Автор: Денис Аветисян
Исследование показывает, что современные языковые модели способны самостоятельно определять оптимальную длину цепочки рассуждений для решения задач.
Предложена стратегия SAGE, позволяющая повысить точность и эффективность решения математических задач за счет самоопределения момента остановки процесса рассуждений.
Несмотря на значительные успехи в области больших языковых моделей (LLM) и методов цепочек рассуждений (CoT), часто наблюдается избыточность и неэффективность вычислений. В работе, озаглавленной ‘Does Your Reasoning Model Implicitly Know When to Stop Thinking?’, авторы исследуют феномен излишних шагов в процессе рассуждений. Удивительно, но исследование выявило, что LLM неявно способны определять оптимальную точку остановки рассуждений, однако эта способность скрыта текущими стратегиями выборки. Может ли новая парадигма выборки, SAGE (Self-Aware Guided Efficient Reasoning), раскрыть этот потенциал и значительно повысить эффективность и точность LLM в решении сложных математических задач?
Вызовы Глубокого Рассуждения в Языковых Моделях
Несмотря на впечатляющие успехи больших языковых моделей, таких как DeepSeek-R1, сложные задачи, требующие глубокого рассуждения, зачастую выявляют ограничения в их способности поддерживать как точность, так и эффективность. Модели демонстрируют высокую производительность в обработке информации и генерации текста, однако при решении задач, требующих многоступенчатых логических выводов, часто допускают ошибки или требуют чрезмерных вычислительных ресурсов. Это особенно заметно при работе с неоднозначными данными или задачами, требующими понимания контекста и здравого смысла. Несмотря на значительный прогресс в области машинного обучения, способность к надежному и экономичному решению сложных задач рассуждения остается серьезным вызовом для современных языковых моделей.
Несмотря на эффективность метода последовательного рассуждения (Chain-of-Thought, CoT) в языковых моделях, его применение часто сопряжено с существенными вычислительными затратами. Суть CoT заключается в генерации промежуточных шагов рассуждения, что позволяет модели объяснить ход своих мыслей и повысить точность ответов. Однако, для решения сложных задач, требующих глубокого анализа, цепочки рассуждений могут значительно удлиняться, приводя к экспоненциальному росту необходимой памяти и времени вычислений. Это особенно критично для практического применения моделей на устройствах с ограниченными ресурсами или при обработке больших объемов данных, где эффективность и скорость ответа являются ключевыми факторами. В связи с этим, активно ведутся исследования по разработке альтернативных подходов, направленных на сокращение длины цепочек рассуждений без ущерба для качества и точности результатов.
Для практического применения языковых моделей, способных к сложному рассуждению, критически важна эффективность. Несмотря на впечатляющие результаты, достигаемые современными моделями, такими как DeepSeek-R1, длительные цепочки рассуждений, характерные для традиционного подхода “Chain-of-Thought”, требуют значительных вычислительных ресурсов и времени. Поэтому, разработка методов, позволяющих достигать высокой точности при минимальном количестве шагов рассуждений, является первоочередной задачей. Сокращение вычислительной сложности не только делает модели более доступными для широкого круга пользователей, но и открывает возможности для их интеграции в системы реального времени, где оперативность является ключевым фактором. В конечном итоге, оптимизация процесса рассуждения способствует созданию более надежных и масштабируемых решений в области искусственного интеллекта.
SAGE: Параллельный Отбор с Учетом Уверенности
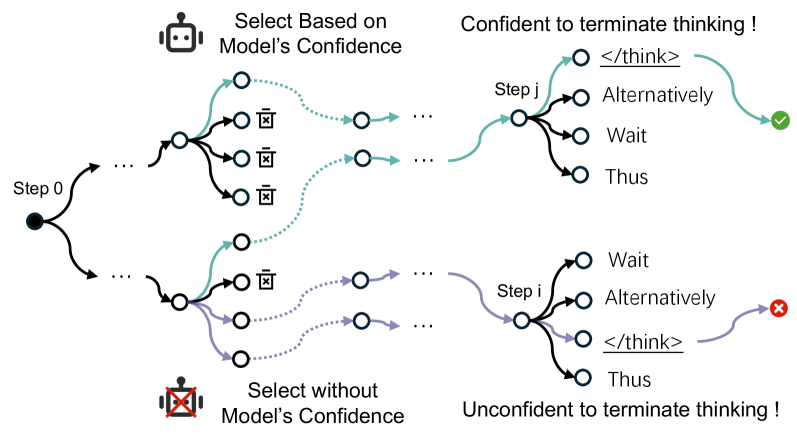
Метод SAGE представляет собой новую парадигму выборки, использующую уверенность модели для направления поиска эффективных путей рассуждений. В отличие от традиционных методов, основанных на случайной или равномерной выборке, SAGE динамически оценивает вероятность правильности каждого шага рассуждения, основываясь на выходных данных модели. Этот подход позволяет алгоритму сосредотачиваться на наиболее перспективных направлениях, избегая ненужных вычислений и повышая вероятность нахождения оптимального решения. Уверенность модели используется как критерий приоритезации, направляя процесс выборки к шагам, которые с наибольшей вероятностью приведут к правильному ответу, что позволяет существенно сократить время и вычислительные ресурсы, необходимые для достижения результата.
Метод SAGE стремится к выявлению более коротких и точных цепочек рассуждений, отдавая приоритет шагам с высокой степенью уверенности модели. Вместо полного перебора всех возможных путей, SAGE фокусируется на тех, которые модель оценивает как наиболее вероятные, что позволяет значительно сократить вычислительные затраты и время поиска. Такой подход позволяет избежать избыточного анализа менее перспективных вариантов, концентрируясь на наиболее релевантных шагах для достижения конечного результата. Это особенно важно в задачах, требующих сложного логического вывода и обработки больших объемов данных, где полный перебор представляется непрактичным.
Параметр «Ширина исследования» (Exploration Width) в методе SAGE определяет количество рассматриваемых альтернативных путей на каждом шаге процесса рассуждения. Увеличение этого параметра способствует более широкому поиску, позволяя исследовать больше потенциальных решений, но увеличивает вычислительные затраты. Уменьшение параметра фокусирует поиск на наиболее перспективных путях, снижая вычислительную сложность, но потенциально упуская более оптимальные решения, требующие более глубокого исследования. Таким образом, «Ширина исследования» служит ключевым регулятором баланса между исследованием (exploration) новых возможностей и использованием (exploitation) уже найденных, влияя на эффективность и точность метода SAGE.
SAGE-RL: Обучение с Подкреплением для Эффективного Рассуждения
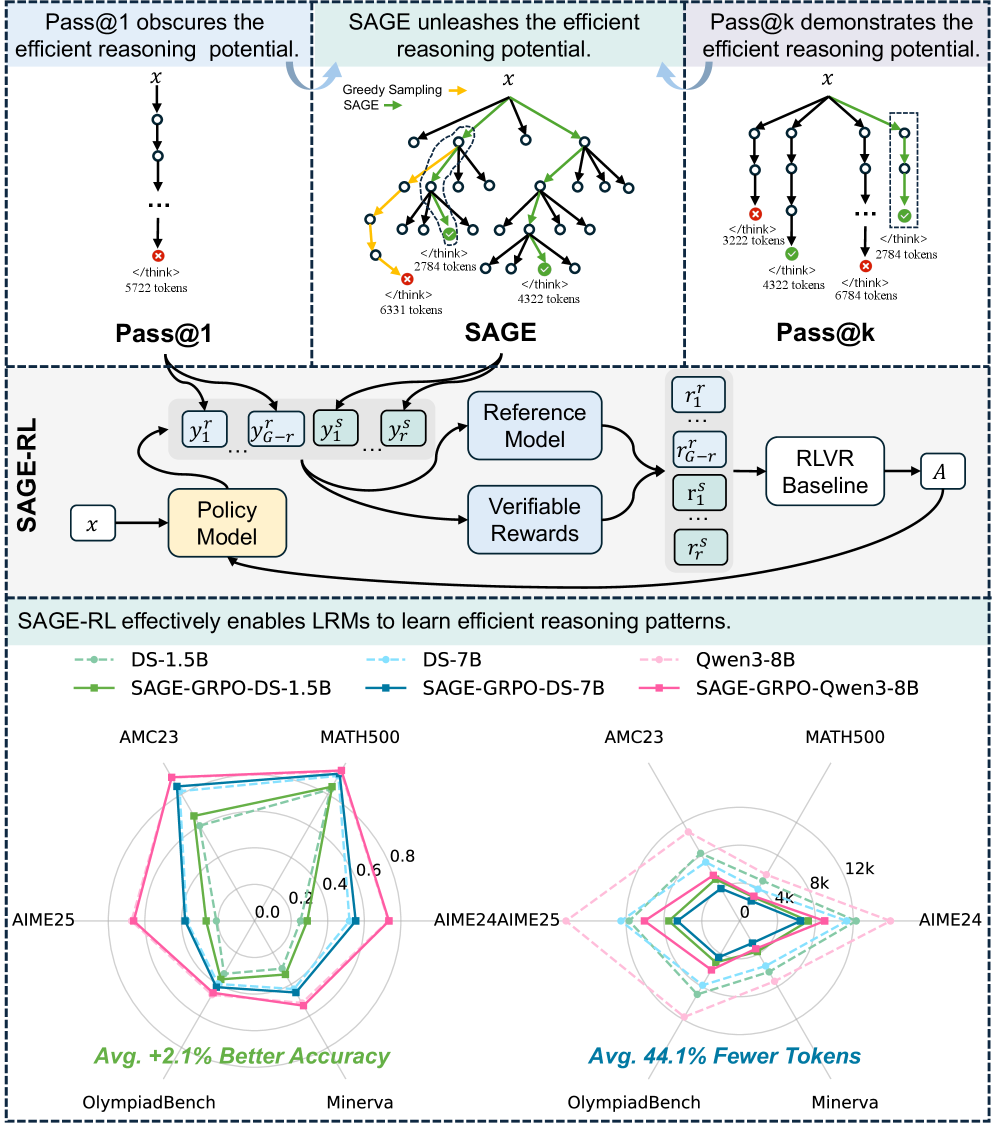
SAGE-RL представляет собой интеграцию алгоритма SAGE во фреймворк обучения с подкреплением с рассуждениями на основе ценностей (RLVR). Данная интеграция позволяет обучать языковые модели оптимизации эффективности процесса рассуждений. В рамках RLVR, SAGE используется для формирования и оценки возможных шагов рассуждения, а обучение с подкреплением корректирует стратегию выбора этих шагов для максимизации целевой функции, отражающей точность и эффективность решения задачи. Это позволяет модели не просто находить правильный ответ, но и делать это, используя минимальное количество вычислительных ресурсов и шагов рассуждений.
В рамках SAGE-RL для оптимизации процесса выборки и максимизации сигналов вознаграждения используются алгоритмы GRPO (Gradient-based Policy Optimization) и GSPO (Gradient-based Sample Policy Optimization). GRPO и GSPO позволяют модели более эффективно исследовать пространство возможных рассуждений, фокусируясь на тех путях, которые с наибольшей вероятностью приведут к правильному ответу. Эти алгоритмы используют градиентный спуск для итеративного улучшения политики выборки, что позволяет модели динамически адаптировать стратегию рассуждений в процессе обучения и повышать точность генерируемых цепочек рассуждений.
В результате применения SAGE-RL наблюдается существенное повышение производительности в задачах, требующих логического вывода. Эксперименты на наборе данных AIME 2025 показали улучшение метрики Pass@1 до 8.2% по сравнению с базовыми моделями. Данный показатель Pass@1 отражает вероятность успешного прохождения теста, то есть генерации корректной последовательности рассуждений, приводящей к правильному ответу. Увеличение значения Pass@1 свидетельствует о повышении точности и надежности генерируемых цепочек рассуждений.
Оценка Эффективности: Более Короткие Цепочки, Более Высокие Награды
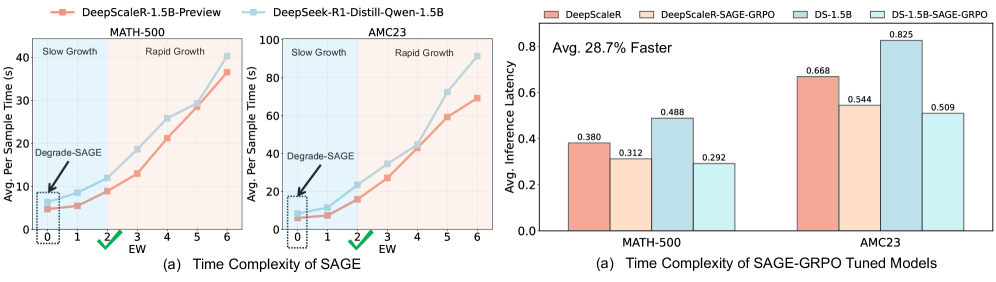
Эмпирические результаты демонстрируют, что SAGE-RL позволяет обнаруживать значительно более короткие цепочки рассуждений без ущерба для точности. Анализ метрик RFCS (Reasoning Fidelity and Chain Sufficiency) подтверждает, что сокращение длины цепочки не приводит к снижению качества решений, а напротив, указывает на более эффективное и лаконичное использование информации. Данное достижение свидетельствует о способности SAGE-RL оптимизировать процесс рассуждений, выделяя наиболее важные шаги и исключая избыточные, что, в свою очередь, повышает надежность и интерпретируемость получаемых результатов. Уменьшение длины цепочек рассуждений открывает возможности для более быстрого и экономичного применения модели в различных задачах, требующих глубокого анализа и принятия решений.
Исследования показали, что сокращение длины цепочки рассуждений, достигаемое благодаря SAGE-RL, напрямую влияет на эффективность использования токенов. В ходе экспериментов зафиксировано снижение времени отклика — до 40% по сравнению с базовыми моделями. Это означает, что модель способна выдавать ответы значительно быстрее, при этом не теряя точности. Уменьшение количества токенов, необходимых для получения ответа, также снижает вычислительные затраты и позволяет обрабатывать больше запросов в единицу времени, что особенно важно для масштабируемых приложений и сервисов, использующих большие языковые модели.
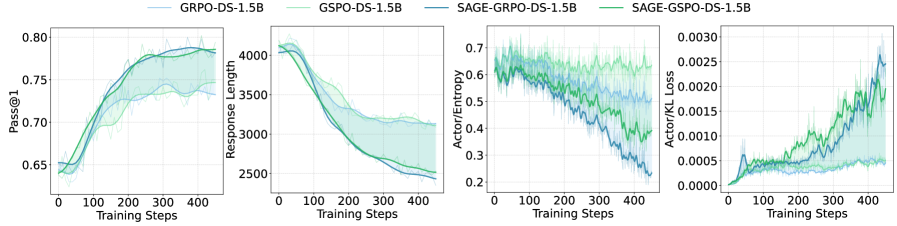
Исследования демонстрируют, что SAGE-RL не только сокращает длину цепочек рассуждений, но и существенно уменьшает объем генерируемых ответов на различных наборах данных, что свидетельствует о более лаконичном и эффективном подходе к решению задач. При этом, наблюдается увеличение значений расхождения Кульбака-Лейблера (KL divergence), указывающее на повышенную уверенность модели в своих выводах и отход от предварительных распределений вероятностей. Повышенное значение KL divergence говорит о том, что SAGE-RL формирует более четкие и уверенные ответы, отклоняясь от усредненных или неопределенных прогнозов, характерных для базовых моделей, и демонстрируя способность к более обоснованным и точным выводам.
Исследования демонстрируют, что подход, основанный на выборке с учетом уверенности модели, обладает значительным потенциалом для решения проблем масштабируемости, возникающих при глубоком рассуждении в языковых моделях. Традиционные методы часто сталкиваются с экспоненциальным ростом вычислительных затрат по мере увеличения сложности задачи, что ограничивает их применение в реальных сценариях. Использование уверенности модели в качестве критерия для отбора наиболее перспективных цепочек рассуждений позволяет существенно сократить их длину без потери точности, тем самым снижая вычислительную нагрузку и задержку вывода. Этот подход открывает возможности для создания более эффективных и масштабируемых систем искусственного интеллекта, способных решать сложные задачи, требующие глубокого анализа и логических выводов, при сохранении высокого уровня надежности и достоверности результатов.
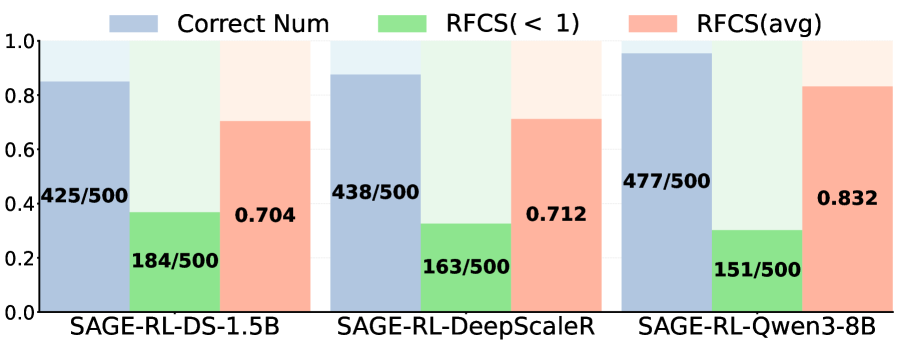
Исследование демонстрирует, что даже самые передовые языковые модели нуждаются в механизмах, определяющих момент завершения рассуждений. Авторы предлагают SAGE — стратегию, направленную на повышение эффективности за счет приоритезации лаконичных, но результативных цепочек рассуждений. Это напоминает о неизбежной борьбе между теоретической элегантностью и практической необходимостью. Как однажды заметил Марвин Минский: «Наиболее полезные идеи часто оказываются самыми простыми». Истина в том, что сложные архитектуры не всегда гарантируют лучшее решение, а зачастую лишь увеличивают технический долг. В данном случае, SAGE стремится найти баланс между глубиной рассуждений и их эффективностью, что является ключевым аспектом для создания действительно полезных систем искусственного интеллекта.
Что дальше?
Представленная работа, как и многие другие в погоне за «разумным» искусственным интеллектом, демонстрирует умение модели находить более эффективные пути к решению задач. Однако, иллюзия «остановки» рассуждений, достигнутая с помощью SAGE, — это лишь оптимизация процесса, а не осознание. Продакшен, как известно, всегда найдёт способ сломать даже самую элегантную теорию, подсовывая задачи, где кратчайший путь — это обходной маневр через пять дополнительных шагов.
Следующим этапом, вероятно, станет попытка привязать эту «эффективность» к мета-обучению, чтобы модель сама определяла, когда достаточно рассуждений. Но не стоит обольщаться. Каждая «революционная» технология завтра станет техдолгом, требующим постоянного обслуживания и патчей. И вопрос не в том, сможет ли модель остановиться, а в том, сколько ресурсов потребуется, чтобы её заставить это сделать, и как долго это продлится.
В конечном счёте, всё новое — это старое, только с другим именем и теми же багами. Вместо того, чтобы удивляться способности модели оптимизировать поиск, стоит задуматься о том, как сделать эту оптимизацию более устойчивой к неизбежным атакам со стороны реального мира, где «верные награды» — понятие весьма относительное.
Оригинал статьи: https://arxiv.org/pdf/2602.08354.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-23 20:44