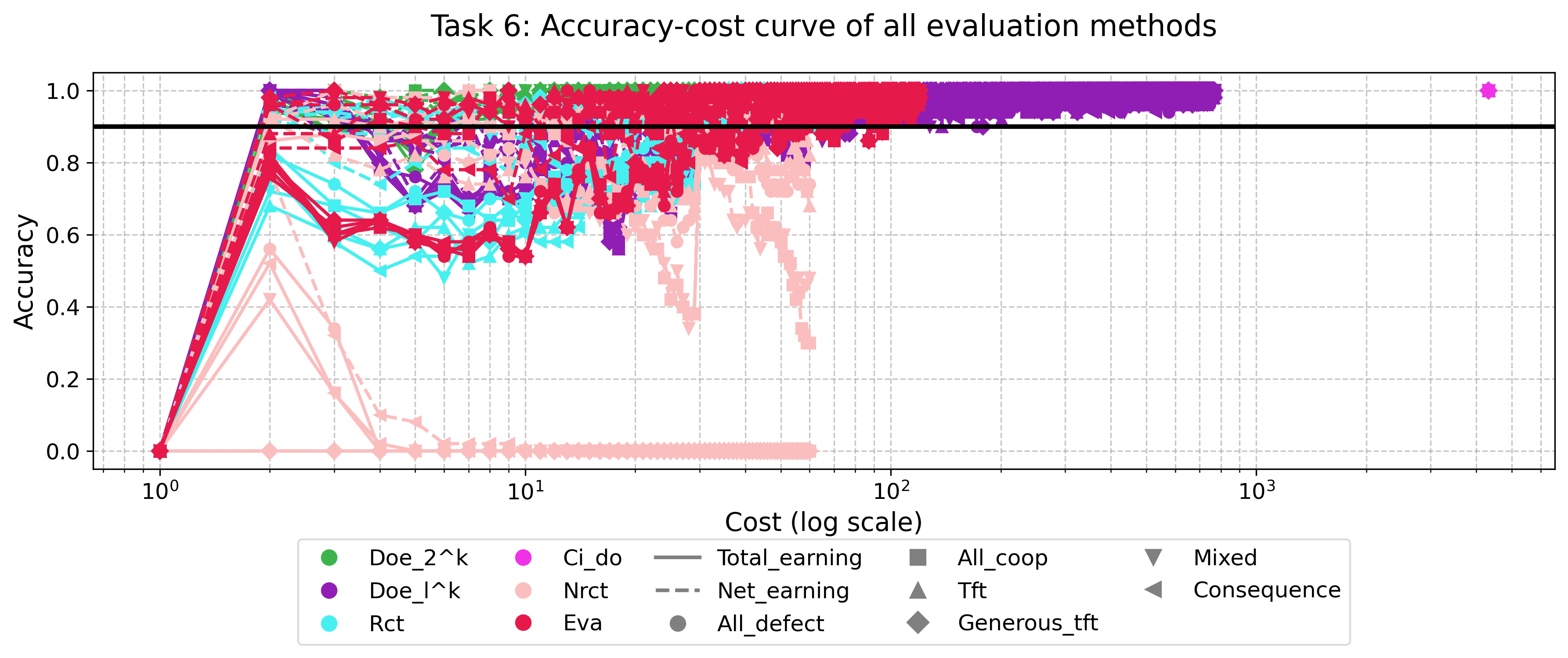
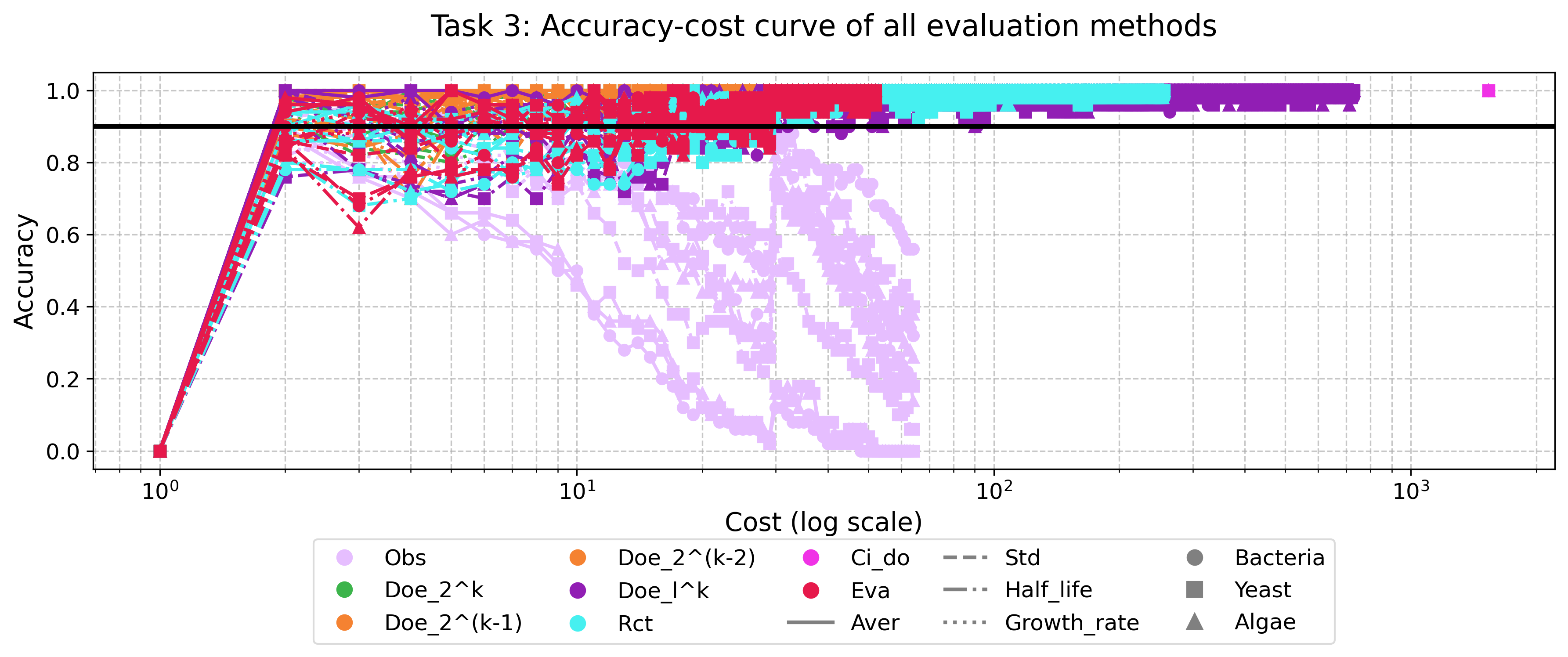
Использование факторных дизайнов, таких как DoE_2k и DoE_2kp, в сочетании с причинно-следственным моделированием на основе Структурных Причинных Моделей (SCM) и Do-исчисления, позволяет проводить строгий анализ эффективности различных стратегий оценки. Результаты экспериментов демонстрируют, что метод стратифицированной выборки стабильно достигает точности более 90% и характеризуется наименьшей стоимостью достижения высокой точности, измеряемой метрикой C@0.9A. Это позволяет не только оценить эффективность методов, но и установить причинно-следственные связи между параметрами оценки и конечным результатом.
Обеспечение валидности: Проверка на правдивость и случайность
Точность любой оценки напрямую зависит от надёжности эталонной истины, или GroundTruth, — то есть, от верных, объективно установленных данных, с которыми сравниваются результаты тестирования. AxiaBench использует разработанный метод ObservationMethod для тщательной проверки этого самого GroundTruth. Этот метод позволяет не просто констатировать наличие эталонных данных, но и удостовериться в их корректности и непредвзятости, что критически важно для обеспечения валидности всей оценки. Без надёжного GroundTruth любые сравнения и выводы становятся сомнительными, а оценка — субъективной и нерепрезентативной. Таким образом, проверка эталонной истины посредством ObservationMethod является фундаментом для объективной и достоверной оценки эффективности различных методов.
Исследование целостности экспериментальных данных, таких как последовательности осадков (PrecipitationSequence), требует тщательной проверки на случайность. Тест на случайность (RandomnessTest) позволяет выявить систематические отклонения от ожидаемого случайного распределения, которые могут указывать на ошибки в процессе сбора данных, смещения в алгоритмах обработки или даже на предсказуемые закономерности, маскирующиеся под случайность. Обнаружение подобных отклонений критически важно, поскольку они могут существенно исказить результаты анализа и привести к ошибочным выводам. В частности, отсутствие достаточной случайности может указывать на необходимость пересмотра методологии эксперимента или использования более надежных методов статистической обработки данных, обеспечивая тем самым достоверность и воспроизводимость научных исследований.
AxiaBench обеспечивает всестороннюю оценку методов оценки, применяя систематический подход к проверке двух ключевых аспектов. Недостаточно просто измерить производительность; необходимо удостовериться в достоверности эталонных данных (GroundTruth) и в том, что процесс генерации данных или проведения экспериментов действительно случаен. Тщательная проверка как эталонных значений, так и случайности процесса позволяет выявить систематические ошибки и предвзятости, которые могут исказить результаты оценки. Именно такой строгий анализ позволяет выйти за рамки поверхностных сравнений и получить более глубокое понимание надежности и валидности различных методов оценки, способствуя развитию более точных и объективных инструментов в соответствующей области.
Предлагаемый подход к оценке выходит за рамки поверхностных сопоставлений различных методов, стремясь к более глубокому пониманию надежности и валидности получаемых результатов. Традиционно, оценка часто ограничивалась простым сравнением показателей, не учитывая внутреннюю согласованность данных и вероятность случайных совпадений. Данная методология, напротив, акцентирует внимание на систематической проверке исходных данных и процессов, обеспечивая уверенность в том, что выявленные различия действительно отражают реальные особенности исследуемого явления, а не являются следствием погрешностей или случайности. Такой уровень строгости позволяет перейти от констатации факта различий к пониманию причин их возникновения, открывая новые перспективы для развития и совершенствования методов оценки в различных областях науки и техники.
Исследование, представленное в статье, демонстрирует, что даже в строгой науке, где ожидается объективность, методы оценки подвержены субъективным искажениям. Авторы предлагают формализованный подход к мета-оценке, стремясь к более надежным результатам. Но ведь человек — не рациональный агент, а биологическая гипотеза с систематическими ошибками, и это проявляется даже в создании систем оценки. Как точно подмечено Иммануил Кант: «Действуй так, чтобы максима твоя могла стать всеобщим законом». В контексте статьи, это означает, что критерии оценки должны быть универсальными и последовательными, чтобы избежать произвола и предвзятости. Ведь зачастую люди выбирают не оптимум, а комфорт, и это проявляется и в том, какие метрики они используют для оценки, предпочитая те, что подтверждают их ожидания.
Что дальше?
Представленная работа, формализуя саму практику оценки, выявляет закономерную, но неприятную истину: оценка не объективна, а лишь более изощрённый способ проявления субъективных предпочтений. Выигрыш предложенного подхода над прочими — не свидетельство его истинной ценности, а лишь подтверждение того, что даже в науке человек склонен отдавать предпочтение тому, что соответствует его внутренним установкам. Рынок, в данном случае, — это коллективная медитация на тему уверенности в правильности выбранного критерия.
AxiaBench, как и любой бенчмарк, неизбежно станет полем битвы за цифры, а не за истину. Важнее не само сравнение методов, а осознание того, что любая метрика — лишь проекция желаемого результата на реальность. Вопрос не в том, какой метод оценки «лучше», а в том, какие ценности он воспроизводит. Инвестор не ищет прибыль — он ищет смысл, и оценка — лишь инструмент его поиска.
Будущие исследования должны сосредоточиться не на оптимизации метрик, а на понимании когнитивных искажений, лежащих в основе процесса оценки. Необходимо исследовать, как контекст, предубеждения и социальные факторы влияют на выбор критериев и интерпретацию результатов. Задача не в создании идеальной оценки, а в осознании её принципиальной неполноты.
Оригинал статьи: https://arxiv.org/pdf/2601.14262.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 05:42