Автор: Денис Аветисян
Исследователи представили Stable-DiffCoder, модель, использующую принципы диффузии для создания кода, демонстрирующую впечатляющие результаты среди моделей аналогичного масштаба.
Stable-DiffCoder использует непрерывное предварительное обучение, обучение с подкреплением по инструкциям и аугментацию данных на основе диффузии для достижения передовых показателей в генерации кода.
Несмотря на теоретические преимущества диффузионных языковых моделей (DLLM) в генерации кода, их практическая эффективность зачастую уступает авторегрессионным аналогам при сопоставимых вычислительных затратах. В данной работе, представленной в статье ‘Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model’, авторы предлагают Stable-DiffCoder — модель, использующую архитектуру Seed-Coder и демонстрирующую превосходство над авторегрессионными моделями на широком спектре кодовых бенчмарков благодаря этапу непрерывного предварительного обучения и оптимизированному графику добавления шума. Stable-DiffCoder достигает лучших результатов среди 8B-параметрических моделей, подтверждая потенциал диффузионного подхода к моделированию кода и открывая новые возможности для улучшения качества генерации и редактирования программного обеспечения. Способны ли диффузионные модели полностью раскрыть свой потенциал в области разработки программного обеспечения и превзойти существующие авторегрессионные подходы?
Ограничения Авторегрессионной Генерации Кода
Современные системы генерации кода в значительной степени опираются на авторегрессионные языковые модели, демонстрирующие впечатляющие результаты в автоматическом создании программного обеспечения. Однако, несмотря на успехи, эти модели сталкиваются с фундаментальными ограничениями масштабируемости. Основанные на последовательном предсказании следующего элемента в последовательности, они эффективно справляются с относительно простыми задачами, но испытывают трудности при работе со сложными проектами, требующими долгосрочного планирования и доступа к большим объемам информации. По мере увеличения объема кода и сложности задач, производительность авторегрессионных моделей закономерно снижается, что ограничивает их возможности в решении действительно масштабных задач разработки программного обеспечения и требует поиска альтернативных подходов к генерации кода.
Архитектура Transformer, лежащая в основе современных моделей генерации кода, демонстрирует впечатляющую способность предсказывать следующий токен в последовательности. Однако, при решении сложных задач, требующих установления связей между удалёнными элементами кода и эффективного доступа к информации, эти модели сталкиваются с ограничениями. Суть проблемы заключается в том, что предсказание следующего токена, хотя и эффективно для простых последовательностей, недостаточно для понимания общей логики программы или для применения знаний, разбросанных по всему коду. Модели испытывают трудности при обработке долгосрочных зависимостей, что снижает их производительность при генерации более сложного и структурированного кода, особенно когда требуется учитывать контекст, охватывающий большое количество строк или функций.
Последовательный характер авторегрессионных моделей, предсказывающих следующий элемент кода шаг за шагом, накладывает существенные ограничения на возможности параллельных вычислений. Это приводит к возникновению вычислительных «узких мест», особенно при генерации сложных программных конструкций. Вместо одновременной обработки различных частей кода, модель вынуждена последовательно обрабатывать каждый токен, что значительно замедляет процесс и ограничивает масштабируемость. В результате, на требовательных бенчмарках, оценивающих способность к генерации больших и сложных программ, производительность авторегрессионных моделей часто достигает плато, демонстрируя ограниченный потенциал для дальнейшего улучшения посредством простого увеличения вычислительных ресурсов.
Маскированная Диффузия для Генерации Кода: Новый Взгляд
Маскированные диффузионные языковые модели (Masked Diffusion Language Models) представляют собой неавторегрессивный подход к генерации кода, в отличие от традиционных моделей, предсказывающих токены последовательно. Это позволяет распараллеливать процесс генерации, поскольку модель обучается восстанавливать замаскированный код, а не предсказывать следующий токен в последовательности. Такой подход потенциально обеспечивает значительное повышение эффективности и скорости генерации кода за счет возможности одновременной обработки нескольких токенов, что особенно важно при работе с большими кодовыми базами.
В отличие от традиционных авторегрессионных моделей, которые генерируют код последовательно, предсказывая токены один за другим, модели маскированной диффузии обучаются восстанавливать исходный код из зашумленной, маскированной версии. Этот процесс предполагает намеренное сокрытие части исходного кода (маскирование) и последующее обучение модели для предсказания и восстановления замаскированных фрагментов. Ключевым преимуществом является возможность параллельной генерации нескольких токенов, поскольку модель не ограничена последовательным предсказанием, что потенциально значительно повышает эффективность генерации кода.
Данный подход использует возможности диффузионных моделей, первоначально разработанных для генерации изображений, и адаптирует их к дискретной области кода. Диффузионные модели, как правило, обучаются постепенно добавлять шум к данным (например, изображению) до тех пор, пока они не превратятся в случайный шум, а затем обучаются обращать этот процесс, восстанавливая исходные данные из шума. Для применения к коду, дискретный характер токенов требует адаптации процесса диффузии. Вместо непрерывного добавления шума, модели учатся «разрушать» код путем маскирования или замены токенов, а затем восстанавливать исходный код из этой «зашумленной» версии. Это позволяет модели изучать вероятностное распределение кода и генерировать новые, синтаксически правильные фрагменты кода.
Stable-DiffCoder: Высокопроизводительная Модель Диффузии
Stable-DiffCoder представляет собой диффузионную языковую модель, разработанную специально для генерации кода. В ее основе лежит модель Seed-Coder, и она расширяет возможности маскированных диффузионных языковых моделей (Masked Diffusion Language Models). В отличие от традиционных подходов, Stable-DiffCoder использует принципы диффузии для создания кода, начиная с зашумленного состояния и постепенно восстанавливая исходный код. Данный подход позволяет модели генерировать более разнообразный и сложный код, чем традиционные авторегрессионные модели, и отличается повышенной устойчивостью к ошибкам в процессе генерации.
В основе архитектуры Stable-DiffCoder лежит метод блочной диффузии (Block Diffusion), при котором для внесения шума в исходный код последовательно удаляются не отдельные токены, а непрерывные блоки токенов. Этот подход отличается от традиционных методов, маскирующих отдельные позиции. Для поддержания стабильности обучения и предотвращения ослабления сигнала в процессе шумоподавления применяется клиппинг расписания шума (Clipped Noise Scheduling). Данная техника ограничивает диапазон добавляемого шума, гарантируя, что сигнал остается достаточно сильным на протяжении всего процесса обучения, что способствует более эффективному восстановлению исходного кода из зашумленного состояния.
Для повышения стабильности и производительности обучения модели Stable-DiffCoder, в процесс обучения интегрированы методы “разогрева” (Warmup Training) и смещения логитов (Logit Shift). Метод “разогрева” предполагает постепенное увеличение скорости обучения на начальных этапах, что способствует более плавному схождению модели и предотвращает нестабильность. Смещение логитов, в свою очередь, изменяет распределение вероятностей, предсказываемых моделью, что улучшает калибровку и повышает точность предсказаний. Дальнейшая оптимизация достигается за счет непрерывного предварительного обучения (Continuous Pretraining), которое позволяет модели адаптироваться к изменяющимся данным и поддерживать высокую производительность на протяжении всего процесса обучения.
Оценка на Ключевых Бенчмарках Генерации Кода
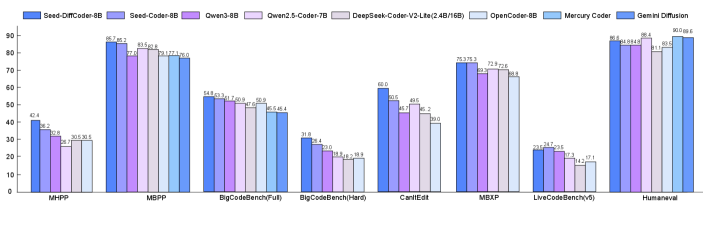
Тщательная оценка возможностей модели Stable-DiffCoder на общепринятых эталонах, таких как HumanEval, MBPP, CRUXEval и MultiPL-E, продемонстрировала ее передовые результаты в области функциональной корректности, решения задач и многоязычной генерации кода. Данные тесты позволили установить, что модель демонстрирует высокую способность к созданию работоспособного кода, эффективному решению сложных алгоритмических задач и адаптации к различным языкам программирования. Результаты подтверждают, что Stable-DiffCoder представляет собой значительный шаг вперед в области автоматической генерации кода, предлагая улучшенные возможности по сравнению с существующими аналогами.
В ходе всестороннего тестирования, модель Stable-DiffCoder продемонстрировала выдающиеся результаты на бенчмарке HumanEval, достигнув показателя Pass@1 в 64.2%. Этот результат свидетельствует о значительно улучшенной способности модели генерировать функционально корректный код, превосходя базовую модель Seed-Coder-8B примерно на 2-3%. Данное превосходство подтверждает эффективность предложенных архитектурных и обучающих решений, позволяющих Stable-DiffCoder более точно интерпретировать и выполнять поставленные задачи по генерации кода, что делает её перспективным инструментом для автоматизации разработки программного обеспечения.
В ходе оценки на наборах данных `MBPP` и `BigCodeBench (Completion, Full Set)` модель `Stable-DiffCoder` продемонстрировала превосходство в генерации корректного кода. На `MBPP` она достигла показателя `Pass@1` в 54.1%, что на 1-2 процентных пункта превышает результат базовой модели `Seed-Coder-8B`. Аналогично, на более крупном наборе данных `BigCodeBench (Completion, Full Set)` `Stable-DiffCoder` набрала 44.1%, опережая `Seed-Coder-8B` примерно на 2-3 процентных пункта. Эти результаты подтверждают способность модели эффективно решать разнообразные задачи по кодированию и демонстрируют значительный прогресс в области автоматической генерации программного обеспечения.
Исследования показали, что модель Stable-DiffCoder демонстрирует выдающиеся результаты в задачах редактирования кода и многоязычного программирования. В частности, модель достигла показателя Pass@1 в 61.3% в тесте CanItEdit, значительно превзойдя все другие протестированные модели. Кроме того, средний показатель Pass@1 в тесте MBXP, охватывающем 13 языков программирования, составил 41.2%, что сопоставимо с результатами модели Seed-Coder-8B и превосходит показатели других моделей, использующих 8 миллиардов параметров. Эти результаты подтверждают способность Stable-DiffCoder эффективно понимать и изменять существующий код, а также генерировать корректные решения на различных языках программирования.
Исследование демонстрирует, что существующие подходы к генерации кода часто наталкиваются на ограничения, связанные с предсказуемостью и недостаточной гибкостью. Авторы Stable-DiffCoder намеренно отошли от традиционных моделей, используя диффузионный подход к языковому моделированию кода. Это позволило им создать систему, способную не просто воспроизводить известные шаблоны, но и исследовать новые возможности генерации. Как говорил Пол Эрдёш: «Математика — это искусство решать проблемы, которые никто не ставил». Иными словами, модель, подобно математическому исследованию, выходит за рамки предписанных задач, активно экспериментируя с данными и алгоритмами, чтобы достичь превосходных результатов в области генерации кода, особенно учитывая применение диффузионной аугментации данных.
Куда же дальше?
Представленная работа, несомненно, расширяет границы возможностей диффузионных языковых моделей в генерации кода. Однако, за кажущейся эффективностью Stable-DiffCoder скрывается вопрос: насколько глубоко эта модель понимает код, а не просто воспроизводит статистические закономерности? Успех, достигнутый благодаря тщательно подобранному конвейеру обучения и аугментации данных, лишь подчеркивает, что прогресс в этой области часто сводится к искусству «накачки» модели данными, а не к созданию настоящего искусственного интеллекта.
Следующим шагом видится не просто увеличение масштаба модели или усложнение архитектуры, а поиск способов привить ей способность к абстрактному мышлению. Необходимо разработать методы, позволяющие модели не просто генерировать код, соответствующий заданным требованиям, но и самостоятельно выявлять ошибки, оптимизировать алгоритмы и адаптироваться к новым, непредсказуемым ситуациям. Проблема «галлюцинаций» в генеративном ИИ, безусловно, остаётся актуальной и в контексте кода — случайные, синтаксически верные, но семантически бессмысленные фрагменты кода — это лишь напоминание о том, что модель оперирует символами, а не смыслом.
В конечном счете, истинный прорыв произойдет тогда, когда модель сможет не просто писать код, а объяснять его, доказывать его корректность и, возможно, даже создавать принципиально новые алгоритмы, превосходящие человеческие. Это, конечно, амбициозная цель, но именно к ней и стоит стремиться, разрушая привычные рамки и подвергая сомнению устоявшиеся догмы.
Оригинал статьи: https://arxiv.org/pdf/2601.15892.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Кванты в Финансах: Не Шутка!
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 08:54