Автор: Денис Аветисян
Как большие языковые модели способны автоматически подбирать оптимальные модели и гиперпараметры для решения задач машинного обучения, предлагая масштабируемую альтернативу ручной настройке.
Исследование возможностей больших языковых моделей в качестве мета-обучающихся для автоматизированного выбора моделей и оптимизации гиперпараметров.
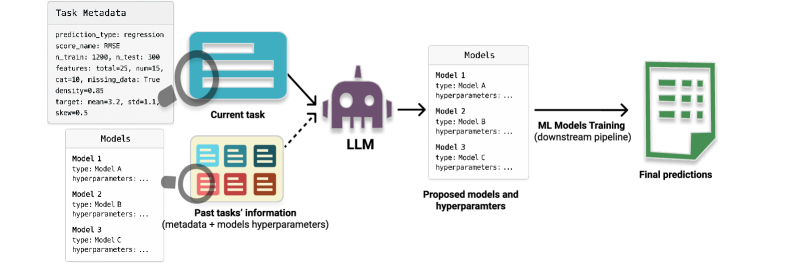
Выбор подходящей модели и гиперпараметров остается сложной задачей в машинном обучении, требующей значительных усилий и экспертных знаний. В статье ‘LLMs as In-Context Meta-Learners for Model and Hyperparameter Selection’ исследуется возможность использования больших языковых моделей (LLM) в качестве мета-обучающихся для автоматизации этого процесса. Показано, что LLM способны, опираясь на метаданные наборов данных, эффективно рекомендовать как семейства моделей, так и их гиперпараметры, демонстрируя конкурентоспособные результаты без необходимости проведения трудоемкого поиска. Открывает ли это путь к созданию универсальных, масштабируемых помощников для автоматизации машинного обучения и оптимизации моделей?
Иллюзии Рассуждений: Почему Большие Модели Ошибаются
Несмотря на впечатляющий масштаб современных больших языковых моделей, надежные способности к рассуждению остаются проблемой. Существующие архитектуры ограничены при решении задач, требующих многоступенчатого логического вывода и глубокого понимания контекста. Традиционные подходы часто терпят неудачу при обобщении знаний и адаптации к новым условиям, особенно в сложных задачах, требующих не только запоминания фактов, но и их комбинирования.
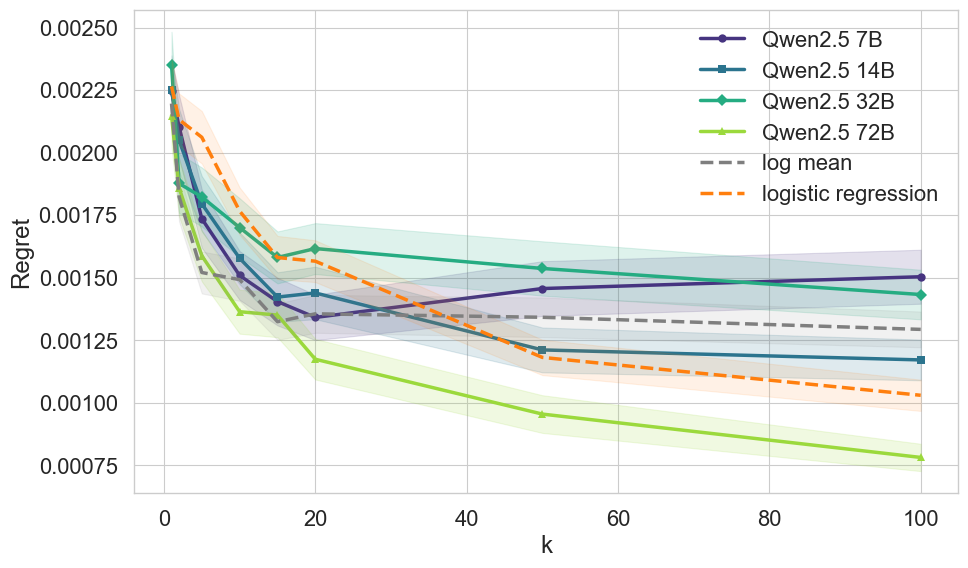
Масштабирование моделей демонстрирует прогресс, но приводит к экспоненциальному росту вычислительных затрат и не гарантирует улучшения способности к рассуждению. Каждая «революционная» архитектура неизбежно превратится в технический долг.
Попытки Обмануть Модель: Zero-Shot и Meta-Informed Стратегии
Стратегия Zero-Shot позволяет большим языковым моделям решать новые задачи исключительно на основе метаданных, без предварительных примеров. Этот подход опирается на способность моделей к обобщению знаний, полученных в процессе обучения. Более сложная Meta-Informed Strategy использует информацию, полученную при решении предыдущих задач, для повышения производительности.
Обе стратегии полагаются на In-Context Learning, позволяя моделям адаптироваться к новым сценариям путем обработки примеров внутри запроса. Модель извлекает информацию из контекста и использует ее для выполнения задачи, даже если она не была явно обучена на подобных примерах.
Kaggle как Полигон: Оценка Производительности и Устойчивости
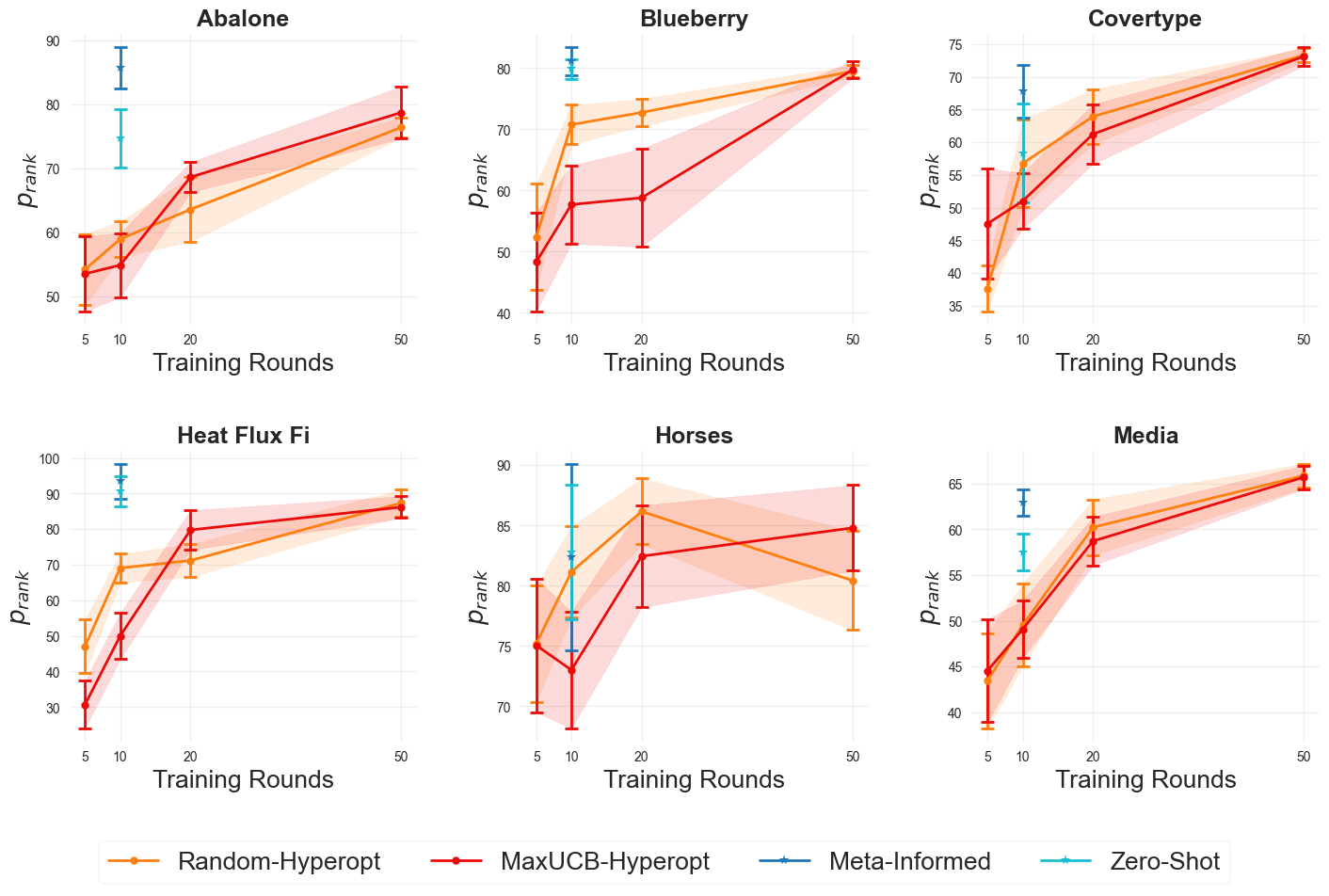
Набор данных Kaggle Benchmark предоставляет стандартизированную платформу для оценки производительности различных методов. Использование унифицированных данных позволяет проводить объективное сопоставление алгоритмов. В качестве ключевого показателя эффективности используется метрика Score (prank), представляющая собой перцентильный ранг на лидирующей таблице.
Результаты экспериментов демонстрируют среднее значение метрики prank, равное 72.7, что превосходит показатели Zero-Shot (70.39) и LGBM-Hyperopt (61.86). Это указывает на улучшенную способность модели к обобщению и точности прогнозирования. Проверка устойчивости модели проводилась путем перестановки запросов. Полученное значение p-value, равное 0.153, свидетельствует об отсутствии статистически значимой разницы между различными версиями запросов, подтверждая стабильность работы модели при незначительных изменениях входных данных.
Представленное исследование демонстрирует, что большие языковые модели способны автоматизировать выбор моделей и гиперпараметров, что не может не вызвать скепсиса. Кажется, что каждая новая «революция» в машинном обучении лишь добавляет ещё один слой абстракции, который рано или поздно потребует расплаты в виде технического долга. Как справедливо заметил Марвин Минский: «Наиболее перспективные исследования — это те, которые дают самые неожиданные результаты». И действительно, способность LLM к мета-обучению в контексте выбора моделей выглядит неожиданно, но неизбежно потребует постоянного контроля и, вероятно, тонны документации – мифа, созданного менеджерами, чтобы хоть как-то упорядочить этот хаос. Весь этот автоматизированный поиск параметров напоминает молитву в храме CI – надежду на то, что ничего не сломается.
Что дальше?
Представленная работа, как и многие другие в последнее время, демонстрирует способность больших языковых моделей решать задачи, изначально для них не предназначенные. По сути, это очередная обёртка над хорошо известными алгоритмами подбора гиперпараметров, теперь с добавлением иллюзии понимания. Вполне вероятно, что через пару лет появятся статьи, доказывающие, что LLM просто переобучаются на метаданных предыдущих экспериментов, а не «учатся» чему-то новому. Ничего нового под солнцем, как говорится.
Однако, проблема автоматического подбора моделей и гиперпараметров (CASH) остаётся актуальной. Масштабируемость – это хорошо, но часто за ней скрывается потеря контроля и непредсказуемость. Интересно, когда кто-нибудь вспомнит про простоту и интерпретируемость классических методов? Вероятно, когда очередная нейронная сеть начнёт выдавать абсурдные результаты, которые невозможно отладить.
Будущие исследования, скорее всего, будут направлены на повышение устойчивости этих моделей к «шуму» в данных и снижение вычислительных затрат. Но в конечном итоге, всё новое – это просто старое с худшей документацией. И не стоит забывать, что самая элегантная теория бессильна перед лицом продакшена, который всегда найдёт способ её сломать.
Оригинал статьи: https://arxiv.org/pdf/2510.26510.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые нейросети на службе нефтегазовых месторождений
2025-11-02 12:33