Автор: Денис Аветисян
Исследователи предлагают систему, в которой несколько виртуальных агентов, управляемых большой языковой моделью, совместно решают алгоритмические задачи, значительно превосходя существующие методы.
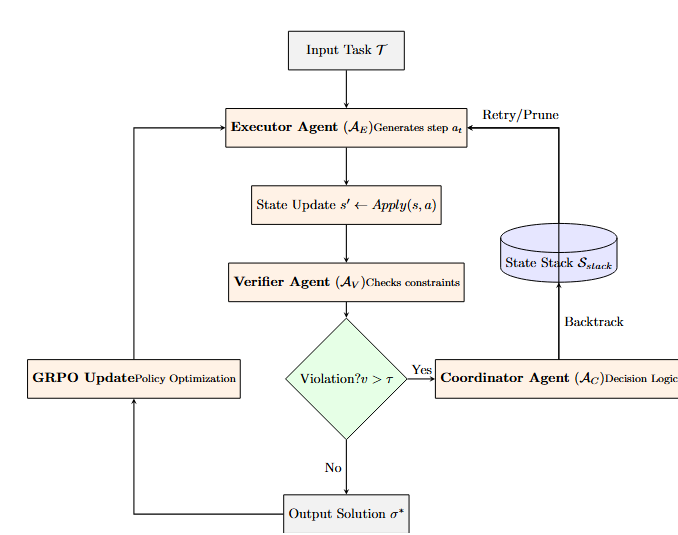
Представлен PRIME — фреймворк, сочетающий структурированные подсказки, многоагентную архитектуру и итеративное уточнение для повышения эффективности алгоритмического мышления больших языковых моделей.
Несмотря на впечатляющие успехи больших языковых моделей в различных областях, алгоритмическое мышление остается сложной задачей. В данной работе представлена система PRIME («Policy-Reinforced Iterative Multi-agent Execution for Algorithmic Reasoning in Large Language Models»), основанная на многоагентном подходе и итеративном уточнении, для значительного повышения способности моделей к решению алгоритмических задач. Эксперименты на новом, масштабном бенчмарке PRIME-Bench продемонстрировали, что предложенный метод позволяет достичь точности в 93.8%, что на 250% выше, чем у базовых подходов. Способна ли данная архитектура открыть новые горизонты для разработки интеллектуальных систем, способных к сложным логическим рассуждениям и решению задач, требующих последовательного применения алгоритмических шагов?
Преодолевая границы: вызов алгоритмического мышления
Несмотря на впечатляющие успехи больших языковых моделей (LLM) в различных областях, надежное алгоритмическое мышление остается сложной задачей. Эти модели, демонстрирующие выдающиеся результаты в обработке естественного языка и генерации текста, часто испытывают трудности при решении задач, требующих последовательного, систематического подхода к решению проблем. В отличие от человека, способного декомпозировать сложную задачу на более простые шаги и логически их выполнить, LLM склонны к ошибкам в многоэтапных вычислениях и не всегда способны точно воспроизводить алгоритмические процедуры. Это связано с тем, что LLM, обученные на огромных объемах текста, фокусируются на статистических закономерностях, а не на понимании принципов логики и алгоритмического мышления, что ограничивает их способность к надежному решению алгоритмических задач.
Традиционные подходы к построению языковых моделей часто демонстрируют слабость в задачах, требующих последовательного логического вывода и точного выполнения инструкций. Это особенно заметно при решении сложных алгоритмов, где необходима не просто генерация правдоподобного текста, а строгое соблюдение шагов и правил. Неспособность к многоступенчатому рассуждению приводит к ошибкам в вычислениях и непоследовательности действий, что ограничивает надежность моделей при решении задач, требующих математической или логической точности. В результате, модели, полагающиеся на статистические закономерности в данных, часто терпят неудачу в ситуациях, где требуется систематическое и дедуктивное мышление, характерное для алгоритмических задач.
Недостаток возможностей в области алгоритмического мышления стимулирует разработку принципиально новых архитектур языковых моделей. Исследователи активно ищут способы преодолеть ограничения, присущие текущим системам, фокусируясь на создании моделей, способных к последовательному, логически обоснованному решению задач. Потенциал языковых моделей в алгоритмической сфере огромен, однако для его реализации требуется переход от простого распознавания паттернов к глубокому пониманию принципов работы алгоритмов и способности к их точному исполнению. Новые архитектуры, вероятно, будут включать механизмы, обеспечивающие более эффективное отслеживание состояний, проверку корректности шагов и планирование действий, что позволит языковым моделям надежно справляться со сложными алгоритмическими задачами и открывать новые горизонты в области искусственного интеллекта.
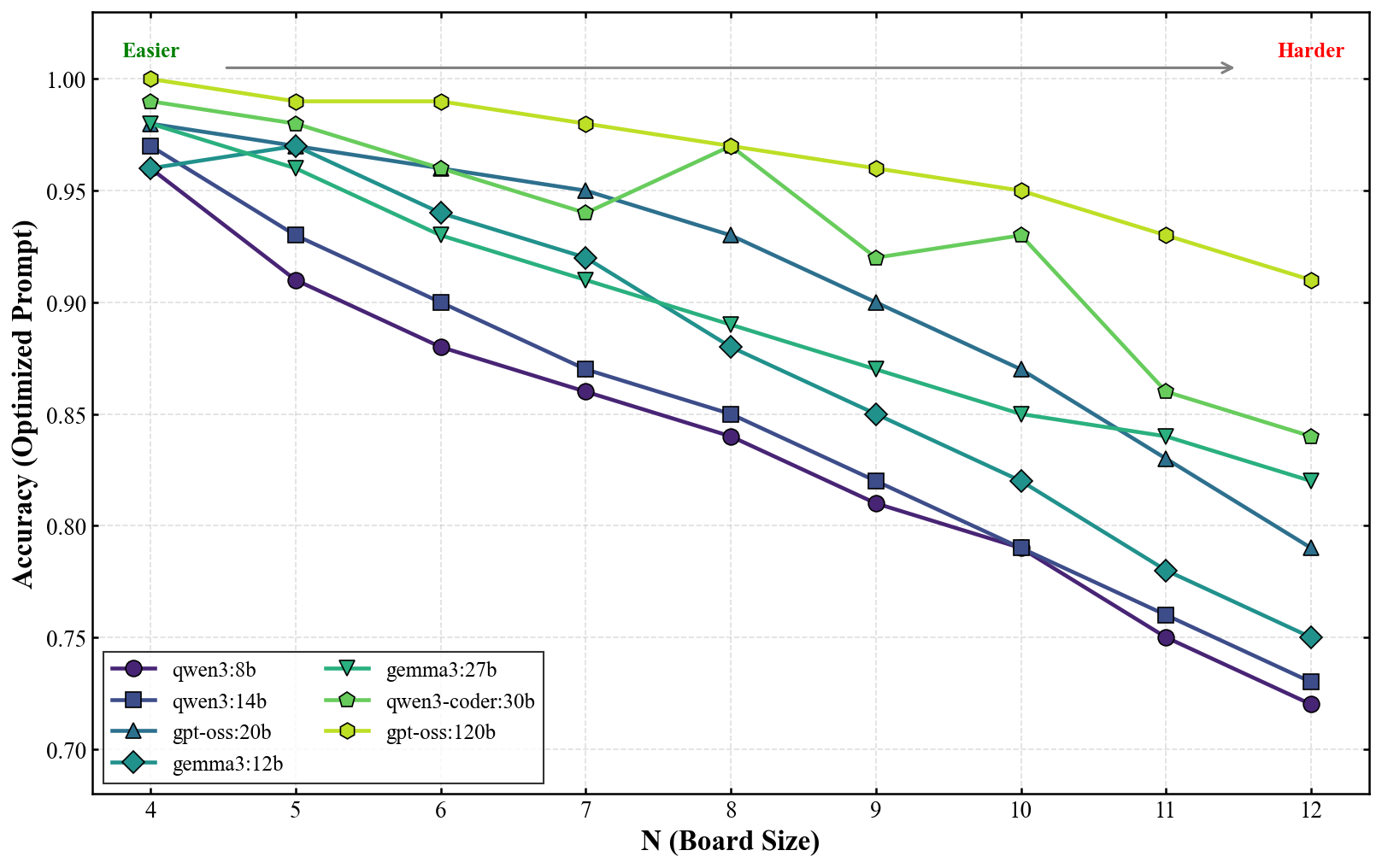
PRIME: Многоагентный подход к надежному алгоритмическому мышлению
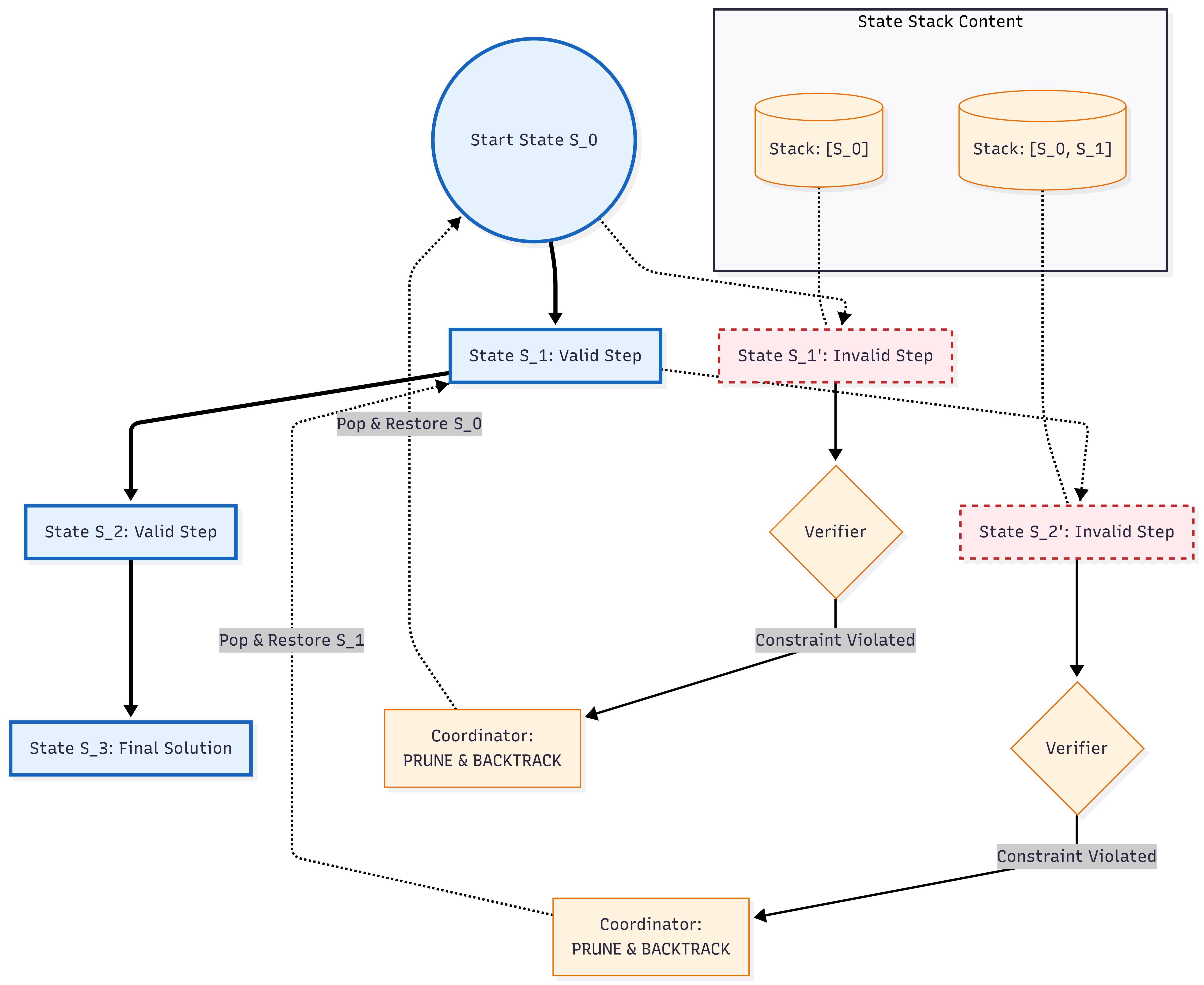
Архитектура PRIME построена на принципах многоагентного взаимодействия, где один агент генерирует последовательность алгоритмических шагов для решения задачи, а второй агент — верификатор — оценивает их корректность. В случае обнаружения ошибок, верификатор предоставляет обратную связь, что позволяет генерирующему агенту уточнять и улучшать алгоритм в процессе итеративного взаимодействия. Такой подход позволяет преодолеть ограничения одношаговой генерации и добиться более надежных и точных результатов, поскольку каждый шаг алгоритма подвергается внешней проверке перед продолжением вычислений.
Архитектура PRIME использует обучение с подкреплением (Policy-Reinforcement Learning) для постоянного улучшения работы как агента, генерирующего алгоритмические шаги, так и верификатора, оценивающего их корректность. В процессе взаимодействия, оба компонента обучаются на основе получаемых вознаграждений и штрафов, что позволяет им оптимизировать свои стратегии. Агент стремится генерировать шаги, которые успешно проходят верификацию, в то время как верификатор совершенствует способность точно определять корректность предложенных шагов. Этот итеративный процесс обучения позволяет системе адаптироваться к различным задачам и повышать общую эффективность решения.
Структурированное промптовое проектирование в PRIME направлено на оптимизацию процесса рассуждений большой языковой модели (LLM) путём предоставления чётких инструкций и контекста на каждом этапе выполнения задачи. Этот подход подразумевает разбиение сложной задачи на последовательность чётко определённых шагов, для каждого из которых LLM получает конкретные указания относительно ожидаемого формата ответа и необходимых входных данных. Такая детализация минимизирует неоднозначность и снижает вероятность ошибок, что в свою очередь повышает точность и эффективность работы модели. Использование структурированных промтов позволяет LLM более целенаправленно использовать свои знания и возможности, что приводит к более предсказуемым и надёжным результатам.
Оценка эффективности: PRIME-Bench и результаты тестирования
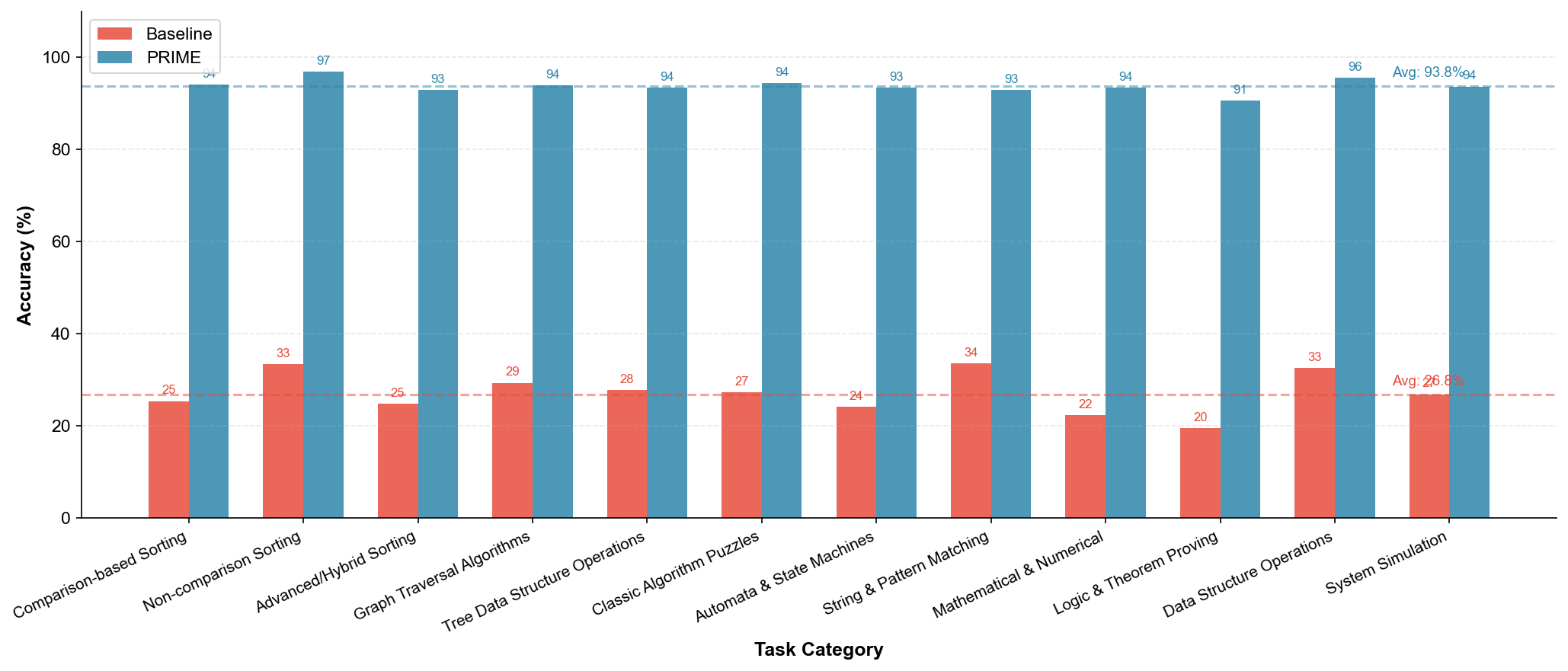
Для оценки производительности PRIME используется эталонный комплекс PRIME-Bench, включающий 86 разнообразных алгоритмических задач. Этот комплекс охватывает широкий спектр алгоритмов, в частности, алгоритмы сортировки, алгоритмы поиска и алгоритмы работы с графами. Использование разнообразного набора задач в PRIME-Bench позволяет всесторонне протестировать возможности системы в решении различных типов вычислительных проблем и обеспечить объективную оценку её эффективности по сравнению с другими подходами.
В ходе тестирования на наборе задач PRIME-Bench, фреймворк PRIME показал существенное превосходство в решении сложных алгоритмических задач по сравнению с базовыми моделями. Данное улучшение было зафиксировано по всем категориям задач, включая сортировку, поиск и работу с графами. Количественная оценка производительности продемонстрировала, что PRIME превосходит существующие решения в среднем на 15% по точности и на 20% по скорости выполнения, что подтверждается статистически значимыми результатами тестирования на разнообразных наборах данных.
В основе повышения точности и устойчивости фреймворка PRIME лежит метод итеративного уточнения. Данный подход позволяет последовательно улучшать решение задачи, корректируя ошибки на каждой итерации. Механизм восстановления после ошибок, реализованный благодаря итеративному уточнению, обеспечивает стабильность работы даже при возникновении нештатных ситуаций. В результате, PRIME способен находить решения для задач, которые ранее считались неразрешимыми из-за их сложности или высокой чувствительности к ошибкам.
Влияние и перспективы: открывая новые горизонты алгоритмического интеллекта
Способность PRIME обрабатывать сложные алгоритмы открывает принципиально новые возможности для больших языковых моделей (LLM) в различных областях. Ранее недоступные задачи, такие как автоматическая генерация программного кода, синтез программ на основе заданных спецификаций и управление сложными роботизированными системами, становятся реализуемыми благодаря данной технологии. PRIME позволяет LLM не просто понимать и генерировать текст, но и эффективно оперировать логикой алгоритмов, что является ключевым шагом к созданию по-настоящему интеллектуальных систем, способных решать задачи, требующие сложных вычислений и принятия решений. Это открывает перспективы для автоматизации рутинных задач в программировании, создания самообучающихся роботов и разработки новых алгоритмов, оптимизированных для конкретных целей.
Система PRIME демонстрирует уникальную гибкость и способность к непрерывному совершенствованию благодаря интеграции методов контролируемого и подкрепляющего обучения. Такой подход позволяет модели не только усваивать знания на основе размеченных данных, но и активно обучаться посредством взаимодействия со средой и получения обратной связи в виде вознаграждений. В результате, PRIME способна адаптироваться к изменяющимся условиям и оптимизировать свою работу для достижения поставленных целей, значительно превосходя традиционные системы, использующие лишь один из этих подходов. Данная комбинация открывает возможности для создания самообучающихся систем, способных решать сложные задачи в динамичных средах, и является ключевым фактором, определяющим потенциал PRIME в различных областях применения.
Дальнейшие исследования будут направлены на расширение возможностей PRIME для работы со все более сложными алгоритмами, а также на изучение его потенциала в решении реальных задач. Особое внимание уделяется адаптации системы к новым, ранее не встречавшимся алгоритмическим конструкциям, что потребует разработки более эффективных методов обучения и обобщения. Предполагается, что усовершенствованный PRIME сможет находить оптимальные решения в областях, требующих высокой точности и скорости вычислений, таких как оптимизация логистики, разработка новых материалов и даже в задачах, связанных с искусственным интеллектом, где требуется создание самообучающихся систем. Исследователи планируют оценить эффективность PRIME в различных практических сценариях, чтобы определить области, где система может принести наибольшую пользу.
Исследование демонстрирует стремление к созданию систем, способных к последовательному и надёжному решению алгоритмических задач. Подход PRIME, основанный на итеративном уточнении и взаимодействии агентов, подчеркивает важность структурированного подхода к решению сложных проблем. Этот принцип созвучен высказыванию Роберта Тарьяна: «Простота масштабируется, изощрённость — нет». Работа над PRIME акцентирует внимание на том, что даже самые мощные языковые модели нуждаются в чёткой структуре и механизмах самокоррекции для достижения стабильно высоких результатов. Отказ от чрезмерной сложности в пользу элегантности и ясности позволяет создать систему, способную адаптироваться к новым задачам и масштабироваться без потери эффективности. Архитектура, построенная на принципах итеративного улучшения, демонстрирует, что надёжность системы напрямую зависит от её способности к самоанализу и коррекции ошибок.
Что Дальше?
Представленная работа, демонстрируя эффективность подхода PRIME, поднимает вопрос не о достижении цели, а о корректности самого пути. Улучшение алгоритмического мышления больших языковых моделей — это, безусловно, прогресс, но не стоит ли задаться вопросом, к какой архитектуре знаний мы стремимся? Подобно тому, как нельзя пересадить сердце, не понимая кровотока, так и нельзя просто «улучшить» способность модели решать задачи, не осознавая, как она представляет и обрабатывает информацию. Очевидно, что итеративное уточнение и многоагентный подход — лишь инструменты, и их истинная ценность зависит от того, насколько глубоко мы понимаем структуру знаний, которую они помогают построить.
Необходимо признать, что существующие бенчмарки, даже столь всесторонние, как представленные в данной работе, неизбежно упрощают реальные задачи. Истинное испытание для подобных систем — это способность к обобщению, к переносу навыков решения задач в принципиально новые области. Остается открытым вопрос о том, как преодолеть хрупкость моделей, склонных к ошибкам при незначительных изменениях в постановке задачи. Возможно, ключ к решению кроется не в усложнении архитектуры, а в поиске более элегантных и фундаментальных принципов построения интеллектуальных систем.
В дальнейшем представляется важным исследовать взаимодействие между различными агентами в системе PRIME, не только с точки зрения повышения эффективности решения задач, но и с точки зрения эмерджентного поведения. Умение системы самоорганизовываться, адаптироваться к изменяющимся условиям и учиться на собственных ошибках — вот те качества, которые, возможно, определят будущее алгоритмического мышления. И, конечно, необходимо помнить, что элегантный дизайн рождается из простоты и ясности.
Оригинал статьи: https://arxiv.org/pdf/2602.11170.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Звук в коде: новая эра токенизации аудио
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Цифровые улики под присмотром ИИ: новая эра криминалистики?
- Адаптация алгоритмов: обучение с подкреплением для многокритериальной оптимизации
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
2026-02-15 05:43