Автор: Денис Аветисян
Новый подход позволяет систематизировать и визуализировать слабые места современных нейросетей, открывая возможности для более эффективной отладки и улучшения качества генерации.
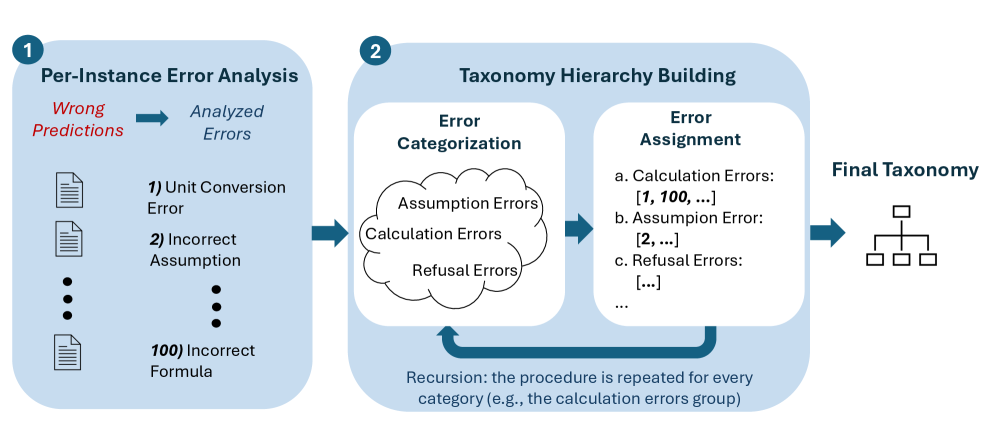
В статье представлена методика ErrorMap для создания структурированной таксономии ошибок больших языковых моделей и ErrorAtlas — полученная в результате таксономия, способствующая лучшему пониманию и диагностике проблем.
Несмотря на успехи больших языковых моделей (LLM), существующие бенчмарки часто указывают лишь на где модель ошибается, но не почему. В работе ‘ErrorMap and ErrorAtlas: Charting the Failure Landscape of Large Language Models’ представлен метод ErrorMap, позволяющий систематически картировать источники ошибок LLM и строить таксономию этих ошибок — ErrorAtlas. Этот подход позволяет не только выявлять скрытые слабости моделей и направлять их улучшение, но и более глубоко понимать природу совершаемых ими ошибок. Какие новые возможности для отладки, оценки и интерпретации LLM открывает детальный анализ их «ландшафта неудач»?
Разбирая систему: Вызовы понимания ошибок больших языковых моделей
Несмотря на впечатляющие возможности, современные большие языковые модели (LLM) демонстрируют подверженность разнообразным и порой незаметным ошибкам. Эти ошибки не ограничиваются простыми грамматическими или синтаксическими погрешностями; они могут проявляться в логических несоответствиях, фактических неточностях, предвзятых суждениях или неспособности адекватно обрабатывать неоднозначные запросы. Спектр возможных ошибок чрезвычайно широк и зависит от множества факторов, включая объем и качество обучающих данных, архитектуру модели и сложность поставленной задачи. Выявление и классификация этих ошибок представляет собой сложную проблему, требующую новых подходов к оценке и анализу работы LLM, поскольку простое измерение общей точности не позволяет понять природу и причины их возникновения.
Традиционные метрики оценки, такие как точность и прецизионность, хотя и позволяют количественно оценить производительность больших языковых моделей, зачастую оказываются недостаточными для выявления первопричин возникающих ошибок. Эти показатели сообщают лишь о наличии ошибки, но не раскрывают её природу — является ли она следствием недостатка данных, логической непоследовательности, неверной интерпретации запроса или иных факторов. Отсутствие детального анализа, объясняющего, почему модель совершает ту или иную ошибку, существенно затрудняет процесс целенаправленного улучшения. В результате, разработчики сталкиваются с необходимостью полагаться на эмпирические методы и дорогостоящие эксперименты для выявления и устранения проблем, что замедляет прогресс в создании более надежных и предсказуемых систем искусственного интеллекта.
Для создания действительно надежных и заслуживающих доверия систем искусственного интеллекта необходимо глубокое понимание характерных ошибок, допускаемых большими языковыми моделями. Простое измерение точности или полноты недостаточно, поскольку не раскрывает природу этих сбоев. Исследование различных режимов отказа — от логических противоречий и фактических неточностей до тонких стилистических погрешностей и предвзятости — позволяет выявить системные недостатки в архитектуре и данных обучения. Именно такой детальный анализ открывает путь к разработке более эффективных методов отладки, корректировки и повышения устойчивости языковых моделей, обеспечивая их предсказуемость и надежность в критически важных приложениях, где последствия ошибок могут быть значительными.
ErrorMap: Гранулярный профиль ошибок — взгляд сквозь систему
Метод ErrorMap представляет собой новый подход к анализу ошибок больших языковых моделей (LLM) посредством профилирования на уровне отдельных экземпляров. В отличие от агрегированных метрик, ErrorMap позволяет выявлять конкретные точки отказа в генерации ответов моделью для каждого отдельного запроса. Это достигается путем анализа поведения LLM на конкретных входных данных и идентификации ошибок, возникающих в процессе обработки каждого отдельного случая. Такой подход обеспечивает более детальное понимание слабых мест модели и позволяет точно определить причины возникновения ошибок, что важно для последующей отладки и улучшения LLM.
Метод ErrorMap использует поэтапное построение таксономии (Layered Taxonomy Construction) для организации типов ошибок в иерархическую структуру. Это позволяет создать детализированную классификацию, выявляя конкретные слабые места языковой модели. Иерархия строится последовательно, начиная с общих категорий ошибок и постепенно детализируясь до более специфичных подтипов. Такая структура обеспечивает возможность анализа ошибок на различных уровнях детализации, что облегчает определение первопричин и разработку стратегий улучшения производительности модели. Например, общая категория «логические ошибки» может быть разделена на подкатегории «ошибки дедукции», «ошибки индукции» и «ошибки абдукции», каждая из которых далее детализируется.
В процессе категоризации ошибок, возникающих в больших языковых моделях, используется модель GPT-oss-120b в качестве автоматизированного судьи. Это позволяет обеспечить согласованность и объективность при отнесении конкретных случаев ошибок к определенным категориям. Модель GPT-oss-120b оценивает выходные данные LLM и классифицирует ошибки, минимизируя субъективность, которая может возникнуть при ручной оценке. Использование данной модели в качестве арбитра гарантирует воспроизводимость результатов и позволяет проводить более надежный анализ слабых мест LLM.

ErrorAtlas: Статичная таксономия ошибок — карта системы
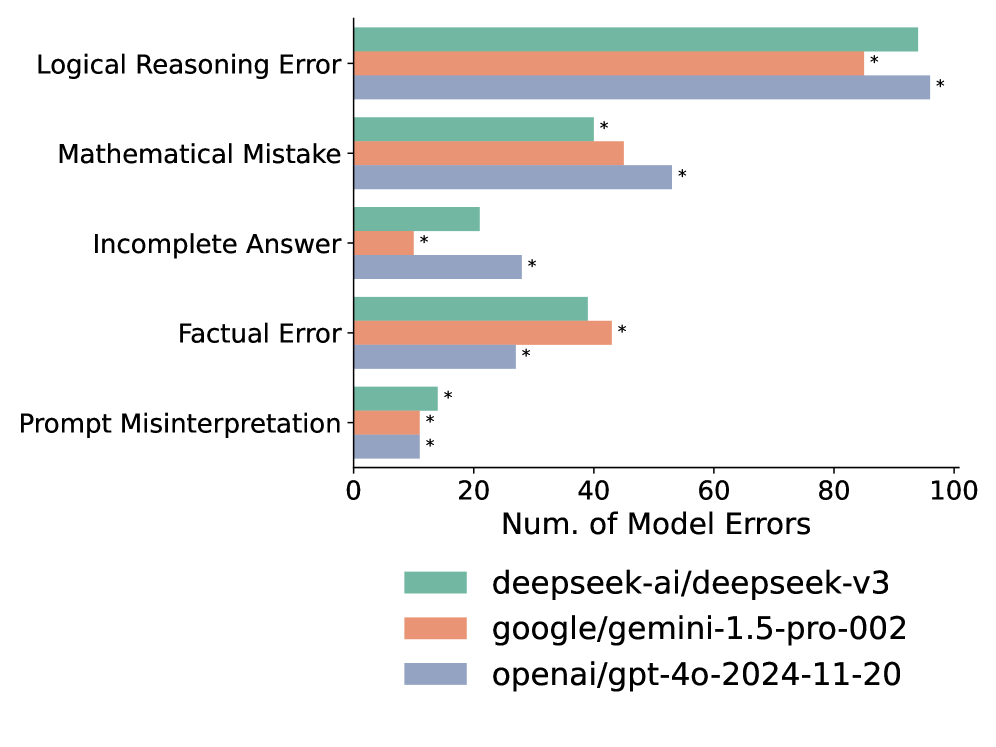
ErrorAtlas представляет собой статичную таксономию ошибок, возникающих у больших языковых моделей (LLM), разработанную на основе инструмента ErrorMap. Эта таксономия обеспечивает стандартизированную основу для всестороннего анализа ошибок, классифицируя их по конкретным типам и категориям. В отличие от общих метрик оценки производительности, ErrorAtlas позволяет проводить детальный анализ типов ошибок, что необходимо для глубокого понимания поведения модели и выявления областей, требующих улучшения. Статичность таксономии гарантирует воспроизводимость и сопоставимость результатов анализа между различными моделями и наборами данных.
ErrorAtlas позволяет проводить сравнительный анализ языковых моделей (LLM) не только по общей производительности, но и по типам совершаемых ими ошибок. Традиционные метрики оценивают только итоговый результат, в то время как ErrorAtlas предоставляет детализированную классификацию ошибок, таких как фактические неточности, логические противоречия, стилистические погрешности и ошибки в понимании контекста. Это позволяет исследователям выявлять специфические слабые места каждой модели и проводить более точное сравнение, определяя, в каких областях одна модель превосходит другую. Например, одна модель может демонстрировать высокую точность, но быть склонна к галлюцинациям, в то время как другая может быть более последовательной, но менее креативной. Такой детализированный анализ способствует целенаправленной оптимизации и улучшению LLM.
Использование ErrorAtlas для бенчмаркинга позволяет получить более детальное представление о сильных и слабых сторонах языковых моделей, что способствует целенаправленной оптимизации. Методика, основанная на ErrorAtlas, демонстрирует высокую степень согласованности — в среднем 91.1% — между экспертной оценкой ошибок и анализом, выполненным искусственным интеллектом, подтверждая надежность и объективность предлагаемой таксономии.
Обеспечение надежности анализа: Проверка устойчивости системы
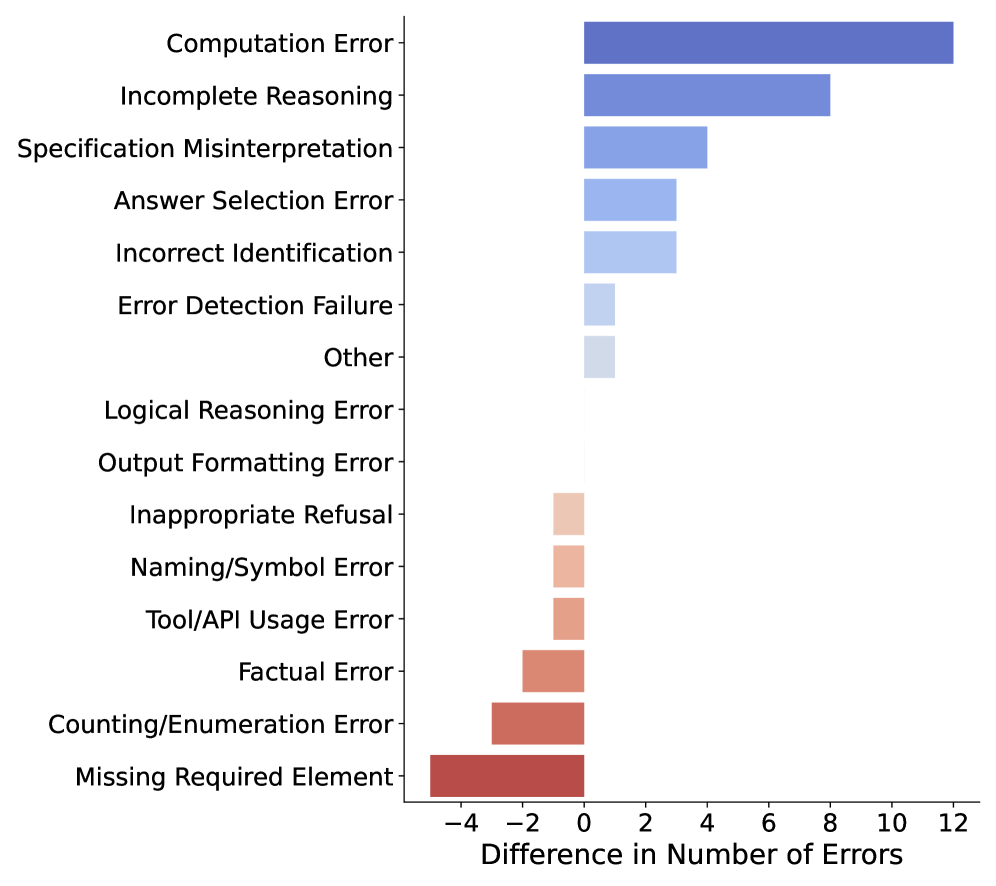
Анализ устойчивости, осуществляемый с помощью ErrorMap, направлен на оценку согласованности и надёжности процесса анализа ошибок в различных условиях. Данный подход позволяет выявить, насколько стабильны результаты категоризации ошибок при незначительных изменениях входных данных или параметров анализа. Используя ErrorMap, исследователи могут оценить, насколько предсказуемо система классифицирует ошибки, и определить факторы, влияющие на стабильность процесса. В конечном итоге, анализ устойчивости способствует повышению доверия к результатам оценки больших языковых моделей и предоставляет возможность выявления и устранения критических режимов отказа, обеспечивая более надежную и предсказуемую работу систем искусственного интеллекта.
Для количественной оценки стабильности категоризации ошибок используются методы бинарной классификации и метрики, такие как косинусное сходство. Бинарная классификация позволяет определить, насколько последовательно система относит один и тот же тип ошибки к определенной категории при незначительных изменениях входных данных или условий. Косинусное сходство, в свою очередь, измеряет угол между векторами, представляющими различные классификации ошибок, что позволяет оценить степень их согласованности. Высокое значение косинусного сходства указывает на то, что система последовательно классифицирует ошибки схожим образом, обеспечивая надежность анализа и возможность выявления ключевых точек отказа в работе больших языковых моделей.
Обеспечение надёжности анализа ошибок является фундаментом для доверия к оценке больших языковых моделей и открывает чёткий путь к смягчению критических сбоев. Тщательное тестирование демонстрирует высокую стабильность предложенного подхода: верхняя граница сходства между результатами анализа достигает 88%, а нижняя граница точности — также 88%. Эти показатели подтверждают, что предложенный метод позволяет последовательно и достоверно выявлять и классифицировать ошибки, что необходимо для разработки более устойчивых и надёжных языковых моделей, способных избегать наиболее опасных сценариев отказа. Такая надёжность анализа позволяет разработчикам с уверенностью оценивать прогресс в улучшении моделей и направлять усилия на устранение наиболее важных недостатков.

Исследование, представленное в статье, демонстрирует стремление к систематизации хаоса ошибок, свойственных большим языковым моделям. Создание ErrorMap и ErrorAtlas — это не просто каталогизация промахов, а попытка понять внутреннюю логику их возникновения. В этом контексте, слова Линуса Торвальдса особенно актуальны: «Если вы не пишете свой собственный код, вы не контролируете ситуацию». Подобно тому, как разработчик должен досконально понимать каждый аспект создаваемого им программного обеспечения, так и исследователи, работающие с большими языковыми моделями, должны глубоко анализировать природу ошибок, чтобы эффективно их устранять и улучшать систему. ErrorMap и ErrorAtlas, по сути, являются инструментами для «реверс-инжиниринга» этих моделей, позволяющими выявить скрытые закономерности и слабости.
Куда Ведет Эта Карта Ошибок?
Представленная работа, выстраивая систематизированную таксономию ошибок больших языковых моделей, лишь обнажает глубину нерешенных вопросов. Ошибка, зафиксированная и классифицированная, перестает быть хаосом, но становится лишь точкой на карте ещё более обширной, неизученной территории. По сути, ErrorMap и ErrorAtlas — это не столько решение проблемы, сколько инструмент для более точного определения границ незнания. Иронично, но систематизация провалов может оказаться продуктивнее, чем стремление к безупречности.
В дальнейшем, вместо слепого наращивания параметров моделей, возможно, стоит сосредоточиться на создании систем, способных не просто генерировать текст, но и осознавать собственные ограничения. Необходима разработка метрик, способных оценивать не столько «правильность» ответа, сколько степень уверенности модели в его корректности — своего рода «самодиагностика» искусственного интеллекта. Ведь ошибка, признанная моделью, гораздо менее опасна, чем ошибка, принятая ею за истину.
Наконец, стоит задуматься о природе самой «ошибки» в контексте языковых моделей. Что есть «неправильный» ответ? Просто несоответствие статистическим закономерностям обучающей выборки? Или проявление чего-то принципиально иного, ускользающего от формализации? Ответ на этот вопрос, вероятно, потребует выхода за рамки чисто инженерного подхода и обращения к более фундаментальным вопросам о природе интеллекта и познания.
Оригинал статьи: https://arxiv.org/pdf/2601.15812.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 02:20