Автор: Денис Аветисян
Новый подход позволяет многоагентным системам улучшать навыки рассуждения и решения задач, используя совместное обучение и текстовый опыт без необходимости переобучения.
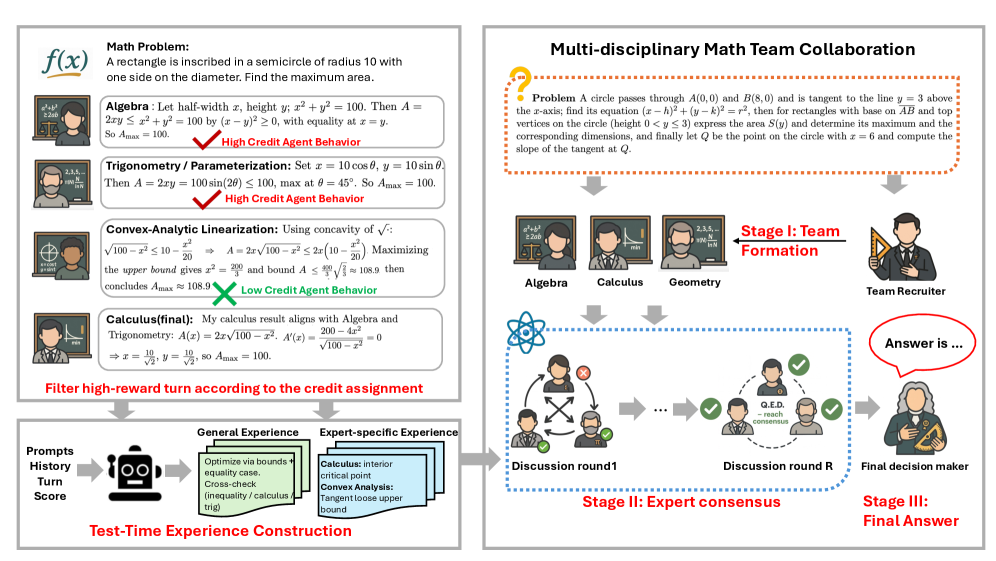
В статье представлен фреймворк Multi-Agent Test-Time Reinforcement Learning (MATTRL), использующий совместное обучение и опыт, представленный в текстовой форме, для повышения способности многоагентных систем к рассуждению и решению проблем.
Несмотря на растущую популярность многоагентных систем, их обучение с подкреплением остается ресурсоемким и нестабильным процессом. В данной работе, посвященной ‘Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning’, предложен фреймворк MATTRL, использующий структурированный текстовый опыт для улучшения совместного принятия решений в режиме реального времени. MATTRL формирует команду экспертов, способных интегрировать опыт, полученный во время работы, и достигать консенсуса, что позволяет повысить точность решения задач в медицине, математике и образовании. Можно ли с помощью подобного подхода создать более устойчивые и эффективные многоагентные системы, способные адаптироваться к изменяющимся условиям без необходимости переобучения?
Синергия Интеллектов: Вызовы Коллективного Рассуждения
Сложные задачи, требующие глубокого анализа и инновационных решений, зачастую не поддаются усилиям одного специалиста. Эффективное решение таких проблем, как правило, достигается благодаря объединению знаний и опыта представителей различных дисциплин — подобно синергии, возникающей в многопрофильных командах. Этот принцип отражает естественную эволюцию научного поиска и инженерной практики, где взаимодействие специалистов с разными взглядами и методами позволяет выявить неочевидные взаимосвязи и преодолеть когнитивные ограничения, свойственные узкоспециализированному подходу. Именно поэтому, моделирование коллективного интеллекта, способного эффективно интегрировать разнородные экспертизы, представляет собой ключевую задачу для современного искусственного интеллекта.
Традиционные системы искусственного интеллекта часто сталкиваются с трудностями при интеграции различных точек зрения, что приводит к фрагментированным и неоптимальным решениям сложных задач. Вместо полноценного синтеза знаний, многие алгоритмы ограничиваются простым усреднением или выбором доминирующей перспективы, игнорируя ценную информацию, содержащуюся в альтернативных подходах. Это особенно заметно в задачах, требующих междисциплинарного анализа, где недостаточная интеграция знаний может привести к упущению важных деталей и, как следствие, к неэффективным результатам. Неспособность эффективно объединять различные перспективы ограничивает потенциал искусственного интеллекта в решении комплексных проблем, требующих широкого спектра знаний и умений.
Эффективное использование коллективного интеллекта требует подходов, выходящих за рамки простого суммирования мнений или данных. Простое агрегирование, например, усреднение оценок или выбор наиболее часто встречающегося ответа, часто упускает из виду нюансы и ценные инсайты, которые могут возникнуть при взаимодействии различных точек зрения. Более сложные методы, такие как взвешивание вкладов участников в зависимости от их экспертизы или использование алгоритмов, способных выявлять и объединять комплементарные знания, позволяют добиться более качественных и инновационных решений. Исследования показывают, что успешные коллективные системы не просто собирают информацию, но и стимулируют дискуссию, позволяют участникам аргументировать свои позиции и совместно формировать более полное понимание проблемы, что в итоге приводит к значительному повышению эффективности решения задач.
В условиях совместного решения сложных задач, существенным препятствием является справедливая и эффективная оценка вклада каждого участника. Традиционные подходы часто фокусируются на итоговом результате, игнорируя нюансы индивидуального участия и интеллектуальных усилий. Это приводит к несправедливому распределению признания и мотивации, снижая эффективность коллективной работы. Исследования показывают, что разработка механизмов, учитывающих качество, новизну и влияние каждого вклада, критически важна для поддержания высокой вовлеченности и стимулирования творческого подхода в командах. Поиск оптимальных методов оценки, основанных на принципах прозрачности и объективности, является ключевой задачей для развития систем искусственного интеллекта, способных эффективно использовать коллективный разум.
MATTRL: Архитектура Динамического Взаимодействия
MATTRL представляет собой новую структуру для многоагентного взаимодействия, основанную на обучении с подкреплением во время тестирования (test-time reinforcement learning). В отличие от традиционных подходов, требующих предварительной тренировки для каждого сценария, MATTRL позволяет агентам адаптироваться и оптимизировать свое поведение непосредственно в процессе выполнения задачи. Это достигается путем непрерывного обучения и корректировки стратегий на основе текущих наблюдений и взаимодействий, что обеспечивает повышенную гибкость и эффективность в динамических средах. Ключевым отличием является способность к обучению «на лету», без необходимости повторного обучения модели для каждого нового условия.
В основе MATTRL лежит механизм внедрения ‘текстуального опыта’ — знаний, полученных из предыдущих взаимодействий, для управления поведением агентов. Этот опыт представляет собой структурированные текстовые данные, описывающие успешные или неудачные стратегии, наблюдаемые в предыдущих эпизодах. Агенты используют этот ‘текстуальный опыт’ как дополнительный входной сигнал, позволяющий им адаптировать свои действия в текущей ситуации, даже без переобучения модели. Фактически, внедрение ‘текстуального опыта’ позволяет агентам обобщать знания, полученные в прошлом, и применять их к новым, ранее не встречавшимся сценариям, повышая эффективность совместной работы.
В основе MATTRL лежит использование “базы опыта” — хранилища данных о предыдущих взаимодействиях агентов. Эта база позволяет агентам адаптироваться к новым ситуациям без необходимости переобучения, поскольку они могут извлекать релевантную информацию из накопленного опыта. Информация в базе опыта структурируется таким образом, чтобы агенты могли эффективно находить и использовать знания, применимые к текущей задаче, что значительно повышает скорость адаптации и общую производительность системы в динамической среде.
В рамках системы MATTRL, использование многоагентного взаимодействия демонстрирует повышенную эффективность решения задач по сравнению с использованием отдельных агентов. В ходе тестирования, средний показатель производительности при совместной работе нескольких агентов увеличился на 3.67% относительно других многоагентных систем и на 8.67% по сравнению с наиболее эффективными одиночными агентами, что подтверждает преимущества подхода к решению сложных задач за счет распределения нагрузки и координации действий между несколькими интеллектуальными сущностями.
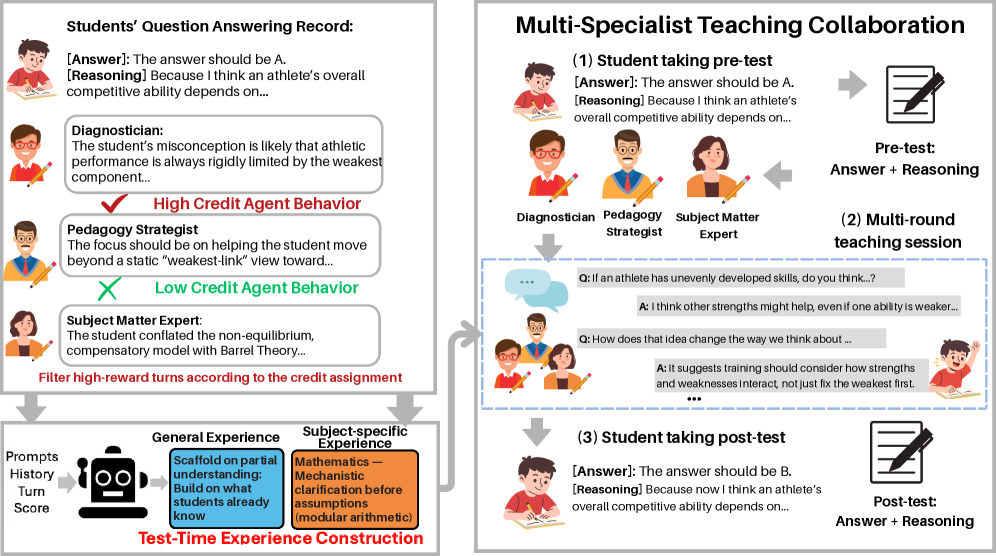
Справедливое Распределение: Методы Оценки Вклада
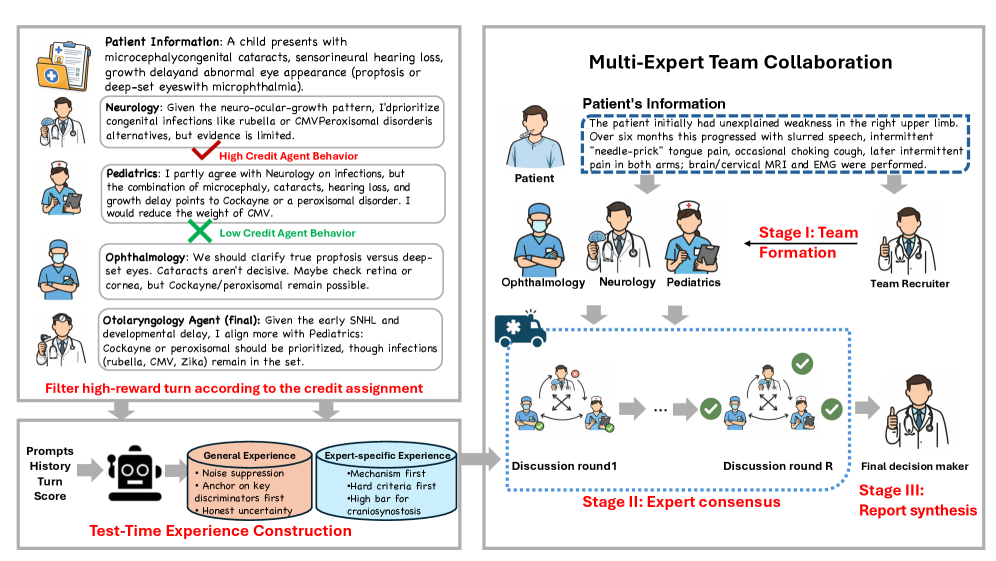
В основе системы MATTRL лежит использование продвинутых методов назначения заслуг (Credit Assignment), предназначенных для справедливой оценки вклада каждого агента в совместную деятельность. В отличие от простых схем разделения вознаграждений, эти методы позволяют дифференцированно оценивать влияние каждого агента на общий результат. Оценка производится на основе анализа вклада каждого агента в процесс достижения общей цели, что обеспечивает более точное и объективное распределение ресурсов и стимулирует эффективное взаимодействие между агентами в системе.
В MATTRL для количественной оценки вклада каждого агента используются методы ‘Difference Rewards’ и ‘Shapley Value’. Метод ‘Difference Rewards’ вычисляет разницу в общей награде системы при участии и отсутствии конкретного агента, тем самым определяя его непосредственное влияние. ‘Shapley Value’, основанный на теории коалиционных игр, определяет средний маржинальный вклад агента во все возможные коалиции других агентов. Этот подход позволяет получить более точную оценку вклада каждого агента, учитывая его взаимодействие с другими участниками системы, и обеспечивает более справедливое распределение ресурсов и поощрений.
В отличие от простых схем разделения вознаграждений, используемые в MATTRL методы кредитного распределения позволяют получить детальное представление о вкладе каждого агента. Они оценивают не общий результат, а маргинальное влияние каждого агента на итоговый успех, вычисляя, насколько изменился бы результат без участия конкретного агента. Это достигается за счет применения таких подходов, как ‘Difference Rewards’ и ‘Shapley Value’, которые позволяют количественно оценить ценность каждого агента независимо от других, предоставляя более точную и справедливую оценку его вклада в совместную работу.
Детальная оценка вклада каждого агента в рамках системы MATTRL позволяет оптимизировать распределение ресурсов и стимулировать эффективное сотрудничество. Экспериментальные данные демонстрируют, что применение данных методов привело к средней прибавке в производительности в 3.67% по сравнению с существующими многоагентными фреймворками. Данный результат достигается за счет точного определения маржинального вклада каждого агента и, как следствие, более справедливого и эффективного распределения вознаграждений и ресурсов.
Влияние на Адаптивную Педагогику: Перспективы Развития
Принципы MATTRL открывают возможности для создания адаптивных образовательных сред, способных учитывать индивидуальные потребности каждого учащегося. Вместо унифицированного подхода, MATTRL позволяет рассматривать процесс обучения как динамическую систему, где образовательный контент и методы подачи материала подстраиваются под текущий уровень знаний и прогресс конкретного ученика. Такая адаптация достигается за счет моделирования студента как активного агента, способного к обучению и развитию, а также за счет использования алгоритмов, отслеживающих его успехи и выявляющих пробелы в знаниях. В результате, образовательный процесс становится более эффективным и персонализированным, позволяя каждому ученику достигать максимального результата, что подтверждается увеличением производительности на 8.67% по сравнению с традиционными методами обучения.
В рамках адаптивного обучения, представление учеников как самостоятельных агентов, обладающих различным уровнем знаний в предметной области, открывает новые возможности для целенаправленной поддержки. Данный подход позволяет преподавателям разрабатывать и применять индивидуальные педагогические стратегии, учитывающие текущий уровень понимания каждого ученика. Моделируя ученика как агента с переменными знаниями, система способна динамически адаптировать сложность и содержание учебного материала, предлагая дополнительные разъяснения или, наоборот, переходя к более сложным темам. Такой персонализированный подход позволяет максимизировать эффективность обучения, фокусируясь на тех областях, где ученику требуется наибольшая помощь, и избегая повторения уже усвоенного материала.
В основе адаптивного обучения, предложенного в данной работе, лежит возможность выявления пробелов в знаниях учащихся посредством углубленного диагностического анализа. Система MATTRL не просто констатирует недостаток понимания, но и применяет специальные методы распределения «кредитов» — оценки вклада различных обучающих интервенций в улучшение результатов. Это позволяет точно определить, какие подходы наиболее эффективны для конкретного учащегося, а какие требуют корректировки или замены. Таким образом, MATTRL обеспечивает не только выявление проблемных зон, но и оптимизацию процесса обучения, направляя ресурсы на наиболее перспективные стратегии и повышая общую результативность.
Внедрение принципов MATTRL позволяет создать индивидуализированный и эффективный процесс обучения, отраженный в усовершенствованной ‘Модели Ученика’. Данная модель, формируемая на основе анализа знаний и стратегий обучения, демонстрирует ощутимый прогресс в успеваемости — на 8.67% выше, чем при использовании традиционных, неадаптивных методов. По сути, система способна не просто передавать информацию, но и точно оценивать уровень понимания каждого учащегося, подстраивая учебный план и обеспечивая максимальную отдачу от обучения. Это достигается за счет постоянного совершенствования ‘Модели Ученика’, что позволяет более эффективно выявлять пробелы в знаниях и предлагать наиболее подходящие образовательные интервенции, гарантируя, что каждый учащийся получит поддержку, необходимую для достижения успеха.
Исследование, представленное в статье, демонстрирует стремление к созданию систем, способных адаптироваться и совершенствоваться в процессе эксплуатации, не требуя постоянного обновления модели. Этот подход перекликается с философскими взглядами Блеза Паскаля: “Человек — всего лишь тростник, самый слабый в природе, но это тростник думает”. Подобно тому, как человек обретает мудрость через опыт, система MATTRL использует совместное обучение и текстовые данные для улучшения рассуждений. Акцент на опыте, полученном во время работы системы, а не на предварительном обучении, подчеркивает идею о том, что устойчивость заключается не в статических структурах, а в способности к медленным, постепенным изменениям. Именно такая адаптация, основанная на текущем контексте и взаимодействии агентов, обеспечивает долговечность и эффективность системы.
Что дальше?
Предложенный подход к обучению мультиагентных систем во время тестирования, безусловно, демонстрирует способность к адаптации без необходимости постоянного обновления моделей. Однако, подобно любому механизму, стремящемуся к совершенству, он обнажает и новые грани сложности. Вопрос не в том, насколько быстро система осваивает новые знания, а в том, как долго она сохраняет способность отличать существенное от несущественного, истинное от случайного. Системы, как и люди, со временем учатся не спешить, и порой, наблюдение за процессом оказывается куда ценнее, чем попытки его ускорить.
Очевидным направлением дальнейших исследований представляется изучение механизмов “забывания” и фильтрации опыта. Накопленный опыт, представленный в текстовом формате, не всегда является чистым источником мудрости; он может содержать шум и противоречия. Мудрые системы не борются с энтропией — они учатся дышать вместе с ней, извлекая пользу даже из кажущегося хаоса. Умение отсеивать устаревшую или нерелевантную информацию станет ключевым фактором долгосрочной эффективности.
В конечном итоге, успех подобного подхода зависит не столько от сложности алгоритмов, сколько от способности системы к саморефлексии. Понимание границ собственной компетентности, признание неполноты знаний — вот что отличает действительно развитую систему. Иногда наблюдение — единственная форма участия, и признание этого факта — первый шаг к истинному пониманию.
Оригинал статьи: https://arxiv.org/pdf/2601.09667.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-18 14:15